

告別漫長等待:3D生成進入“秒時代”!Apple 重新定義實時視圖合成
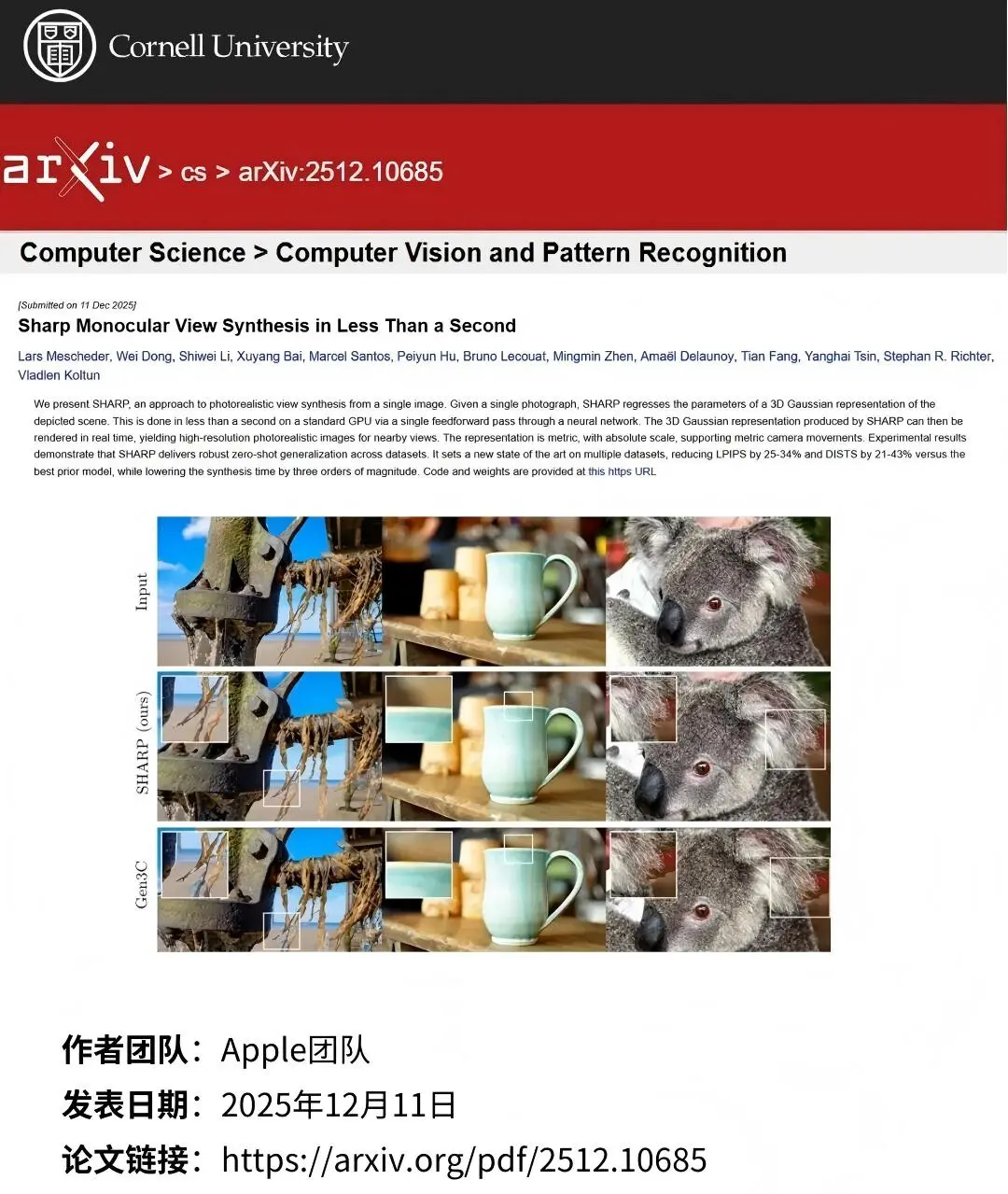
論文標題:Sharp Monocular View Synthesis in Less Than a Second
👉一鍵直達論文
👉Lab4AI大模型實驗室論文閲讀
✨研究背景
在 AR/VR 及互動照片瀏覽領域,用户迫切需要能從單張照片快速生成高保真、可交互的 3D 場景 。然而,傳統的神經渲染技術(如 NeRF)通常需要多張輸入圖像和耗時的場景優化過程,難以滿足實時交互的需求。
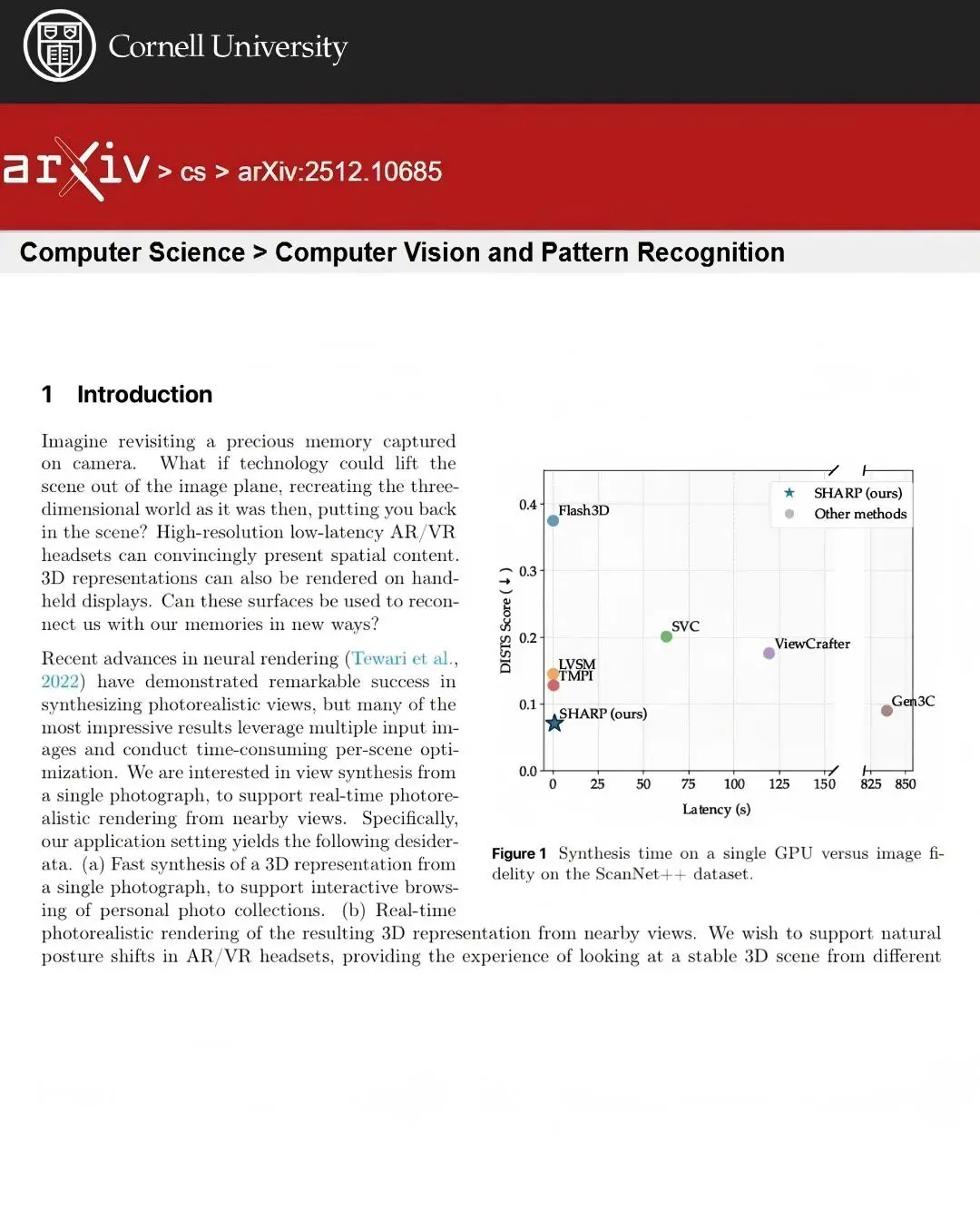
另一方面,雖然現有的擴散模型能實現單圖轉 3D,但其合成時間往往長達數分鐘,且在近距離觀察時圖像細節不夠鋭利。因此,如何在極低延遲內生成支持實時渲染、且具備攝影級精細度的 3D 表示,是當前的一大技術痛點。
✨核心創新
SHARP(Single-image High-Accuracy Real-time Parallax)採用純迴歸框架,通過單一前饋神經網絡直接回歸出 3D 高斯表示 。其關鍵技術選擇包括:
- 🔍端到端架構:設計了一個包含預訓練編碼器、深度解碼器和高斯解碼器的網絡,能夠生成約 120 萬個高斯基元。
- 🔍有狀態的深度調整模塊:引入學習型的深度調整模塊,在訓練中通過解決深度估計的不確定性(如透明或反射表面)來提升合成視角的鋭度 。
- 🔍優化的損失配置:結合了顏色損失、感知損失(LPIPS)、Gram 矩陣損失以及多種正則化項,在確保圖像鋭利的同時抑制了常見的視覺偽影。
- 🔍自監督微調(SSFT):在真實圖像上利用模型生成的偽標籤進行進一步微調,增強了模型處理複雜視角效果的能力。
✨貢獻
SHARP框架通過單前饋神經網絡,1秒內迴歸120萬基元3D高斯表示,比擴散模型快三個數量級。零樣本測試刷新SOTA,LPIPS(25-34%)、DISTS(21-43%)降低,圖像質量提升;搭載深度調整模塊與自監督微調策略,解決單目深度估計模糊,保障視角鋭度與保真度。