

一、智能駕駛數據預處理的行業挑戰
隨着智能駕駛技術的逐級演進,數據驅動的模型訓練範式對數據預處理環節提出三大挑戰:
- 數據孤島化:需整合攝像頭、LiDAR、毫米波雷達、V2X通信等多模態數據,傳統ETL工具難以實現高效集成。
- 任務爆炸式增長:單輛測試車每日產生可達50TB 數據,需支持百萬甚至千萬級任務併發調度與彈性擴容。
- 開發運維一體化需求:要求數據流水線具備高可用性(99.99% SLA)、動態彈性擴容能力,併兼容TensorFlow、PyTorch 等 AI 框架。
在智駕數據處理與開發方案中,大數據開發治理平台 DataWorks 可在數據集成、開發與任務調度階段,提供一站式的開發、調度與治理能力,支持數據研發工程師進行數據建模開發、任務調度、數據資產管理等操作,確保數據能夠被高效地處理和利用,可支持對海量數據的千萬級任務調度與管理,為智能駕駛的數據分析和模型訓練奠定基礎。
二、DataWorks核心能力解析
千萬級任務調度引擎:破解數據洪流困局
當前,智能駕駛數據處理或開發階段的調度技術方案普遍基於 Airflow/Argoflow 任務調度引擎或腳本等方式對任務進行調度,萬級任務場景下 Argo Workflow 因任務依賴嵌套和資源鎖衝突產生調度延遲,單日任務吞吐量難以突破 10 萬量級,同時當資源配額衝突或需要跨系統調優時需額外投入研發資源處理,運維壓力極大,使得整個智能駕駛生產線遭遇性能瓶頸。
DataWorks 超大規模週期性任務調度系統可支撐日千萬級調度,久經阿里巴巴“雙11”考驗,性能與穩定性業界領先。
DataWorks 相較於 Argo & Airflow,對比和功能差異如下:
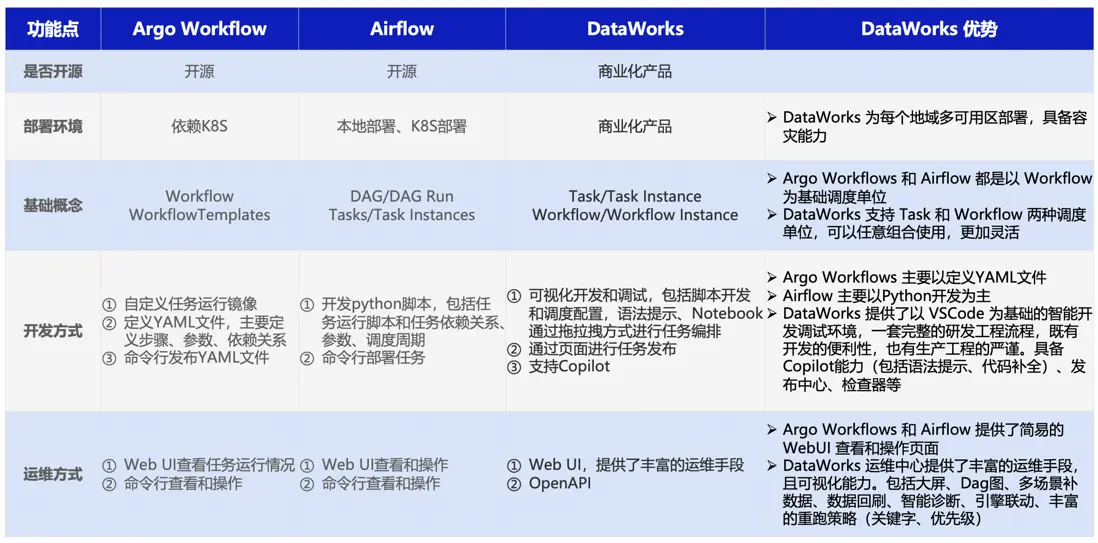
Argo vs Airflow vs DataWorks功能對比表
DataWorks可通過以下能力實現海量數據下的千萬級任務調度,為智能駕駛的數據分析和模型訓練奠定基礎。
- 分鐘/小時/天/周/月/年週期調度
- 觸發式調度,可自定義調度日曆
- 數據預處理任務與算法任務的統一編排與調度,支持跨多種計算引擎的可視化任務流程編排
- 循環/分支/歸併等流程控制任務,賦值節點、上下文傳參,調度參數、工作空間全局參數
- 跨週期任務依賴,依賴成環與孤立節點自動檢測
- 任務出錯可自動重試
藉助 DataWorks 自研一站式大數據運維監控平台,支持實時查看任務運行狀態,提供智能診斷、重跑等運維操作,幫助用户對異常任務進行基礎運維;提供智能基線,可解決重要任務產出時間不可控,海量任務監控難的問題,保障任務產出的時效性;提供調度、資源等多方位的運維能力,輕鬆管理和管理調度任務。
數據集成:多領域數據匯聚
在進行智能駕駛數據預處理時,需要將多源數據進行整合,進行數據建模開發、數據血緣及數據資源管理。
DataWorks 的數據集成功能模塊是穩定高效、彈性伸縮的數據同步平台,致力於提供複雜網絡環境下、豐富的異構數據源之間高速穩定的數據移動及同步能力。支持離線同步、實時同步,以及離線和實時一體化的全增量同步。採用星形引擎架構,數據源接入數據集成後,即可與其他各類型數據源組成同步鏈路進行數據同步。適用於數據入湖入倉、分庫分表、實時數據歸檔、雲間數據流轉等數據傳輸場景。

引擎架構
在智能駕駛數據預處理解決方案中,通過以下能力實現多源數據集成,構建統一數據湖倉:
- 覆蓋豐富異構數據源:支持 MySQL、Oracle、MongoDB、MaxCompute、Hologres、OSS、Kafka 等幾十種數據源直連;
- 豐富的同步方案:數據入湖、整庫遷移、增量同步、分庫分表同步、全增量一體化同步;
- 離線同步提供數據讀取(Reader)和寫入插件(Writer),以實現對數據源的讀寫操作。
- 實時同步支持將多種輸入及輸出數據源搭配組成同步鏈路進行單表或整庫數據的實時增量同步。
- 提供多種數據源之間進行不同數據同步場景(整庫離線同步、全增量實時同步)的同步。
全鏈路數據開發能力:構建標準化預處理流水線
數據開發 Data Studio 是阿里巴巴基於10餘年大數據建設經驗打造的智能湖倉一體數據開發平台,兼容阿里雲多項計算服務,提供智能化 ETL、數據目錄管理及跨引擎工作流編排的產品能力。通過個人開發環境實例支持 Python 開發、Notebook 分析與 Git 集成,Data Studio 還支持豐富多樣的插件生態,實現了實時離線一體化、湖倉一體化、大數據AI一體化,助力“Data+AI”全生命週期的數據管理。

數據開發平台全景圖
通過以下能力實現智能駕駛數據預處理一體化開發效率提升。
- 可視化工作流編排:通過可視化拖拽方式整合多種類型的子任務節點,便捷地建立任務上下游關係,加速數據處理流程的搭建,可快速構建端到端數據流,有效提升任務開發效率;
- 湖倉一體多引擎協同數據開發平台:支持湖與倉統一元數據管理、數據入湖、統一數據開發 WebIDE、統一任務編排調度;
- Data+AI協同開發:支持數據集成、Notebook、Python、Shell、MaxCompute、Hologres、Flink、EMR、AI 算法等多種節點的開發,支持支持自定義個人開發環境容器鏡像,全面支持 Python 開發生態,支持大數據計算引擎 SQL 與 Python 交互式協同開發;
- DataWorks Copilot 智能助手:全面推出 DataWorks Copilot 智能助手,支持各類計算引擎 SQL 及Python 的代碼生成與補全;通過豐富的 AI Agents 提供自然語言交互界面(LUI),為數據開發全面提效;
數據資產管理:打造智能駕駛數據資產全景圖
DataWorks的數據治理模塊可對智能駕駛業務中的結構化數據和非結構化數據進行統一的管理。
- 元數據服務:幫助用户進行智能駕駛相關數據資產的有序組織,通過類目導航、數據專輯等方式從全局或專業視角對數據進行分類管理,同時根據表、字段、指標、描述等多元素全局搜索能力,查看基礎元模型、Schema詳情、產出信息、熱度信息、使用記錄、業務描述、使用説明等數據的詳細信息,從而實現快速查找數據、理解數據和使用數據,助力數據的便捷消費。
- 數據血緣: 從原始數據文件到訓練數據集,從模型訓練到模型的部署和在線推理服務,DataWorks可實現Data+AI 資產全鏈路血緣端到端還原,追溯模型訓練涉及的數據/任務,加速智能駕駛數據處理與開發的持續迭代。
三、典型應用場景:某智駕端到端數據產線百萬級任務調度
某智駕場景需對採集的數據進行清洗、轉換和準備等工作,生成對模型訓練有用的數據,自建 Airflow 調度方案存在無法穩定運行、無法提供任務監控、無法按時產出等痛點,需要實現百萬級的任務管理、開發調度及數萬任務併發運行能力、對結構化、非結構化元數據統一管理能力、數據產線關鍵指標監控能力、調度穩定性和高可用能力。通過阿里雲 DataWorks 技術方案完成對Airflow替換,支持快速推進端到端智駕方案量產。
業務價值:
- 調度規模:DataWorks 支持百萬級任務管理及開發調度,現階段支持上萬任務併發運行,產能達到數萬 clips/天,持續突破調度瓶頸;
- 混合調度:DataWorks 支持CPU/GPU資源任務混合調度,涵蓋主流GPU資源;
- 智能監控:DataWorks 提供智能基線/自定義規則等監控手段和多種觸達方式,其中智能基線為業界首創;
- 產出耗時: DataWorks 通過單任務多 worker 並行優化,大幅降低子任務數,降低20%環境準備耗時,提升穩定性,通過算子優化、數據集掛載優化等手段,相同資源下,產能提升1倍;
- 元數據:DataWorks 支持對結構化、非結構化元數據統一管理;
- Data+AI:DataWorks 支持 MaxCompute、PAI、Python 等多個節點類型的海量任務調度;
四、未來展望:從數據預處理到車雲協同的智能化升級
未來,DataWorks將進一步拓展智能駕駛場景,通過持續強化數據集成、千萬級調度與大數據AI一體化開發,驅動智能駕駛技術進入“數據定義駕駛智慧”的新紀元。