

背景
RAG(Retrieval-Augmented Generation)技術通過結合信息檢索與大模型生成能力,可以有效降低“幻覺率”,提升回答的準確性。目前,RAG 技術已廣泛應用於多個領域,但主要集中於文本數據的處理。隨着視覺語言模型(Vision-Language Models, VLM)和多模態向量模型的快速發展,RAG 的應用邊界正在不斷擴展,逐步從傳統的純文本場景延伸至多模態場景,其應用邊界已擴展至視頻等非結構化數據。視頻 RAG 正是在這種背景下應運而生,它通過解析視頻內容,提取其中的語義信息,並將其納入到 RAG 流程中,為用户提供基於視頻知識的智能問答與內容理解能力。
而視頻作為高信息密度載體,廣泛應用於教育、安防、直播等領域,但其語義解析與多模態融合仍面臨挑戰。視頻 RAG 的核心在於對視頻內容的處理與多模態信息的融合,其典型流程如圖1所示。下面將詳細介紹下 OpenSearch LLM 版中視頻 RAG 的具體實現流程。
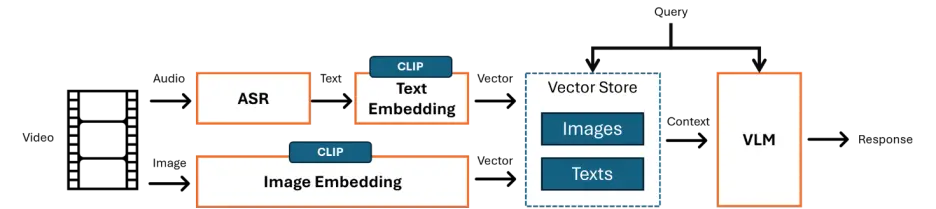
圖1 視頻 RAG 基本流程
離線流程
與傳統 RAG 類似,分為解析→切片→向量化→索引構建四部分(圖2)。下面將逐一介紹。
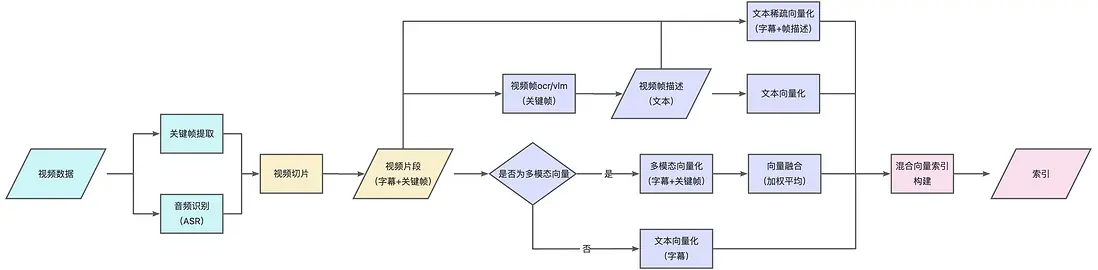
圖2 視頻 RAG 離線處理流程(不同顏色代表不同階段)
1. 視頻解析
視頻解析主要包括兩個核心任務:關鍵幀提取和音頻識別(Audio Speech Recognition, ASR),旨在從原始視頻中提取出具有語義價值的視覺與語音信息,為後續的檢索提供高質量的數據輸入。
1.1 關鍵幀提取
關鍵幀是指能夠表示視頻內容變化的代表性幀圖像,通常出現在場景切換或視覺顯著變化的時刻。通過提取關鍵幀,可以在不損失主要信息的前提下,大幅減少數據冗餘,提升處理效率。
常見的關鍵幀提取方法包括:
• 固定幀率抽樣
按照設定的時間間隔(如每秒1幀)對視頻進行均勻採樣,然後根據幀之間的相似度(如基於圖像嵌入向量的餘弦相似 度)進行去重,保留最具代表性的幀。
• 基於視覺差異
通過計算相鄰幀之間的視覺差異(如直方圖差異、SSIM 等),檢測出畫面突變點作為關鍵幀。
這裏將兩種方法進行了組合使用,以兼顧精度和效率。
1.2. 音頻識別(ASR)
音頻識別(ASR)是將視頻中的語音內容轉譯為文本序列的過程。這一過程首先需要從視頻中分離出音頻軌道,隨後利用語音識別模型(如 Whisper)將其轉換為可讀的文字內容(字幕)。
從後續的向量化過程可以發現,ASR 結果十分關鍵,因為它為後續的檢索與生成提供了直接的輸入來源,而關鍵幀僅作為視覺維度上的一個補充。
2. 視頻切片
在完成關鍵幀提取和音頻識別之後,下一步是將原始視頻分割為多個語義相對完整、時間跨度合理的視頻片段單元。
2.1. 切片生成策略
實際上每個關鍵幀都對應了一段起止時間,即對應了一個視頻片段。然而,這些初始片段可能過於短暫,無法有效承載完整的語義內容。因此需要一些後處理策略對片段進行合併與優化:
• 基於 ASR 結果
將相鄰的視頻片段根據 ASR 識別出的語音文本進行語義關聯,若兩個片段在時間上連續且語義相關,則將其合併為一個更大的切片。
• 基於時間窗口
設定一個合理的時間閾值(如10秒),將短於該閾值的片段與其前後鄰近片段進行整合,以形成更大的語義單元。
2.2. 切片數據結構
切片完成後,每個視頻切片包含以下三個核心信息:
- 元信息:包括該切片的起始時間和結束時間,用於定位其在原視頻中的位置。
- 字幕內容:ASR處理後的語音轉文字的結果,記錄了該切片中出現的對話或旁白內容。
- 關鍵幀序列:因為上述的片段合併策略,所以一個切片中可能包含多個關鍵幀。
3. 切片向量化
3.1 單/多模態向量化(主鏈路)
根據用户配置的向量模型類型是否為多模態,系統採用不同的向量化策略以實現向後兼容性和靈活性:
• 多模態向量化
當使用多模態向量模型時,先分別對切片中的字幕內容和關鍵幀序列進行向量化,然後將字幕embedding 和關鍵幀 embedding 進行融合,這裏採用加權平均的方式,得到最終視頻切片的embedding。
• 單模態向量化(向後兼容)
若使用的是僅支持文本的向量模型,則僅基於字幕內容進行向量化,直接將字幕 embedding 作為視頻切片的 embedding 表示。
3.2 細節強化(輔鏈路)
考慮到單一視頻切片的 embedding 可能因信息過載而忽略某些細節,系統引入了另一條細粒度向量化鏈路作為補充:
- 每個關鍵幀被單獨視為一個獨立切片單元;
- 利用圖像理解技術(如 OCR 或 VLM)將其轉換為描述性文本;
- 對生成的文本進行向量化處理,形成關鍵幀級別的 embedding。
目的是保留視頻中關鍵幀的細節信息,為高精度匹配場景提供支持(如效果展示中的第一個例子)。
3.3 稠密 + 稀疏混合表示
除了稠密向量表示,系統還對每個切片的文本部分進行了稀疏向量化處理,用來表達關鍵詞和權重信息,形成稠密+稀疏的混合表示。
4. 混合索引構建
最後進行稠密和稀疏向量的混合索引構建。這裏直接複用 OpenSearch 向量檢索版的混合檢索 能力,如圖3所示。
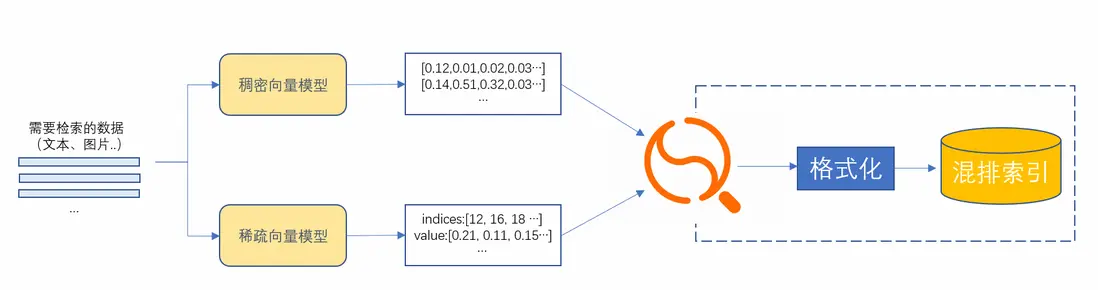
圖3 OpenSearch 向量檢索版混合向量索引構建
在線流程
這裏以 Naive RAG 為例,分為向量化→召回→AI生成三部分(圖4)。也可以接入 Rerank、Deep Search 等高階能力。

圖4 視頻 RAG 在線流程(不同顏色代表不同階段)
首先,對用户的文本查詢進行稠密與稀疏向量表示,使用的模型需與離線處理階段保持一致。
然後利用 OpenSearch 向量檢索版混合檢索能力,召回到視頻切片和關鍵幀描述切片(對應離線流程中的兩條向量化鏈路)。
最後根據户選擇的生成模型是否具備多模態處理能力組織上下文輸入。如果支持多模態能力,則將召回的視頻切片中的字幕文本、關鍵幀圖像以及關鍵幀描述文本一併作為輸入;如果不支持多模態能力則只使用字幕文本和關鍵幀描述文本,忽略圖像信息。生成模型基於整合後的上下文信息,生成符合用户需求的回答。
效果展示
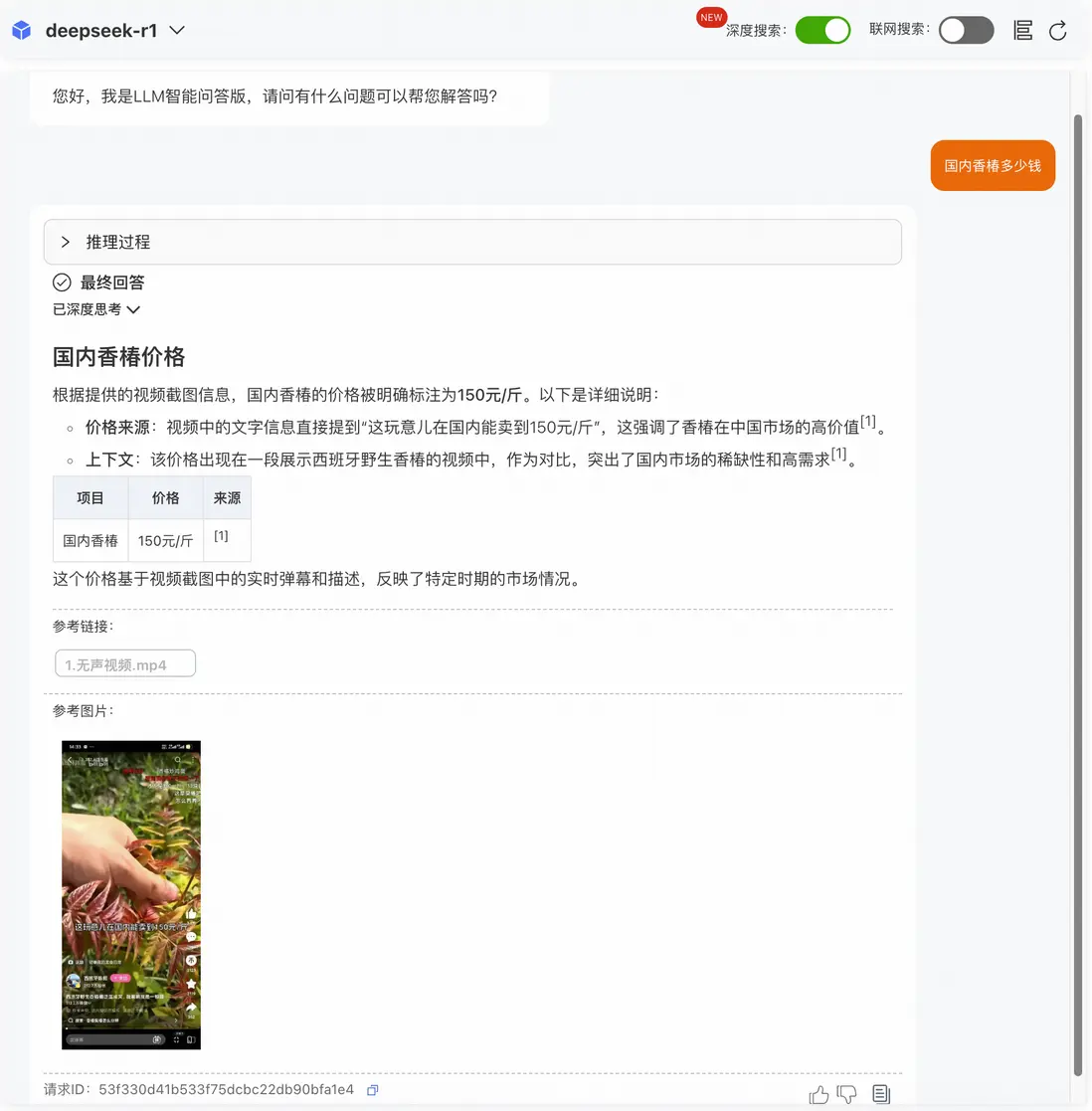
示例1:高精度匹配場景,問題答案出現在某一關鍵幀中
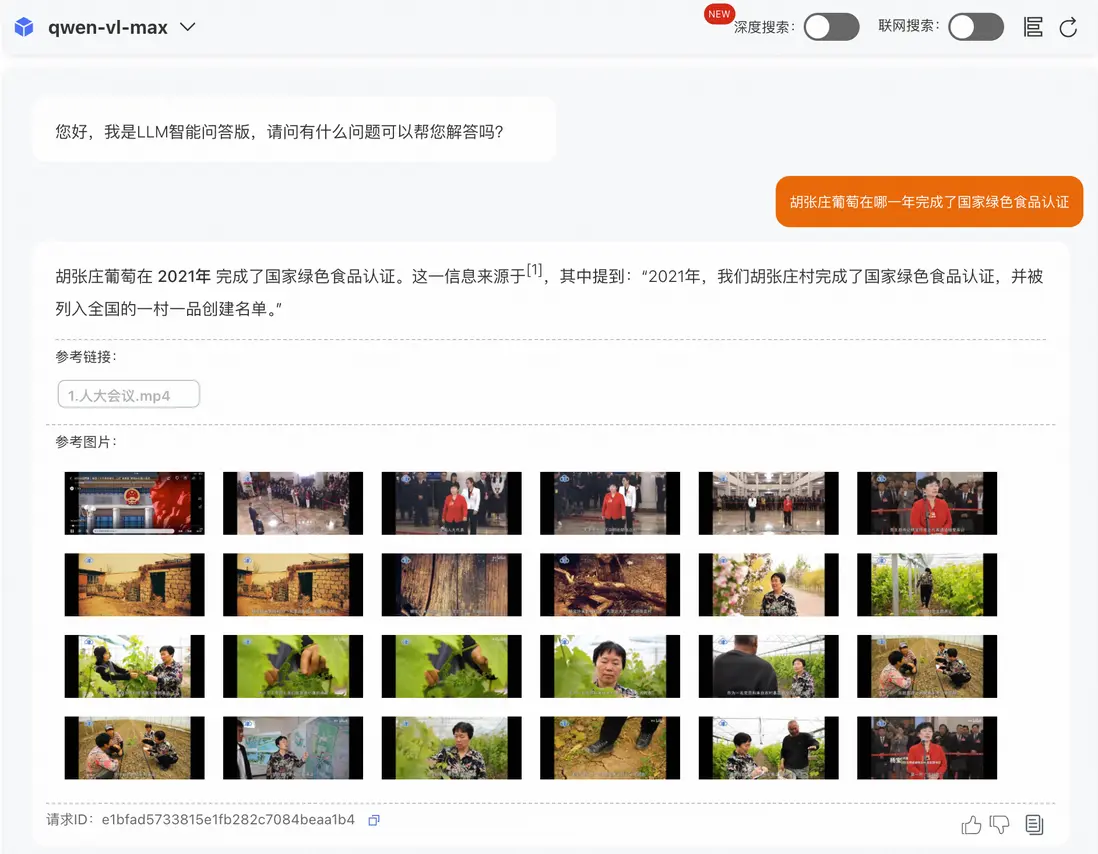
示例2:問題答案出現在視頻語音中
結尾
視頻 RAG 本質上是對數據源類型的擴充,從傳統的 PDF、Word等 文本進一步擴展到視頻領域。然而,在實踐過程中,也容易遇到以下問題:
• 文本召回性能下降。 由於另一種模態的數據加入,在文本和視頻兩種模態數據都存在的場景下,對多模態向量化模型提出了更高的要求。雖然多模態模型能融合視覺與文本信息,但其在純文本檢索任務上的表現往往不如專用的文本向量化模型。這可能導致在文本主導的問答任務中,出現語義匹配精度下降的問題。
• 另一方面,長視頻處理效率低。 相比文本數據,視頻數據體量更大,處理時間顯著增加,尤其對於長視頻,離線處理時間可能需要幾十分鐘甚至更久。而且視頻解析過程涉及大量的深度學習模型(如ASR、VLM等),計算開銷大。為了加速視頻解析,需依賴GPU等高性能算力,對部署成本要求更高。
OpenSearch LLM 版通過創新的視頻解析流程與多模態融合策略,為這些問題提供了可行的解決方案。未來,隨着多模態模型效率的提升與視頻處理技術的迭代,視頻RAG有望進一步突破邊界,成為多模態智能問答領域的核心技術支柱,推動非結構化數據的價值釋放與應用場景的持續擴展。
• 瞭解更多:OpenSearch(免費試用)