

港大團隊提出DeepCode ,讓 Agent 真能“讀論文寫可運行代碼”
01 論文概述
這篇論文來自香港大學團隊(通訊作者:Chao Huang)。論文提出並開源了 DeepCode :一個能“自動寫項目”的智能體框架,想解決的不是讓模型多寫幾段代碼,而是讓它讀完論文或技術文檔後,能把一整套代碼工程搭起來,包括項目結構怎麼拆、不同文件怎麼配合、訓練/評測腳本怎麼寫,最後還能把復現實驗真正跑通。

論文名稱:DeepCode: Open Agentic Coding
👉論文鏈接
👉Github
👉大模型實驗室Lab4AI
當論文動輒幾十頁、細節分散在圖表/公式/附錄裏,模型的上下文窗口又裝不下全部信息時,它為什麼還能穩定生成一個能跑通的完整倉庫?
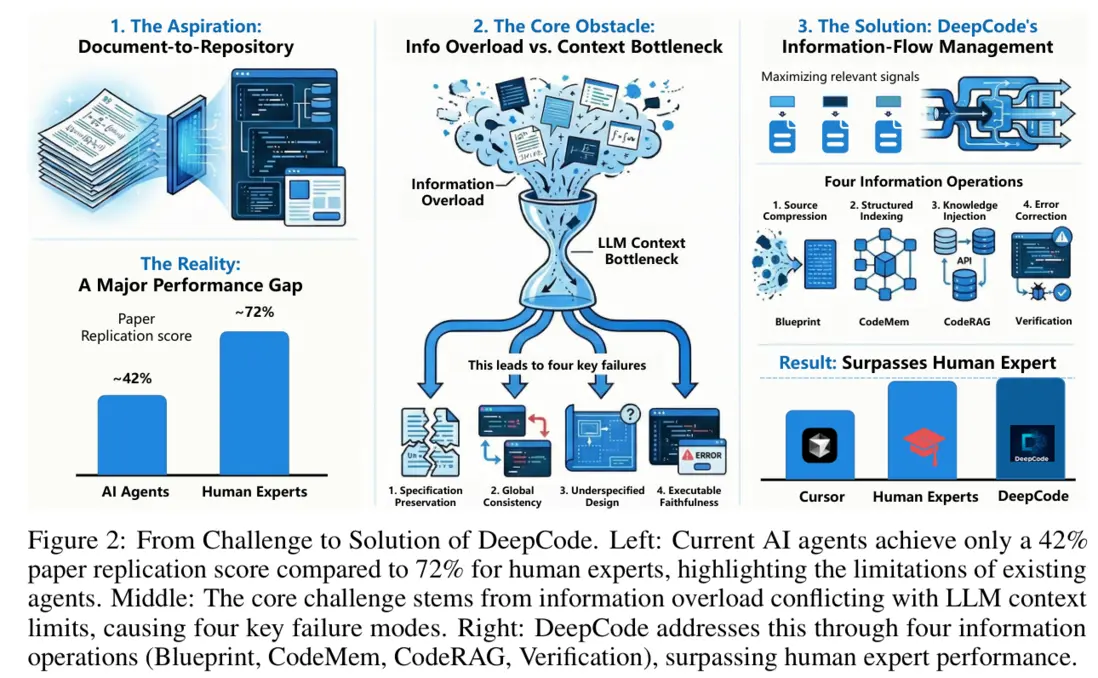
論文的核心觀點其實很直白:現在很多 coding agent 不是“不會寫代碼”,而是很難把一篇論文真正落成一個能跑的完整項目。 問題也不主要在模型參數不夠大,而在於一個硬矛盾——論文信息太多太散(文字、公式、圖表、附錄到處都是細節),但模型的上下文窗口有限,裝不下也裝不準。
如果用最樸素的辦法:把論文全文和前面生成過的代碼一直往上下文裏塞,結果往往是越塞越亂。大量無關細節把關鍵約束淹沒了,模型抓不住“到底哪些東西必須照論文做”。最後就會出現一種常見失敗:倉庫看上去結構也有、代碼也像那麼回事,但關鍵細節寫錯、文件之間對不上、腳本一跑就報錯。
所以 DeepCode 換了個思路: 把這件事當成 “有限容量裏怎麼傳遞關鍵信息” 的問題。也就是,不追求把所有內容都餵給模型,而是讓系統學會把信息先整理、再按需取用,保證每一步寫代碼時看到的都是“當前最相關的那部分”。
基於這個思路,作者將關鍵挑戰總結成四類:
- 規範保真:論文要求分散在各處,模型容易漏掉或寫偏;
- 部分視圖下的全局一致性:倉庫模塊互相依賴,但生成按文件推進且上下文有限,易接口漂移;
- 未充分指定設計的補全:論文常只寫算法核心,工程細節與實驗框架大量默認不明説;
- 可執行保真度:不僅要“合理”,還要能端到端跑通,長鏈路更易積累細小 bug。
DeepCode 的解法可以理解成“四個工具 + 三步流程”:先把論文提煉成一份“可實現的項目説明書”(Blueprint),再用一套“項目記憶”記錄每個文件的作用和接口(CodeMem),需要補缺時再從外部檢索可靠實現模式(CodeRAG),最後用自動檢查 + 實際運行來抓 bug 並逐條修掉(Verification),確保最終交付的是能運行的倉庫而不是“看起來很像的代碼”。
02 核心貢獻
論文的核心貢獻主要是以下三點:
- 先把問題説清楚: 作者指出,做“讀論文寫完整項目”這件事,最大障礙不是模型不聰明,而是論文信息又長又散、模型上下文又有限。想做對,不能靠硬塞內容,必須學會把信息整理成結構、壓縮重點、按需取用。
- 再把方法做成系統: 他們把這個思路落成一個可用框架 DeepCode,用四個關鍵模塊把流程跑通:先把論文提煉成“項目説明書”(藍圖),再用“項目記憶”保證多文件不跑偏,需要時從外部補齊缺失實現,最後通過自動檢查和運行測試不斷修錯,專門解決“細節漏、接口亂、缺工程細節”的老大難問題。
- 最後用結果證明有效: 在 PaperBench 這種要求“真復現、真跑通”的基準上,DeepCode 的表現明顯強過主流商用代碼 Agent,而且在一些關鍵設置下,甚至超過了頂尖機構的博士級人類復現水平。
03 核心技術
DeepCode 不把“讀論文寫倉庫”當成一次性生成任務,而是拆成三步走:先把論文梳理成“能照着做的説明書”,再按説明書寫代碼,最後用自動跑通來糾錯。
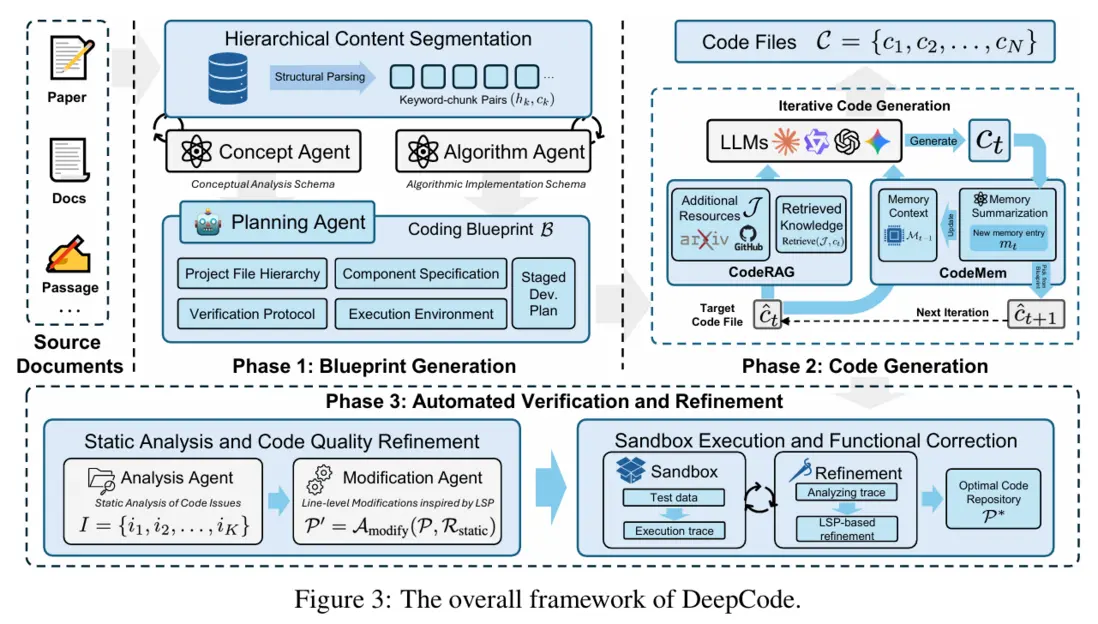
3.1 階段 1:Blueprint(把“論文”變成“項目説明書”)
(1)關鍵點 1:分層切片(Hierarchical Content Segmentation)
它不會把整篇論文一股腦塞進模型上下文,而是先按“章節/小節”切成很多小塊,並用“標題當 keyword”做鍵值索引(可以理解為“目錄 + 標籤”)。後面寫某個模塊時,只把當前真正相關的那幾段取出來看,避免上下文越塞越亂、重點被稀釋。
(2)關鍵點 2:雙分析智能體分工(Concept / Algorithm)
- Concept Agent(大框架):負責把論文講的內容翻譯成“項目怎麼拆、先做什麼後做什麼”的路線圖。
- Algorithm Agent(摳細節):負責把關鍵細節“摳出來”:公式、偽代碼、網絡結構、訓練流程、超參表等;論文也允許它通過在線檢索補齊實現參考(比如某些標準算法的常見寫法)。
(3)關鍵點 3:藍圖的標準化內容(canonical sections)
最後由 Planning Agent 把兩部分分析合成一份“藍圖 B”,更像一份工程規格書:
- 倉庫大概長什麼樣(文件/目錄結構)
- 每個組件要實現什麼(對應論文的算法與模塊)
- 怎麼驗證對不對(驗證協議/運行入口)
- 運行環境怎麼配(依賴、版本、腳本)
- 開發步驟怎麼排(分階段計劃)
3.2 階段 2:CodeMem + CodeRAG(讓多文件不跑偏、缺的細節能補上)
這一階段核心就是兩件事:第一是寫到一半別“失憶”,第二是論文沒寫的工程細節別硬猜。
CodeMem:用“項目記憶”替代“把歷史代碼貼回去”
每生成一個文件,它不把整段源碼再塞回上下文,而是把這個文件“總結成一條記憶卡片”,重點只保留:
- Core Purpose:這個文件/模塊是幹嘛的
- Public Interface:對外暴露什麼類/函數/常量(接口簽名)
- Dependency Edges:它依賴誰、誰會依賴它(依賴關係)
這樣上下文不會隨着倉庫變大而爆炸——寫新文件時,只拿相關記憶摘要就夠了。
CodeRAG:需要時再“外部查資料”,不是每次都搜
論文考慮到很多工程細節在論文裏壓根不寫(比如常見訓練腳手架、標準實現套路)。所以它會先把候選倉庫索引好(篩相關文件→做摘要→建立 source→target 的關係),寫某個目標文件時,模型先判斷一句:“我這一步需不需要檢索?”
需要就把最相關的 snippet/用法/模式拿來當參考注入上下文,不需要就不搜,避免檢索噪聲反而干擾。
3.3 階段 3:Verification(把“寫得像”升級為“跑得通”)
DeepCode 最後一定走驗證閉環,因為“看起來對”不等於“能復現”。驗證分兩層:
- 靜態分析 + 行級修補(LSP 風格):先對照藍圖檢查:有沒有缺文件、空文件、明顯質量問題。修復時儘量做“行級補丁”,而不是整文件推倒重寫,避免越改越引入新錯誤。
- 沙箱運行 + 迭代糾錯:自動搭環境、跑入口腳本/測試流程,捕獲報錯棧(trace),定位可能出錯的文件,再繼續用行級補丁修。一直循環到能跑通,或達到迭代上限。
04 研究結果
4.1 基準與評測:PaperBench Code-Dev
PaperBench Code-Dev 用 ICML 2024 的 20 篇論文當題目,要求模型只看論文,從零生成完整倉庫和 reproduce.sh,並在 VM/容器裏跑起來。每篇論文都有作者認可的 rubric,把任務拆成 8,316 個可評分組件,再用 SimpleJudge(o3-mini)按層級權重自動打分。
換句話説,它測的不是“代碼寫得像不像”,而是復現有沒有真的做到位、有沒有真的跑通。
4.2 主結果:對 LLM Agent / 科研復現 Agent / 商用 Agent / 人類專家均顯著領先
- 對普通LLM-based agents:DeepCode 約 73.6%: 最強對照(o1)約 43.3%(論文引言也提到 o1 在 20 篇上約 42.4%)。
- 對科研復現 Agent(PaperCoder): PaperCoder 51.1±1.4%,DeepCode 73.6±2.8%。
- 對人類專家(Top ML PhD): 在3-paper 子集上,人類 best-of-3 為 72.4%,DeepCode 為 75.9±4.5%。

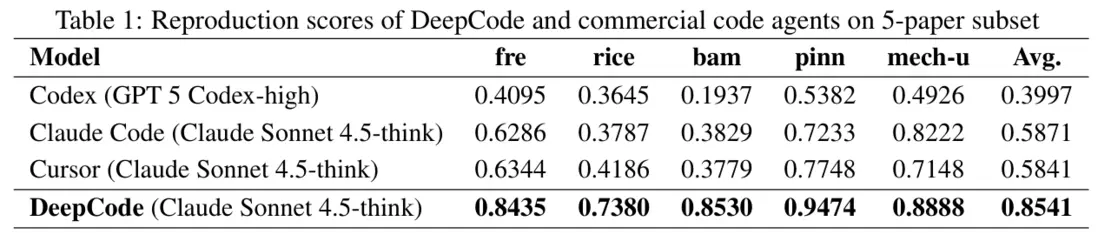
4.3 與商用代碼 Agent 的正面對打
論文在 5-paper 子集上,直接對比 Codex / Cursor / Claude Code,DeepCode 平均分約 0.85,顯著領先;並強調 DeepCode 與 Cursor/Claude Code 使用相同底座模型時依然能拉開差距,説明優勢主要來自架構與執行策略,而非“單純模型更強”。
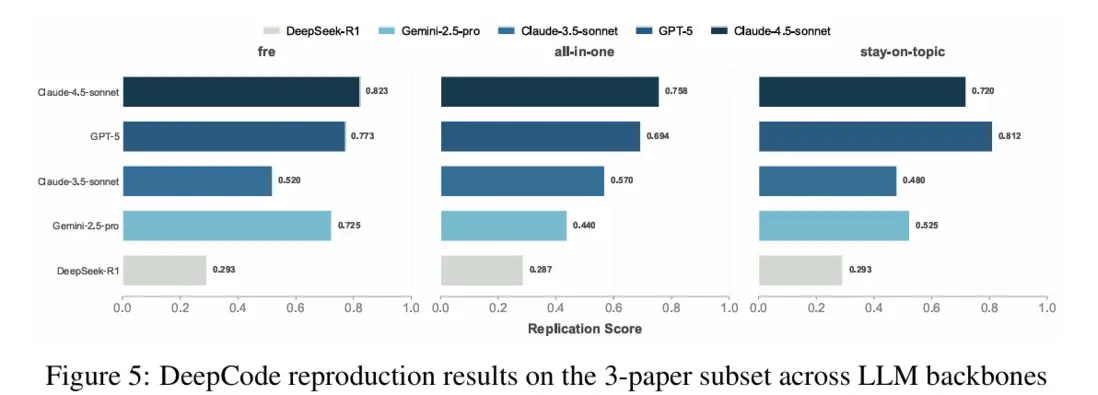
4.4 “模型底座換一換”會怎樣?
論文在三項任務(fre / all-in-one / stay-on-topic)上比較 5 個底座:Claude-4.5、GPT-5、Claude-3.5、Gemini-2.5-Pro、DeepSeek-R1;結論是強底座總體更穩,但 DeepCode 的框架能顯著抬高下限——也就是中等模型也能更像“工程師”一樣把項目寫完整、寫一致、寫到能跑。
4.5 組件消融:哪些模塊最“值回票價”?
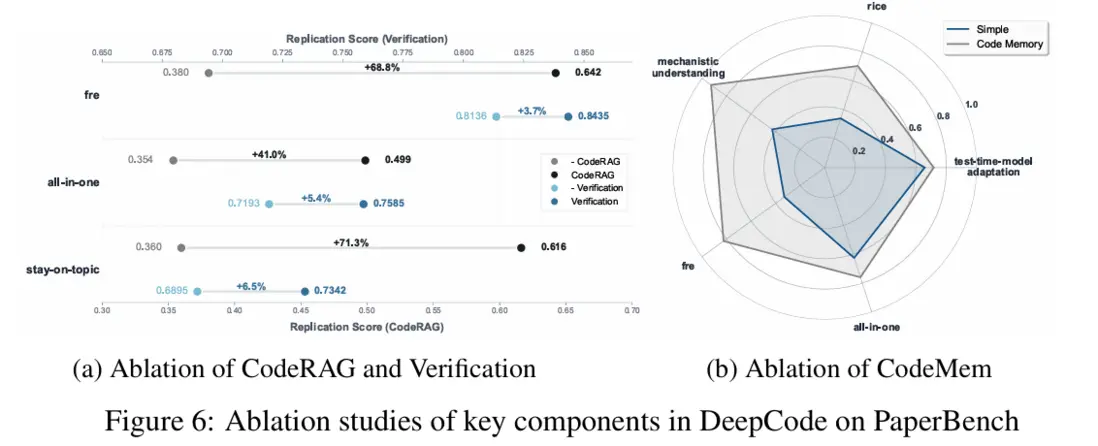
消融結果表明,CodeRAG、CodeMem、Verification 的“回報”各不相同:CodeRAG 對弱底座模型最值,在 Gemini-2.5-Flash 上可帶來顯著提升;CodeMem 則是保障長鏈路跨文件一致性的關鍵,相比簡單滑窗丟歷史,能把多項任務從 0.33–0.43 拉昇到 0.70–0.92;Verification 的提升幅度相對更小但穩定(約 3.7%–6.5%),主要解決拼寫、依賴缺失和命令行參數等“最後一公里”可執行性問題。
一句話點破 DeepCode 的“方法論價值”
如果把“復現論文寫倉庫”看成一個長鏈路的信息傳遞問題,DeepCode 的重點不是堆更大模型、開更長上下文,而是把信息流做成一套工程管道:先壓縮成藍圖(Blueprint)→ 再用記憶維持一致性(CodeMem)→ 必要時補知識(CodeRAG)→ 最後閉環修到能跑(Verification),從而在有限上下文裏也能穩定交付“能跑通的項目”。
本文由AI深度解讀,轉載請聯繫授權。關注“大模型實驗室Lab4AI”,第一時間獲取前沿AI技術解析!