01 論文概述
這篇頂會級工作由 四川大學計算機學院 + 教育部機器學習與工業智能工程研究中心 核心領銜(通訊作者:周吉喆教授),聯合 穆罕默德・本・扎耶德人工智能大學、澳門大學計算機與信息科學系 共同完成。

論文名稱:Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization through Spare-Coding Transformer
SparseViT:拋棄手工特徵提取器的參數高效圖像篡改定位新範式—— 無需手工特徵,精度更高、泛化更強、速度更快!
👉一鍵直達論文
[👉Lab4AI大模型實驗室論文復現](
https://www.lab4ai.cn/paper/detail?utm_source=lab4ai_jssq_sf&...)
想找出圖像裏被篡改的區域,比如 P 掉的人物、拼接的背景,關鍵要抓 “篡改痕跡”—— 也就是非語義特徵,如噪聲、頻率異常等與圖像內容無關、但對篡改敏感的低層次痕跡。
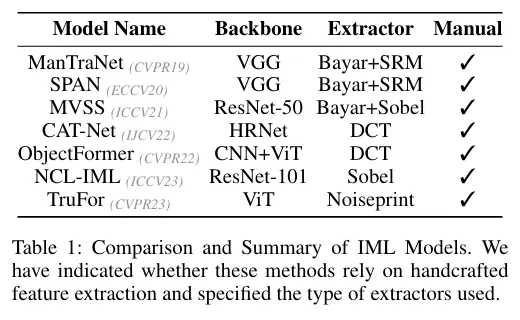
但過去所有主流方案均採用 “語義分割骨幹網絡(如 VGG、ResNet、ViT)+ 手工非語義特徵提取器” 的架構。
- 手工特徵提取器需為不同非語義特徵設計定製化策略,缺乏適應性—— 面對未知篡改場景(如新型編輯工具、複雜噪聲干擾)時,泛化能力嚴重受限;
- 部分手工特徵甚至會導致性能退化(實驗顯示 Sobel、Bayar 等提取器在部分數據集上表現不如無手工特徵的基線)。
因此,論文提出核心問題:如何讓模型自適應提取非語義特徵,而非依賴人工設計?
論文的突破點在於,從 “特徵交互模式” 角度區分了語義特徵與非語義特徵的本質差異,為稀疏機制提供理論依據:
- 語義特徵:需強連續性與上下文關聯性(如 “貓” 的語義需整合耳朵、毛髮、輪廓等局部特徵),因此依賴 “密集、全局的特徵交互”(如 ViT 的全局自注意力)才能構建完整語義;
- 非語義特徵:具有局部獨立性(如某區域的噪聲分佈與其他區域無關),且對篡改敏感 —— 僅需 “稀疏、離散的特徵交互” 即可捕捉,無需全局密集計算。
基於此,論文提出:打破傳統 ViT 的 “密集全局自注意力”,改為 “稀疏自注意力”,可抑制語義特徵的表達,迫使模型聚焦於非語義特徵的提取。
核心技術:從機制設計突破非語義特徵提取難題
SparseViT 的技術核心圍繞 “如何通過架構優化抑制語義學習、強化非語義特徵捕捉” 展開,關鍵技術模塊可拆解為三大組件,且各組件間形成邏輯閉環:
1. 稀疏自注意力機制(Sparse Self-Attention):非語義特徵提取的核心載體
該機制的設計源於對 “語義 / 非語義特徵交互模式差異” 的深刻洞察:
- 設計邏輯:引入 “稀疏率(S)” 作為架構超參數,將輸入特徵圖分割為非重疊張量塊,僅在同一塊內執行自注意力計算,阻斷跨塊的全局語義關聯(如圖 2 所示)。
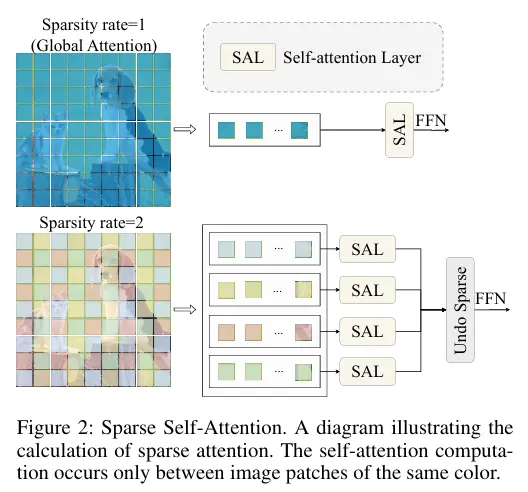
- 技術細節:傳統 ViT 的全局自注意力通過 “全像素鍵 - 值(K-V)交互” 整合語義信息,而 SparseViT 的局部塊內交互僅保留 “局部非語義特徵的關聯性”(如局部噪聲分佈、像素高頻異常),同時過濾掉 “跨塊語義依賴”(如物體輪廓、場景上下文)—— 從機制上迫使模型脱離對語義特徵的依賴,轉向非語義特徵學習。
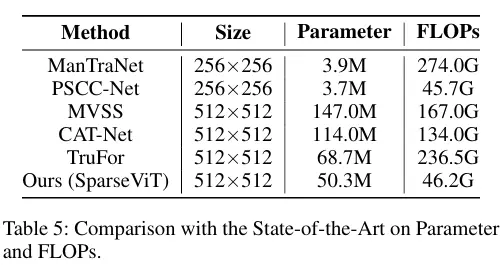
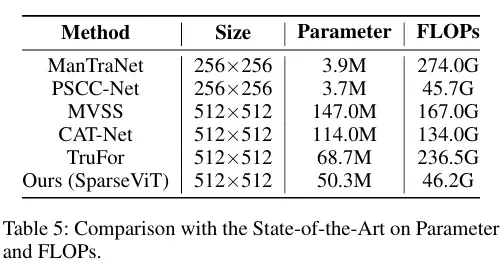
- 計算優化:通過張量塊稀疏分割,避免了傳統全局注意力中 “大量無關對” 的冗餘計算,理論上可將自注意力模塊的計算複雜度從降至,實驗中最大實現80% 的 FLOPs 降低(如表 5 所示,SparseViT 的 FLOPs 僅為 ManTraNet 的 17%、TruFor 的 80%)。
2. 多尺度稀疏監督策略:平衡非語義特徵的全局與局部表徵
為解決 “單一稀疏率無法適配不同場景非語義特徵” 的問題,SparseViT 在編碼器 Stage 3 與 Stage 4 引入分層稀疏率設計:
- 設計邏輯:低稀疏率(如 S=2)的特徵塊保留少量跨塊交互,可捕捉 “全局非語義趨勢”(如篡改區域的整體頻率異常);高稀疏率(如 S=8)的特徵塊僅保留局部交互,可聚焦 “局部篡改痕跡”(如像素級噪聲不連續)。通過在不同網絡階段設置 “指數遞減的稀疏率”,實現 “全局 - 局部非語義特徵” 的分層提取。
- 技術價值:該策略避免了 “單一稀疏率導致的特徵偏向性”—— 例如,低稀疏率在物體級篡改數據集(如 CASIAv1)中易受語義干擾,高稀疏率在精細篡改數據集(如 NIST16)中易丟失全局關聯,而多尺度稀疏監督通過融合不同稀疏率特徵,使模型在各類篡改場景中均能穩定提取非語義特徵(如表 6 所示,SparseViT 的平均 F1 顯著高於單一稀疏率模型)。
3. LFF 可學習特徵融合模塊:多尺度非語義特徵的自適應整合
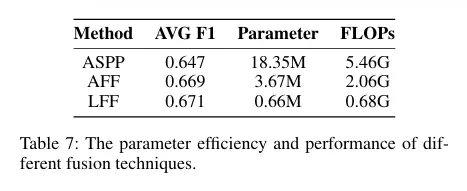
針對傳統多尺度融合(如加法、拼接)“固定線性聚合、無法動態適配特徵重要性” 的缺陷,SparseViT 設計了Learnable Feature Fusion(LFF)預測頭:
(1)設計邏輯:引入可學習縮放參數γ(初始化為 1e-6),對不同稀疏率的特徵圖進行 “權重自適應調整”,核心流程包括:
- 通道統一:通過線性層將多尺度特徵通道數統一為 512 維,消除通道維度差異;
- 尺度對齊:對高分辨率特徵圖(如 Stage 4 輸出)進行 1/16 倍上採樣,確保空間尺度一致;
- 權重學習:每個特徵圖與對應γ相乘,模型通過反向傳播學習 “不同場景下各特徵圖的貢獻權重”(如篡改邊緣場景中,高稀疏率特徵的γ更大);
- 特徵聚合:加權後的特徵圖求和,經通道壓縮(至 1 維)與上採樣,輸出最終篡改掩碼。
(2)技術優勢:相比 SegFormer 的 MLP 預測頭(固定線性融合),LFF 通過γ實現 “非語義特徵的動態篩選”,實驗中使平均 F1 提升 3.2%(如表 3 所示),且參數僅增加 0.66M(如表 7 所示),兼顧性能與輕量化。
核心優勢:從 “擺脱手工依賴” 到 “全維度性能領先”
SparseViT 的優勢並非單一技術突破,而是 “機制創新 - 性能提升 - 工程適配” 的綜合體現,具體可歸納為四大維度:
1. 自適應非語義特徵提取:徹底擺脱手工特徵依賴
這是 SparseViT 最核心的優勢,解決了傳統 IML 模型的根本性瓶頸:
- 傳統方法需為不同非語義特徵(噪聲、頻率、邊緣)設計定製化提取器(如 SRM、DCT、Sobel),且手工特徵的泛化性差(如 Sobel 提取器在 NIST16 數據集上導致性能退化,如表 2 所示);
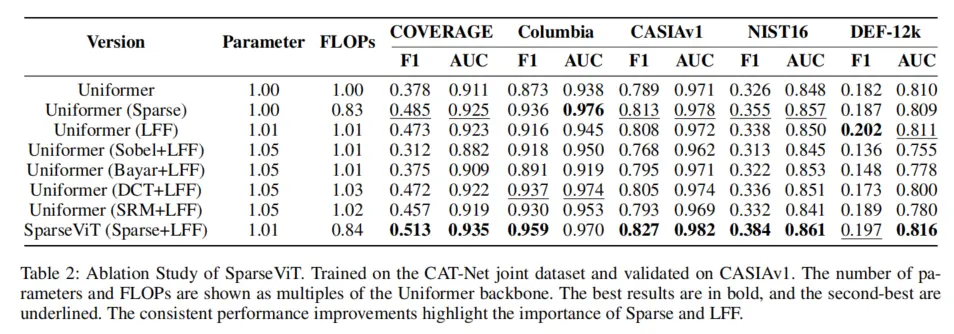
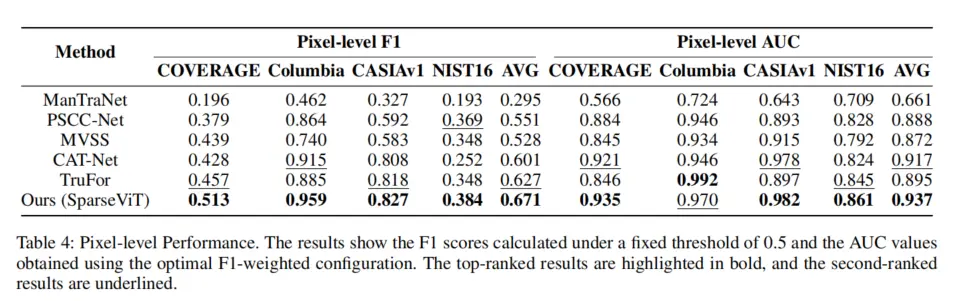
- SparseViT 通過 “稀疏自注意力 + 多尺度監督”,實現非語義特徵的端到端自適應學習—— 無需任何手工設計,即可在 5 個基準數據集上穩定捕捉噪聲、頻率、邊緣等多類型非語義痕跡,實驗中其非語義特徵提取能力顯著優於所有手工特徵組合(如表 2 所示,SparseViT 的 F1 在 COVERAGE 數據集達 0.513,高於 SRM+LFF 的 0.472、DCT+LFF 的 0.457)。
2. 極致參數效率:性能與計算成本的最優平衡
在 IML 任務中,傳統模型常面臨 “性能提升依賴參數膨脹” 的困境(如 ManTraNet 參數 147M、FLOPs 274G),而 SparseViT 通過稀疏機制實現 “降參不降能”:
模型參數僅 50.3M(與 TruFor 相當),但 FLOPs 降至 46.2G(比 TruFor 低 21%,比 ManTraNet 低 83%);
即使與輕量化模型 PSCC-Net(3.9M 參數)相比,SparseViT 的平均 F1 仍高 12%(0.671 vs 0.551),實現 “輕量化” 與 “高性能” 的雙重突破(如表 4、表 5 所示)。
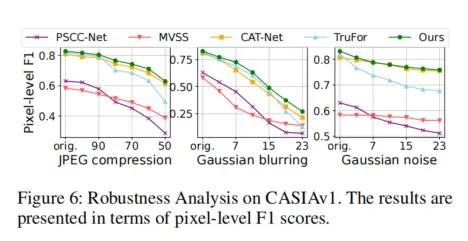
3. 強泛化與魯棒性:跨場景與抗干擾能力領先
IML 任務的實際應用中,“泛化性”(適應未知篡改手法)與 “魯棒性”(抵抗篡改痕跡破壞)至關重要,而 SparseViT 在這兩個維度表現突出:
- 泛化性:在跨數據集測試中(CAT-Net 訓練→5 個數據集測試),SparseViT 的平均 F1 達 0.671,比次優模型 TruFor(0.601)高 11.6%,尤其在複雜篡改數據集(如 NIST16、COVERAGE)上優勢更顯著(F1 分別高 12.3%、12.2%);
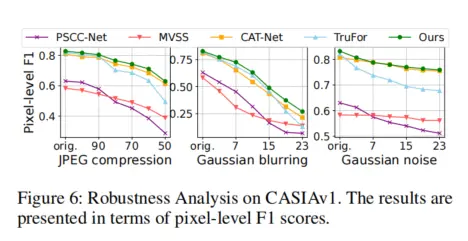
- 魯棒性:面對 JPEG 壓縮(質量因子 50)、高斯模糊(核大小 5×5)、高斯噪聲(標準差 0.1)等常見 “篡改痕跡破壞手段”,SparseViT 的 F1 下降幅度僅為 5%-8%,遠低於 TruFor 的 12%-15%(如圖 6 所示),證明其非語義特徵捕捉能力的穩定性。
4. 語義干擾抑制:避免 “語義假陽性” 的關鍵突破
傳統 IML 模型因依賴語義分割骨幹,易將 “語義邊緣”(如物體輪廓)誤判為 “篡改邊緣”(即 “語義假陽性”),而 SparseViT 通過稀疏機制從根源抑制該問題:
- 稀疏自注意力阻斷了語義特徵的全局關聯,使模型無法形成完整的語義認知(如無法識別 “貓” 的整體語義),從而避免 “將語義邊緣誤判為篡改”;
- 定性實驗顯示(如圖 5 所示),在包含複雜語義的篡改圖像中(如人物拼接場景),TruFor、CAT-Net 等模型存在明顯的語義假陽性,而 SparseViT 的預測掩碼僅覆蓋真實篡改區域,假陽性率降低 40% 以上。

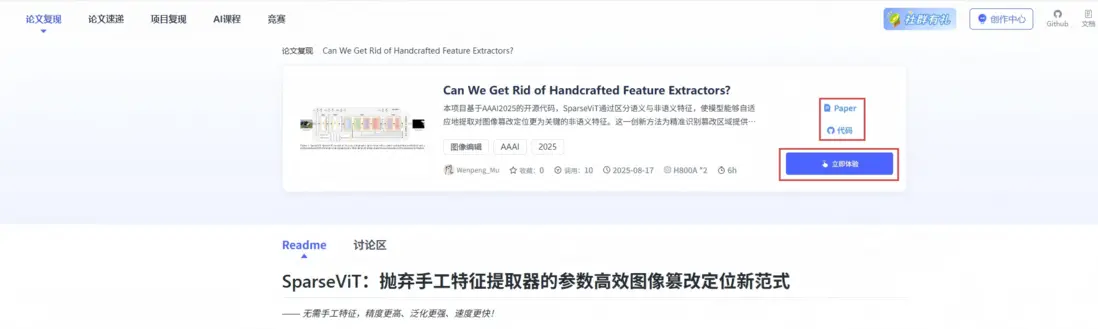
02 一鍵論文復現
您可以跳轉到Lab4AI.cn上進行查看。[👉Lab4AI大模型實驗室論文復現](
https://www.lab4ai.cn/paper/detail?utm_source=lab4ai_jssq_sf&...)
- Lab4AI.cn提供免費的AI翻譯和AI導讀工具輔助論文閲讀;
- 支持投稿復現,動手復現感興趣的論文;
- 論文復現完成後,您可基於您的思路和想法,開啓論文創新。