









本文整理自 IvorySQL 2025 生態大會暨 PostgreSQL 高峯論壇的演講分享,演講嘉賓:呂海波,PG ACED ,北京大學數據庫課程企業導師。
本文主要包括以下三部分內容:
- CPU 流水線的秘密:神秘的 PMC 與 PMU
- 示例數據庫 1 的改進與不足:從 CPU 看程序
- 示例數據庫 2 的秘密花園使用 PMC 推導軟件架構
CPU 流水線的秘密:神秘的 PMC 與 PMU
- PMC:Performance Monitoring Counter
- PMU:Performance Monitoring Unit
PMC 是性能監控計數器,PMU 是性能監控單元,兩者其實是一回事。
CPU 在其流水線的內部內置了上千個計數器,用來觀察程序指令在 CPU 內部運行的狀態。單個計數器就是 PMC,所有的計數器合起來就是 PMU。
PMC 的作用
眾所周知,CPU 體積很小,卻內置了上千個計數器,其重要性不言而喻。
PMC 的作用是對程序進行 profiling(或畫像/側寫/……)。通過畫像,讓開發者瞭解程序在 CPU 中的運行狀況,有針對性的調整、優化程序,以提高程序性能、能效。
perf 與 PMC
perf stat -ePMC1,PMC2,……PMCn -p/t 進/線程
使用一條 perf 的命令,就能夠把某個或某些計數器打開,然後把機器去的結果展現出來。
CPU 中有什麼 PMCs ?
使用 perf list 這一條命令,就能把所有的 PMC 列出來。
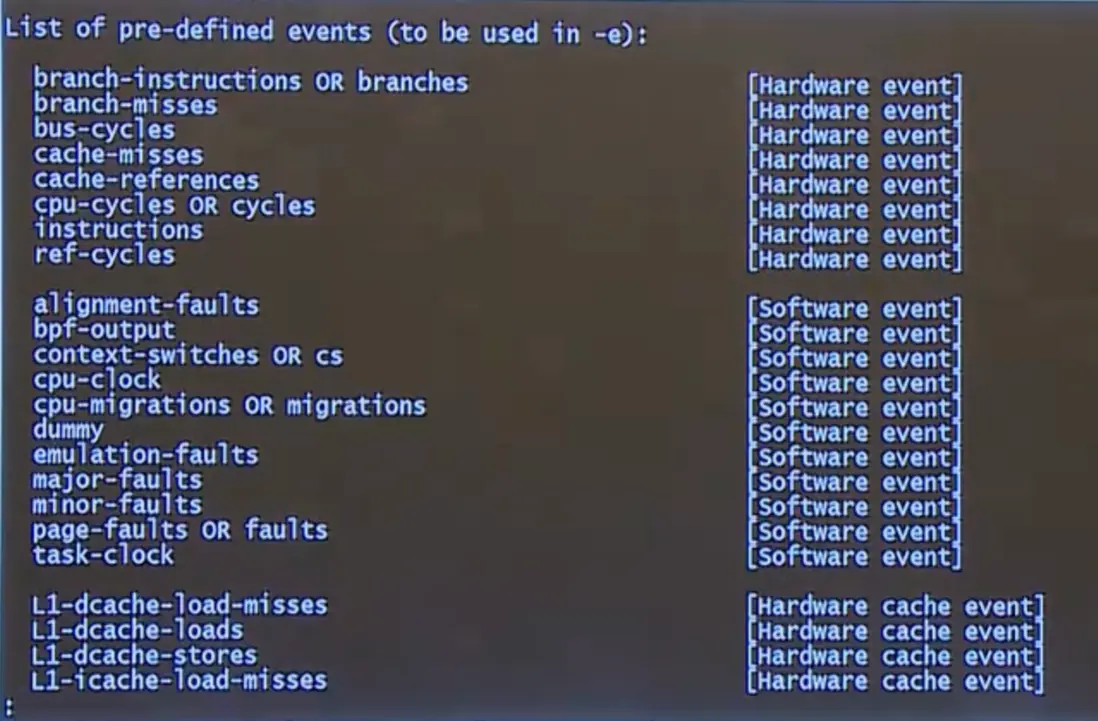
上圖中標記 hardware event 的即為 CPU 內流水線的計數器,一共有 1000 多個。標記為 software event 的則是操作系統中軟件的計數器,但不是 CPU 中的。
雖然這些計數器很多,但最重要的是開頭這些。
示例數據庫 1 的改進與不足:從 CPU 看程序
PMC 的作用
下面用一個非常簡單的例子,來看一下 PMC 的作用。
如果想知道“執行某條命令時,CPU 到底為它運行了多少條指令”,用 perf stat -e instructions:u -t 26896 這條命令就能精準統計。
這條命令的每個部分都有明確作用:
-
-e instructions:u:指定要監控的“事件計數器”。instructions表示計數器類型,即統計“指令總數”。- 冒號後的
u是篩選條件,只統計用户態指令,會自動屏蔽操作系統內核態的指令。
-
-t 26896:指定監控對象。t是thread(線程)的縮寫,這裏直接跟線程 ID26896,表示只監控該線程的指令。- 若想監控整個進程,需將
-t換成-p,再跟上進程 ID。
CPU 會根據“特權等級”區分指令來源,主要分兩類:
- 用户態指令:普通應用程序(比如你執行的命令)發出的指令,是統計的核心目標。
- 內核態指令:操作系統自身(比如處理文件、網絡)發出的指令,屬於“干擾項”。
加 :u 能屏蔽內核態指令,讓最終的統計結果更乾淨,只反映你關注的命令實際消耗的 CPU 指令數。
畫像,對比着看才更有意義。我們下面對比下“示例 1 數據庫”和 PG。看看怎麼從 CPU 角度對數據庫進行畫像。
接下來我們進行觀察時,需先明確兩點核心邏輯:
- 若有多個 PMC(性能監控計數器),可針對單個程序做深度分析;
- 當前僅用“指令數”這一個 PMC,因此更適合通過多個程序對比來得出結論。
我們選取兩個數據庫對象作為對比樣本,關鍵信息如下:
-
第一個對象:PG 數據庫
- 內置一張表,表名為“vage2”;
- 該表數據量為 195M,包含 4 列,其中兩列為主鍵;
- 表內共插入 300 萬行數據。
-
第二個對象:示例數據庫
- 暫不提及具體名稱,統一稱其為“示例數據庫 1”;
- 該表數據量為 196M,包含 4 列,其中兩列為主鍵;
- 表內共插入 300 萬行數據。

PG

示例數據庫 1
對比分析先從簡單 SQL 開始——複雜壓測的指令數太多,暫不考慮。以主鍵 ID 為例,300 萬行數據對應的索引層高約 3-4 層,若按 3 層計算,一次查詢會涉及 4 次邏輯操作。
另外,示例數據庫 1 將 PG 的進程模式改成了線程模式。之前展示的統計命令其實需要進程號和線程號,但從示例數據庫 1 查詢到的並非線程號或進程號,而是線程標識。這裏我也做了演示:先用 GDB 調試示例數據庫 1 的進程,再通過一條命令 (gdb) i threads,即可從線程標識獲取線程號。這裏的“I”就是 Info 命令。用 Info 命令顯示數據庫一的所有線程,就能列出所有線程信息。接着,查出之前的線程號,將其轉換成十六進制,再在顯示的線程列表中搜索這個十六進制值,就能找到對應的是 2 號線程——也就是剛才第二個窗口裏對應的線程,其線程號為 6918。
接下來的操作很簡單:我們執行命令 perf stat -e instructions:u -t 26896,其中 -t 後面跟的就是目標線程號(這裏以 26896 為例)。這條命令會針對 26896 線程開啓 CPU 指令計數器——只要該線程有任何操作,都會觸發 CPU 前端指令計數器的計數增長。
開啓計數器後,切換到旁邊的窗口執行目標 SQL(比如我們之前提到的簡單語句,也可以是其他語句);執行完成後切回原窗口,按 ctrl+c 即可查看統計結果。
多次執行後會發現,前兩次結果可能有波動,後續則趨於穩定。在示例數據庫一中,執行這條簡單 SQL 大約需要 100 多萬條指令(略多於 100 萬)。
再看 PG 的測試,操作模式幾乎一致:先多次執行目標 SQL,查出其進程號(比如 7096),然後在旁邊窗口使用 perf 命令時,因 PG 是進程模式,只需將參數從-t(線程號)換成-p(進程號),即 -p 7096,其他命令保持不變。
統計結果顯示,PG 執行相同操作的指令數約為 21 萬(略多於 20 萬)。對比來看,示例數據庫一的指令數是 PG 的 4 到 6 倍,多次測試取平均值後,差距約為 5 倍。
從功能上看,PG 並不比示例數據庫一弱,甚至在不同場景下各有優勢。但從指令數差異能看出,示例數據庫一的操作邏輯略顯冗餘——就像兩人聊天時,本可以用 10 句話講清的問題,它卻用了 50 句,存在一定的資源浪費。不過,這種冗餘在當前場景下的影響並不算大,我們通過這種簡單方式,能從 CPU 指令角度直觀觀察到這一特點。
衡量 Coding 水平
除了統計指令數,使用 PMC 中的指標,還可以簡單的觀察程序開發者的 coding 水平。以分枝指令數和 not_taken 分枝指令數為例進行對比。

可以看到,示例數據庫 1 和 PG 相比,coding 水平是有差異的。不過示例數據庫 1 也有優點,它把進程改成了線程。線程的最大優勢是 TLB 的 miss 率更低。

進程與線程
- 進程模式下的 TLB 行為
如圖所示,進程 1 和進程 2 的用户空間中,變量 a 和變量 b 雖映射到同一塊共享內存,但由於進程擁有獨立的地址空間,TLB(地址轉換旁視緩衝器)會為它們分別維護包含 VA Tag(虛擬地址標籤)、ASID(地址空間標識符)等字段的條目。即使物理內存是同一塊,TLB 中也會存在兩個獨立的條目。 - 線程模式下的 TLB 優勢
線程屬於同一進程,共享同一個地址空間。若兩個線程訪問類似變量 a、b(映射到同一塊共享內存),它們在 TLB 中會複用同一個條目。
- 當線程 1 訪問變量 a 時,TLB 會緩存對應的地址轉換條目;
- 線程 2 訪問變量 b 時,可直接命中該 TLB 條目,無需重新執行地址轉換,從而大幅降低 TLB miss 率。
- 性能影響的本質
TLB miss 率的降低能直接提升內存訪問效率(如數據庫場景中,線程模式的地址轉換開銷會顯著小於進程模式)。但性能提升的上限還受其他因素制約——若代碼本身存在邏輯冗餘(如不必要的繁瑣流程),僅靠線程的 TLB 優勢可能無法完全抵消整體性能損耗。
示例數據庫 2 的秘密花園:使用 PMC 推導軟件架構
用 PMC 推導軟件架構:準備測試數據

接下來我們用示例數據庫 2 做對比,該數據庫是基於 SSTable 處理架構的。
啓動測試,測試的表有 100 萬行,八九十兆,沿着主鍵做 10 萬次查詢。查詢完成的時間為 1.6 秒左右,是 PG 的六七倍。
以不同的步幅訪問內存,產生不同比例的 L1 Cache Miss,觀察影響。
示例數據庫 2 比 PG 慢,主要原因是 miss 率太差,導致性能下降很多。示例數據庫 2 的 miss 率差,主要原因是,像傳統的數據庫,一個進/線程從頭到尾完成 SQL 所有工作。

示例數據庫 2 採用分階段執行 SQL 的架構設計,將單條 SQL 的執行流程拆分為多個獨立階段。針對每個階段,系統會維護一個線程資源池;當請求流轉至該階段時,會從對應的資源池中獲取一個線程,專門為該請求在當前階段的處理提供服務。

該模式存在重大性能缺陷:跨 CPU 核心的階段調度會引發高頻緩存失效。
如圖所示,SQL 請求的處理被拆分為請求階段、SQL 執行階段、事務階段、存儲階段,分別由不同 CPU 核心(Core 1 至 Core 4)負責。當請求從一個階段流轉到下一個階段時,執行線程會切換到不同的 CPU 核心。
由於每個 CPU 核心的 L1、L2 緩存是私有的,前一階段在 Core 1 緩存的 L1、L2 數據,無法被後續階段所在的 Core 2/Core 3/Core 4 直接複用。這必然導致大量 L1、L2 緩存失效(miss)——數據需在 CPU 核心間傳遞,甚至回退到 L3 緩存或內存中重新讀取,大幅增加了緩存訪問開銷。
這也是示例數據庫性能不佳的核心原因:跨 CPU 核心的階段拆分導致 L1/L2 緩存 miss 率顯著升高,直接拖累了整體執行效率。

分支預測與編碼對底層硬件的適配性
- BTB 的硬件作用
BTB(Branch Target Buffer,分支目標緩衝器)是 CPU 用於分支預測的關鍵硬件結構,存儲“跳轉語句”(如代碼中的 if (條件 1))和“預測的目標地址”,通過提前預判分支走向,減少分支指令的執行開銷,提升 CPU 執行效率。 - 示例數據庫 2 的分支預測缺陷
該數據庫分支預測命中率低,核心原因是編碼階段未充分適配底層硬件機制(如 BTB 的工作邏輯)。開發者對 CPU 分支預測這類底層特性缺乏考量,導致分支指令頻繁觸發預測失敗,直接拖累執行性能。 - 與 PG 的對比及本質結論
PostgreSQL(PG)在設計時更注重對底層硬件(包括分支預測、緩存架構等)的適配,因此分支預測命中率更高,執行效率更優。
這種差異本質上是編碼對底層系統(硬件機制+軟件架構)理解深度的差異——若要從底層優化性能,需深入理解 BTB、緩存、CPU 調度等原理,才能針對性地提升編碼對硬件特性的適配性。

以上就是分享的全部內容,歡迎大家關注呂海波老師的公眾號《IT 知識刺客》。






