

本系列文章將圍繞東南亞頭部科技集團的真實遷移歷程展開,逐步拆解BigQuery遷移至MaxCompute過程中的關鍵挑戰與技術創新。本篇為第一篇,跨國數倉遷移背後MaxCompute的統一存儲格式創新。
注:客户背景為東南亞頭部科技集團,文中用GoTerra表示
背景
當東南亞頭部科技集團GoTerra決定將其集團數據倉庫從BigQuery遷移至阿里雲MaxCompute時,這一決策背後折射出更深層的考量:全球化業務的區域合規性需求、亞太市場本地化部署的成本優化目標,以及對PB級數據處理能力的極致追求。
而BigQuery作為全球領先的雲數據倉庫產品,憑藉其Serverless架構、彈性擴展能力與高併發處理性能,長期被視為全球範圍內企業構建大規模分析型雲數據倉庫架構的標杆。其核心優勢體現在:
- 全託管Serverless服務:屏蔽底層技術細節,免除底層基礎設施維護,用户只需關注數據邏輯與業務需求;
- 與Google生態無縫集成:通過Dataflow、Vertex AI等工具實現數據處理與AI模型的閉環;
- 標準SQL與低延遲查詢:支持複雜分析場景,尤其適合中小型企業快速啓動大數據項目;
- 按需付費模式:避免預置資源浪費,對突發性數據增長具備天然適應性。
此次遷移屬於非常複雜的跨國異構技術遷移,而是面臨多重技術突破與業務挑戰:
- 底層存儲格式差異:BigQuery與MaxCompute在底層存儲格式與架構上存在巨大差異,需要在底層存儲架構上進行大量的改造與優化,確保上層業務的遷移與日常使用盡可能平滑無感
- SQL兼容性:MaxCompute SQL與BigQuery的標準SQL在語法、函數庫及執行引擎上存在差異,需開發自動化轉換工具;
- 數據一致性保障:跨平台遷移過程中,如何避免數據丟失、版本衝突及ETL流程中斷成為關鍵;
- 性能調優:MaxCompute的分區表、資源組調度機制與BigQuery的列式存儲優化策略需重新適配業務場景;
- 組織協同:跨國團隊在遷移期間的系統可用性平衡與灰度發佈策略設計。
本文將從底層存儲格式差異與重構的技術角度,深入解析GoTerra在歷時9個月的複雜遷移過程中,MaxCompute在底層存儲格式上做出的一系列技術演進與創新改造。
動機源於用户場景痛點
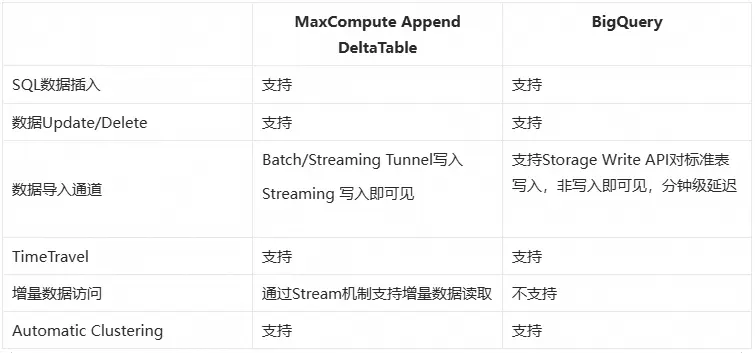
BigQuery作為國際上先進的數據倉庫服務商,依賴Google自身深厚的技術積累,以及長期以來客户場景的不斷打磨,向用户提供了一套全面、靈活、免運維、高性能的數據倉庫服務。特別值得注意的是,在同一套底層數據存儲格式的基礎上,BigQuery向用户提供了包括數據流式寫入、ACID 事務、索引、Timetravel、Auto Clustering在內的多種底層存儲數據管理能力。其支持用户根據實際業務需求來任意組合數據架構,極大降低了用户使用門檻,讓用户在不需要理解底層存儲原理的前提下就可便捷的應用數倉的各種數據功能。
相比之下,MaxCompute在過去的技術路線中提供了其中包括Standard Table標準表,Range/Hash Cluster Table,Transactional Table, Delta Table在內的4種不同的表類型,以滿足多樣的用户需求場景。然而多樣化的表類型大大抬升了用户的使用門檻,用户需要深入每一種表類型各自的功能與限制,同時每一種表類型都有着自身較大的使用限制、表的能力沒有辦法隨着用户場景的變化做動態適配,用户總是需要針對新的場景創建新類型表,學習、維護成本高。例如
- 追求高吞吐寫入和通用性場景下使用Standard Table 。
- 追求極致的查詢性能(特別是JOIN和過濾)情況下使用Range/Hash Cluster Table,存在部分寫入和結構的限制。
- 需要支持行級更新(UPDATE)情況下使用的Transactional Table 和 Delta Table 之間選擇。
- 需要現代數據湖的複雜更新(UPSERT)和歷史追溯能力的情況下使用的Delta Table。
在GoTerra技術遷移的項目過程中,我們面臨巨大的技術挑戰,由於GoTerra集團自身業務的複雜性高。用户本身在BigQuery中使用到的表數量非常大,不同的互聯網業務場景,數據的實時/批量寫入、數據消費方式截然不同,對性能的要求也存在巨大差異,但客户有期望提供統一的表格式能夠同時支持以上四種不同表所擁有的優勢與特性。用户能夠使用同一種表類型完成了對所有業務場景的支持。但是在MC當前的產品形態下,用户一方面需要對MC的各種表類型進行深入的學習理解,同時還需要GoTerra對當前已有業務的數據使用方式進行深入分析與歸納,這裏涉及到各個業務部門大量人員的培訓和海量數據業務場景的深入分析梳理,整體的遷移因為大量的培訓分析工作遲遲無法有效推進。
綜上所述,在較短的時間內完成海量數據和極端複雜業務場景的遷移,給我們提出瞭如下挑戰:
- 統一底層存儲格式,同時支持多種的數據能力並進行功能整合,在底層存儲能力上打破功能碎片化的局面
- 實時化:通過流式數據寫入、增量數據處理、增量計算Pipeline的構建,提升數倉實時能力
- 智能化:動態能力與Auto Scaling能力增強,進一步提升產品自適應免運維能力
存儲技術方案解析
結合MaxCompute當前已有存儲技術能力以及未來存儲格式演進的規劃,通過對系統工程實現和存儲格式的梳理重構,我們推出了Append DeltaTable,通過新的表格式,我們達成了以下幾個技術核心功能:
- 通過單一的,可拓展的表組織結構,同時獲得包括動態Cluster分桶、ACID 事務、數據append,數據流式寫入、timetravel、incremental read、二級索引在內的多種數據寫入、訪問、組織、索引能力
- 支持用户根據使用場景的變化,對錶的數據組織形式與功能進行按需調整和修改
- 主要數據訪問、寫入鏈路、消費接口與存量表格式保持兼容,降低用户的使用門檻和遷移門檻
- 在能力拓展的同時,數據基礎讀寫、訪問性能與存量表格式相比不發生回退,保持我們在成本與性能上的競爭優勢
Append DeltaTable的推出,一方面是對存量表格式已有功能場景的整合,支持了包括ACID 事務、數據append,數據流式寫入、Timetravel等能力,讓用户能夠在同一種表類型內部不受限制對多種能力進行組合,按需對業務場景進行適配。
專業用詞:
- MaxCompute Append DeltaTable TableFormat(表格式):MaxCompute在2025年最新推出的基於RangeCluster表結構來構建的增量數據表格式。
- Data-Bucketing:Bucketing 就是利用 buckets(按列進行分桶)來決定數據分區(partition)的一種優化技術,它可以幫助在計算中避免數據交換(avoid data shuffle)。並行計算的時候shuffle常常會耗費非常多的時間和資源。MaxCompute在Range/Hash Cluster表格式中初次引入了Bucket概念。
- Data-Clustering: Clustering聚合是管理和優化數據倉庫的數據存儲和檢索的基本技術方案,通過將相關數據在物理上集中存儲,支持通過數據裁剪達到提升查詢效率的目的
- Range Clustering表:Range Clustering作為一種新的數據切分方式,按照一個或多個列的範圍順序存儲數據,數據按鍵值大小排序並存儲, 提供了一個全局有序的數據分佈。
- Hash Clustering表:通過設置表的Shuffle和Sort屬性,按照哈希函數將數據分佈到不同的桶(buckets)中, 數據按鍵值哈希後的結果存儲。
- 在這裏我們着重介紹在GoTerra數據遷移場景中,為了倍數級提升海量數據存儲與計算效率,降低業務遷移成本。在此我們介紹在Append DeltaTable表格式中關鍵幾個核心特性:
Storage Service - 數據自治服務
Storage Service是MaxCompute自研的分佈式存儲引擎核心組件,其負責海量數據在高可靠存儲、高吞吐讀寫的情況下智能數據治理服務。隨着雲數倉場景從大數據規模向 AI 原生智能架構的不斷演進,Storage Service 需解決以下關鍵挑戰:
- 存儲效率:PB 級數據冷熱分層、壓縮比優化、碎片治理。
- 計算協同:支持 Append DeltaTable 表格式的動態分區、增量讀取、列式轉換。
- 彈性擴展:適配跨區域集羣的動態負載波動(如大促期間日均 PB 級數據遷移)。
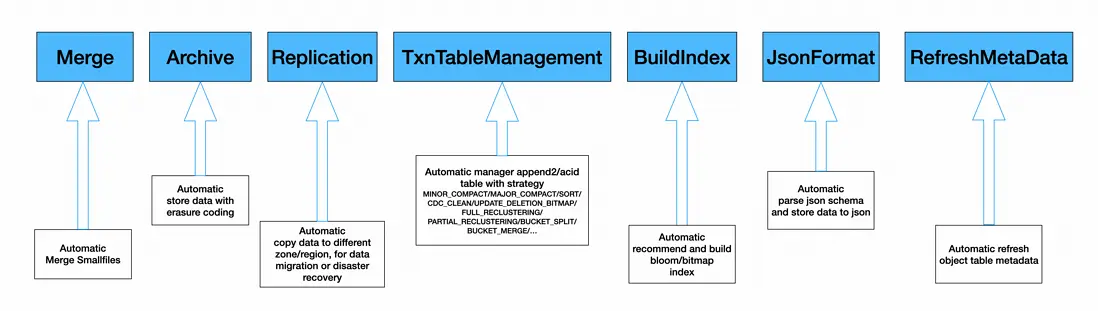
Storage Service 通過支持以下後台數據作業任務實現數據的自運維、自優化、自癒合的能力,顯著降低人工干預成本。系統的支持數據自動治理服務,其包括不限於以下工作任務:
- 文件合併與重寫: 即基礎的Merge Task,合併小文件降低存儲Master的壓力,同時,支持數據重寫使用更高的壓縮率和編碼算法,以及寫出RAID文件等,提供數據archive的能力。
- Auto Tiered Storage: MaxCompute作為跨Region 超大存儲集羣,計算能力需支持每天都要在不同Storage Tier之間搬運PB級數據。
- Minor Compaction & Major Compaction: 在支持Append DeltaTable Table之後,存儲層提供了Minor Compaction(保存版本,但消除小delta文件),以及Major Compaction(合併消除版本)兩種模式,用於存儲效率優化。
- Index Building: 構建包括Bloomfilter, BitmapIndex等數據索引。
- Streaming Compaction: 在數據管道Tunnel流式寫入數據的場景,支持對行存文件的合併以及轉換成列式文件(AliOrc)。
- Data Reclustering: 在Streaming寫入Hash/Range Clustering Table的場景下面,我們支持把新Append追加寫入的無序數據,重新進行partitioning分區和ordering排序,併合併到原有的clustering table。
- Data Backup: 通過跨地域複製實現異地數據備份。
Storage Service在支持以上後台自動數據治理的任務,通過數據重排/重分佈/複製等多種方式持續優化數據計算/存儲效率。Storage Service數據自治服務系統分為兩大部分,Service Control和Service Runtime,前者負責接收外部請求,排隊,路由,並將請求轉發到計算集羣。後者則將一個請求轉換成具體的執行計劃,並提交Service Job Plan執行請求。以Service Control控制服務來收集後台數據任務需求,分發到計算集羣,再在Service Runtime環境中轉換成具體執行計劃,提交Service Job,完成後台工作任務。
Dynamic Bucketing - 動態Bucket數據優化
在創建Range/Hash Cluster表時,用户需要提前評估對應業務的數據規模,以此為依據設置合適的Bucket數量和cluster key。在完成Cluster表創建後,MaxCompute通過clustering算法將數據按照cluster key路由到各自對應的Bucket中。正因為此產品設置,當數據量太多但是Bucket數量太少,會導致單個Bucket數據量過大,那麼查詢時數據裁剪效果不佳。但是反過來,如果設置的Bucket數量遠遠大於業務數據量所需要的範圍,會導致每個Bucket內數據量太少而產生大量碎片文件,對查詢性能也會造成不良的影響。因此,在創建表時,根據業務的數據量設定合適Bucket數量無形中抬升了用户的使用門檻,用户需要同時對業務本身對使用模式和MaxCompute底層表格式都有一定的理解,才能夠正確使用clustering的相關能力,發揮出clustering帶來的查詢性能收益。
這種用户在建表時顯示指定Bucket數量的表固定設置方式帶來了幾個問題:
- 在大規模數據遷移場景,用户需要對每一張表的潛在業務使用規模進行評估,如果表的數量比較少,評估工作還可能通過專項推進,但是當面對成千上萬張表時,對每一張表的數據規模進行評估就變得非常難以執行了
- 即使用户對錶的數據規模在當下都做了準確的評估,但是隨着業務自身的演進,實際的數據規模也會持續變化,在當下適用的bucket數量設置可能在未來變得不再適用
綜上所述,靜態的Bucket數量配置無論是在大規模數據遷移場景,還是在業務快速變化的日常使用環境中,都難以做出有效的支撐,更合理的方式,是平台根據用户實際數據量大小,動態地設置所需要的bucket數量,用户不需要對底層的bucket數量進行感知,一方面大大降低了用户的學習和使用門檻,另一方面對於不斷變化的數據規模,也能夠更好地做出適應。
因此,Append DeltaTable表格式在設計之初就支持了Bucket的動態分配,所有存儲在表中的數據都被自動劃分為Bucket,每一個Bucket都是一個邏輯是連續的存儲單元,包含了500MB左右的數據。用户在創建和寫入數據之前,並不需要在表層面指定Bucket的數量,隨着用户數據的持續寫入,新的Bucket會不斷被按需創建出來,用於承載用户的數據。用户並不需要擔心隨着數據量的增加或者減少,會導致Bucket內數據量過大或者過小導致的數據傾斜和數據碎片問題。
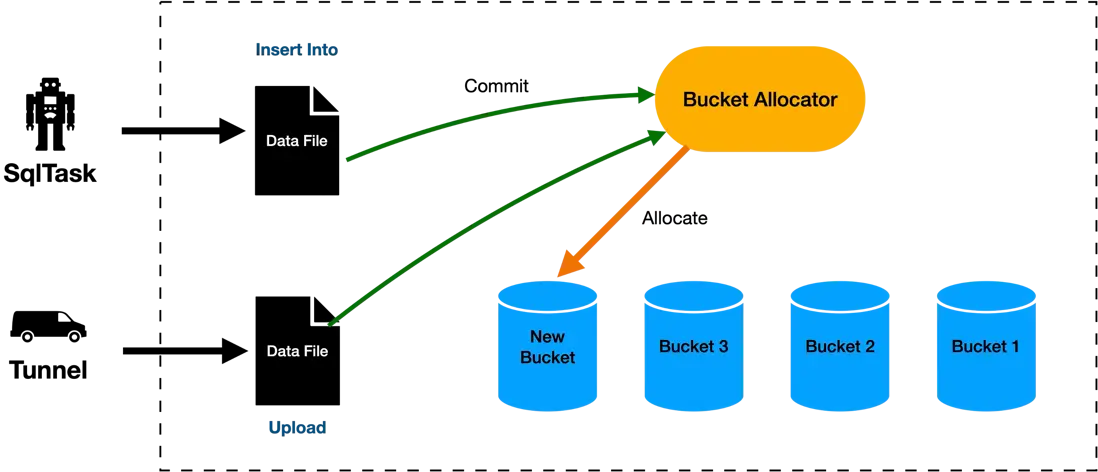
Incremental Reclustering - 增量重聚合
Clustering是數據領域最常見的數據優化手段之一,cluster key是用户指定的表屬性,通過將用户指定的數據字段進行排序並且進行連續的存儲,當用户對cluster key進行查詢時,我們可以通過下推裁剪等優化,大大縮小數據掃描的範圍,從而達到提升查詢效率的目的。
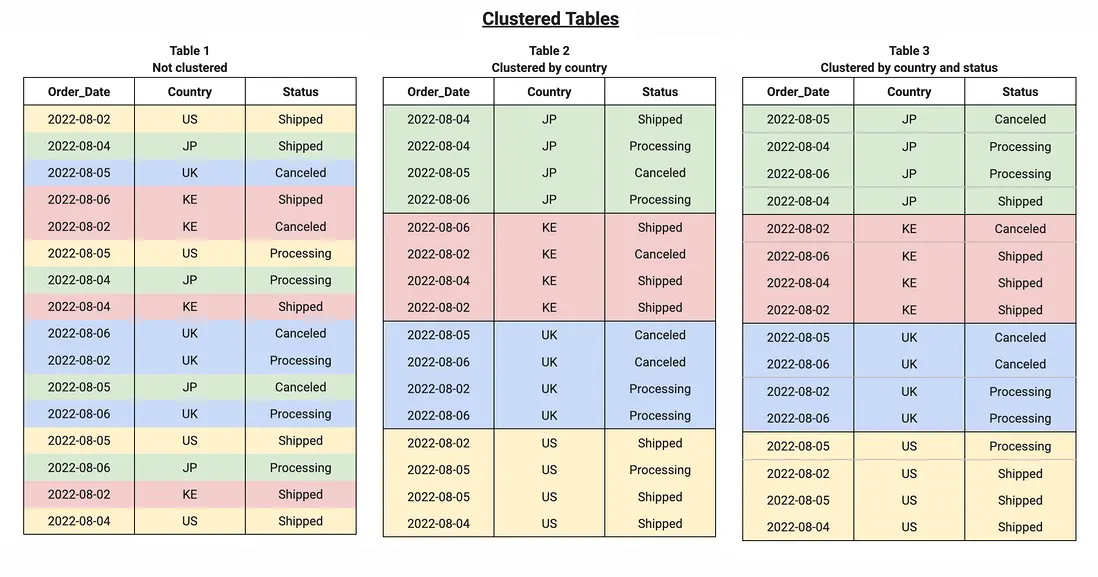
如上圖所述,MaxCompute之前提供了Range/Hash Clustering兩種Clustering能力,支持用户通過Range分桶或者Hash分桶對數據進行分桶,並對單個桶內的數據進行排序,通過對查詢過程中Bucket裁剪和單個桶內數據的裁剪,達到查詢加速的效果。然而,Range/Hash Clustering的表能力存在的一個限制是,數據必須在寫入過程中就完成數據的分桶與排序,從而達到一個全局有序的狀態,不支持。因此對數據寫入的方式進行了限制,要求數據必須以insert overwrite的形式一次性寫入,數據寫入完成後,如果需要再進一步追加數據,則需要將表中原有的數據全部讀取,與新增數據union之後再次寫入,數據追加代價非常大,效率很低。
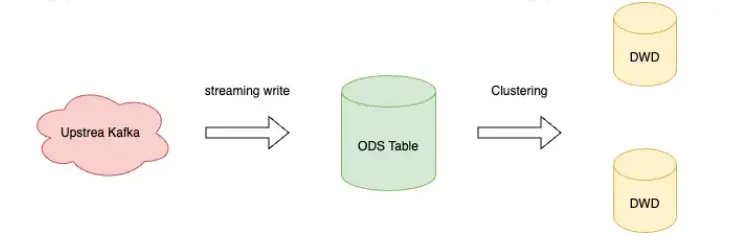
如上圖所示,一般來説,業務通常不會對ODS層的數據表使用clustering,原因在於ODS層的數據比較接近原始的業務數據,通常是通過外部的採集鏈路持續導入的,對數據導入的性能有很高的要求,原有clustering表代價巨大的寫入模式無法滿足低延遲高吞吐的寫入要求。因此業務側往往傾向於在DW層的表中設置ClusterKey,對在前一個業務日期完成數據導入的ODS表進行數據清晰後導入到新的數據相對穩定的DW層,進而加速後續的查詢業務性能。
但是這種方案帶來的問題在於DW層數據的新鮮度上會存在一定的延遲,為了避免反覆更新DW層帶來的讀寫放大,DW層的更新通常在ODS層數據穩定後才進行,這導致通過DW層查詢到的數據在業務日期上是存在滯後的。然而在GoTerra遷移的過程中,業務方對查詢性能和數據新鮮度都有着非常極致的要求,希望能夠在ODS層之間實現Clustering,通過對ODS表的數據查詢加速,獲取實時信息。
因此,原本MaxCompute提供的在寫入數據時同步執行Clustering的方案無法在數據的實時性上滿足用户訴求。Append DeltaTable 的增量Clustering能力,通過後台數據服務異步執行增量Clustering的方式,在數據導入性能,數據實時性,以及數據查詢性能上做到了最大限度的平衡。
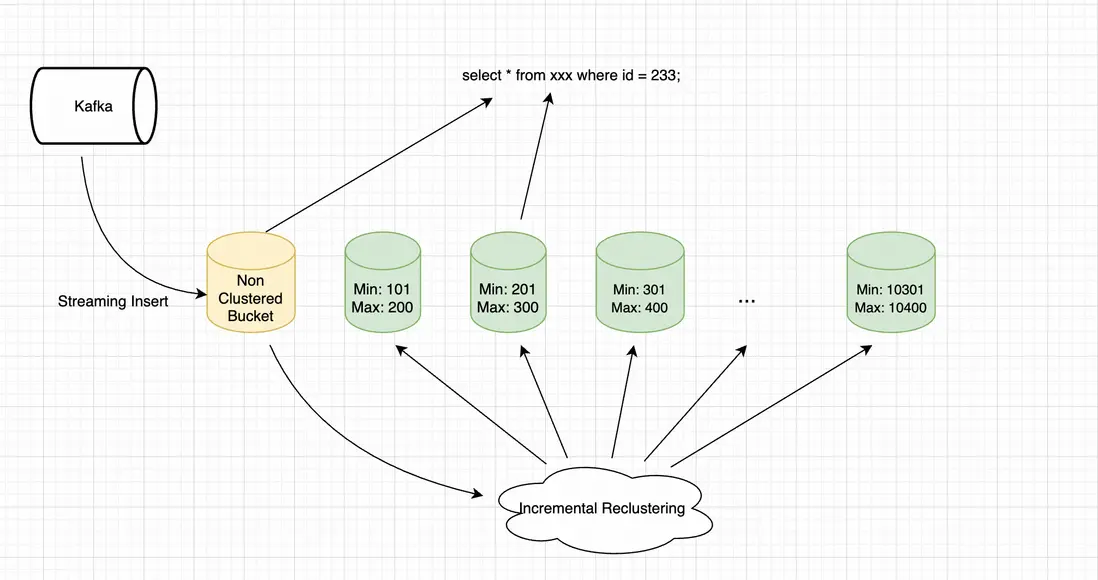
如上圖所示,用户數據通過Streaming 寫入的方式導入MaxCompute,寫入階段為了最大限度保障寫入延遲與吞吐,數據直接以未排序的方式落盤,被分配到新分配到Bucket中。此時由於新寫入到Bucket數據沒有執行Clustering操作,新增Bucket在數據範圍上會和其他已經完成Clustering的bucket產生重疊。在執行查詢任務時,SQL引擎對Clustered Bucket執行Bucket裁剪,對增量Bucket則執行掃描。
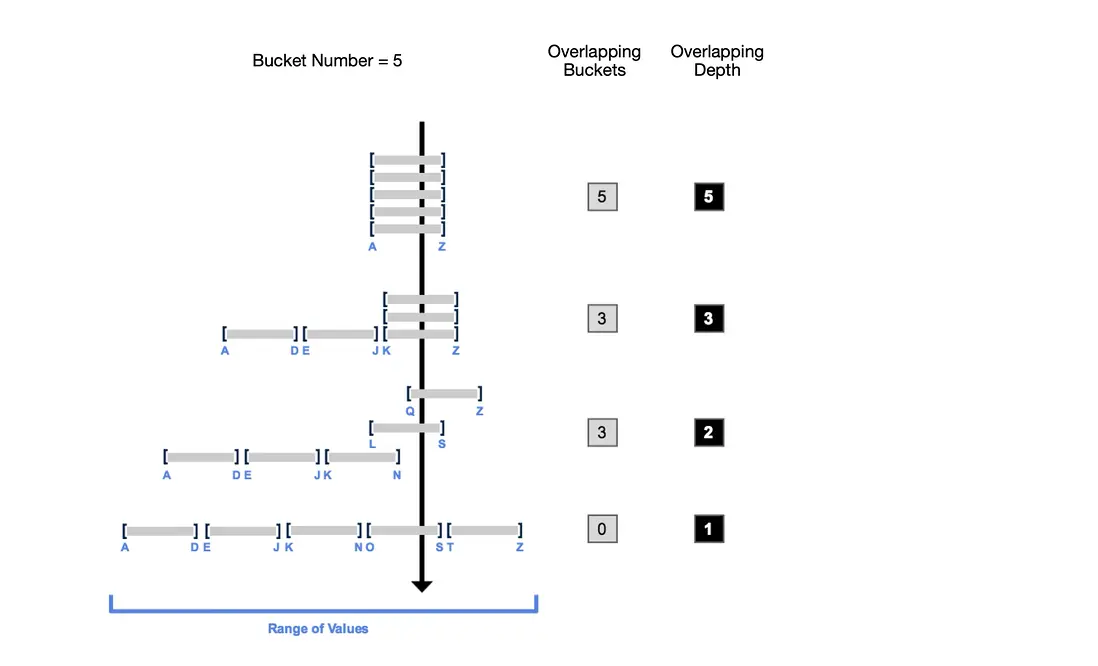
如上圖所示,MaxCompute後台數據服務持續對Bucket Overlap Depth進行監控,當Overlap達到特定閾值後觸發增量Reclustering,對新寫入的Bucket執行Reclustering操作,確保用户數據的主題部分始終維持在一個有序狀態,從而確保了整體查詢性能的穩定。
Performance Improvement - 顯著性能效果
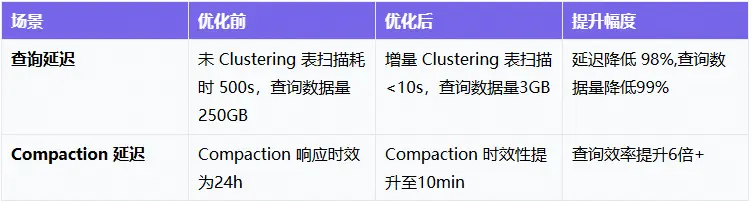
Append DeltaTable創新表格式在複雜業務場景上優秀表現從側面反映出數據存儲格式的技術優化對大數據分析場景下的核心價值。其技術價值&性能優化總結如下:
1. 數據自治:
- 通過 Merge、Compaction、Reclustering 等後台任務,實現存儲效率與查詢性能的動態平衡。
2. 彈性擴展:
- 動態 Bucketing 與 Auto-Split/Merge 策略,支持從 TB 到 EB 級數據的無縫擴展。
3. 實時 Clustering:
- 增量 Reclustering 在 ODS 層實現毫秒級數據新鮮度與 Clustering 查詢加速。
實踐總結
Append DeltaTable 的推出一方面結束了MaxCompute一直以來存在的功能割裂狀態,大大降低了用户對於底層存儲格式的理解和使用成本,在繼承MaxCompute一如即往優秀性能的同時,靈活性,時效性,場景的多樣性上都有了巨大的提升。在GoTerra遷移項目中,Append DeltaTable的推出極大提升了GoTerra項目總體的遷移效率。Append DeltaTable作為Maxcompute用於遷移BigQuery數據的唯一表格式,承接了包括55w張表,60+PB數據的全量遷移工作。也證明了Append DeltaTable在自身整體的架構設計和整體實現上能夠支持和BigQuery等國際一流廠商的全方位能力對標。
Append DeltaTable的成功落地不僅標誌着MaxCompute在存儲架構上的重大突破,更預示着雲原生數據平台在規模化、實時化、智能化方向的演進趨勢。在兼顧MaxCompute原有的高吞吐批處理能力的同時,填補了傳統數據倉庫在時效性上的短板。這種設計使GoTerra得以在遷移後無縫銜接歷史批處理作業與新興的實時分析需求,例如將用户行為日誌的分鐘級處理延遲壓縮至秒級,為東南亞市場的動態定價、風控模型迭代等場景提供實時決策支持。
未來技術規劃
從更宏觀的未來視角看,Append DeltaTable創新表格式的推出體現了阿里雲對Data + AI融合架構的前瞻性佈局。其底層的列式存儲與向量化引擎為AI機器學習特徵工程提供了天然數據加速路徑。而未來技術規劃趨勢在於近實時數據處理與多模態數據存儲能力。其中多模態數據(如文本、圖像、時序)的統一存儲能力,則為企業構建跨模態分析流水線奠定了基礎。GoTerra的海量數據遷移是國內企業邁向全球數據治理標準的關鍵一步——中國自主研發的數據基礎設施已具備支撐跨國企業級複雜業務的完整能力。未來,隨着Append DeltaTable與MaxCompute原生實時計算組件的深度集成以及Delta Live MV能力的進一步推出,MaxCompute將進一步釋放數據資產的全生命週期價值,為雲原生時代的數據革命提供中國方案。