









本文整理自 IvorySQL 2025 生態大會暨 PostgreSQL 高峯論壇的演講分享,演講嘉賓:權宗亮。
本文主要包括以下三部分:
- SeqScan 現狀
- heapam 改進
- 全表計數
SeqScan 現狀
我們使用了一個稍寬的 SeqScan 表,包含約 10-20 個字段,記錄數達 1,000 萬。填充因子約為 50%,生成的數據總計 2.63 GB,佔用約 34.5 萬塊磁盤空間,大致如此。
以下是其尺寸詳情:

其執行計劃較為簡單,包括兩個主要操作:一是全表掃描,二是對全表進行 count(*)。
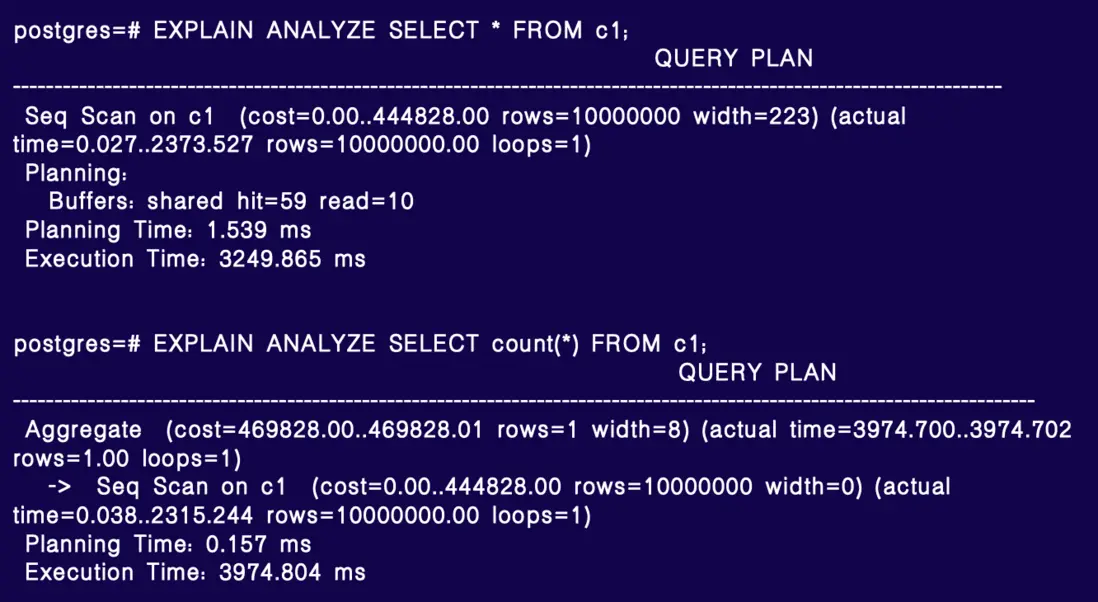
全表掃描的順序掃描耗時約 2.4 秒,是主要的開銷,其餘時間可忽略,可能是數據傳輸開銷。
對於 count(*),總耗時約 4 秒,其中順序掃描(SeqScan)耗時約 2.3 秒,佔用了大部分時間。
目前來看,這種方式看似不常規,正常情況下較少使用。但在實際場景中,一旦文檔中提及相關內容,用户就可能嘗試使用。
我們有一位客户,其表包含數千萬條記錄,業務設計要求每隔一段時間進行全表計數,以統計新增記錄數。客户未透露具體業務邏輯,且不願調整設計。在某些商業數據庫(如國產數據庫遷移場景)中,客户常提出類似需求,強調現有方案高效(如“某某產品很快”),並要求我們的數據庫支持。若試圖協商,他們通常以競爭產品為基準,認為我們需跟進。類似情況普遍存在,處理起來頗費周折。
對於 PostgreSQL(Pg),數千萬條記錄在當前架構下壓力較大。客户採用火山模型逐次 next 計數,count 操作中未利用索引或優化,純靠順序掃描(SeqScan),效率較低。相比之下,某商業產品(暫不具名)經長期對比測試,同樣為 SeqScan,但性能高出約 2.3-2.4 倍。例如,Pg 耗時 2.3 秒,而該產品僅需 1 秒,測試在同一機器、相同配置下進行。該商業產品確實優秀,具備 Pg 尚未完全實現或優化的特性,這點無可否認。我們將繼續努力改進。
heapam 改進
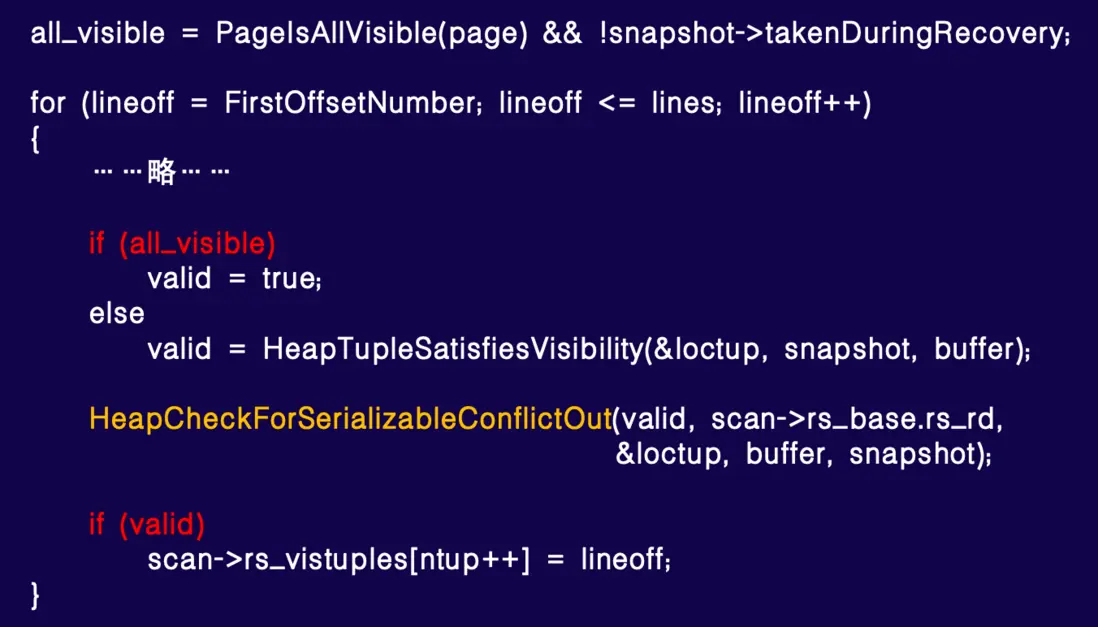
這是 PostgreSQL (Pg) 的一段代碼,用於掃描一個數據塊時,首先檢查塊首的 VM (visibility map) 是否標記為全可見,且通常不發生在恢復過程中。因此,在大多數情況下,如果表的 all_visible 比例較高或改動影響較小,代碼可能跳到此處,相關邏輯基本無用。
我們通過英特爾 VTune 等性能分析工具深入分析這段代碼,發現部分開銷無必要。常規情況下的 HeapTupleSatisfiesVisibility 檢查(標紅部分)以及底部的序列化衝突檢查 HeapCheckForSerializableConflictOut(標黃部分),在 all_visible 為真時,多餘且耗時。標紅的兩個條件判斷及後續函數調用(如序列化事務檢查),在默認或一般場景下幾乎不使用,因此開銷可忽略。

發現這一問題後,我向社區提交了一個補丁(Commit a97bbe1f,Reduce branches in heapgetpage()'s per-tuple loop;),但因晚了約兩個月,期間另一位開發者已提交了類似補丁。應用該補丁後,成功消除了這兩塊冗餘邏輯。
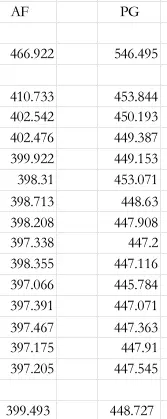
這是我當時進行的測試。AF 代表優化後的版本,PG 為原始版本。測試結果顯示,平均耗時從原先約 450 毫秒降至 400 毫秒,優化幅度顯著。
不過,隨着新技術引入,當時的提升效果跟現在比並不大。但在當時測試中,確實取得了明顯改善。測試使用了一個包含 1,000 萬條記錄的表,通過跳過無關數據逐步掃描,減少其他干擾,最終得出此結果。
從結構上看,每次處理時並非直接提取數據,而是根據可見性記錄每個 block 或配置中哪些項(item)可見。這些記錄(如 item pointers)會先保存下來,再根據元組(tuple)位置逐一提取。此處可能有優化空間,若批量解壓元組,或許能提升效率。目前的邏輯是返回後再次解壓元組,依賴 item pointers 跳轉至具體位置,再進行解壓操作。尤其在 count 操作中,眾所周知這些步驟本無必要,因此優化潛力較大。但受限於當前框架,改動難度較高,改進空間受限。
全表計數
在 PostgreSQL (Pg) 中,可見性視圖位圖(Visibility Map)是眾所周知的功能,包含兩個標誌位:ALL_VISIBLE 和 ALL_FROZEN。當設置 ALL_VISIBLE 時,塊頭(Page Header)中會同時標記一個 PD_ALL_VISIBLE 標誌。這樣,可通過位圖讀取塊的全可見性,也可直接從塊頭確認。
若塊標記為全可見,則可跳過先前邏輯,提前計算。因為一旦 ALL_VISIBLE 被設置,若塊變為不可見,該標誌會被清除。因此,全可見狀態表明塊相對穩定,至少在一段時間內未被修改。

因此,我們採用了一個相對簡單的方法,在頁面頭部新增了一個字段,並在設置 pd_upper 時計算其值。
接下來的優化重點是改進優化器,在路徑選擇時根據表的 all_visible 比例判斷最優路徑。若表非全可見,逐塊訪問效率較低,走索引可能更優。因此,需讓優化器瞭解全表掃描(Seq Scan)的成本可基於 all_visible 比例降低。優化器獲取數據後,Aggregate(agg)通過 next 操作在 Advanced 階段統計,但當前執行器需改進,使其直接獲取塊數量,而非逐條挖掘數據。即使塊全可見,若不優化,傳統邏輯仍需循環處理 item pointers(物理位置指針,指向磁盤存儲位置),提取元組再交給聚合引擎,效率不高。若跳過這些,直接利用 all_visible,可顯著提升性能。
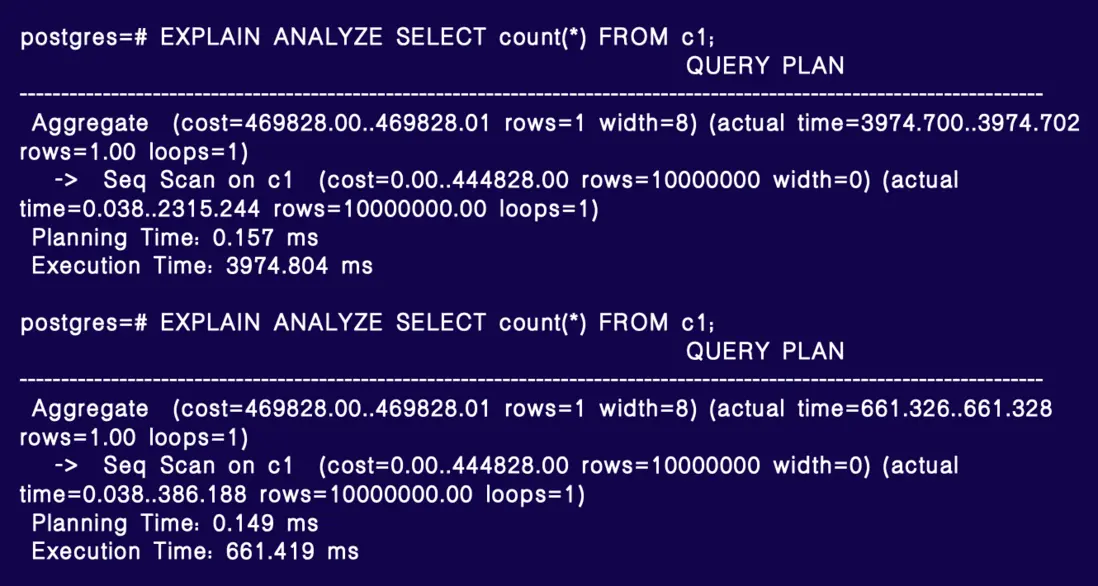
此改動目前不夠優雅,優化器調整尚符合框架,但執行器改動較為生硬。不過,總算解決了用户問題。以 SELECT count(*) 為例,原始耗時約 4 秒,優化後在全可見理想狀態下降至約 661 毫秒(約 1/6),極端情況下可達 10 倍提升,視緩存命中率而定。緩存命中率低時,優化效果更明顯。
此改進針對 count 操作簡單實用,旨在緩解用户頻繁對千萬級表執行 count,大幅減輕 PostgreSQL 壓力。
總結
本文圍繞 PostgreSQL 全表 count 這一核心場景,從現狀分析、技術改進到落地效果展開了完整梳理。
儘管當前執行器改動仍有優化空間(如批量解壓元組的框架限制),但這些實踐已切實解決了用户在千萬級數據表計數中的核心訴求。未來隨着 PostgreSQL 底層框架的進一步迭代,全表 count 的效率仍有提升潛力,而本次從業務痛點出發、基於代碼層與特性層的雙重優化思路,也為後續類似性能問題的解決提供了可參考的實踐路徑。




