

在這個信息爆炸的時代,我們似乎習慣了把數據交給雲端。
但作為一名開發者,當涉及到敏感的會議記錄、私人語音筆記時,我總是心存顧慮:
有沒有可能打造一個完全離線、跑在瀏覽器裏、且終身免費的AI會議助手?
面對複雜的 WebAssembly、模型量化、多線程調度,作為一個非專業的開發者,我通常需要幾周來啃文檔。
但這一次,在文心快碼(Comate) 的協助下,我僅用2小時就完成了這個會議助手的全棧開發。
00|項目背景:開發一個隱私優先的會議助手
市面上的會議記錄軟件確實好用,但它們有兩個致命弱點:
- 隱私黑盒:數據必須上傳雲端,對於公司內部機密或個人隱私內容,這始終是個隱患。
- 依賴網絡:在高鐵、飛機或網絡不佳的環境下,這些工具直接“變磚”。
因此,我想基於開源社區最火的 Whisper(語音識別)和一個能夠本地化部署的大語言模型,開發一個純前端、零服務端、完全離線的 Web 應用。要求如下:
- 隱私絕對安全:斷網也能用,數據不出本地。
- 零成本:不花錢買 Token,不買服務器。
- 體驗要絲滑:不能因為跑模型把瀏覽器卡死。
我不熟悉 WebAssembly,也沒搞過模型量化。如果純手寫,光環境配置就十分勸退。於是,我直接把難題拋給了我的專屬 AI 工程師——文心快碼(Comate) 。
01|架構設計
我沒有直接開始寫代碼,而是先向Plan智能體拋出了我的想法。
點擊對話窗口左下角,即可切換不同子智能體⬆️
然後,用自然語言給出需求。
我想做一個完全離線的AI會議助手,給我一個可行的技術方案。
Plan智能體迅速扮演了架構師的角色,1分鐘內就為我輸出了一份詳細的技術選型與可行性分析:
# 技術選型與可行性分析報告
## 1. 核心引擎選型
**推薦方案:Transformers.js + ONNX Runtime Web**
理由:這是 Hugging Face 的官方 JS 實現,支持直接在瀏覽器端運行 .wasm 格式的深度學習模型。
## 2. 關鍵架構建議
⚠️ **風險預警:** AI 推理是計算密集型任務,如果在主線程運行,會導致 UI 界面完全凍結(假死)。
**解決方案:** 必須採用 Web Worker 架構。將 AI 模型加載和推理邏輯完全隔離在後台線程,通過 postMessage 與主界面通信。
## 3. 模型演進路線
**Phase 1 (驗證):** 使用 Xenova/whisper-tiny (約 40MB)。速度快,但中文識別可能出現幻覺(如輸出繁體或亂碼)。
**Phase 2 (生產):** 升級為 Xenova/whisper-small (約 240MB)。中文準確率不僅大幅提升,且支持自動標點。
## 4. 數據流設計
```
Input (MP3/WAV) -> AudioContext (重採樣至 16kHz) -> Web Worker -> Whisper Model -> Text/Timestamps
```
## 5. 技術實施計劃
### 階段一:基礎架構搭建
- [ ] 搭建 Web Worker 通信框架
- [ ] 實現音頻文件處理和重採樣邏輯
- [ ] 集成 Transformers.js 庫
### 階段二:核心功能開發
- [ ] 實現 whisper-tiny 模型加載和語音識別
- [ ] 開發時間戳生成功能
- [ ] 構建主界面與 Worker 通信機制
### 階段三:優化升級
- [ ] 升級到 whisper-small 模型
- [ ] 優化中文識別準確率
- [ ] 添加自動標點功能
### 階段四:生產部署
- [ ] 性能測試和優化
- [ ] 錯誤處理和用户體驗優化
- [ ] 生產環境部署
## 6. 風險評估與應對
| 風險類型 | 風險描述 | 應對措施 |
|---------|---------|---------|
| 性能風險 | 模型推理導致界面凍結 | Web Worker 隔離,進度反饋 |
| 兼容性風險 | 瀏覽器對 WebAssembly 支持不一 | 漸進式降級,兼容性檢測 |
| 模型風險 | 中文識別準確率不足 | 模型升級,後處理優化 |
| 網絡風險 | 模型下載失敗或緩慢 | 本地緩存,CDN 加速 |
## 7. 成功指標
- ✅ 語音識別準確率 > 85%
- ✅ 界面響應時間 < 100ms
- ✅ 模型加載時間 < 30秒
- ✅ 支持主流音頻格式
- ✅ 跨瀏覽器兼容性⬆️這份文檔清晰地規劃了:
- 核心引擎:推薦使用 Transformers.js,這是 Hugging Face 的 JS 版本,支持在瀏覽器端運行 Whisper。
- 架構建議:為了防止 AI 推理卡死主線程,必須使用 Web Worker 進行多線程隔離。
- 模型選擇:建議起步使用 whisper-tiny 驗證流程,後期升級為 whisper-small 提升中文準確率。
這份報告直接幫我省去了至少 3 天的調研+學習時間,並且讓我瞬間理清思路:這事能做,而且路徑很清晰。
02|產品開發與功能迭代
我與Comate共進行了5次交互,迭代了3個版本。
🐒 初始版本:能跑,但“胡言亂語”
萬事開頭難,第一步是讓瀏覽器“聽懂”人話。為了追求速度,我們用了 whisper-tiny 模型。
幫我搭建項目骨架。我需要一個 Web Worker 腳本來獨立運行 whisper-tiny 模型,主界面負責上傳音頻。Whisper 模型對音頻採樣率要求很嚴格,必須處理好。
Zulu智能體秒生成了 worker.js 的核心邏輯,並特別貼心地實現了一個單例模式,防止重複點擊導致內存爆炸。
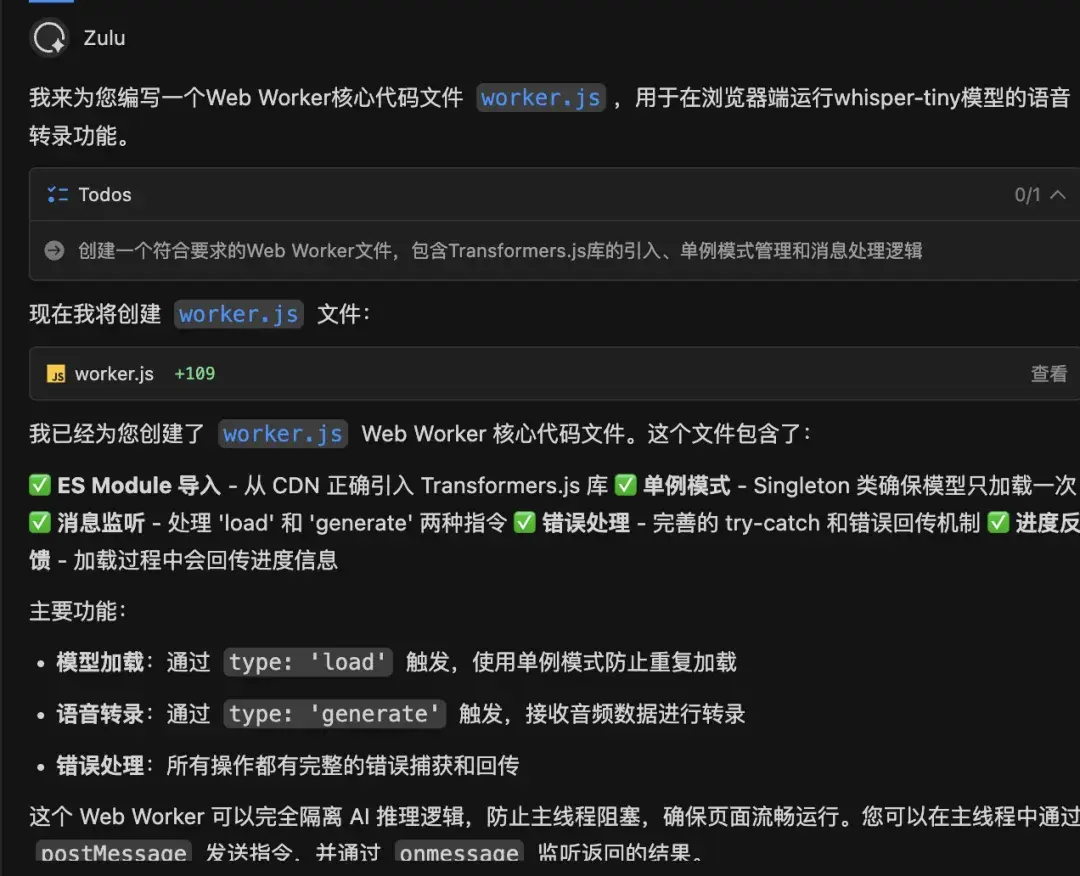
在處理音頻採樣率這個“大坑”時,Comate 自動編寫了一段基於 OfflineAudioContext 的重採樣代碼,將任意格式的音頻(MP3/M4A)強制轉換為模型所需的 16000Hz。
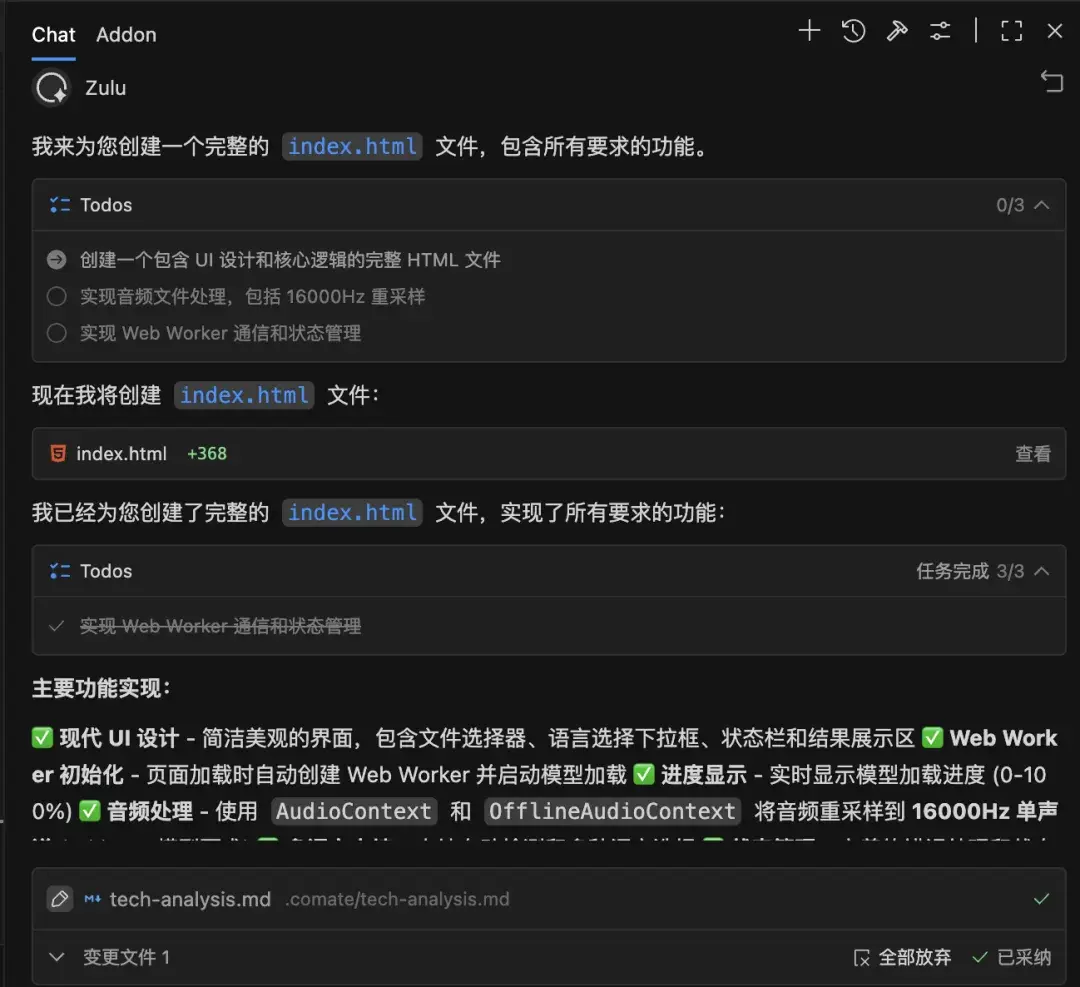
在初次運行時,我遇到了經典的“UI 假死”問題,進度條也不動。
直接用大白話向Code Review智能體提問即可:
界面沒反應,控制枱報錯 Cannot read properties of null怎麼辦
Code Review立即發現,是因為我在更新狀態文字時,不小心覆蓋了進度條的 DOM 節點。它立刻給出了修復方案,將文字和進度條的 DOM 結構分離。

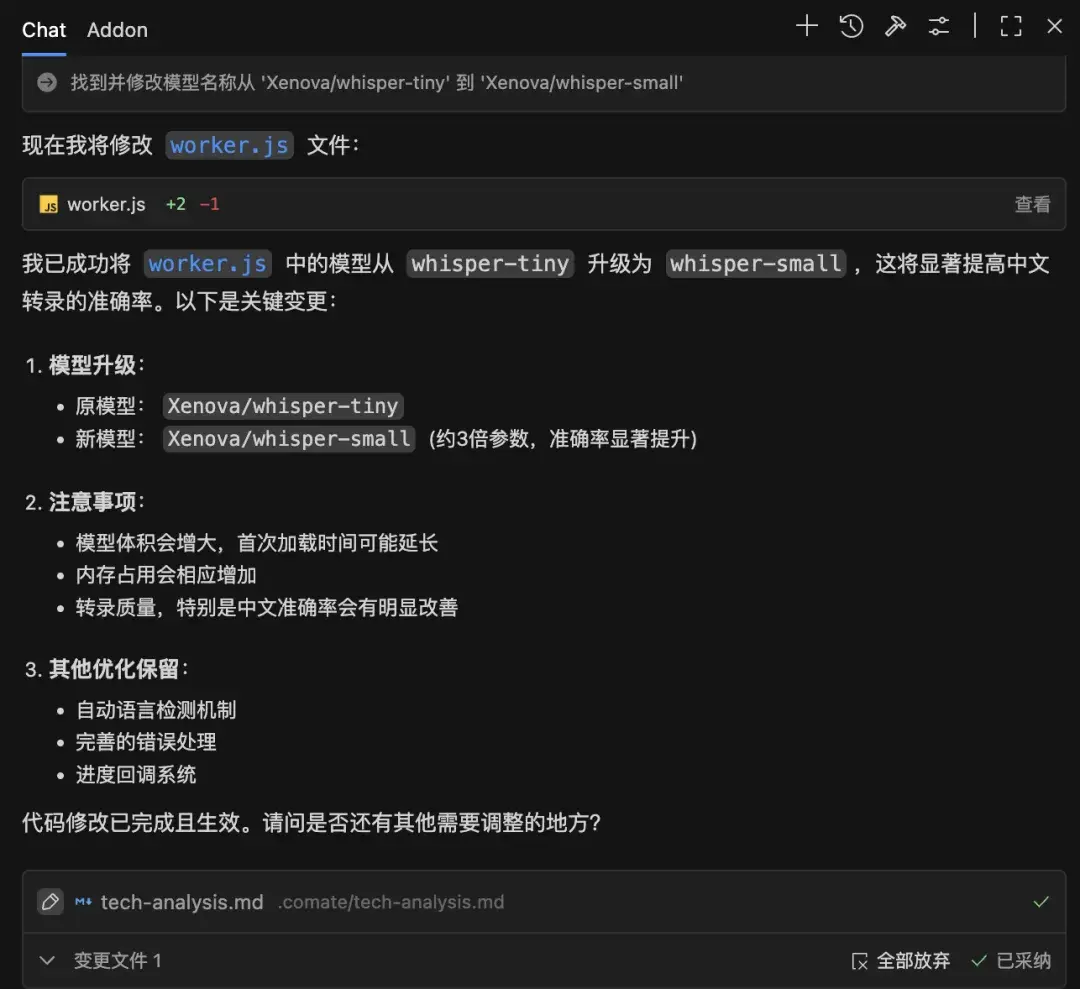
whisper-tiny能跑通之後,我讓Zulu幫我把模型從 whisper-tiny 升級為 whisper-small,顯著提高了中文轉錄的準確率。
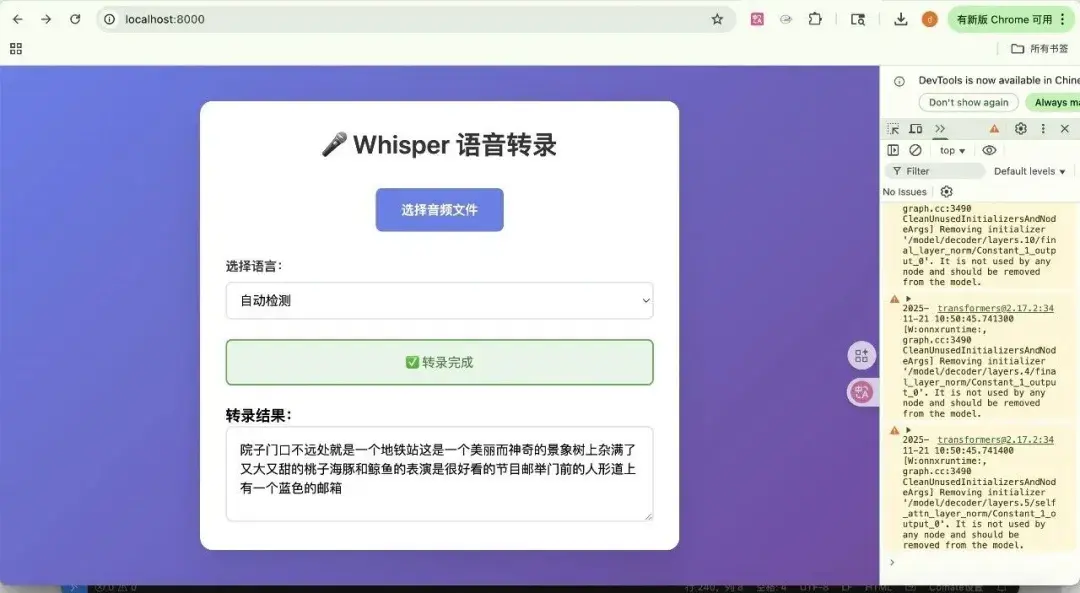
至此,我的應用已經能把聲音轉成文字了,雖然只是一大段純文本。
🤯交互重構:實現音文同步
面對屏幕上密密麻麻的文字,我提出了更高的要求。
現在的純文本太難閲讀了。我希望實現以下效果:
文字要按時間戳分段顯示。
點擊某一段文字,音頻自動跳到對應位置播放。
播放時,文字要高亮跟隨。
Comate 重新設計了 worker.js 的返回數據結構,開啓了 return_timestamps: true 選項,不僅返回文字,還返回了每一句話的 [開始時間, 結束時間]。
// [worker.js] 開啓時間戳與語言鎖定
const transcriptionOptions = {
task: 'transcribe',
// 關鍵升級:開啓時間戳,返回 [start, end] 數據
return_timestamps: true,
chunk_length_s: 30,
...options
};接着,它重寫了前端渲染邏輯,生成了一個包含點擊事件的列表。當我再次運行項目,上傳一段測試錄音時,看着文字隨着聲音逐行高亮,那種專業產品的質感瞬間就出來了。
// [index.html] 渲染帶時間戳的字幕列表
renderTranscript(chunks) {
const container = document.getElementById('transcript');
const player = document.getElementById('audioPlayer');
container.innerHTML = '';
chunks.forEach(chunk => {
if (!chunk.text.trim()) return;
const div = document.createElement('div');
div.className = 'transcript-line';
const [start, end] = chunk.timestamp; // 獲取時間戳
// 顯示格式化的時間標籤
div.innerHTML = `<span class="timestamp">[${this.fmtTime(start)}]</span>${chunk.text}`;
// 核心交互:點擊文字,播放器跳轉到對應時間
div.onclick = () => {
player.currentTime = start;
player.play();
};
container.appendChild(div);
});
}此外,針對“中英文混雜”的問題,Comate 還建議我在代碼中增加語言鎖定的邏輯,防止模型把中文誤翻譯成英文。
// 語言鎖定邏輯:防止模型把中文誤翻譯成英文
if (transcriptionOptions.language === 'chinese') {
transcriptionOptions.language = 'zh'; // 強制使用 'zh' 代碼
}使用體驗如文章內視頻所示👉https://mp.weixin.qq.com/s/jjuWFmMG0IJR3M8x-JPdqg
🔽小tips:想讓Comate手把手教學代碼含義,可以點擊“代碼解釋”開啓哦
🤩注入靈魂:連接本地 AI 大腦
最後,我希望這個工具不僅能“聽”,還能“思考”。
我要引入一個本地的大語言模型,讓它幫我自動總結會議紀要和待辦事項。要求使用中文能力較好的大模型,且必須按需加載,不要一上來就下載幾百兆文件。
Comate 幫我進行了全棧升級:
1.雙模型調度:Comate 修改了後台架構,實現了聽覺模型和LLM的獨立加載邏輯。
// [worker.js] 雙模型獨立調度架構
self.addEventListener('message', async (event) => {
const { type, data } = event.data;
switch (type) {
case'load_asr':
// 僅加載聽覺模型 (Whisper),速度快
await handleLoadASR();
break;
case'load_llm':
// 用户點擊開關後,才加載大腦模型 (Qwen),按需佔用內存
await handleLoadLLM();
break;
case'generate':
await handleTranscription(data);
break;
case'summarize':
await handleSummarization(data);
break;
}
});2.Prompt 工程:Comate 甚至幫我內置了一套 Prompt:“你是一個專業的會議秘書,請提取摘要和 Todo...”,讓小模型也能輸出高質量結果。
// [worker.js] 內置 Prompt 工程
const messages = [
{
role: "system",
content: "你是一個專業的會議秘書。請根據以下會議記錄,提取核心摘要、關鍵點和待辦事項(Todo)。"
},
{ role: "user", content: text }
];
// 構建符合 Qwen 模型規範的提示詞格式
const prompt = `<|im_start|>system\n${messages[0].content}<|im_end|>\n<|im_start|>user\n${messages[1].content}<|im_end|>\n<|im_start|>assistant\n`;3.體驗優化:為了解決大模型文件過大導致進度條顯示 NaN% 的問題,Comate 編寫了防禦性代碼,並設計了一個優雅的“🧠 啓用 AI 大腦”開關。
// [worker.js] 進度條防禦性代碼
function createProgressCallback(modelName){
return (data) => {
let percent = 0;
if (data.total && data.loaded) {
percent = (data.loaded / data.total) * 100;
}
// 防禦性編程:如果算出來是 NaN (因為缺少 content-length),則設為 -1
if (isNaN(percent) || !isFinite(percent)) {
percent = -1;
}
self.postMessage({
status: 'progress',
progress: percent, // 前端根據 -1 顯示"下載中..."而非"NaN%"
message: percent >= 0
? `正在下載 ${modelName}: ${percent.toFixed(1)}%`
: `正在下載 ${modelName} (數據量較大)...`
});
};
}最後,為了驗證產品表現,我上傳了一段開源的胡言亂語測試音頻。
👇它竟然一本正經地為我總結出了“待辦事項:瞭解景點背景”,並且通過正則清洗技術,完美去除了模型原本輸出的 system/user 等亂碼標籤。
✨最後,讓我們一起驗收下,這個0代碼、0設計稿、1小時內開發出的小程序,究竟效果怎麼樣:
🔗實測效果,可以複製以下網址使用:https://chen-chen429.github.io/local-whisper-note/
03|總結與思考
在點擊 GitHub Pages 部署按鈕的那一刻,我意識到:開發者的門檻正在被重塑。
在這個項目中,文心快碼(Comate) 不僅僅是一個代碼補全工具,它實際上分飾了多個角色:
- 產品經理:幫我梳理“離線隱私”的產品定位。
- 架構師:幫我設計 Web Worker 多線程架構。
- 資深前端:幫我解決 AudioContext 重採樣和 DOM 操作的疑難雜症。
- AI 工程師:幫我搞定了模型量化加載和 Prompt 清洗。
通過與Comate的深度協作,我把原本需要一週調研+開發的“硬核技術需求”,壓縮到了 2 小時的落地實踐。
對於開發者而言,不再需要精通每一個領域的細枝末節(比如 WASM 的內存管理),我們只需要擁有清晰的邏輯和精準的表達。
未來,隨着 WebGPU 算力的進一步釋放,這個網頁完全可以進化為更強大的‘第二大腦’——它不僅能支持實時聲紋識別(區分是誰在説話),甚至能引入本地向量數據庫,讓用户直接與過去一年的所有會議記錄進行跨文檔對話......而這一切,依然不需要上傳哪怕 1KB 的數據到雲端。
擁抱Comate輔助開發,釋放你的創造力,從現在開始。
👇 別光心動,現在就上手開造!
一鍵下載 Comate,把你的腦洞變成現實
點我跳轉:https://comate.baidu.com/zh/download
方式一:下載Comate AI IDE,享受絲滑開發過程
方式二:在 VS Code 或 Jetbrains IDE 中搜索“文心快碼”插件,安裝即用
如果你也有一個想實現的點子
不妨下載文心快碼
讓它成為你的「專屬工程師」!
誰知道呢,下一個爆款應用
也許就誕生在你的一次嘗試中~