









0.前言
在護網的過程中,經常需要反向連接,就有可能連接到域名上,所以可以做一個識別,判斷是不是一些APT組織通過一些批量的代碼生成的惡意域名。
1.樸素貝葉斯
樸素貝葉斯算法原理:其實樸素貝葉斯方法是一種生成模型,對於給定的輸入x,通過學習到的模型計算後驗概率分佈P ,將後驗概率最大的類作為x的類輸出。
舉個例子,a : 1(a的值是1) 對應的標籤是0,a的值是1那麼標籤為0的概率是多少?
優點:樸素貝葉斯模型發源於古典數學理論,有穩定的分類效率。 對小規模的數據表現很好,能個處理多分類任務,適合增量式訓練,對缺失數據不太敏感,算法也比較簡單,常用於文本分類。
缺點:理論上,樸素貝葉斯模型與其他分類方法相比具有最小的誤差率,但是實際上並非總是如此,這是因為 樸素貝葉斯模型給定輸出類別的情況下,假設屬性之間相互獨立,也就是數據得是離散的,這個假設在實際應用中往往是不成立的,在屬性個數比較多或者屬性之間相關性較大時,分類效果不好。而在屬性相關性較小時,樸素貝葉斯性能最為良好。
需要知道先驗概率,且先驗概率很多時候取決於假設,假設的模型可以有很多種,因此在某些時候會由 於假設的先驗模型的原因導致預測效果不佳。
由於是通過先驗和數據來決定後驗的概率從而決定分類,所以分類決策存在一定的錯誤率。 對輸入數據的表達形式很敏感。
補充
1.高斯貝葉斯分類器: 在高斯樸素貝葉斯中,每個特徵都是連續的,並且都呈高斯分佈。高斯分佈又稱為正態分佈。 GaussianNB 實現了運用於分類的高斯樸素貝葉斯算法。特徵的可能性(即概率)假設為高斯分佈。
2.多項式貝葉斯分類器: 實現服從多項分佈數據的貝葉斯算法,是一個經典的樸素貝葉斯在文本分類中使用的變種,其中的數據是通常表示為詞向量的數量,雖然 TF-IDF 向量在實際項目中表現得很好。
3.伯努利貝葉斯分類器:實現了用於多重伯努利分佈數據的樸素貝葉斯訓練和分類算法,即有多個特徵,但每個特 徵 都假設是一個二元變量。 因此,這類算法要求樣本以二元值特徵向量表示;如 果樣本含有其他類型的數據, 一個 BernoulliNB 實例會將其二值化(取決於 binarize 參數)。
先驗概率
先驗概率是指在沒有任何額外信息的情況下,事件發生的概率。在貝葉斯分類器中,先驗概率通常表示 為類別的先驗概率,即在沒有觀察到任何特徵的情況下,某個類別發生的可能。
from collections import Counter
# 假設我們有一個標籤列表
labels = ["cat", "dog", "cat", "dog", "dog", "cat"]
# 計算先驗概率
label_counts = Counter(labels)
total_samples = len(labels)
priors = {label: count / total_samples for label, count in label_counts.items()}
print("Prior probabilities:", priors)提前看標籤的分佈,那麼整個數據裏面先驗概率貓佔比50%,狗佔比50%。
沒有任何的數據,也沒有任何特徵,就只有個標籤做一個統計。
後驗概率
後驗概率是在給定一些觀察結果後,事件發生的概率。在貝葉斯分類器中,後驗概率 𝑃(ci∣x)P(Ci∣X) 表示在觀察到特徵 xX 的情況下,類別 ciCi 發生的概率。
import numpy as np
# 假設我們有特徵的概率分佈
# 特徵x的概率在類別Ci下
p_x_given_c = {
"cat": {"feature1": 0.7, "feature2": 0.2},
"dog": {"feature1": 0.3, "feature2": 0.8}
}
# 計算後驗概率
def calculate_posterior(features, priors, p_x_given_c):
posteriors = {}
for label, prior in priors.items():
likelihood = np.prod([p_x_given_c[label].get(f, 1.0) for f in features])
# 使用features列表中的f
joint_probabilities = {}
for lab in priors.keys():
joint_prob = np.prod([p_x_given_c[lab].get(f, 1.0) for f in
features]) # 計算每個類別的聯合概率
joint_probabilities[lab] = joint_prob * priors[lab]
# 計算歸一化常數P(x)
p_x = sum(joint_probabilities.values())
# 使用歸一化常數計算後驗概率
posterior = (likelihood * prior) / p_x if p_x > 0 else 0
posteriors[label] = posterior
return posteriors
# 觀察到的特徵
x = ["feature1", "feature2"]
# 計算後驗概率
posteriors = calculate_posterior(x, priors, p_x_given_c)
print("Posteriors:", posteriors)聯合概率
聯合概率是指多個事件同時發生的概率。在樸素貝葉斯中,我們假設特徵之間相互獨立,因此可以計算特徵的聯合概率。
# 計算聯合概率
def calculate_joint_probability(features, p_x_given_c):
joint_probabilities = {}
for label, feature_probs in p_x_given_c.items():
joint_prob = 1
for feature in features:
feature_prob = feature_probs.get(feature, 1) # 特徵不存在時,概率為1
joint_prob *= feature_prob
joint_probabilities[label] = joint_prob
return joint_probabilities
# 計算聯合概率
joint_probs = calculate_joint_probability(x, p_x_given_c)
print("Joint probabilities:", joint_probs)DGA
惡意域名批量生成生成的域名都有類似的規律。
-
長度
-
特殊字符的使用 數量、位置。
-
熵
-
數字與字母結合的規律,幾個數字與幾個字符。
2.使用樸素貝葉斯識別惡意域名
首先收集一些APT組織生成的惡意域名。
長度都是差不多的,隨機生成的,這些是黑域名,那肯定就有白域名了。
數據收集完之後就可以先來加載數據。
import csv
import numpy as np
#處理域名的最小長度
MIN_LEN=10
def load_alexa(filename):
domain_list=[]
csv_reader = csv.reader(open(filename))
for row in csv_reader:
domain=row[1]
if len(domain) >= MIN_LEN:
domain_list.append(domain)
return domain_list
def load_dga(filename):
domain_list=[]
#xsxqeadsbgvpdke.co.uk,Domain used by Cryptolocker - Flashback DGA for 13 Apr 2017,2017-04-13,
# http://osint.bambenekconsulting.com/manual/cl.txt
with open(filename) as f:
for line in f:
domain=line.split(",")[0]
if len(domain) >= MIN_LEN:
domain_list.append(domain)
return domain_list
x1_domain_list = load_alexa("../data/top-1000.csv")
x2_domain_list = load_dga("../data/dga-cryptolocke-1000.txt")
x3_domain_list = load_dga("../data/dga-post-tovar-goz-1000.txt")
x_domain_list=np.concatenate((x1_domain_list, x2_domain_list,x3_domain_list))
y1=[0]*len(x1_domain_list)
y2=[1]*len(x2_domain_list)
y3=[2]*len(x3_domain_list)
y=np.concatenate((y1, y2,y3))
print(x_domain_list)過濾掉小於10個字符的域名,畢竟APT組織生成的域名都不會小於10個字符的。
【----幫助網安學習,以下所有學習資料免費領!加vx:YJ-2021-1,備註 “博客園” 獲取!】
① 網安學習成長路徑思維導圖
② 60+網安經典常用工具包
③ 100+SRC漏洞分析報告
④ 150+網安攻防實戰技術電子書
⑤ 最權威CISSP 認證考試指南+題庫
⑥ 超1800頁CTF實戰技巧手冊
⑦ 最新網安大廠面試題合集(含答案)
⑧ APP客户端安全檢測指南(安卓+IOS)
將讀到的域名添加到列表中去,然後把所有的列表做一個組合。
然後給每一個數據打上標籤,正常樣本 0 惡意樣本1 2 。
然後把這些字符串轉化為數學上可以表達的東西。
import pickle
import load_data
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
cv = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",
token_pattern=r"\w", min_df=1)
x= cv.fit_transform(load_data.x_domain_list).toarray()
np.savetxt("../model/data_x.csv", x, delimiter=",")
np.savetxt("../model/data_y.csv", load_data.y, delimiter=",")
with open('../model/cv.pickle','wb') as f:
pickle.dump(cv,f) #將訓練好的模型clf存儲在變量f中,且保存到本地使用CountVectorizer將字符串轉化為詞袋集,然後看其出現的頻率和頻次。
然後將數據丟給fit_transform分類器,再將其轉換為numpy一維矩陣。
數據處理完就該到模型部分了。
from sklearn.naive_bayes import GaussianNB
import model_param
clf = GaussianNB(priors=model_param.nb_param["priors"],var_smoothing=model_param.nb_param["var_smoothing"])模型結構用的高斯樸素貝葉斯。
模型訓練
from sklearn.model_selection import train_test_split
import numpy as np
import model_struct
import pickle
x = np.genfromtxt("data_x.csv",delimiter=",")
y = np.genfromtxt("data_y.csv",delimiter=",")
x_train, x_test , y_train, y_test = train_test_split(x, y, test_size = 0.3)
save_model = model_struct.clf.fit(x_train,y_train)
# 模型的保存
with open('nb.pickle','wb') as f:
pickle.dump(save_model,f) #將訓練好的模型clf存儲在變量f中,且保存到本地模型測試
import pickle
from sklearn.model_selection import cross_val_score
import numpy as np
import matplotlib.pyplot as plt
with open('../nb.pickle', 'rb') as f:
clf_load = pickle.load(f) # 將模型存儲在變量clf_load中
x = np.genfromtxt("../data_x.csv",delimiter=",")
y = np.genfromtxt("../data_y.csv",delimiter=",")
# 交叉驗證
scores = cross_val_score(clf_load, x, y, cv=10, scoring='accuracy')
# 11111
# 00001
print(scores.mean())
plt.bar(np.arange(10),scores,facecolor='yellow',edgecolor='white') # +表示向上顯示
for x,y in zip(np.arange(10),scores):
plt.text(x,y+0.05, '%.2f' % y,ha='center',va= 'bottom') # '%.2f' % y 保留y的兩位小數 ha='center' 居中對齊 va= 'bottom' 表示向下對齊 top向上對齊
plt.ylim(0,1.1)
plt.show()模型測試結果:
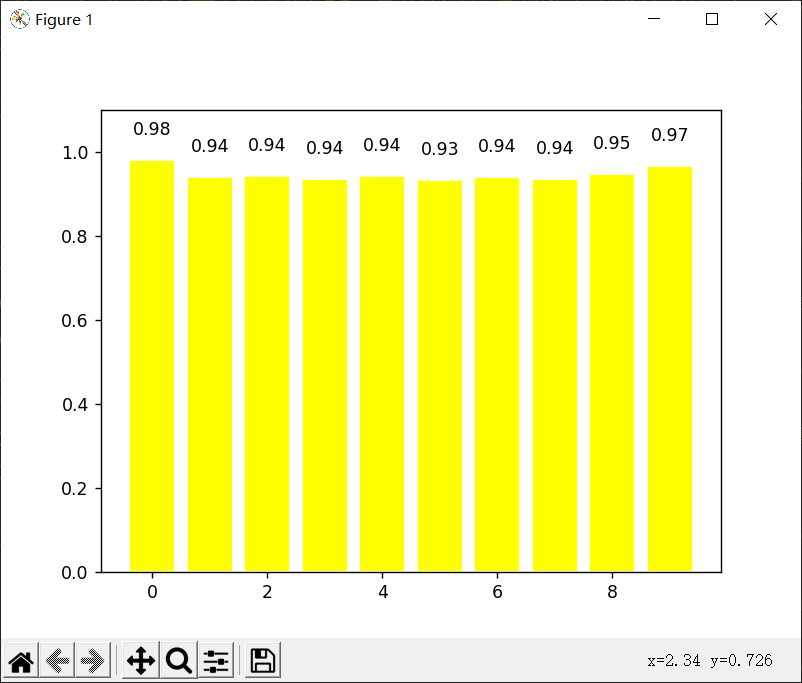
每一次運算的得分,整體的正確率在94.7%。
使用測試:
import sys
import config
sys.path.append(config.syspath)
import config
import pickle
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
def load_and_vec_data():
content = input("請輸入要識別的域名:")
input_data = [str(content)]
with open('../cv.pickle', 'rb') as cv:
cv = pickle.load(cv)
x= cv.transform(input_data).toarray()
print(x)
return x
# 加載模型
with open('../nb.pickle', 'rb') as f:
clf_load = pickle.load(f)
# 使用模型進行預測
prediction = clf_load.predict(load_and_vec_data())
print("預測結果:", prediction)輸入域名,轉換成數組,加載分類器。

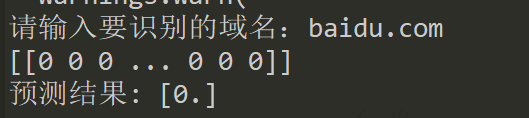
可以看到實現了正常域名和惡意域名的識別分類。
做一個可視化出來。
from flask import Flask, render_template, request, redirect, url_for
import predict_data_vec
import pickle
app = Flask(__name__, static_url_path='/static')
@app.route('/')
def index():
return render_template('index.html')
@app.route('/process', methods=['POST'])
def process():
user_input = request.form['text_input']
# 這裏可以添加你的處理邏輯
x = predict_data_vec.load_and_vec_data(user_input)
# 加載模型
with open('../model/nb.pickle', 'rb') as f:
clf_load = pickle.load(f)
# 使用模型進行預測
prediction = clf_load.predict(x)
if prediction == [0.]:
prediction = '合法域名'
# 放過
else:
prediction = '非法域名'
result = "處理結果: " + str(prediction) # 示例處理邏輯
return redirect(url_for('result', result=result))
@app.route('/result/<result>')
def result(result):
return render_template('result.html', result=result)
if __name__ == '__main__':
app.run(debug=True)使用flask框架。

這裏其實還是存在數據不足的問題,會導致模型精確度不夠。
所以還是要主動去搜集惡意域名,得有個幾十萬數據可能才能夠讓模型有97%的準確率。
如果覺得還是不夠穩,可以在AI判斷完之後再添加個人工判斷,AI覺得是非法域名,可以彈個窗或者發個消息通知。
用人的方式去理解到底是不是惡意域名,就是告警處理。
更多網安技能的在線實操練習,請點擊這裏>>



