

本文整理自 IvorySQL 2025 生態大會暨 PostgreSQL 高峯論壇的演講分享,演講嘉賓:孟飛龍,瀚高股份研發工程師。
本文主要從以下 4 個方面進行分享:
- 前言
- 故障檢測與轉移
- 問題探討
- 結語
前言
前言部分主要介紹一些 PostgreSQL 高可用相關的概念,讓大家對高可用有一個大概的瞭解。
PostgreSQL 高可用簡述
- 高可用的作用
在數據庫宕機的危機時刻,PostgreSQL 高可用架構會通過一系列精密設計的機制,悄然接管服務並保障業務連續性。 - 高可用的基礎
流複製,主庫將預寫日誌(WAL)實時發送至備庫,備庫通過應用日誌實現數據同步。同步複製模式下犧牲部分性能換取零數據丟失。
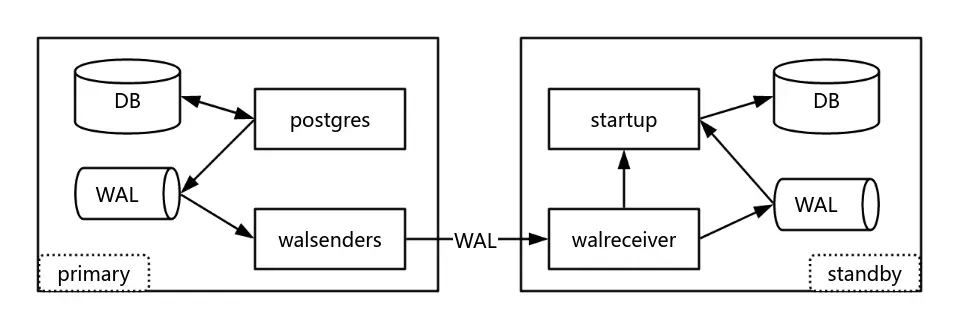
上圖為流複製示意圖。左側為主庫,當用户寫入數據,數據庫不會直接把數據寫入磁盤,而是先把 WAL 寫到磁盤,然後通過 walsenders 進程將 WAL 發送到備庫。右側的備庫,通過 walreceiver 進程接收 WAL 日誌,然後通過 startup 進程將日誌進行重做,使數據落盤,從而實現主備之間的數據同步。為了實現數據的零丟失,一般會將流複製模式設置為同步模式。
- 高可用的動作
提升備庫為新主庫,通常通過設置 vip 使應用無感知地連接主庫。 - 高可用的難題
腦裂防護,如因網絡分區造成的多主問題。
PostgreSQL 高可用開源軟件
-
Pgpool-II
- 核心功能:連接池、負載均衡、讀寫分離、故障轉移
- 侷限:配置複雜度較高,故障轉移需結合自定義腳本
-
Repmgr
- 核心功能:主從複製管理、自動化故障轉移、監控複製狀態
- 侷限:在某些複雜場景下的靈活性和自動化程度較弱
-
Stolon
- 核心功能:雲原生高可用,支持 Kubernetes 集成。
- 侷限:依賴外部存儲,性能受存儲層限制
-
Patroni
- 核心功能:自動化、強一致性和雲原生支持,比較主流
- 侷限:依賴分佈式協調服務的強一致性,增加了架構的複雜度
故障檢測與轉移
故障檢測
1. 數據庫故障檢測
高可用組件通過檢查主庫進程狀態或數據庫連接來判斷健康狀況:
- 主庫故障:觸發新主選舉。
- 同步備故障:降為異步備。
工作原理:
- Patroni:通過監控 PG 進程檢測故障,若主庫進程缺失,嘗試重啓或根據配置降級。
- Repmgr:通過連接數據庫判斷健康狀況,主庫故障時通知備節點競選新主,同步備故障影響主庫寫入需處理。
2. 服務器故障檢測
高可用組件通過主庫狀態判斷健康狀況:
- Patroni:依據 DCS 中的 leader 狀態。
- Repmgr:通過連接主庫和 witness 判斷。
- 故障類型:斷電、斷網。
工作原理:
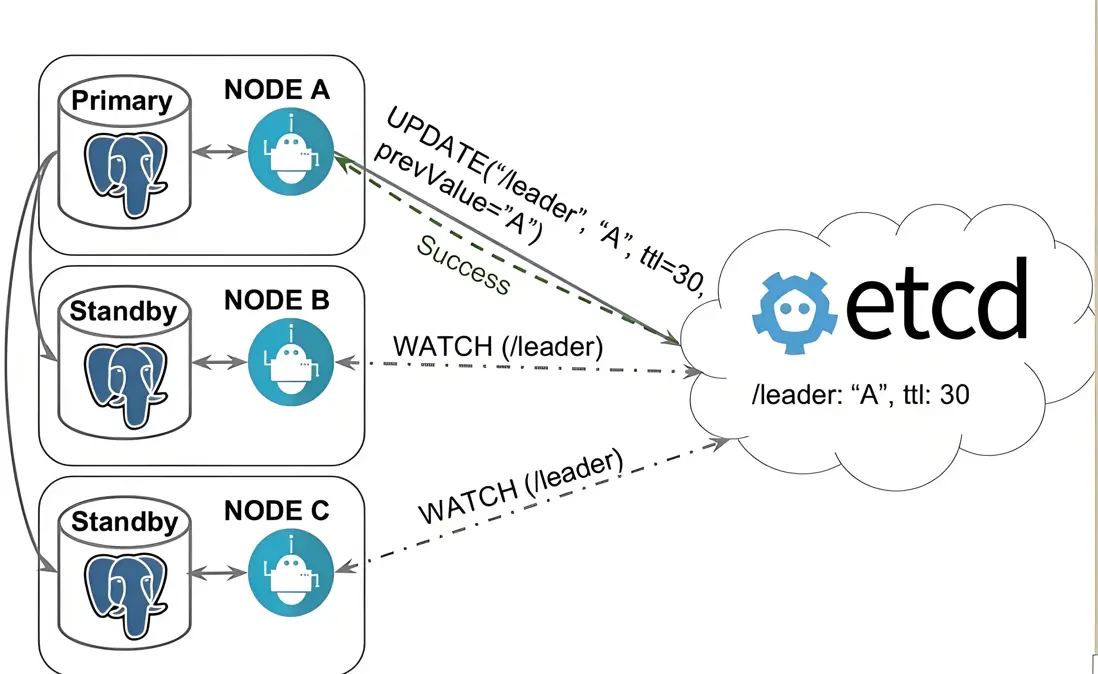
- Patroni 實時監控 Node A 數據庫狀態,若異常且無法恢復,刪除 etcd 中的 leader 鍵。
- Node B 和 C 檢測到 leader 缺失,發起競選。
- 若 Node A 服務器故障,Patroni 未更新 etcd leader(超過 TTL,如 30 秒),etcd 清除 leader,備節點重新競選。
故障轉移
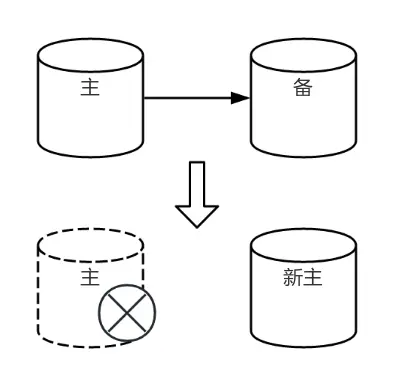
當主庫故障且高可用軟件判斷無法恢復時,需選舉新主節點並執行 promote 操作以恢復服務。由於通常配置多個備節點(Node B),需通過選舉確定哪一節點成為新主。
- 選舉依據:高可用軟件優先考慮 LSN(日誌序列號),選擇與主庫數據量最接近的節點。通常提供“故障優先級”參數,優先級越高者選舉優先級越高。
- 同步節點提升:如 Patroni,會優先提升同步備節點為新主。
- 新主處理:新主執行 promote 操作後,其他備節點更新其 primary connection 信息,追隨新主建立流複製。可配置物理或邏輯複製槽,高可用工具會相應處理這些槽。
問題探討
RPO 和 RTO
-
RPO 與性能
RPO(Recovery Point Objective,恢復點目標) 是衡量系統在故障或災難發生後,允許丟失的數據量(以時間為單位)——數據丟多少。
想要做到 RPO=0 需要將流複製設置為同步模式,備庫延遲過高會影響主庫的寫入。
-
RTO 與穩定
RTO(Recovery Time Objective,恢復時間目標)是衡量系統在故障或災難發生後,業務功能恢復到可接受水平所需的最大可接受時間——多久能恢復。
想要減小 RTO 就需要減小高可用的檢測間隔,但較小的檢測間隔又會影響集羣的穩定,一點網絡波動就會造成誤判,導致集羣頻頻切換主備。
離線節點回歸
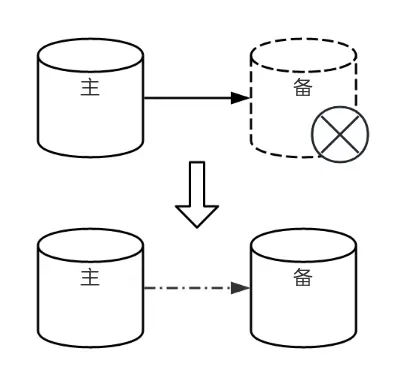
問題描述
長時間離線節點回歸集羣時,因缺失 WAL(Write Ahead Log)日誌,無法與主庫建立流複製。
解決方法
-
配置物理複製槽
- 優點:可支持節點回歸。
- 缺點:配置複雜,且若節點永久離線,主庫物理複製槽保留 WAL 日誌,佔用磁盤空間。
-
配置日誌歸檔與恢復
- 方法:將 WAL 日誌備份至遠程磁盤,確保離線節點回歸後可恢復。
- 缺點:需額外遠程服務器資源。
-
無配置時的應急方法
- 方法:重做備庫(最原始方式)。
注意事項
- 主節點離線迴歸:若主節點長時間離線並接收新數據,與新主數據不一致,需同步數據。
- 日誌覆蓋問題:新主覆蓋 WAL 日誌後,原主節點嘗試恢復仍可能成功,但因缺失日誌無法啓動,會持續尋求主庫發送缺失日誌(操作失敗)。
腦裂防護
問題描述
數據庫腦裂會導致應用無法判斷數據寫入目標主庫,引發數據分歧或丟失。
解決方法
- Repmgr:通過配置 witness(見證節點)或手動設置 location 參數,解決網絡分區問題,防止腦裂。
-
Patroni:依賴 DCS(如 etcd)的 Raft 協議,需多數派共識才能維持服務,天然規避腦裂。但若 Patroni 進程異常退出(如主庫進程未隨退出),備節點可能選舉新主,導致腦裂。
-
解決措施:
- Watchdog:若長時間未接收 Patroni 心跳,觸發系統重啓。
- 故障重啓:故障重啓:通過 systemd 服務配置 Patroni 故障重啓機制。
- 最佳實踐:設置 VIP 綁定新主,避免腦裂影響。
-
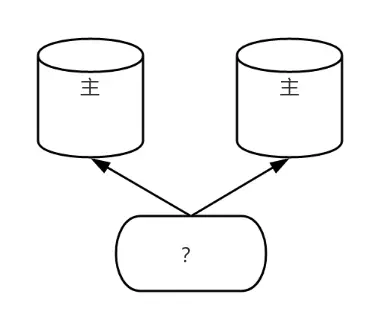
兩節點部署的極限問題
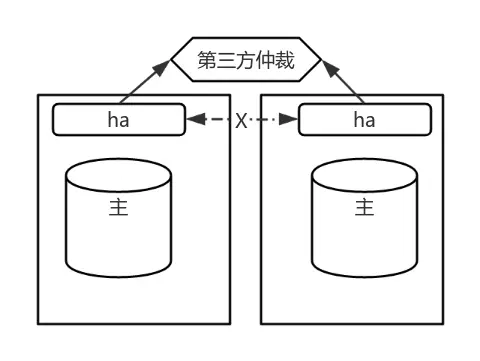
問題背景
通常,穩定的 PG 高可用集羣需至少三個節點支持。但客户僅提供兩台服務器,需實現高可用。
解決方法
- 第三方仲裁方式:引入網關 IP 作為仲裁。當一節點故障,另一節點嘗試與仲裁聯通,若成功則視為正常節點。
風險與侷限
- 腦裂風險:若兩節點正常但因網絡隔離互不可達,均可與第三方仲裁聯通,可能導致腦裂。目前兩節點極限部署無完美解決方案。
- 實際應用:客户需求迫切下,採用此方案,腦裂風險發生概率較低。
結語
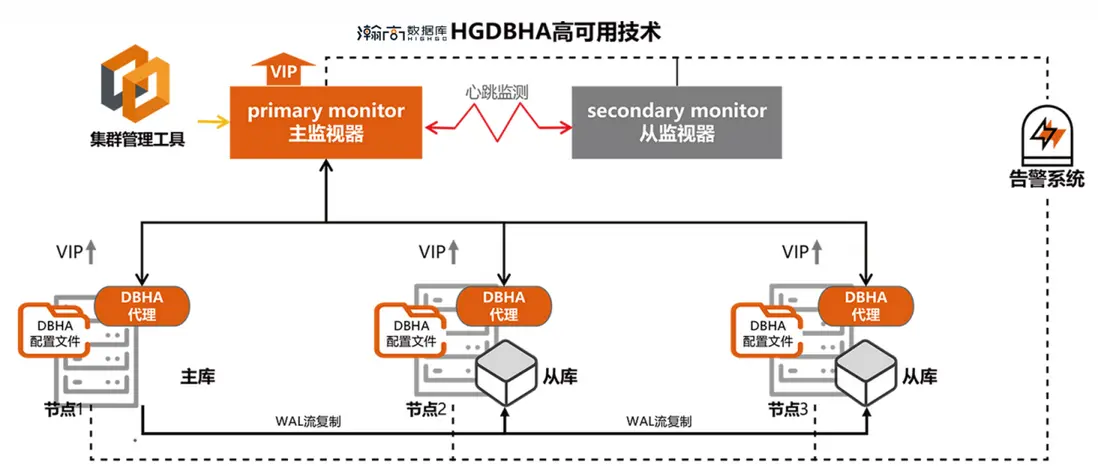
PostgreSQL 高可用架構通過“監控-檢測-轉移-恢復”的閉環設計,將數據庫宕機的影響降至最低。其背後是流複製、分佈式協調、智能選主等技術的深度融合,更是對業務連續性需求的精準迴應。在實際部署中,需結合場景選擇同步/異步複製模式,配置合理的監控告警,並定期演練故障恢復流程,方能築牢數據安全的最後一道防線。