









前言
書接上文,經過之前的不懈努力,我們已經有了較為完善的監控系統與告警系統,而prometheus的工作模式就像一個單點,拉取數據回來之後存儲在自己的磁盤上
當監控數據越來越多,那prometheus單點的壓力就會變大,那本文就來討論一下如何降低單點prometheus的壓力
環境準備
| 組件 | 版本 |
|---|---|
| 操作系統 | Ubuntu 22.04.4 LTS |
| docker | 24.0.7 |
| kube-state-metrics | v2.13.0 |
| thanos | 0.36.1 |
水平拆分
水平拆分的目的就是為了拆成多個prometheus,讓單個prometheus負載降低,不要這麼容易掛掉,並且拆成多個之後,就算掛掉一個,其餘的也可以正常工作。比如一個prometheus專門負責節點監控數據採集、一個prometheus專門負責k8s監控數據採集等
1. 根據採集的目標進行拆分
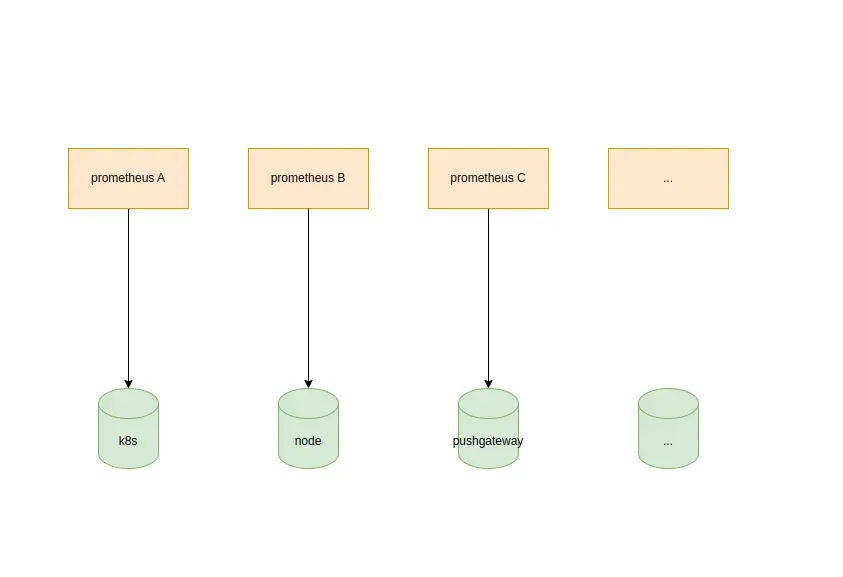
每個業務都有一個prometheus對其進行採集,並且不同prometheus之間解耦
這時候業務部門提出需求,k8s的監控還是太多了,一個prometheus依然不堪重負,那怎麼辦呢?
2. kube-state-metrics拆分
由於k8s是通過kube-state-metrics這個exporter進行採集,所以我們需要對其進行拆分
2.1 根據namespace進行拆分
這個拆分是顯而易見的,不同的namespace採集進入不同的prometheus即可,配置也很簡單,只需要修改kube-state-metrics的啓動參數即可
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- args:
- --metric-labels-allowlist=pods=[*]
- --metric-annotations-allowlist=pods=[*]
- --namespaces=default # 新增
name: kube-state-metrics
image: registry.cn-beijing.aliyuncs.com/wilsonchai/kube-state-metrics:v2.13.0
ports:
- containerPort: 8080
--namespaces=default 告訴kube-state-metrics只採集namespace為default的數據
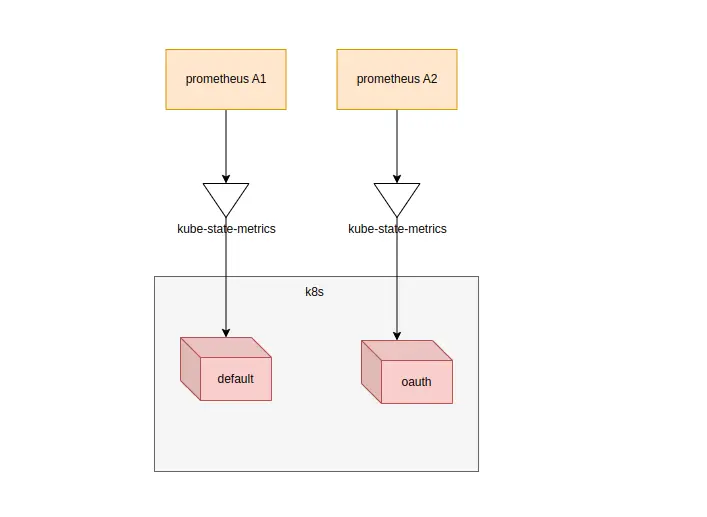
創建多個prometheus以及kube-state-metrics,然後指定採集不同的namespace
這種方法配置簡單,但是分配多個kube-state-metrics的採集策略就比較複雜,一旦業務複雜,namespace多起來之後,也會造成頻繁修改配置,還有沒有更簡單的方法呢?
2.2 kube-state-metrics根據shard拆分
在kube-state-metrics的高版本(具體是哪個版本待查,筆者的版本是v2.13.0),支持了自動分片的採集策略,就是讓多個kube-state-metrics自己去分片,省去人為配置的煩惱
關於水平分片的例子,可以參考 kube-state-metrics
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
name: kube-state-metrics
namespace: kube-system
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- apps
resourceNames:
- kube-state-metrics
resources:
- statefulsets
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
name: kube-state-metrics
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
serviceName: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
spec:
containers:
- args:
- --pod=$(POD_NAME)
- --pod-namespace=$(POD_NAMESPACE)
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: registry.cn-beijing.aliyuncs.com/wilsonchai/kube-state-metrics:v2.13.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
securityContext:
runAsUser: 65534
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metrics啓動起來之後檢查一下metrics的指標數量
▶ curl -s 10.244.0.107:8080/metrics | wc -l
949
▶ curl -s 10.244.0.108:8080/metrics | wc -l
909看起來已經打散到2個節點去了,如果我再增加一個節點,那指標數量又分散了
▶ curl -s 10.244.0.107:8080/metrics | wc -l
702
▶ curl -s 10.244.0.108:8080/metrics | wc -l
733
▶ curl -s 10.244.0.109:8080/metrics | wc -l
663這時候只需要把不同的prometheus配置採集不同kube-state-metrics即可,架構也變成了這個樣子
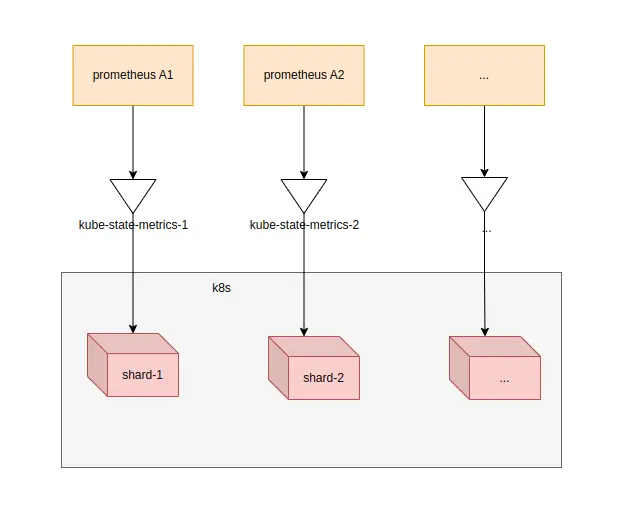
當然kube-state-metrics也是有手動分片模式的,就是通過參數--shard來實現了,只不過有自動分片的話,沒有極致特殊的需求,我們還是用自動分片來處理更加合適
多prometheus數據匯聚
當我們拆分了監控數據,用不同的prometheus來採集的時候,又帶來了新的問題
- 由於prometheus使用本地磁盤存儲數據,所以通過prometheus的web界面查看監控數據時,也只能查看到本prometheus的監控數據,不能跨prometheus查詢監控數據
- 使用grafana添加數據源的時候,就出現了多prometheus數據源的情況,造成管理複雜
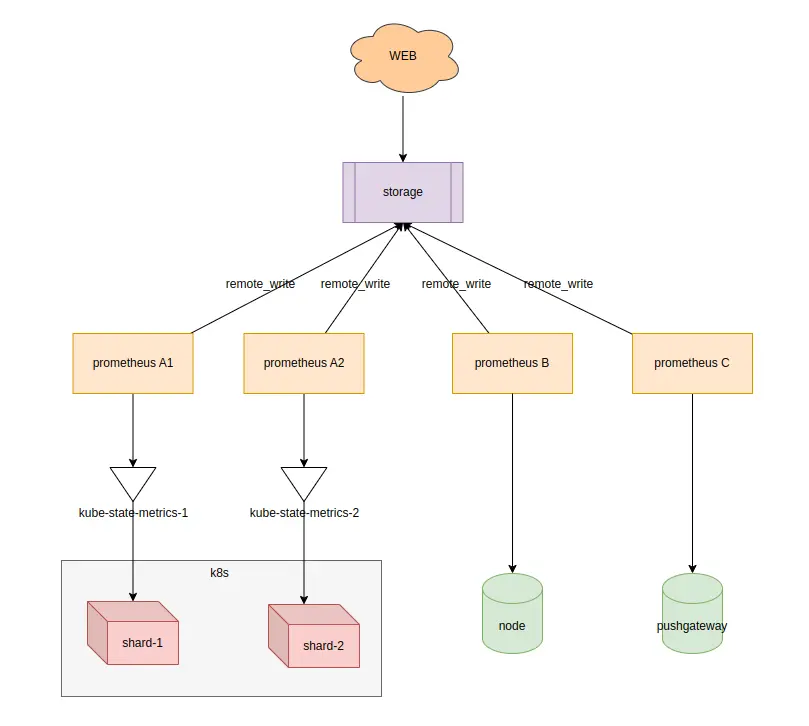
- 有一個公共的storage組件,prometheus通過remote_write的方式,把數據匯聚在這個組件,就可以解決數據分散的問題,並且數據存儲的方式就很靈活了,可以存儲在本地,然後通過傳統的raid做數據備份,也可以直接通過雲 平台的對象存儲保存歷史數據
- 最後再來一個統一的web界面進行查詢,同時這個web界面兼容了prometheus的promQL,並且兼容了prometheus的api,可以直接作為數據源添加至grafana中
- 有這種功能的組件就很多了,比如thanos、cortext、influxDB等等,都可以完成這個工作
小結
- 下一小節,通過thanos來詳細討論一下怎麼做數據匯聚
聯繫我
- 聯繫我,做深入的交流

至此,本文結束
在下才疏學淺,有撒湯漏水的,請各位不吝賜教...



