

作者:流利説 Ibson(大數據負責人)/ Bruce(數據工程師)
背景介紹
-
行業
- 流利説是領先的科技驅動的教育公司,公司自主研發了領先的英語口語評測、寫作打分引擎和深度自適應學習系統,致力於為用户提供一整套系統性的英語學習解決方案,從聽、説、讀、寫多個維度提升用户的英語水平。
-
業務特徵
- AI 打分:利用大數據和人工智能算法對用户英語口語評測、寫作打分。
- 個性化推薦:根據用户學習目標及評級,自動推薦專項和強化課程內容。
- 數據驅動:通過分析用户畫像和學習效果,優化推薦策略,提升用户滿意度。
-數據運營:基於大數據及用户特徵,提高運行效率,提升用户黏度及用户滿意度。
-
原有架構痛點
- 彈性資源管理問題:資源配置不夠靈活,定時定量彈出,任務提交高峯會出現任務等待,低峯時段資源利用率低。
- 費用問題:Master 和 Core 節點為常駐節點,空閒時仍會產生費用,導致成本增加。
- 性能問題:當前架構缺乏類似於 Fusion 的加速技術,部分任務執行速度較慢,尤其是在處理大規模數據時。
- 運維問題:多組件架構使得故障排查和恢復變得複雜,增加了運維的工作負擔。
- 監控問題:僅包含集羣層面及組件的監控,缺乏對 Spark 任務狀態及資源監控。
- 擴容問題:臨時需求需手動擴容,擴容響應較慢。
為了應對新的業務挑戰,流利説選擇與阿里雲合作,利用其 EMR Serverless Spark ,構建了符合業務場景和分析師習慣的工程解決方案。
為什麼選擇阿里雲 Serverless Spark
EMR Serverless Spark 是一款面向 Data+AI 的高性能 Lakehouse 產品。它為企業提供了一站式的數據平台服務,包括任務開發、調試、調度和運維等,極大地簡化了數據處理和模型訓練的全流程。同時,它100%兼容開源 Spark 生態,能夠無縫集成到客户現有的數據平台。使用 EMR Serverless Spark,企業可以更專注於數據處理分析和模型訓練調優,提高工作效率。
- 元數據管理:支持對接外部 Hive MetaStore 元數據服務。
- 調度引擎支持:提供了市場主流調度引擎集成,例如 Airflow 和 DolphinScheduler 等。
- 完善的周邊服務:提供全面的監控和告警功能,能夠實時跟蹤任務狀態和性能,及時發現並解決問題。
- 託管彈性伸縮功能:自動調整資源,減少手動干預。
- 集羣穩定性:由雲服務商管理,提供高穩定性和可靠性。
- 彈性資源管理:按需進行分配資源,避免資源浪費。
- 按需計費:僅為實際使用的資源付費,降低成本。
- 快速啓動:無需預配置資源,能夠快速啓動和運行任務。
- 自動擴展:根據工作負載自動調整資源,提升靈活性。
- 性能優化:Serverless Spark 通過技術如 Fusion 加速任務執行,提高效率,降低成本。
- Shuffle 性能:內置 Celeborn 服務,解決了大 Shuffle 場景下的磁盤限制問題。
技術方案設計
- 架構圖
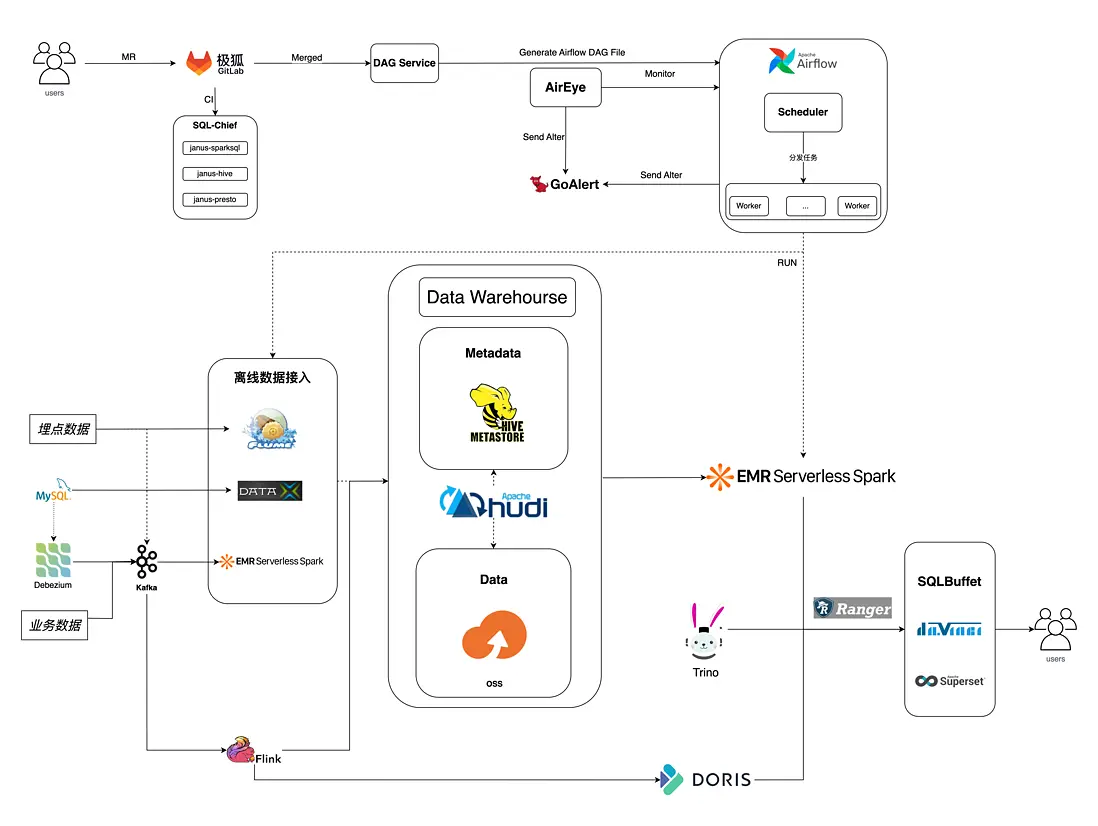
流利説數據平台涵蓋從數據採集、接入、存儲、計算到管理、查詢與可視化的完整能力。支持多種源數據接入,提供毫秒級實時處理、分鐘級近實時流處理及 T+1 離線批處理能力,能滿足多樣化業務需求。離線 ETL 腳本存儲於 GitLab,依賴於 GitLab 的分支管理、版本管理和 review 機制,實現可追溯、可協作的腳本管理;平台以 Airflow 作為調度系統,實現高效、可靠且可視化的工作流調度;以 EMR Serverless Spark 做為核心計算引擎,結合 Fusion 引擎加速,實現高效、彈性、可靠且低成本的數據處理。以 Hive Metastore 作為元數據管理,提供統一的數據目錄服務,實現元數據的集中存儲與管理,支持多引擎數據共享和跨平台數據訪問,簡化數據治理流程。數據存儲阿里雲 OSS ,提供高可靠、低成本的對象存儲。平台配合 AirEye 監控及 GoAlert 告警,構建完整的可觀測性系統,實現對關鍵指標的實時監控與異常檢測,提高系統可靠性和運維效率。
典型應用場景
- CI & CD 與離線 ETL 計算
流利説數據團隊自研了 DAG 自動生成服務,數據分析師和數倉工程師提交數據轉換腳本到代碼倉庫後會,自動集成 CI 進行腳本校驗,完成 review 並 Merged 後會觸發自研 DAG Service 生成 Airflow 可以直接調度的 Dag 文件。Airflow 基於阿里雲提供的 Operator 完成與 EMR Serverless Spark 的插件式集成,可直接提交任務到 EMR Serverless Spark,並監控任務狀態。相比於之前 Airflow + EMR Gateway 的方式去提交任務,結合 EMR Serverless Spark 的高效彈性及 Fusion 引擎優化,顯著提升了任務的執行效率、併發度、穩定性和可靠性。另外 EMR Serverless Spark 提供完善的監控,可顯著降低運維成本。
- 數據集成
流利説數據平台支持多種數據源數據接入,對業務數據庫接入支持每天全量接入和增量接入。對業務數據庫的增量接入引人數據湖 Hudi,用於支持數據更新、刪除操作及 Schema 演進管理。增量接入通過 CDC 技術實時監控業務庫日誌,將變更事件推送到 Kafka,通過週期調度 EMR Serverless Spark 任務完成增量數據入湖。該場景同樣是在 Airflow 中調度提交任務到 EMR Serverless Spark,由於增量數據可能會有周期性變化,藉助於 Serverless 的彈性伸縮能力,可顯著提高資源利用率,避免資源浪費,相比於之前半托管集羣的定時彈性伸縮更加穩定和流暢。
- 數據查詢
流利説查詢平台提供的 Trino 、Doris 和 Spark 三種查詢引擎,用户可以根據使用場景來選擇合適的引擎來進行數據查詢、分析及ETL 腳本驗證等。 查詢平台 Spark 引擎切換到 EMR Serverless Spark 之前是基於 Spark 的 Thrift Server 構建的,服務穩定性差且無法進行細粒度的資源隔離,運維成本高;切換到 EMR Serverless Spark 後,可通過 Web 管理界面可以管理和運維 Thrift Server 會話,可顯著降低運維成本。另外,查詢平台實現用户級別的路由,可實現不同用户提交到不同 ThriftServer,避免了資源搶佔。 另外,基於 EMR Serverless Spark 的彈性伸縮能力,減少了計算資源閒置,顯著降低成本。
遷移後的收益
- 性能:離線任務開啓 耗時減少 40%,核心報表更早產出。
- 穩定性:任務穩定性顯著提高,失敗率降低 80%。
- 資源靈活:根據業務需求自動調整擴充計算資源。
- 運維成本:減少不必要的大數據組件,精簡系統架構,降低平台運維成本。
- 性價比:真正的按量付費,不使用時沒有資源消耗,成本降低 30%。
後續期待
基於阿里雲 EMR Serverless Spark 技術棧快速構建了離線數據計算平台,EMR Serverless Spark 全託管免運維、自研 Fusion 引擎,內置高性能向量化計算和 RSS 能力,相比開源版本3倍以上的性能優勢以及計算/存儲分離的架構,為我們節省了總體成本。同時,EMR Serverless Spark 自身提供的豐富特性,也極大提升了我們數據團隊的生產力,為數據分析業務的快速開展交付奠定了基礎。未來,流利説希望與阿里雲 EMR 團隊針對湖倉場景輸出更多行業先進解決方案。