









1. HNSW索引 分層可導航小世界
1.1. 定義
HNSW(Hierarchical Navigable Small World,分層可導航小世界)的核心思想是構建一個分層圖結構:
- 分層結構:每個數據點隨機分配一個層級,層級越高的數據點越少。
- 小世界圖:每層是一個“鄰接圖”,每個點只和部分點相連,圖結構保證“短路徑”導航。
- 導航:從高層開始,逐層向下搜索,逐步接近目標點。
生活類比
想象你在一個有很多樓層的大商場裏找一個你想買的商品。
- 頂層:你可以很快地環顧整個商場的大致佈局(跳躍性大,看得遠)。
- 中間層:你已經大致知道商品在哪個區域,走得更近一些。
- 底層:你到了具體的貨架,仔細找你要的商品(查得很細)。
HNSW 就像這樣,從高層“遠距離跳躍”,逐層到低層“精細查找”,高效地找到目標。
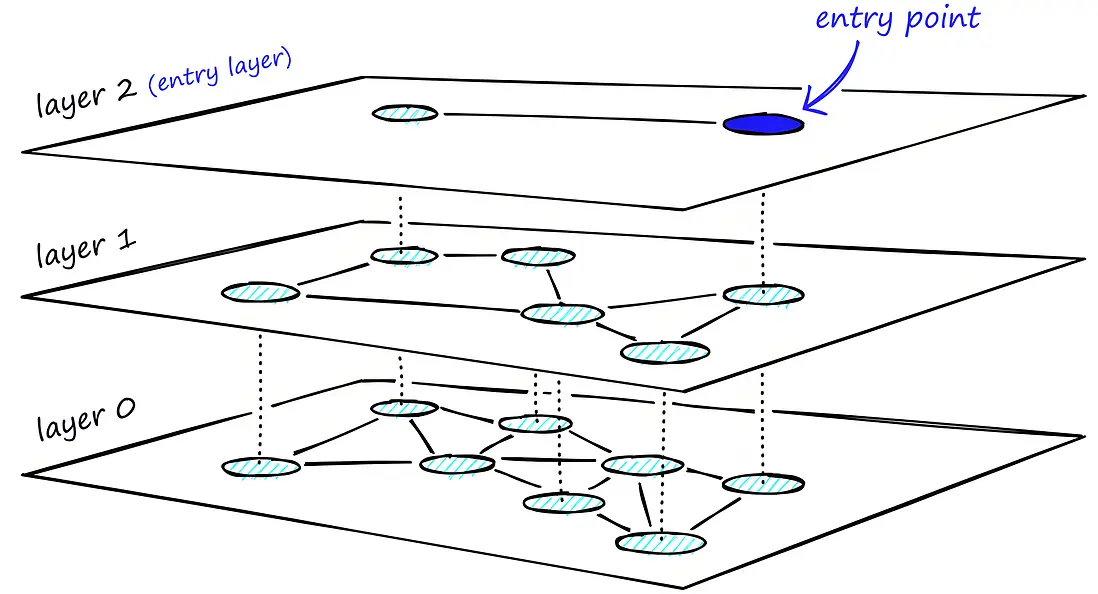
1.2. 分層
分層結構
- HNSW會把所有點隨機分配到不同的層,層數服從指數分佈(層數越高,點越少)。
- 層0:所有數據點都在(最底層,最全)。
- 層1、2...:層數越高,點越少,只有部分點存在。
每層的連接方式
- 每層的點會與同層的若干最近鄰(如M個)建立連接,形成“小世界”結構。
- 高層(比如層2、3):點少,連接稀疏,覆蓋全局,便於快速跨越大範圍。
- 底層(層0):點多,連接密集,便於精細定位和局部查找。
層與層之間的關係
- 每個點只在自己被分配到的層及以下所有層出現。
- 比如,某點分配到層3,它就會在層0、1、2、3都存在,在更高層就不存在了。
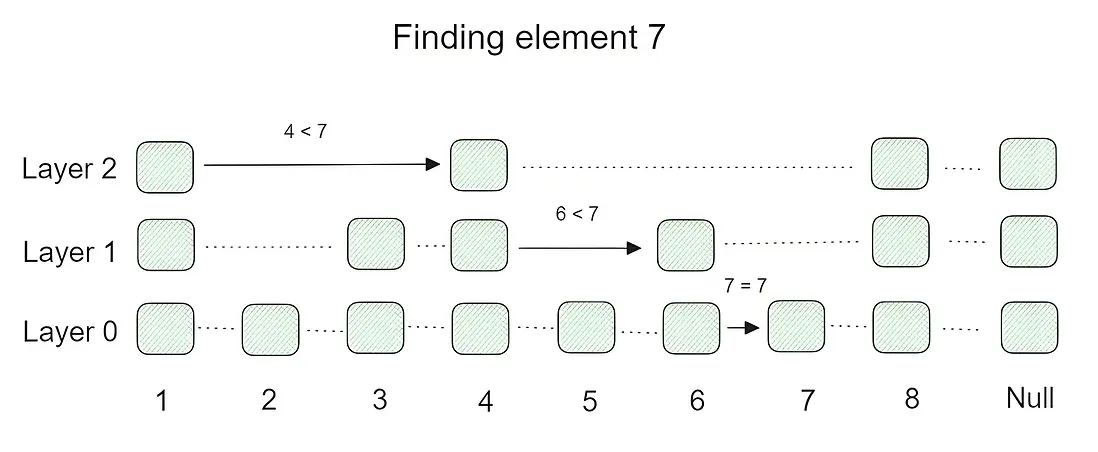
1.3. 查找過程
假設你要查找一個查詢向量q的最近鄰:
步驟1:從最高層開始
- 任選最高層的一個點(通常是最新插入的最高層點)作為起點。
- 在這一層,遍歷當前點的鄰居,只要有更近的點就跳過去,直到找不到更近的鄰居為止(即局部最優)。
步驟2:逐層向下導航
- 到達當前層的局部最優點後,下降到下一層,把上層找到的點作為下層的起點。
- 在下層重複上面的搜索過程,繼續尋找更近的鄰居。
- 層層遞進,直到最底層(層0)。
步驟3:底層精細搜索
- 到達層0後,一般會用更大的候選集(比如堆/隊列)做擴展搜索,以保證查找精度。
- 通過訪問鄰居,維護一個候選集,不斷更新,直到滿足停止條件(如訪問次數上限,或沒有更近的點)。
1.4. Milvus 索引示例
創建索引示例:
from pymilvus import MilvusClient
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="HNSW", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={
"M": 64, # Maximum number of neighbors each node can connect to in the graph
"efConstruction": 100 # Number of candidate neighbors considered for connection during index construction
} # Index building params
)
參數説明:
- metric_type:度量方式,可選項通常有:
COSINE(餘弦相似度)、IP(內積)、L2(歐式距離) -
M:
- 含義: 每個節點(向量)在圖中可以連接的最大鄰居數(通常是最底層)。
-
作用:
- 在構建 HNSW 圖時,
M決定了每個節點可以連接的最大鄰居數量。 - 較大的
M值會使得圖的連通性更好,從而提升搜索的準確性,但同時會增加索引的存儲需求和構建時間。
- 較小的
M值會減少索引大小和構建時間,但可能會降低搜索的準確性。
- 在構建 HNSW 圖時,
- 推薦值: 根據經驗,
M的值通常設置在 12 到 64 之間。
-
efConstruction:
- 含義: 構建索引時,每次插入一個節點時考慮的候選鄰居數(每一層)。
-
作用:
- 在 HNSW 索引的構建過程中,每插入一個節點,算法會嘗試找到最合適的鄰居來連接。
efConstruction決定了在搜索候選鄰居時的搜索範圍。 - 較大的
efConstruction值會提高索引構建的質量,從而提升搜索準確性,但也會增加索引構建時間。 - 較小的
efConstruction值會減少構建時間,但可能會降低搜索的準確性。
- 在 HNSW 索引的構建過程中,每插入一個節點,算法會嘗試找到最合適的鄰居來連接。
- 推薦值: 一般設置為 2 到 200 之間。
efConstruction的值通常大於或等於M。
2. IVF 倒排文件索引
2.1. 定義
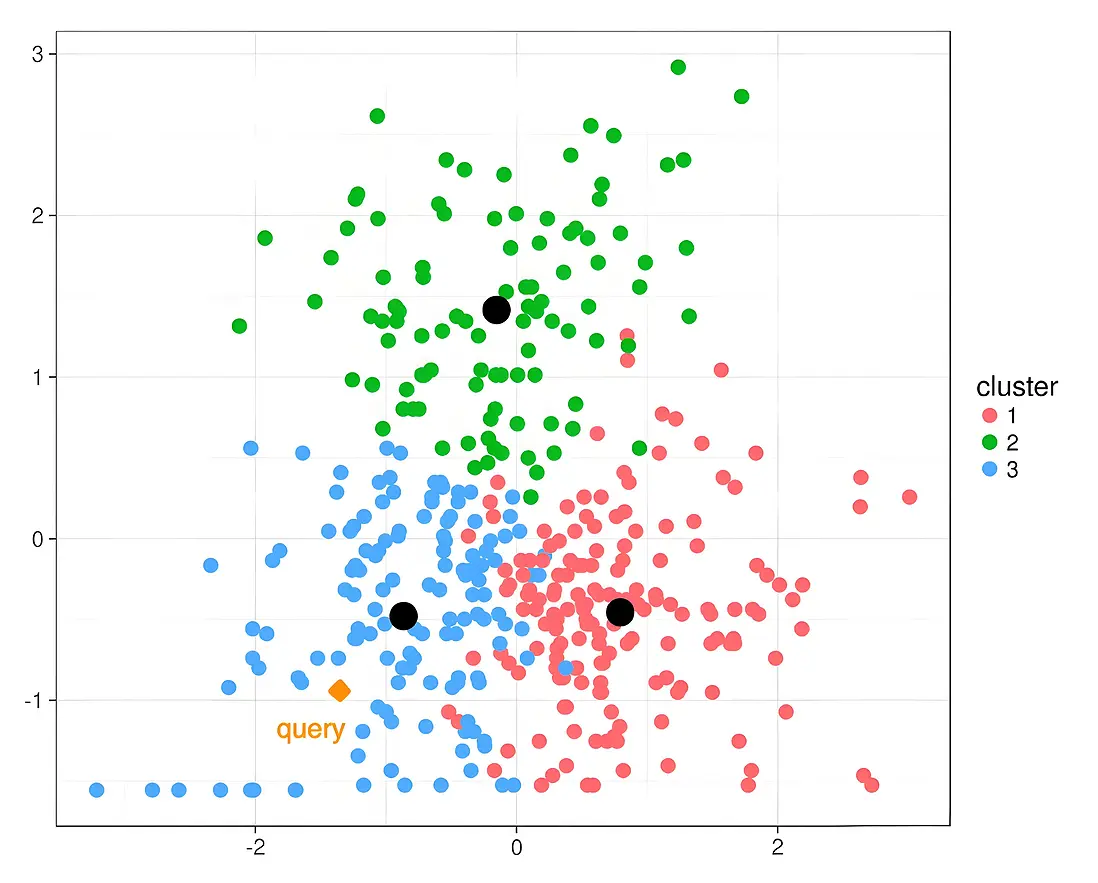
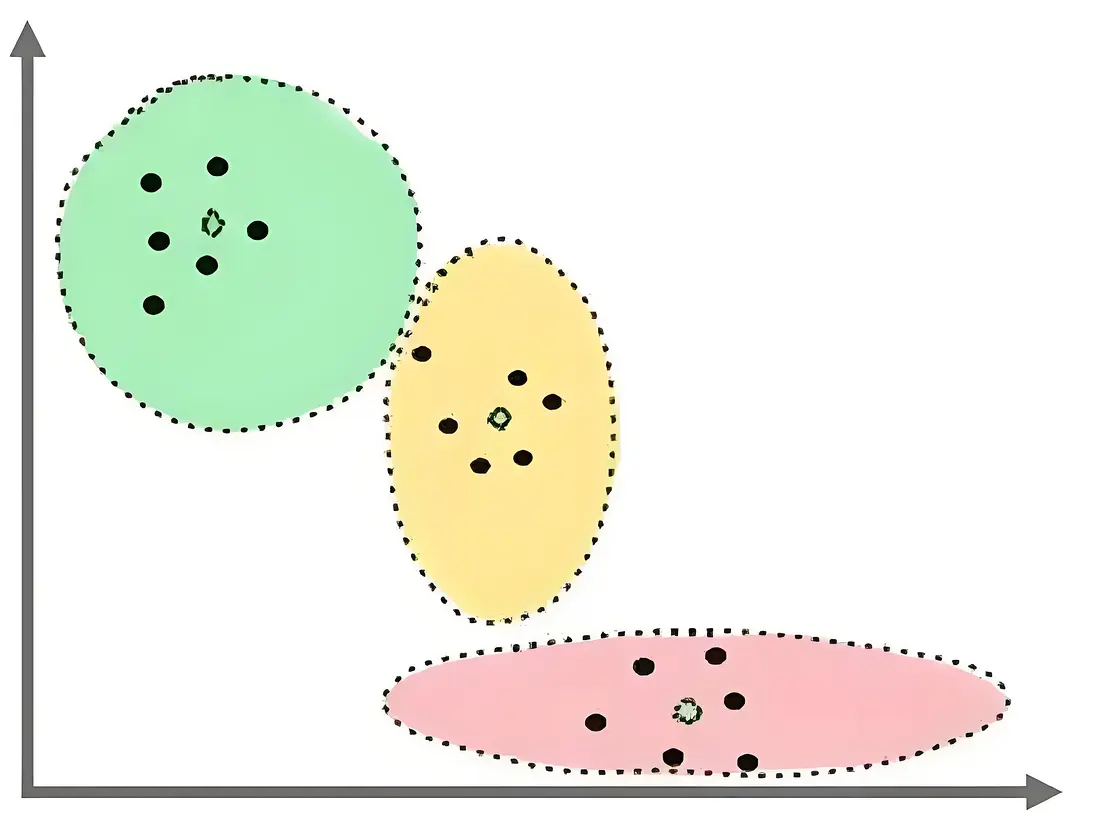
IVF(Inverted File Index,倒排文件索引)的核心是通過數據分簇和倒排索引結合,減少搜索範圍,從而提升檢索效率。其核心步驟包括:
- 聚類:使用k-means等算法將數據集劃分為nlist個簇,每個簇的中心稱為質心(Centroid)。
- 倒排列表:對每個向量計算其與所有質心的距離,將其分配到最近的簇,建立倒排列表:
{簇ID: [向量1, 向量2, ...]}。 - 近鄰搜索時,僅搜索與查詢向量最相關的少數簇,避免全局遍歷
2.2. 檢索流程
粗搜索
- 計算查詢向量與所有質心的距離,選擇最近的nprobe個簇。
- nprobe是控制搜索範圍的超參數,越大召回率越高,但速度越慢。
精細搜索
- 在選中的nprobe個簇內,遍歷所有向量,計算與查詢向量的距離。
- 返回Top-K最近鄰結果。
2.3. Milvus 索引示例
創建索引示例:
from pymilvus import MilvusClient
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="IVF_FLAT", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={
"nlist": 64, # Number of clusters for the index
} # Index building params
)
參數説明:
- metric_type:度量方式,可選項通常有:
COSINE(餘弦相似度)、IP(內積)、L2(歐式距離) -
nlist:
-
聚類數量:
nlist決定了數據被分成多少個簇。- 每個簇的向量數量大致為
總數據量 / nlist。
-
搜索範圍:
- 在查詢時,算法會選擇一定數量的簇進行搜索(通過參數
nprobe控制)。 - 如果
nlist設置得過小,每個簇可能包含太多向量,導致搜索效率和準確性降低。 - 如果
nlist設置得過大,索引構建時間和存儲開銷會增加。
- 在查詢時,算法會選擇一定數量的簇進行搜索(通過參數
-
如果數據集較小(幾千到幾萬條向量):
- 設置一個較小的
nlist值,例如 64 或 128。 - 這樣可以快速構建索引,並且查詢時仍能保持較高的準確性。
- 設置一個較小的
-
如果數據集較大(百萬級以上):
- 設置一個較大的
nlist值,例如 1024 或 4096。 - 這樣可以更好地劃分數據,提高查詢的準確性。
- 設置一個較大的
-
3. 局部敏感哈希 LSH
3.1. 定義
局部敏感哈希(Locality Sensitive Hashing,LSH)是一種通過哈希函數對高維數據進行分區,從而實現高效相似性搜索的技術。
LSH的核心在於設計特殊的哈希函數,使得相似的數據點傾向於被分配到相同的哈希桶中,減少搜索範圍。
在數學上,LSH通過概率保證以下性質:
- 相似的點有較高的概率映射到相同的哈希桶。
- 不相似的點有較低的概率映射到相同的哈希桶。
LSH通常基於特定距離度量(如歐氏距離或餘弦相似度)設計哈希函數。
隨機生成超平面,用於劃分向量空間。通過投影結果的正負值生成二進制哈希值。
3.2. 示例
通過5個二維座標系的示例看看。查詢點Q:(2, 3),目標是找到離它最近的點。
分界線
我們選擇兩條分界線作為哈希函數,每條線將空間分為兩個區域(0或1)。
| 哈希函數 | 分界線方程 | 規則(點在線上方=1,否則=0) |
|---|---|---|
| h₁ | y = x | 例如:點(1,3) → 3>1 → 哈希值1 |
| h₂ | y = 2x - 1 | 例如:點(2,2) → 2>3 → 哈希值0 |
用哈希函數分桶
將每個數據點通過h₁和h₂映射到哈希值,並分桶。
| 點 | 座標 | h₁(y=x) | h₂(y=2x-1) | 哈希組合(h₁,h₂) |
|---|---|---|---|---|
| A | (1,3) | 1 | 3 > 1 → 1 | (1,1) |
| B | (2,2) | 0 | 2 > 3 → 0 | (0,0) |
| C | (3,4) | 1 | 4 > 5 → 0 | (1,0) |
| D | (6,5) | 0 | 5 > 11 → 0 | (0,0) |
| E | (5,7) | 1 | 7 > 9 → 0 | (1,0) |
哈希表構建
-
哈希表1(h₁):根據h₁分桶
- 桶1:A, C, E
- 桶0:B, D
-
哈希表2(h₂):根據h₂分桶
- 桶1:A
- 桶0:B, C, D, E
查詢點Q的哈希計算
查詢點Q=(2,3)的哈希值:
- h₁(Q):3 > 2 → 1
- h₂(Q):3 > 3(2*2-1=3) → 0(等於線時通常歸為0)
- 哈希組合:(1,0)
多哈希表檢索
在兩個哈希表中分別查找Q所在的桶:
- 哈希表1(h₁=1):桶1 → 候選點A, C, E
- 哈希表2(h₂=0):桶0 → 候選點B, C, D, E
4. 向量數據庫
4.1. Cherry Studio
不少人應該用過 Cherry Studio 的知識庫,需要提前維護嵌入模型,可以往知識庫中上傳文件,或者粘貼網頁地址。
然後就可以在知識庫內檢索相似語義的內容了,在和大模型的聊天中也可以基於該知識庫進行RAG檢索。
往知識庫上傳文件或粘貼網址時,就是通過ETL通道,藉助嵌入模型進行向量化。當文件右側的綠色圖標亮了後,就是已經完成向量化,並將多維向量成功存儲到向量數據庫。
Cherry Studio 的向量數據庫使用 libsql,基於 SQLite 分支開發的嵌入數據庫。擴展了一些更方便向量計算的數據類型和函數等。
雖然性能上不如主流的向量數據庫,但作為嵌入數據庫,更適合在 Cherry Studio 這種客户端應用中使用。
具體可以查看 Cherry Studio 知識庫WIKI 。
以mac電腦為例,向量數據庫文件在 ~/Library/Application Support/CherryStudio/Data/KnowledgeBase/ 目錄下。
可以 通過 SQLite 客户端打開,我是用 VS Code 的 SQLite Viewer 插件查看,表結構如下:
CREATE TABLE vectors (
id TEXT PRIMARY KEY,
pageContent TEXT UNIQUE,
uniqueLoaderId TEXT NOT NULL,
source TEXT NOT NULL,
vector F32_BLOB (2048),
metadata TEXT
)4.2. Milvus
Milvus 作為主流的向量數據庫,根據數據量級、檢索性能、匹配精度等不同場景要求。
可以自由選擇多種數據類型、度量方式、索引類型等進行組合。
各精度 數據類型
僅以稠密向量 float 存儲為例,當數據量大時,可以犧牲部分精度。
| 類型 | 每元素字節 | 精度 | 存儲佔用 | 計算速度 | 兼容性/支持度 | 典型用途 |
|---|---|---|---|---|---|---|
| float32 | 4 | 高 | 中 | 快 | 極高 | 主流檢索、AI嵌入 |
| float64 | 8 | 最高 | 高 | 慢 | 低 | 科研/高精度運算 |
| float16 | 2 | 低~中 | 低 | 很快 | 低 | GPU推理/特定加速 |
| int8/uint8 | 1 | 低 | 極低 | 極快 | 高(索引壓縮) | 大規模壓縮檢索 |
各壓縮級別 索引
針對稠密向量,主要支持:HNSW、IVF索引。
下面僅以 IVF 索引為例,HNSW 也有對應壓縮變種。
| 索引類型 | 存儲佔用 | 檢索精度 | 檢索速度 | 適用數據規模 | 典型場景 |
|---|---|---|---|---|---|
| IVF_FLAT | 大 | 高 | 中 | 萬~百萬 | 精度優先,小中規模 |
| IVF_SQ8 | 較小 | 中高 | 較快 | 十萬~千萬 | 存儲有限,速度需提升 |
| IVF_PQ | 很小 | 中 | 快 | 百萬~億級 | 海量數據,速度存儲優先 |
| IVF_RABITQ | 極小 | 中高 | 很快 | 千萬~億級 | 超大數據,精度和速度兼顧 |
選擇度量方式
在創建索引時,需要指定度量方式。稠密向量默認度量方式都是餘弦相似度。
from pymilvus import MilvusClient
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="HNSW", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={
"M": 64, # Maximum number of neighbors each node can connect to in the graph
"efConstruction": 100 # Number of candidate neighbors considered for connection during index construction
} # Index building params
)
具體使用方式就不多説了,可以看 Milvus 官網WIKI

