









作者:京東物流 田禹
1 網絡爬蟲
網絡爬蟲:是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。
網絡爬蟲相關技術和框架繁多,針對場景的不同可以選擇不同的網絡爬蟲技術。
2 Scrapy框架(Python)
2.1. Scrapy架構
2.1.1. 系統架構
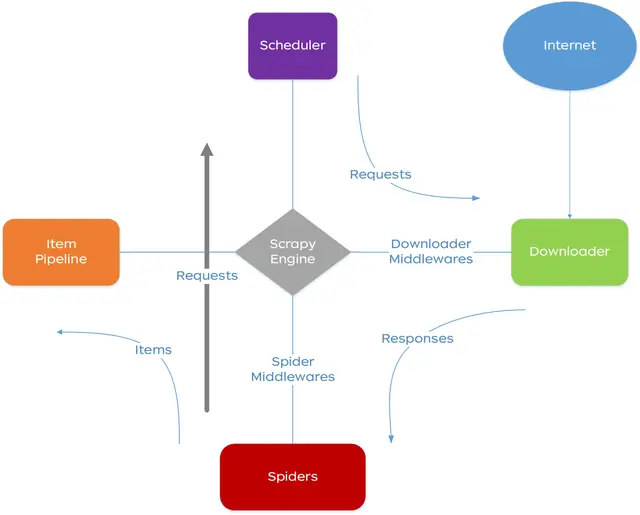
2.1.2. 執行流程
總結爬蟲開發過程,簡化爬蟲執行流程如下圖所示:

爬蟲運行主要流程如下:
(1) Scrapy啓動Spider後加載Spaider的start_url,生成request對象;
(2) 經過middleware完善request對象(添加IP代理、User-Agent);
(3) Downloader對象按照request對象下載頁面;
(4) 將response結果傳遞給spider的parser方法解析;
(5) spider獲取數據封裝為item對象傳遞給pipline,解析的request對象將返回調度器進行新一輪的數據抓取;
2.2. 框架核心文件介紹
2.2.1. scrapy.cfg
scrapy.cfg是scrapy框架的入口文件,settings節點指定爬蟲的配置信息,deploy節點用於指定scrapyd服務的部署路徑。
|
[settings]
default = sfCrawler.settings
[deploy]
url =http://localhost:6800/
project = jdCrawler
|
2.2.2. settings.py
settings主要用於配置爬蟲啓動信息,包括:併發線程數量、使用的middleware、items等信息;也可以作為系統中的全局的配置文件使用。
注:目前主要增加了redis、數據庫連接等相關配置信息。
2.2.3. middlewares.py
middleware定義了多種接口,分別在爬蟲加載、輸入、輸出、請求、請求異常等情況進行調用。
注:目前主要用户是為爬蟲增加User-Agent信息和IP代理信息等。
2.2.4. pipelines.py
用於定義處理數據的Pipline對象,scrapy框架可以在settings.py文件中配置多個pipline對象,處理數據的個過程將按照settings.py配置的優先級的順序順次執行。
注:系統中產生的每個item對象,將經過settings.py配置的所有pipline對象。
2.2.5. items.py
用於定義不同種數據類型的數據字典,每個屬性都是Field類型;
2.2.6. spider目錄
用於存放Spider子類定義,scrapy啓動爬蟲過程中將按照spider類中name屬性進行加載和調用。
2.3. 爬蟲功能擴展説明
2.3.1. user\_agents\_middleware.py
通過procces_request方法,為request對象添加hearder信息,隨機模擬多種瀏覽器的User-Agent信息進行網絡請求。
2.3.2. proxy_server.py
通過procces_request方法,為reques對象添加網絡代理信息,隨機模擬多IP調用。
2.3.3. db\_connetion\_pool.py
文件位置
db\_manager/db\_connetion_pool.py,文件定義了基礎的數據連接池,方便系統各環節操作數據庫。
2.3.4. redis\_connention\_pool.py
文件位置db\_manager/ redis\_connention_pool.py,文件定義了基礎的Redis連接池,方便系統各環節操作Redis緩存。
2.3.5. scrapy_redis包
scrapy_redis包是對scrapy框架的擴展,採用Redis作為請求隊列,存儲爬蟲任務信息。
spiders.py文件:定義分佈式RedisSpider類,通過覆蓋Spider類start\_requests()方法的方式,從Redis緩存中獲取初始請求列表信息。其中RedisSpider子類需要為redis\_key賦值。
pipelines.py文件:定義了一種簡單的數據存儲方式,可以直接將item對象序列化後保存到Redis緩存中。
dupefilter.py文件:定義數據去重類,採用Redis緩存的方式,已經保存的數據將添加到過濾隊列中。
queue.py文件:定義幾種不同的入隊和出隊順序的隊列,隊列採用Redis存儲。
2.4. 微博爬蟲開發示例
2.4.1. 查找爬蟲入口
2.4.1.1. 站點分析
網站一般會分為Web端和M端兩種,兩種站點在設計和架構上會有較大的差別。通常情況下Web端會比較成熟,User-Agent檢查、強制Cookie、登錄跳轉等限制,抓取難度相對較大,返回結果以HTML內容為主;M端站點通常採用前後端分離設計,大多提供獨立的數據接口。所以站點分析過程中優先查找M端站點入口。微博Web端及M端效果如圖所示:
微博Web端地址:https://weibo.com/,頁面顯示效果如下圖所示:
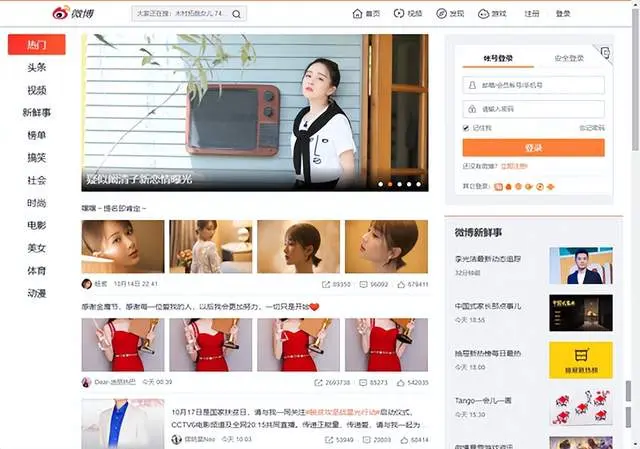
注:圖片來源於微博PC端截圖
微博M端地址:https://m.weibo.cn/?jumpfrom=weibocom,頁面顯示效果如下圖所示:
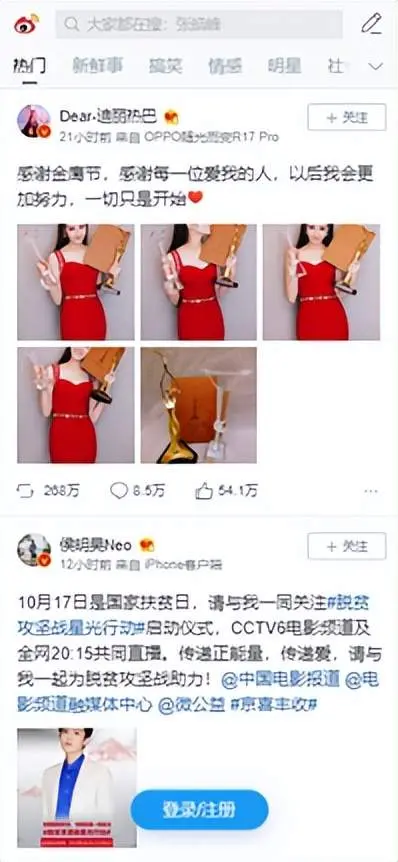
注:圖片來源於微博M端截圖
2.4.1.2. HTML源碼分析
Web端站點和M端站點返回結果都是HTML格式,部分站點為了提升頁面渲染速度,或者為了增加代碼分析難度,通過動態JavaScrip執行等方式,動態生成HTML頁面,網絡爬蟲缺少JS執行和渲染過程,很難獲取真實的數據,微博Web端站點HTML代碼片段如下所示:

腳本中的正文內容:

M端站點HTML內容:

M端HTML內容中並未出現頁面中的關鍵信息,可以判定為前後端分離的設計方式,通過Chrome瀏覽器開發模式,能夠查看所有請求信息,通過請求的類型和返回結果,基本可以確定接口地址,查找過程如下圖所示:
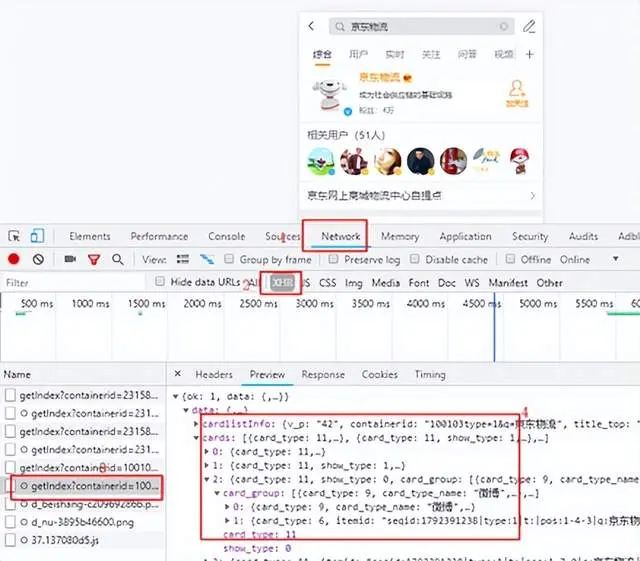
注:圖片來源於微博M端截圖
(1) 打開Chrome開發者工具,刷新當前頁面;
(2) 修改請求類型為XHR,篩選Ajax請求;
(3) 查看所有請求信息,忽略沒有返回結果的接口;
(4) 在接口返回結果中查找頁面中相關內容。
2.4.1.3. 接口分析
接口分析主要包括:請求地址分析、請求方式、參數列表、返回結果等。
請求地址、請求方式和參數列表可以根據Chrome開發人員工具中的網絡請求Header信息獲取,請求信息如下圖所示:
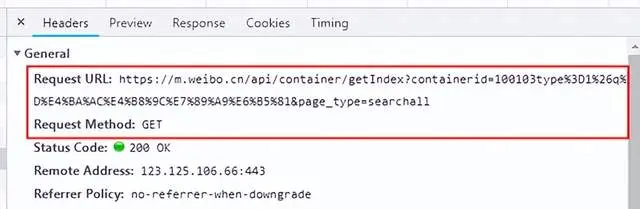
上圖中接口地址採用的是GET方式請求,請求地址是unicode編碼,參數內容可以查看Query String Parameters列表查看請求參數,效果如下圖所示:

請求結果分析主要分析數據結構的特點,查找與正文內容相同的數據結構,同時要檢查所有結果是否與正文內容一致,避免特殊返回結果影響數據解析過程。
2.4.1.4. 接口驗證
接口驗證一般需要兩個步驟:
(1)用瀏覽器(最好是新開瀏覽器,如Chrome的隱身模式)模擬請求過程,在地址欄中輸入帶有參數的請求地址查看返回結果。
(2)採用Postman等工具模擬瀏覽器請求過程,主要模擬非Get方式的網絡請求,同樣也可以驗證站點是否強制使用Cookie和User-Agent信息等。
2.4.2. 定義數據結構
爬蟲數據結構定義主要結合業務需求和數據抓取的結果進行設計,微博數據主要用户國內的輿情繫統,所以在開發過程中將相關站點的數據統一定義為OpinionItem類型,在不同站點的數據保存過程中,按照OpinionItem數據結構的特點裝配數據。在items.py文件中定義輿情數據結構如下所示:
class OpinionItem(Item):
rid = Field()
pid = Field()
response_content = Field() # 接口返回的全部信息
published_at = Field() # 發佈時間
title = Field() # 標題
description = Field() # 描述
thumbnail_url = Field() # 縮略圖
channel_title = Field() # 頻道名稱
viewCount = Field() # 觀看數
repostsCount = Field() # 轉發數
likeCount = Field() # 點贊數
dislikeCount = Field() # 不喜歡數量
commentCount = Field() # 評論數
linked_url = Field() # 鏈接
updateTime = Field() # 更新時間
author = Field() # 作者
channelId = Field() # 渠道ID
mediaType = Field() # 媒體類型
crawl_time = Field() # 抓取時間
type = Field() # 信息類型:1 主貼 2 主貼的評論2.4.3. 爬蟲開發
微博爬蟲採用分佈式RedisSpider作為父類,爬蟲定義如下所示:
class weibo_list(RedisSpider):
name = 'weibo'
allowed_domains = ['weibo.cn']
redis_key = 'spider:weibo:list:start_urls'
def parse(self, response):
a = json.loads(response.body)
b = a['data']['cards']
for j in range(len(b)):
bb = b[j]
try:
for c in bb['card_group']:
try:
d = c['mblog']
link = 'https://m.weibo.cn/api/comments/show?id={}'.format(d['mid'])
# yield scrapy.Request(url=link, callback=self.parse_detail)
# 內容解析代碼片段
opinion['mediaType'] = 'weibo'
opinion['type'] = '1'
opinion['crawl_time'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
yield opinion
except Exception as e:
print(e)
continue
except Exception as e:
print(e)
continue代碼解析:
代碼行1:定義weibo_list類,繼承RedisSpider類;
代碼行2:定義爬蟲名稱,爬蟲啓動時使用;
代碼行3:增加允許訪問的地址域名列表;
代碼行4:定義微博開始請求地址的redis key;
代碼行6:定義爬蟲的解析方法,爬蟲下載頁面後默認調用parser方法;
代碼行7~21:將下載結果內容解析後裝配到item對象中;
代碼行22:通過yield關鍵字,生成Python特有的生成器對象,調用者可以通過生成器對象遍歷所有結果。
2.4.4. 數據存儲
數據存儲主要通過定義Pipline實現類,將爬蟲解析的數據進行保存。微博數據需要增加進行情感分析的加工過程,開發過程中首先將微博數據保存到Redis服務中,通過後續的情感分析解析服務獲取、加工,並保存到數據庫中。數據保存代碼如下所示:
class ShunfengPipeline(object):
def process_item(self, item, spider):
if isinstance(item, OpinionItem):
try:
print('===========Weibo查詢結果============')
key = 'spider:opinion:data'
dupe = 'spider:opinion:dupefilter'
attr_list = []
for k, v in item.items():
if isinstance(v, str):
v = v.replace('\'', '\\\'')
attr_list.append("%s:'%s'" % (k, v))
data = ",".join(attr_list)
data = "{%s}" % data
# 按照數據來源、類型和唯一id作為去重標識
single_key = ''.join([item['mediaType'], item['type'], item['rid']])
if ReidsPool().rconn.execute_command('SADD', dupe, single_key) != 0:
ReidsPool().rconn.execute_command('RPUSH', key, data)
except Exception as e:
print(e)
pass
return item關鍵代碼説明:
代碼行1:定義Pipline類;
代碼行2:定義process_item方法,用於接收數據;
代碼行3:按照Item類型分別處理;
代碼行4~17:Item對象拼裝為JSON字符串;
代碼行18~21:對數據進行去重校驗,並將數據保存到redis隊列中;
代碼行26:返回item對象供其他Pipline操作;
Pipline定義完成後,需要在工程中的settings.py文件中進行配置,配置內容如下所示:
|
\# 配置項目管道
ITEM_PIPELINES = {
"sfCrawler.pipelines.JdcrawlerPipeline": 401,
"sfCrawler.pipelines\_manage.mysql\_pipelines.MySqlPipeline": 402,
"sfCrawler.pipelines\_manage.shunfeng\_pipelines.ShunfengPipeline": 403,
}
|
爬蟲入門地址:
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
3 WebMagic框架(Java)
3.1 前言
總結Scrapy使用過程中存在的問題,以及爬蟲系統後期上線需求考慮,採用Java語言進行爬蟲的設計與開發。具體原因如下:
(1)上線基礎環境依賴:需要使用線上Clover、JimDB、MySQL等基礎環境;
(2)可擴展性強:以現有框架為基礎,二次封裝Request請求對象,實現通用網絡爬蟲開發,提供易擴展的地址生成、網頁解析接口。
(3)集中部署:通過部署通用爬蟲方式,抓取所有支持站點的爬蟲,解決Scrapy框架一站點一部署問題。
(4)反-反爬蟲:部分站點針對Scrapy框架請求特點,實施反爬蟲策略(如:天貓),拒絕所有爬蟲請求。WebMagic模擬瀏覽器請求,不受該爬蟲限制。
3.2 WebMagic概述
(內容來源:https://webmagic.io/docs/zh/posts/ch1-overview/architecture.html)3.2.1 總體架構
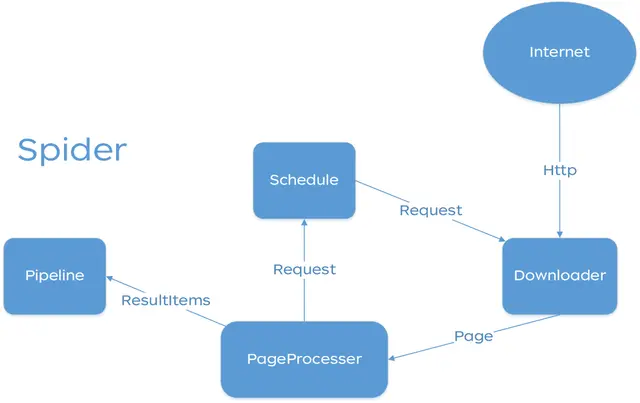
WebMagic的結構分為Downloader、PageProcessor、Scheduler、Pipeline四大組件,並由Spider將它們彼此組織起來。這四大組件對應爬蟲生命週期中的下載、處理、管理和持久化等功能。WebMagic的設計參考了Scapy,但是實現方式更Java化一些。
而Spider則將這幾個組件組織起來,讓它們可以互相交互,流程化的執行,可以認為Spider是一個大的容器,它也是WebMagic邏輯的核心。
WebMagic總體架構圖如下:
3.1.2 WebMagic的四個組件
3.1.2.1 Downloader
Downloader負責從互聯網上下載頁面,以便後續處理。WebMagic默認使用了Apache HttpClient作為下載工具。
3.1.2.2 PageProcessor
PageProcessor負責解析頁面,抽取有用信息,以及發現新的鏈接。WebMagic使用Jsoup作為HTML解析工具,並基於其開發瞭解析XPath的工具Xsoup。
在這四個組件中,PageProcessor對於每個站點每個頁面都不一樣,是需要使用者定製的部分。
3.1.2.3 Scheduler
Scheduler負責管理待抓取的URL,以及一些去重的工作。WebMagic默認提供了JDK的內存隊列來管理URL,並用集合來進行去重。也支持使用Redis進行分佈式管理。
除非項目有一些特殊的分佈式需求,否則無需自己定製Scheduler。
3.1.2.4 Pipeline
Pipeline負責抽取結果的處理,包括計算、持久化到文件、數據庫等。WebMagic默認提供了“輸出到控制枱”和“保存到文件”兩種結果處理方案。
Pipeline定義了結果保存的方式,如果你要保存到指定數據庫,則需要編寫對應的Pipeline。對於一類需求一般只需編寫一個Pipeline。
3.1.3 用於數據流轉的對象
3.1.3.1 Request
Request是對URL地址的一層封裝,一個Request對應一個URL地址。
它是PageProcessor與Downloader交互的載體,也是PageProcessor控制Downloader唯一方式。
除了URL本身外,它還包含一個Key-Value結構的字段extra。你可以在extra中保存一些特殊的屬性,然後在其他地方讀取,以完成不同的功能。例如附加上一個頁面的一些信息等。
3.1.3.2 Page
Page代表了從Downloader下載到的一個頁面——可能是HTML,也可能是JSON或者其他文本格式的內容。
Page是WebMagic抽取過程的核心對象,它提供一些方法可供抽取、結果保存等。在第四章的例子中,我們會詳細介紹它的使用。
3.1.3.3 ResultItems
ResultItems相當於一個Map,它保存PageProcessor處理的結果,供Pipeline使用。它的API與Map很類似,值得注意的是它有一個字段skip,若設置為true,則不應被Pipeline處理。
3.1.4 控制爬蟲運轉的引擎--Spider
Spider是WebMagic內部流程的核心。Downloader、PageProcessor、Scheduler、Pipeline都是Spider的一個屬性,這些屬性是可以自由設置的,通過設置這個屬性可以實現不同的功能。Spider也是WebMagic操作的入口,它封裝了爬蟲的創建、啓動、停止、多線程等功能。下面是一個設置各個組件,並且設置多線程和啓動的例子。詳細的Spider設置請看第四章——爬蟲的配置、啓動和終止。
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//從https://github.com/code4craft開始抓
.addUrl("https://github.com/code4craft")
//設置Scheduler,使用Redis來管理URL隊列
.setScheduler(new RedisScheduler("localhost"))
//設置Pipeline,將結果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//開啓5個線程同時執行
.thread(5)
//啓動爬蟲
.run();
}3.3 通用爬蟲分析及設計
3.2.1 通用爬蟲功能分析
(1)單個應用同時支持多個站點的數據抓取;
(2)支持集羣部署;
(3)容易擴展;
(4)支持重複抓取;
(5)支持定時抓取;
(6)具備大數據分析擴展能力;
(7)降低大數據分析集成複雜度,提高代碼複用性;
(8)支持線上部署;
3.2.2 通用爬蟲設計
通用爬蟲設計思路是在WebMagic基礎上,將Scheduler、Processor、Pipeline進行定製,設計如下圖所示:
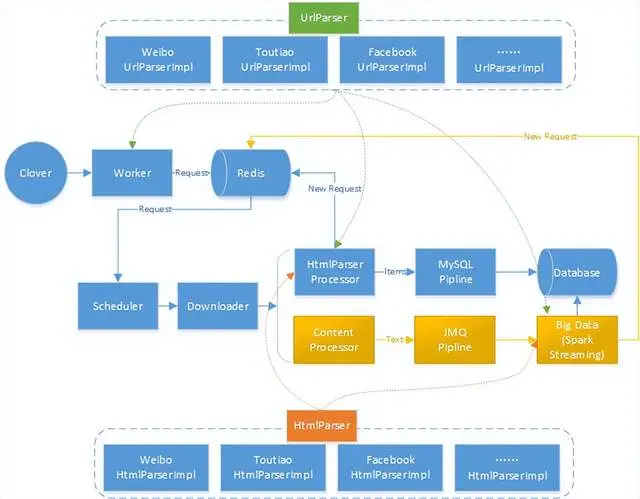
設計過程中按照爬蟲開發的特點,將爬蟲實現過程拆分為兩個環節:生成請求和內容解析。
(1)生成請求(UrlParser):按照不同站點的請求地址及參數特點(如:Get/Post請求方式,URL參數拼接等)及業務需要(如:使用國內代理還是國外代理),按照站點參數拼裝成為通用的Request請求對象,指導Downloader進行網頁下載。
(2)內容解析(HtmlParser):按照解析網頁內容的特點,通過XPATH、JSON等方式對頁面內容進行提取過程,每個內容解析器只針對相同頁面內容進行解析,當內容中包含深度頁面抓取的請求時,由UrlParser生成新的請求對象並返回給調度器。
3.2.3 任務調度設計
為了實現爬蟲的分佈式,將Scheduler功能進行弱化,實現過程增加Clover、Worker、Redis環節。Clover負責定時調度Worker生成默認請求對象(一般為檢索功能、首頁重複抓取任務等),將生成的請求對象添加到Redis隊列中,Scheduler只負責從Redis隊列中獲取請求地址即可。
3.2.4 Processor設計
Processor用於解析Downloader下載的網頁內容,為了充分利用服務器網絡和計算資源,設計之初考慮能夠將網頁下載和內容解析拆分到不同服務中進行處理,避免爬蟲節點CPU時間過長造成網絡帶寬的浪費。所以,設計過程中按照爬蟲內部解析和外部平台集成解析兩種方式進行設計。
(1)爬蟲內部解析:即下載內容直接由Processor完成頁面解析過程,生成Items對象和深度Request對象。為了簡化對多個站點內容的解析過程,Processor主要負責數據結構的組織和HtmlParser的調用,通過Spring IOC的方式實現多個站點HtmlParser集成過程。
(2)外部平台集成:能夠將爬蟲抓取內容通過MQ等方式,實現其他平台或服務的對接過程。實現過程中可以將抓取的網頁內容組織成為文本類型,通過Pipline方式將數據發送到JMQ中,按照JMQ方式實現與其他服務和平台的對接過程。其他服務可以複用HtmlParser和UrlParser完成內容解析過程。
3.2.5 Pipline設計
Pipline主要用於數據的轉儲,為了適用Processor的兩種方案,設計MySQLPipeline和JMQPipeline兩種實現方式。
3.4 通用爬蟲實現
3.4.1 Request
WebMagic提供的Request類能夠滿足網絡請求的基本需求,包括URL地址、請求方式、Cookies、Headers等信息。為了實現通用的網絡請求,對現有請求對象進行業務擴展,增加是否過濾、過濾token、請求頭類型(PC/APP/WAP)、代理IP國別分類、失敗重試次數等。擴展內容如下:
/**
* 站點
*/
private String site;
/**
* 類型
*/
private String type;
/**
* 是否過濾 default:TRUE
*/
private Boolean filter = Boolean.TRUE;
/**
* 唯一token,URL地址去重使用
*/
private String token;
/**
* 解析器名稱
*/
private String htmlParserName;
/**
* 是否填充Header信息
*/
private Integer headerType = HeaderTypeEnums.NONE.getValue();
/**
* 國別類型,用於區分使用代理類型
* 默認為國內
*/
private Integer nationalType = NationalityEnums.CN.getValue();
/**
* 頁面最大抓取深度,用於限制列表頁深度鑽取深度,按照訪問次數依次遞減
* <p>Default: 1</p>
* <p> depth = depth - 1</p>
*/
private Integer depth = 1;
/**
* 失敗重試次數
*/
private Integer failedRetryTimes;3.4.2 UrlParser & HtmlParser
3.4.2.1 UrlParser實現
UrlParser主要用與按照參數列表生成固定的請求對象,為了簡化Workder的開發過程,在接口中增加了生成初始化請求的方法。
/**
* URL地址轉換
* @author liwanfeng1
*/
public interface UrlParser {
/**
* 獲取定時任務初始化請求對象列表
* @return 請求對象列表
*/
List<SeparateRequest> getStartRequest();
/**
* 按照參數生成Request請求對象
* @param params
* @return
*/
SeparateRequest parse(Map<String, Object> params);
}3.4.2.2 HtmlParser實現
HtmlParser主要是將Downloader內容進行解析,並返回data列表及深度抓取的Request對象。實現如下:
/**
* HTML代碼轉換
* @author liwanfeng1
*/
public interface HtmlParser {
/**
* HTML格式化
* @param html 抓取的網頁內容
* @param request 網絡請求的Request對象
* @return 數據解析結果
*/
HtmlDataEntity parse(String html, SeparateRequest request);
}
/**
* @author liwanfeng1
* @param <T> 數據類型
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class HtmlDataEntity<T extends Serializable> {
private List<T> data;
private List<SeparateRequest> requests;
/**
* 添加數據對象
* @param obj 數據對象
*/
public void addData(T obj){
if(data == null) {
data = new ArrayList<>();
}
data.add(obj);
}
/**
* 添加Request對象
* @param request 請求對象
*/
public void addRequest(SeparateRequest request) {
if(requests == null) {
requests = new ArrayList<>();
}
requests.add(request);
}
}3.4.3 Worker
Workder的作用是定時生成請求對象,結合UrlParser接口的應用,設計統一的WorkerTask實現類,代碼如下:
/**
*
* @author liwanfeng1
*/
@Slf4j
@Data
public class CommonTask extends AbstractScheduleTaskProcess<SeparateRequest> {
private UrlParser urlParser;
private SpiderQueue spiderQueue;
/**
* 獲取任務列表
* @param taskServerParam 參數列表
* @param i 編號
* @return 任務列表
*/
@Override
protected List<SeparateRequest> selectTasks(TaskServerParam taskServerParam, int i) {
return urlParser.getStartRequest();
}
/**
* 執行任務列表,組織Google API請求地址,添加到YouTube列表爬蟲的隊列中
* @param list 任務列表
*/
@Override
protected void executeTasks(List<SeparateRequest> list) {
spiderQueue.push(list);
}
}
添加Worker配置如下:
<!-- Facebook start -->
<bean id="facebookTask" class="com.jd.npoms.worker.task.CommonTask">
<property name="urlParser">
<bean class="com.jd.npoms.spider.urlparser.FacebookUrlParser"/>
</property>
<property name="spiderQueue" ref="jimDbQueue"/>
</bean>
<jsf:provider id="facebookTaskProcess"
interface="com.jd.clover.schedule.IScheduleTaskProcess" ref="facebookTask"
server="jsf" alias="woker:facebookTask">
</jsf:provider>
<!-- Facebook end -->3.4.4 Scheduler
調度主要用於推送、拉取最新任務,以及輔助的推送重複驗證、隊列長度獲取等方法,接口設計如下:
/**
* 爬蟲任務隊列
* @author liwanfeng
*/
public interface SpiderQueue {
/**
* 添加隊列
* @param params 爬蟲地址列表
*/
default void push(List<SeparateRequest> params) {
if (params == null || params.isEmpty()) {
return;
}
params.forEach(this::push);
}
/**
* 將SeparaterRequest地址添加到Redis隊列中
* @param separateRequest SeparaterRequest地址
*/
void push(SeparateRequest separateRequest);
/**
* 彈出隊列
* @return SeparaterRequest對象
*/
Request poll();
/**
* 檢查separateRequest是否重複
* @param separateRequest 封裝的爬蟲url地址
* @return 是否重複
*/
boolean isDuplicate(SeparateRequest separateRequest);
/**
* 默認URL地址生成Token<br/>
* 建議不同的URLParser按照站點地址的特點,生成較短的token
* 默認採用site、type、url地址進行下劃線分割
* @param separateRequest 封裝的爬蟲url地址
*/
default String generalToken(SeparateRequest separateRequest) {
return separateRequest.getSite() + "_" + separateRequest.getType() + "_" + separateRequest.getUrl();
}
/**
* 獲取隊列總長度
* @return 隊列長度
*/
Long getQueueLength();
}4 瀏覽器調用爬蟲(Python)
瀏覽器調用爬蟲主要藉助Selenium與ChromeDriver技術,通過本地化瀏覽器調用方式加載並解析頁面內容,實現數據抓取。瀏覽器調用主要解決複雜站點的數據抓取,部分站點通過流程拆分、邏輯封裝、代碼拆分、代碼混淆等方式增加代碼分析的複雜度,結合請求拆分、數據加密、客户端行為分析等方式進行反爬操作,使爬蟲程序無法模擬客户端請求過程向服務端發起請求。
該種方式主要應用於順豐快遞單號查詢過程,訂單查詢採用騰訊滑動驗證碼插件進行人機驗證。基本流程如下圖所示:

首先配置ChromeDriver組件到操作系統中,組件下載地址:
https://chromedriver.storage.googleapis.com/index.html?path=2...,將文件保存到系統環境變量“PATH”中指定的任意路徑下,建議:C:\Windows\system32目錄下。
組件添加驗證:啓用命令行窗口->任意路徑運行“ChromeDriver.exe”,程序會以服務形式運行。
爬蟲實現過程如下:
(1)啓動瀏覽器:為了實現爬蟲的併發,需要通過參數方式對瀏覽器進行優化設置;
啓動瀏覽器
def getChromeDriver(index):
options = webdriver.ChromeOptions()
options.add_argument("--incognito") # 無痕模式
options.add_argument("--disable-infobars") # 關閉菜單欄
options.add_argument("--reset-variation-state") # 重置校驗狀態
options.add_argument("--process-per-tab") # 獨立每個tab頁為單獨進程
options.add_argument("--disable-plugins") # 禁用所有插件
options.add_argument("headless") # 隱藏窗口
proxy = getProxy()
if proxy is not None:
options.add_argument("--proxy-server==http://%s:%s" % (proxy["host"], proxy["port"])) # 添加代理
return webdriver.Chrome(chrome_options=options)(2)加載頁面:調用瀏覽器訪問指定地址頁面,並等待頁面加載完成;
driver.get('http://www.sf-express.com/cn/sc/dynamic_function/waybill/#search/bill-number/' + bill_number)
driver.implicitly_wait(20) #最長等待20秒加載時間(3)切換Frame:驗證碼採用IFrame方式加載到當前頁面,接下來需要對頁面元素進行操作,需要將driver切換到iframe中;
driver.switch_to.frame("tcaptcha_popup")
driver.implicitly_wait(10) #等待切換完成,其中iframe加載可能有延遲(4)滑動模塊:滑動頁面中的滑塊到指定位置,實現驗證過程;
滑動驗證碼操作過程如下圖所示:
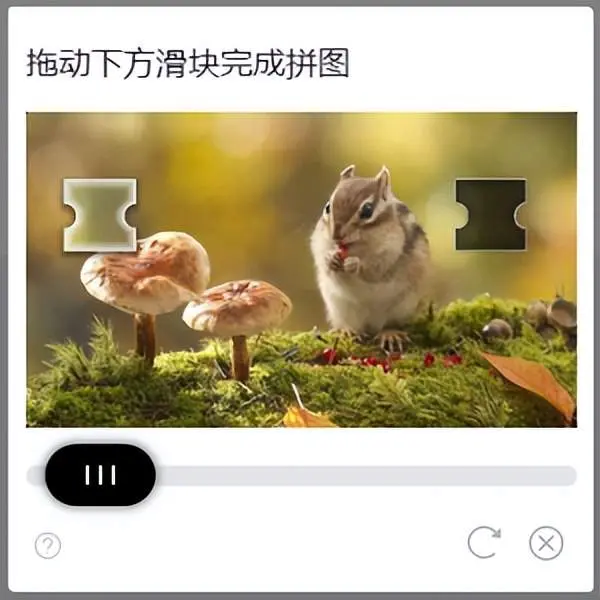
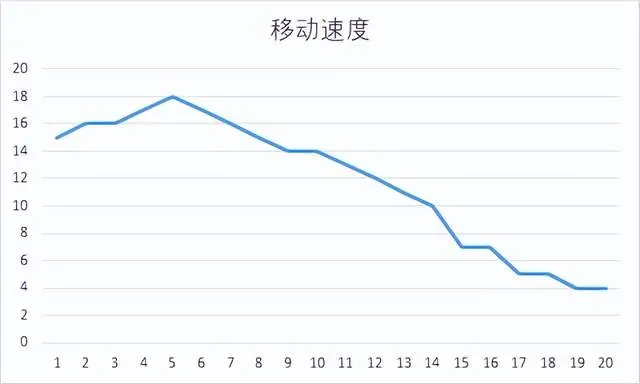
滑動模塊執行距離在240像素前後,整個滑動過程取樣14個,模擬拋物線執行過程控制滑動速度,將這個滑動過程分為20次移動(避免每次採樣結果相同),分析如下圖所示:

代碼如下:
# 隨機生成滑塊拖動軌跡
def randomMouseTrace():
trace = MouseTrace()
trace.x = [20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 9, 9, 8, 8, 7, 7, 6, 6, 5, 5]
trace.y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
trace.time = [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]
return trace
# 拖動滑塊
def dragBar(driver, action):
dragger = driver.find_element_by_id("tcaptcha_drag_button")
action.click_and_hold(dragger).perform() # 鼠標左鍵按下不放
action.reset_actions()
trace = randomMouseTrace()
for index in range(trace.length()):
action.move_by_offset(trace.x[index], trace.y[index]).perform() # 移動一個位移
action.reset_actions()
time.sleep(trace.time[index]) # 等待停頓時間
action.release().perform() # 鼠標左鍵鬆開
action.reset_actions()
return driver.find_element_by_id("tcaptcha_note").text == ""(4)數據解析及存儲:數據解析過程主要是按照id或class進行元素定位獲取文本內容,將結果插入到數據庫即完成數據抓取過程。
(5)其他:採用Python的threading進行多線程調用,將訂單編號保存到Redis中實現分佈式任務獲取過程,每執行一次將POP一個訂單編號。
待改進:
(1)模塊滑動速度和時間固定,可以進行隨機優化;
(2)未識別滑塊釋放位置,目前採用滑塊更新的方式重試,存在一定的錯誤率;
(3)如果不切換代理IP,需要對瀏覽器啓動進行優化,減少啓動次數,提升抓取速度;
5 gocolly框架(Go)
多線程併發執行是Go語言的優勢之一,Go語言通過“協程”實現併發操作,當執行的協程發生I/O阻塞時,會由專門協程進行阻塞任務的管理,對服務器資源依賴更少,抓取效率也會有所提高。
(以下內容轉自:https://www.jianshu.com/p/23d4ecb8428f)
5.1 概述
gocolly是用go實現的網絡爬蟲框架gocolly快速優雅,在單核上每秒可以發起1K以上請求;以回調函數的形式提供了一組接口,可以實現任意類型的爬蟲;依賴goquery庫可以像jquery一樣選擇web元素。
gocolly的官方網站是http://go-colly.org/,提供了詳細的文檔和示例代碼。
5.2 安裝配置
安裝
go get -u github.com/gocolly/colly/引入包
import "github.com/gocolly/colly"5.3 流程説明
5.3.1 使用流程
使用流程主要是説明使用colly抓取數據前的準備工作
- 初始化Collector對象, Collector對象是colly的全局句柄
- 設置全局設置,全局設置主要是設置colly 句柄的代理設置等
- 註冊抓取回調函數, 主要是用於在抓取數據後在數據處理的各個流程提取數據以及出發其他操作
- 設置輔助工具,如抓取鏈接的存放隊列,數據清洗隊列等
- 註冊抓取鏈接
- 啓動程序開始抓取
5.3.2 抓取流程
每次抓取數據流程中的各個節點都會嘗試觸發用户註冊的抓取回調函數,以完成提取數據等需求, 抓取流程如下。
- 根據鏈接每次準備抓取數據前調用 註冊的OnRequest做每次抓取前的預處理工作
- 當抓取數據失敗時會調用OnError做錯誤處理
- 抓取到數據後調用OnResponse,做剛抓到數據時的處理工作
- 然後分析抓取到的數據會根據頁面上的dom節點觸發OnHTML回調進行數據分析
- 數據分析完畢後會調用OnScraped函數進行每次抓取後的收尾工作
5.4. 輔助接口
colly也提供了部分輔助接口,協助完成數據抓取分析流程, 以下列舉一部分主要的支持。
- queue 用於存放等待抓取的鏈接
- proxy 用於代理髮起抓取源
- thread 支持多攜程併發處理
- filter 支持對特殊鏈接進行過濾
- depth 可以設置抓取深度控制抓取
5.5. 實例
更多可以參考源碼鏈接中的例子(https://github.com/gocolly/colly/tree/master/_examples)












