

作者:京東零售 王雷
1、Redis集羣方案比較
• 哨兵模式
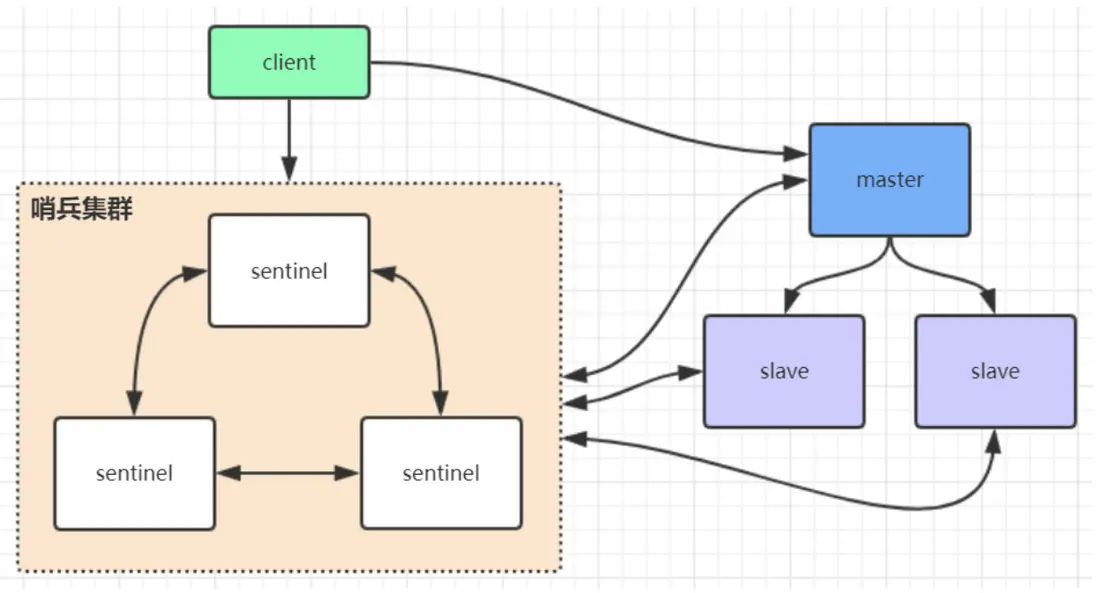
在redis3.0以前的版本要實現集羣一般是藉助哨兵sentinel工具來監控master節點的狀態,如果master節點異常,則會做主從切換,將某一台slave作為master,哨兵的配置略微複雜,並且性能和高可用性等各方面表現一般。
特別是在主從切換的瞬間存在訪問瞬斷的情況,而且哨兵模式只有一個主節點對外提供服務,沒法支持很高的併發,且單個主節點內存也不宜設置得過大,否則會導致持久化文件過大,影響數據恢復或主從同步的效率。
• 高可用集羣模式

redis集羣是一個由多個主從節點羣組成的分佈式服務器羣,它具有複製、高可用和分片特性。Redis集羣不需要sentinel哨兵也能完成節點移除和故障轉移的功能。
需要將每個節點設置成集羣模式,這種集羣模式沒有中心節點,可水平擴展,據官方文檔稱可以線性擴展到上萬個節點(官方推薦不超過1000個節點)。redis集羣的性能和高可用性均優於之前版本的哨兵模式,且集羣配置非常簡單。
2、Redis高可用集羣搭建
• redis集羣搭建
redis集羣需要至少三個master節點,我們這裏搭建三個master節點,並且給每個master再搭建一個slave節點,總共6個redis節點,這裏用三台機器部署6個redis實例,每台機器一主一從,搭建集羣的步驟如下:
第一步:在第一台機器的/usr/local下創建文件夾redis-cluster,然後在其下面分別創建2個文件夾如下
(1)mkdir -p /usr/local/redis-cluster
(2)mkdir 8001 8004
第二步:把之前的redis.conf配置文件copy到8001下,修改如下內容:
(1)daemonize yes
(2)port 8001(分別對每個機器的端口號進行設置)
(3)pidfile /var/run/redis_8001.pid # 把pid進程號寫入pidfile配置的文件
(4)dir /usr/local/redis-cluster/8001/(指定數據文件存放位置,必須要指定不同的目錄位置,不然會丟失數據)
(5)cluster-enabled yes(啓動集羣模式)
(6)cluster-config-file nodes-8001.conf(集羣節點信息文件,這裏800x最好和port對應上)
(7)cluster-node-timeout 10000
(8)# bind 127.0.0.1(bind綁定的是自己機器網卡的ip,如果有多塊網卡可以配多個ip,代表允許客户端通過機器的哪些網卡ip去訪問,內網一般可以不配置bind,註釋掉即可)
(9)protected-mode no (關閉保護模式)
(10)appendonly yes
如果要設置密碼需要增加如下配置:
(11)requirepass test (設置redis訪問密碼)
(12)masterauth test (設置集羣節點間訪問密碼,跟上面一致)
第三步:把修改後的配置文件,copy到8004,修改第2、3、4、6項裏的端口號,可以用批量替換:
:%s/源字符串/目的字符串/g
第四步:另外兩台機器也需要做上面幾步操作,第二台機器用8002和8005,第三台機器用8003和8006
第五步:分別啓動6個redis實例,然後檢查是否啓動成功
(1)/usr/local/redis-5.0.3/src/redis-server /usr/local/redis-cluster/800*/redis.conf
(2)ps -ef | grep redis 查看是否啓動成功
第六步:用redis-cli創建整個redis集羣(redis5以前的版本集羣是依靠ruby腳本redis-trib.rb實現)
# 下面命令裏的1代表為每個創建的主服務器節點創建一個從服務器節點
# 執行這條命令需要確認三台機器之間的redis實例要能相互訪問,可以先簡單把所有機器防火牆關掉,如果不關閉防火牆則需要打開redis服務端口和集羣節點gossip通信端口16379(默認是在redis端口號上加1W)
# 關閉防火牆
# systemctl stop firewalld # 臨時關閉防火牆
# systemctl disable firewalld # 禁止開機啓動
# 注意:下面這條創建集羣的命令大家不要直接複製,裏面的空格編碼可能有問題導致創建集羣不成功
(1)/usr/local/redis-5.0.3/src/redis-cli -a test --cluster create --cluster-replicas 1 192.168.0.61:8001 192.168.0.62:8002 192.168.0.63:8003 192.168.0.61:8004 192.168.0.62:8005 192.168.0.63:8006
第七步:驗證集羣:
(1)連接任意一個客户端即可:./redis-cli -c -h -p (-a訪問服務端密碼,-c表示集羣模式,指定ip地址和端口號)
如:/usr/local/redis-5.0.3/src/redis-cli -a test -c -h 192.168.0.61 -p 800*
(2)進行驗證: cluster info(查看集羣信息)、cluster nodes(查看節點列表)
(3)進行數據操作驗證
(4)關閉集羣則需要逐個進行關閉,使用命令:
/usr/local/redis-5.0.3/src/redis-cli -a test -c -h 192.168.0.60 -p 800* shutdown
3、Java操作redis集羣
藉助redis的java客户端jedis可以操作以上集羣,引用jedis版本的maven座標如下:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
Java編寫訪問redis集羣的代碼非常簡單,如下所示:
public class JedisClusterTest {
public static void main(String[] args) throws IOException {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(20);
config.setMaxIdle(10);
config.setMinIdle(5);
Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();
jedisClusterNode.add(new HostAndPort("192.168.0.61", 8001));
jedisClusterNode.add(new HostAndPort("192.168.0.62", 8002));
jedisClusterNode.add(new HostAndPort("192.168.0.63", 8003));
jedisClusterNode.add(new HostAndPort("192.168.0.61", 8004));
jedisClusterNode.add(new HostAndPort("192.168.0.62", 8005));
jedisClusterNode.add(new HostAndPort("192.168.0.63", 8006));
JedisCluster jedisCluster = null;
try {
//connectionTimeout:指的是連接一個url的連接等待時間
//soTimeout:指的是連接上一個url,獲取response的返回等待時間
jedisCluster = new JedisCluster(jedisClusterNode, 6000, 5000, 10, "zhuge", config);
System.out.println(jedisCluster.set("cluster", "test"));
System.out.println(jedisCluster.get("cluster"));
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedisCluster != null)
jedisCluster.close();
}
}
}
運行效果如下:
OK
test
集羣的Spring Boot整合Redis連接代碼見示例項目:redis-sentinel-cluster
1、引入相關依賴:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
springboot項目核心配置:
server:
port: 8080
spring:
redis:
database: 0
timeout: 3000
password: wl
cluster:
nodes: 192.168.0.61:8001,192.168.0.62:8002,192.168.0.63:8003,192.168.0.61:8004,192.168.0.62:8005,192.168.0.63:8006
lettuce:
pool:
max-idle: 50
min-idle: 10
max-active: 100
max-wait: 1000 訪問代碼:
@RestController
public class IndexController {
private static final Logger logger = LoggerFactory.getLogger(IndexController.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
@RequestMapping("/test_cluster")
public void testCluster() throws InterruptedException {
stringRedisTemplate.opsForValue().set("test", "666");
System.out.println(stringRedisTemplate.opsForValue().get("test"));
}
}
4、Redis集羣原理分析
Redis Cluster 將所有數據劃分為 16384 個 slots(槽位),每個節點負責其中一部分槽位。槽位的信息存儲於每個節點中。
當 Redis Cluster 的客户端來連接集羣時,它也會得到一份集羣的槽位配置信息並將其緩存在客户端本地。這樣當客户端要查找某個 key 時,可以直接定位到目標節點。同時因為槽位的信息可能會存在客户端與服務器不一致的情況,還需要糾正機制來實現槽位信息的校驗調整。
• 槽位定位算法
Cluster 默認會對 key 值使用 crc16 算法進行 hash 得到一個整數值,然後用這個整數值對 16384 進行取模來得到具體槽位。
HASH_SLOT = CRC16(key) mod 16384
• 跳轉重定位
當客户端向一個錯誤的節點發出了指令,該節點會發現指令的 key 所在的槽位並不歸自己管理,這時它會向客户端發送一個特殊的跳轉指令攜帶目標操作的節點地址,告訴客户端去連這個節點去獲取數據。客户端收到指令後除了跳轉到正確的節點上去操作,還會同步更新糾正本地的槽位映射表緩存,後續所有 key 將使用新的槽位映射表。

• Redis集羣節點間的通信機制
redis cluster節點間採取gossip協議進行通信
維護集羣的元數據(集羣節點信息,主從角色,節點數量,各節點共享的數據等)有兩種方式:集中式和gossip
• 集中式
優點在於元數據的更新和讀取,時效性非常好,一旦元數據出現變更立即就會更新到集中式的存儲中,其他節點讀取的時候立即就可以立即感知到;不足在於所有的元數據的更新壓力全部集中在一個地方,可能導致元數據的存儲壓力。 很多中間件都會藉助zookeeper集中式存儲元數據。
• gossip:
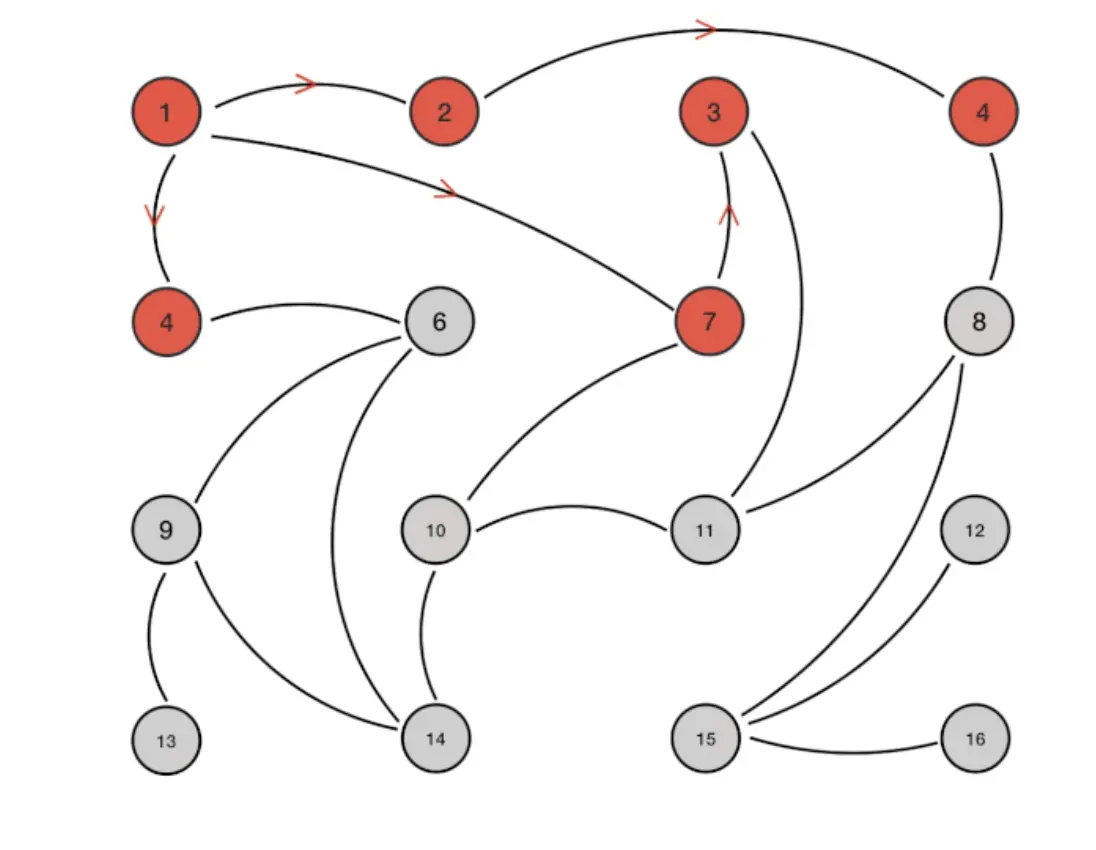
gossip協議包含多種消息,包括ping,pong,meet,fail等等。
1)meet:某個節點發送meet給新加入的節點,讓新節點加入集羣中,然後新節點就會開始與其他節點進行通信;
2)ping:每個節點都會頻繁給其他節點發送ping,其中包含自己的狀態還有自己維護的集羣元數據,互相通過ping交換元數據(類似自己感知到的集羣節點增加和移除,hash slot信息等);
3)pong: 對ping和meet消息的返回,包含自己的狀態和其他信息,也可以用於信息廣播和更新;
4)fail: 某個節點判斷另一個節點fail之後,就發送fail給其他節點,通知其他節點,指定的節點宕機了。
gossip協議的優點在於元數據的更新比較分散,不是集中在一個地方,更新請求會陸陸續續,打到所有節點上去更新,有一定的延時,降低了壓力;缺點在於元數據更新有延時可能導致集羣的一些操作會有一些滯後。
gossip通信的10000端口
每個節點都有一個專門用於節點間gossip通信的端口,就是自己提供服務的端口號+10000,比如7001,那麼用於節點間通信的就是17001端口。 每個節點每隔一段時間都會往另外幾個節點發送ping消息,同時其他幾點接收到ping消息之後返回pong消息。
• 網絡抖動
真實世界的機房網絡往往並不是風平浪靜的,它們經常會發生各種各樣的小問題。比如網絡抖動就是非常常見的一種現象,突然之間部分連接變得不可訪問,然後很快又恢復正常。
為解決這種問題,Redis Cluster 提供了一種選項cluster-node-timeout,表示當某個節點持續 timeout 的時間失聯時,才可以認定該節點出現故障,需要進行主從切換。如果沒有這個選項,網絡抖動會導致主從頻繁切換 (數據的重新複製)。
Redis集羣選舉原理分析
當slave發現自己的master變為FAIL狀態時,便嘗試進行Failover,以期成為新的master。由於掛掉的master可能會有多個slave,從而存在多個slave競爭成為master節點的過程, 其過程如下:
1)slave發現自己的master變為FAIL
2)將自己記錄的集羣currentEpoch加1,並廣播FAILOVER\_AUTH\_REQUEST 信息
3)其他節點收到該信息,只有master響應,判斷請求者的合法性,併發送FAILOVER\_AUTH\_ACK,對每一個epoch只發送一次ack
4)嘗試failover的slave收集master返回的FAILOVER\_AUTH\_ACK
5)slave收到超過半數master的ack後變成新Master(這裏解釋了集羣為什麼至少需要三個主節點,如果只有兩個,當其中一個掛了,只剩一個主節點是不能選舉成功的)
6)slave廣播Pong消息通知其他集羣節點。
從節點並不是在主節點一進入 FAIL 狀態就馬上嘗試發起選舉,而是有一定延遲,一定的延遲確保我們等待FAIL狀態在集羣中傳播,slave如果立即嘗試選舉,其它masters或許尚未意識到FAIL狀態,可能會拒絕投票
延遲計算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK表示此slave已經從master複製數據的總量的rank。Rank越小代表已複製的數據越新。這種方式下,持有最新數據的slave將會首先發起選舉(理論上)。
集羣腦裂數據丟失問題
redis集羣沒有過半機制會有腦裂問題,網絡分區導致腦裂後多個主節點對外提供寫服務,一旦網絡分區恢復,會將其中一個主節點變為從節點,這時會有大量數據丟失。
規避方法可以在redis配置里加上參數(這種方法不可能百分百避免數據丟失,參考集羣leader選舉機制):
min-replicas-to-write 1 //寫數據成功最少同步的slave數量,這個數量可以模仿大於半數機制配置,比如集羣總共三個節點可以配置1,加上leader就是2,超過了半數*注意:這個配置在一定程度上會影響集羣的可用性,比如slave要是少於1個,這個集羣就算leader正常也不能提供服務了,需要具體場景權衡選擇。
集羣是否完整才能對外提供服務
當redis.conf的配置
cluster-require-full-coverage為no時,表示當負責一個插槽的主庫下線且沒有相應的從庫進行故障恢復時,集羣仍然可用,如果為yes則集羣不可用。
Redis集羣為什麼至少需要三個master節點,並且推薦節點數為奇數?
因為新master的選舉需要大於半數的集羣master節點同意才能選舉成功,如果只有兩個master節點,當其中一個掛了,是達不到選舉新master的條件的。
奇數個master節點可以在滿足選舉該條件的基礎上節省一個節點,比如三個master節點和四個master節點的集羣相比,大家如果都掛了一個master節點都能選舉新master節點,如果都掛了兩個master節點都沒法選舉新master節點了,所以奇數的master節點更多的是從節省機器資源角度出發説的。
Redis集羣對批量操作命令的支持
對於類似mset,mget這樣的多個key的原生批量操作命令,redis集羣只支持所有key落在同一slot的情況,如果有多個key一定要用mset命令在redis集羣上操作,則可以在key的前面加上{XX},這樣參數數據分片hash計算的只會是大括號裏的值,這樣能確保不同的key能落到同一slot裏去,示例如下:
mset {user1}:1:name zhuge {user1}:1:age 18假設name和age計算的hash slot值不一樣,但是這條命令在集羣下執行,redis只會用大括號裏的 user1 做hash slot計算,所以算出來的slot值肯定相同,最後都能落在同一slot。
哨兵leader選舉流程
當一個master服務器被某sentinel視為下線狀態後,該sentinel會與其他sentinel協商選出sentinel的leader進行故障轉移工作。每個發現master服務器進入下線的sentinel都可以要求其他sentinel選自己為sentinel的leader,選舉是先到先得。同時每個sentinel每次選舉都會自增配置紀元(選舉週期),每個紀元中只會選擇一個sentinel的leader。如果所有超過一半的sentinel選舉某sentinel作為leader。之後該sentinel進行故障轉移操作,從存活的slave中選舉出新的master,這個選舉過程跟集羣的master選舉很類似。
哨兵集羣只有一個哨兵節點,redis的主從也能正常運行以及選舉master,如果master掛了,那唯一的那個哨兵節點就是哨兵leader了,可以正常選舉新master。
不過為了高可用一般都推薦至少部署三個哨兵節點。為什麼推薦奇數個哨兵節點原理跟集羣奇數個master節點類似。