

作者:億緹希技術(上海)有限公司 馬博、王建春
一、背景介紹
一體系汽配供應鏈平台(以下簡稱一體系),專注提供高品質發動機、變速箱、底盤技術零部件,融匯優質實體資源和創新互聯網科技,為上游品牌商提供高效的下沉渠道,為下游零售商帶來可信賴的產品和服務,讓採購更便捷可靠,實現行業數字化轉型。
- 隨着企業對實時數據分析、AI 能力和大規模數據處理的需求不斷增長,平台數據量龐大且持續增長、數據呈現半結構化及非結構化等特點的現狀,傳統的本地大數據平台在存儲、彈性、成本、運維複雜度、深度挖掘、AI支持等方面逐漸暴露出瓶頸。與此同時,雲計算的成熟與普及催生了全新的“Serverless 數據計算架構”,為構建下一代雲原生數據平台提供了可能。
- 阿里雲 E-MapReduce(簡稱:EMR)推出的 EMR Serverless Spark 和 EMR Serverless StarRocks,正是這一趨勢下的重要技術產品。這兩個產品結合阿里雲一站式數據開發治理平台 DataWorks,共同構建了一個高效、靈活、低成本的數據分析體系。
為了應對新的業務挑戰,一體系選擇與阿里雲合作,利用其強大的EMR平台,構建了符合業務場景和分析師習慣的工程解決方案。
本文將從架構演進的角度出發,探討如何通過 EMR Serverless Spark 和 DataWorks 實現從傳統 Hadoop 平台向雲原生架構的平滑遷移與持續優化。
二、為什麼選擇阿里雲EMR Serverless Spark
EMR Serverless Spark 是一款兼容開源 Spark 的高性能 Lakehouse 產品。它為用户提供任務開發、調試、發佈、調度和運維等全方位的產品化服務,顯著簡化了大數據計算的工作流程,無需用户管理底層集羣即可直接提交作業,支持批處理和流式計算。使用户能更專注於數據分析和價值提煉。
- 豐富的功能支持:支持權限管理、資源配額與任務隔離。兼容 Apache Spark API,現有任務可無縫遷移。
- 靈活的計費方式:僅對實際使用的 CPU、內存和執行時間計費。
- 良好的引擎性能:內置 Spark Native Engine,相對開源版本性能提升3倍。
- 完善的服務保障:根據任務負載動態分配資源,提升性能與成本效益。無需關注集羣部署、擴縮容、故障恢復等底層操作。
三、技術方案設計
一體系通過阿里雲 EMR Serverless Spark,實現了數據與 AI 技術的有效融合,並結合 EMR Serverless StarRocks 搭建了 Lakehouse 平台。該平台核心部分如下:
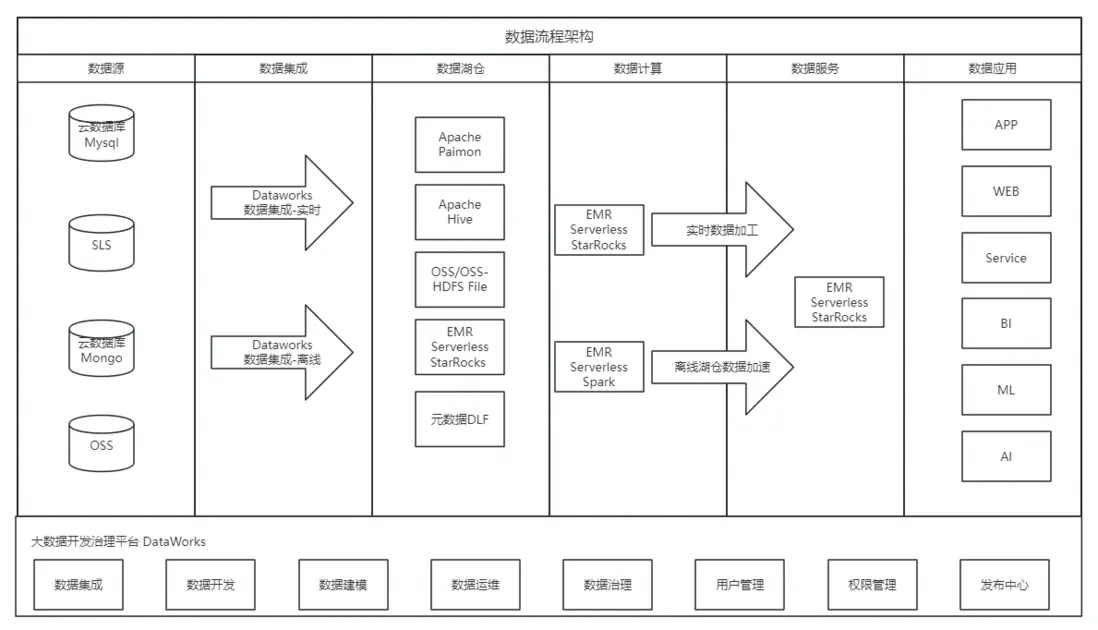
首先,上游數據通過 DataWorks 的數據集成,實時以 Apache Paimon 格式寫入數據湖,寫入時開啓自動Compaction,用於平衡寫入和讀取性能。同時湖表元數據同步至 DLF,以保持數據的實時性。
其次,通過 Serverless Spark 構建了數倉經典分層架構,95%的數據源採用 DataWorks 數據集成的實時入湖(ODS),經過清洗轉化為明細數據(DWD),然後根據主題將明細層數據輕度聚合(DWS),再根據特定應用或業務場景提供高質量的指標數據(ADS),為上層業務系統提供支持。
在BI應用方面,一體系通過 DataWorks 調度 StarRocks 任務,通過使用異步物化視圖,加速數據湖查詢,為數據湖中的報表和應用實現更高的併發,以及更好的性能。同時將 StarRocks 本地表中的實時數據與數據湖中的歷史數據關聯起來以進行增量計算。為上層應用提供 Dashboard 和報表支持,提升了數據的可視化和決策能力。
在 ML/AI 應用方面,一體系通過 DataWorks 調度 Spark 任務,進行數據的計算和聚合,處理後的指標數據從數據湖推送到了AI知識庫,推動了 Data + AI 技術在實際業務中的應用。
以下架構圖展示瞭如何利用 Serverless Spark 結合開源湖格式 Paimon、ML/AI 的多種工具庫,以及阿里雲 DLF 統一湖倉管理平台,實現高效的數據處理和AI賦能,使用 Serverless StarRocks 實現極速數據分析,為業務應用帶來顯著的提升。
四、數據平台演進
第一階段(評估),明確現狀與目標,選型階段我們做了很多的調研,綜合各個方面考慮(湖倉一體、存算分離、彈性伸縮、開箱即用、運維監控、長期支持等),選擇一個成熟且統一的平台:既能夠支持數據處理、數據分析場景,也能夠很好地支撐數據科學場景,於是選擇了阿里雲EMR。
第二階段(適配),任務兼容性驗證,基於原數據平台 Apache Ambari+Azkaban 的構建,梳理 Hadoop 任務、依賴關係、數據流向等,將作業適配到 EMR Serverless 環境,測試性能與穩定性,確保 Spark SQL、UDF、依賴庫等均兼容 EMR Serverless Spark。
第三階段(遷移),分批切換任務,在 DataWorks 中創建新任務和流程編排,使用 Spark 作為計算引擎,逐步替代原有腳本和jar包,將數據遷移到 OSS 或OSS-HDFS 中,實現存儲與計算解耦。
第四階段(優化),性能調優與成本控制,EMR Serverless Spark 提供了 Fusion 引擎,性能提升顯著。StarRocks 提供了可視化慢 SQL,及 SQL 查詢分析能力,方便運維管理。利用 Serverless 特性優化資源配置,提升性價比。
第五階段(治理),統一平台管理,藉助 DataWorks 實現任務統一調度、監控與治理,結合EMR Serverless Spark 和 EMR Serverless StarRocks的一站式的數據平台服務,極大地簡化了數據處理的全生命週期工作流程。
五、業務場景介紹
隨着企業加速數字化應用的廣度和深度,平台運營數據成為驅動業務增長、改善用户體驗、提升運營效率的核心資產。數據處理架構滿足了日益增長的數據量、實時性要求及靈活分析能力的需求,不僅解決了企業在日常海量運營數據分析的性能瓶頸、成本壓力與運維難題,更為企業提供了敏捷開發、智能分析、持續演進的能力支撐。
場景1:基於業務交易端到端數據的深度應用,動態、靈活制定運營策略,指導各業務端開展針對性的工作,達到公司中、短期目標。
- EMR Serverless Spark:對來自多個系統的交易數據進行清洗、合併、維度建模。
- DataWorks:統一編排每日/每小時任務,保障數據準時產出。
- OLAP 引擎:使用 StarRocks 進行實時查詢與可視化分析。
- ML 模型集成:通過 Spark MLlib 接入模型,進行特定場景針對性的策略制定。
場景2:客户服務分析對於提升客户滿意度、增強品牌忠誠度以及優化整體運營效率至關重要。通過全面的數據分析,快速識別客户服務中的薄弱環節,制定有效的改進措施。
- EMR Serverless Spark:負責對業務全過程數據的清洗、聚合計算。
- DataWorks:統一調度 Spark 任務,管理依賴關係,保障任務鏈穩定性。
- StarRocks:用於物化視圖加速湖倉數據,交互式查詢與報表展示。
- 報表對接:通過統一接口將分析結果接入報表系統。
六、Serverless Spark 產品優勢
- 雲原生極速計算引擎
內置 Spark Native Engine,相對開源版本性能提升3倍; 內置企業級 Celeborn (Remote Shuffle Service),支持 PB 級 Shuffle 數據,計算資源總成本最高下降 30% 。
- 彈性資源管理
資源調度具備秒級彈性,支持按需分配最小粒度為 1 核的資源,按任務或隊列級別進行精細化資源計量,確保資源使用的最大化與靈活性。
- DATA 和 AI
提供完全兼容 PySpark/Python 的開發與運行環境,支持 Python 生態的機器學習 Lib,以及 Spark MLlib,支持產品化管理 Python 三方依賴庫。
- 生態兼容
具備強大的兼容性與集成能力。支持 DLF 和 Hive MetaStore 數據目錄,兼容 Paimon、Iceberg、Hudi 和 Delta 等主流湖格式,可對接 Airflow 和 Dolphin Scheduler 等主流調度系統,支持 Kerberos/LDAP 認證和 Ranger 鑑權,還支持 DataWorks 和 DBT 提交任務,全方位滿足用户需求。
七、遷移後的收益
7.1 技術層面
數據入湖:
採用了 Apache Paimon 作為數據湖存儲格式,並集成了 Apache Spark、Flink 作為計算引擎,構建了一個完整的數據湖倉系統。這一系統已經在實時數據監控和分析等場景中得到了成熟的應用,顯著提升了我們的數據處理能力和業務效率。
研發效率:
遷移到 EMR Serverless Spark + DataWorks架構後,使用 Spark SQL 會話功能快速開發驗證+DataWorks 生產調度的模式,研發效率顯著提升,保障了關鍵業務的數據產出支持。
運維保障:
EMR Serverless Spark 的多版本管理能力為用户提供了靈活的選擇空間,支持快速升級至最新優化版本,自動化的擴縮容、故障恢復等功能減少了手動干預的需求,降低運維壓力。
7.2 業務層面
數據響應時長:大量作業由小時級提高到分鐘級,生產速度得到大幅提升。
彈性伸縮能力:根據任務的實際需求動態調整資源規模,確保在高峯期也能保持良好的性能表現,同時在低谷期節省開支。
八、總結及後續期待
我們基於阿里雲 EMR Serverless Spark 技術棧快速構建了全新的大數據平台,相比開源版本3倍以上的性能優勢以及計算/存儲分離的架構,極大提升了我們數據團隊的效能,為開展業務分析提供快速數據交付能力。從傳統 Hadoop 到 Serverless Spark,不僅是技術架構的升級,更是企業數據能力的一次質變,構建了一個面向未來的一體化雲原生數據平台,為AI應用的深度融合,奠定數字化基礎。
EMR Serverless Spark 助力我們實現高效、彈性、易維護的數據處理,邁向更智能、更敏捷的雲原生數據平台。未來可期,繼續攜手前行!”
——一體系平台架構師