

本文整理自 Lazada Group EVP 及供應鏈技術負責人陳立羣在 Flink Forward Asia 2025 新加坡實時分析專場的分享。
引言:實時數據驅動,海外電商競爭的新高地
在電商行業,用户行為瞬息萬變,促銷節奏日益緊湊,能否在毫秒級做出數據驅動的決策,已成為決定成敗的關鍵。作為東南亞領先的電商平台,Lazada 面臨着一項巨大挑戰:在六個國家管理數十億商品 SKU,同時為不同市場的用户提供高度個性化的商品推薦。
為應對這一挑戰,Lazada 基於阿里雲實時計算 Flink 和 Hologres,打造了一個端到端的實時商品選品平台。這個平台不僅支撐了日常運營,更在大促期間實現了分鐘級決策響應。本文將深入分享 Lazada 如何通過現代流式處理與實時分析技術,重構電商數據架構,實現從“事後分析”到“事中調控”的躍遷。
選品的本質:從“貨架管理”到“用户洞察”

電商中的商品選品與傳統零售有着本質區別。一家實體 7-Eleven 便利店受限於物理空間,可能只能陳列約 2500 個 SKU;而電商平台可以在單個品類下展示數百萬件商品。然而,真正的挑戰並不在於存儲容量的限制,而在於有限的屏幕展示空間,以及為每位用户提供個性化、相關性強的商品推薦的需求。
Lazada 在六個市場開展業務,擁有一個龐大的供應生態系統,包括本地賣家、跨境商家和國際供應商。這構成了一個極其複雜的環境,我們必須高效地管理和分析數十億個商品 SKU,同時通過智能選品和實時分析確保最佳的用户體驗。
商品選品流程包含三個關鍵層級。最底層是數據服務層,為所有商品相關信息提供基礎設施支持。在其之上是選品層,SKU 被分組進入不同池中,並根據業務需求進行處理。最上層是分析層,使業務智能團隊能夠進行實時分析並做出數據驅動的決策。
這種多層架構在高流量活動期間尤為重要,例如我們的大型促銷活動,類似於阿里巴巴的雙11。在這些高峯時段,我們需要實時分析商品表現,識別庫存風險,檢測潛在欺詐行為,並監控競爭對手動態。能否在幾分鐘甚至幾秒內做出商業決策,往往決定了整場活動的成敗。
業務與技術的雙重挑戰
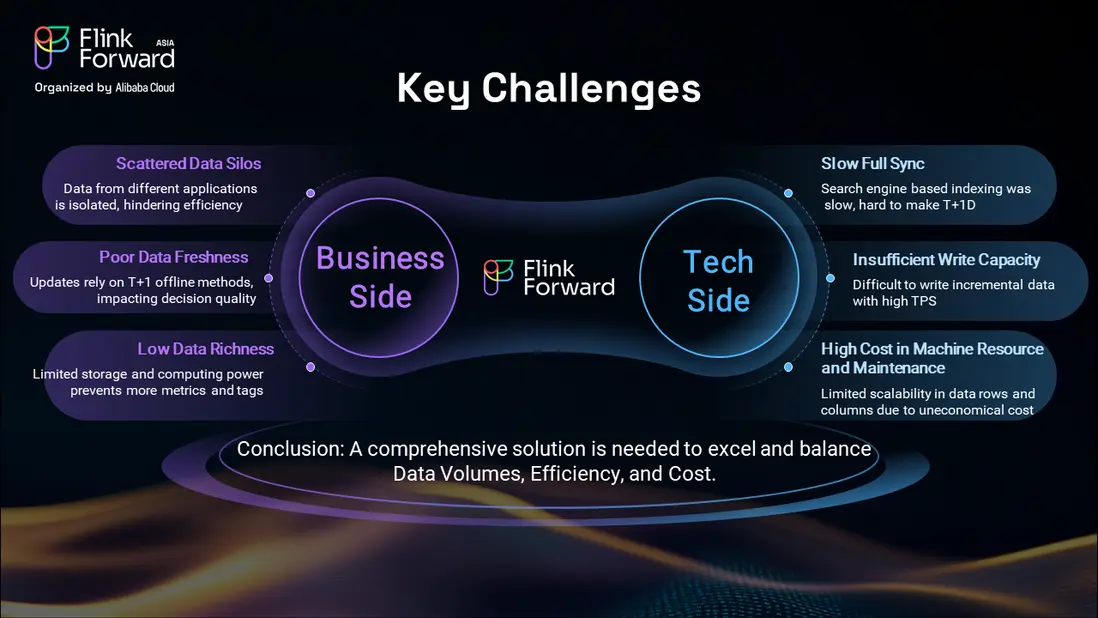
業務層面的挑戰
從業務角度來看,Lazada 繼承了來自阿里巴巴的基礎設施,最初導致不同業務單元之間數據孤島林立。我們的供應團隊、1P 自營業務、跨境運營和 marketplace 業務部門各自維護獨立的產品與 SKU 數據源。這種數據割裂在業務團隊需要創建整合數據池以進行綜合商品分析時,顯著降低了效率。
數據新鮮度是另一個關鍵挑戰。在我們原有的系統中,上線一個新產品或更新商品屬性,可能需要超過一天時間才能同步到所有系統。這種延遲使得依賴過時數據進行時效性強的商業決策變得不可行,尤其是在閃購或促銷活動期間,市場條件變化極為迅速。
此外,原有技術架構也限制了數據的豐富性。業務團隊經常提出需要更多指標和標籤,以更好地理解商品表現和用户偏好,但我們的舊系統無法高效地滿足這些不斷演進的需求。
技術架構的侷限性
從技術角度看,我們原有的架構存在若干顯著缺陷。全量數據同步耗時超過一天才能完成,這在節奏快速的電商環境中是無法接受的。系統的吞吐能力有限,難以應對業務運行所需的高 TPS(每秒事務數)要求。
成本效益也一直是持續存在的問題,高昂的機器資源成本和巨大的維護開銷消耗了寶貴的技術資源。這些侷限性表明,我們需要一個能夠以可擴展的效率處理海量數據並降低運營成本的綜合解決方案。
技術挑戰還因需要支持異構數據源、實時流處理能力,以及高效地同時執行批處理和流處理而進一步加劇。我們的舊系統無法在滿足業務所要求的性能和可靠性標準的同時,滿足這些不斷變化的需求。
擁抱現代流處理的新機遇

成熟流處理技術的出現,特別是 Apache Flink,為我們解決上述挑戰提供了前所未有的機會。Flink 社區的貢獻,加上阿里巴巴在該領域的大量開發工作,已經創建了一個強大的批流融合生態系統,能夠處理我們複雜的業務需求。
支持異構數據源的能力尤其具有吸引力,因為 Lazada 使用了多種繼承自阿里巴巴的數據源和技術。這些技術的開源性質意味着我們既可以利用社區的創新成果,又能保持足夠的靈活性,根據自身特定需求定製解決方案。
這一技術基礎使我們能夠構想一個統一的平台,無縫整合實時流處理與批處理,為現代電商運營提供所需的靈活性和性能。
架構方案:Flink + Hologres 的黃金組合
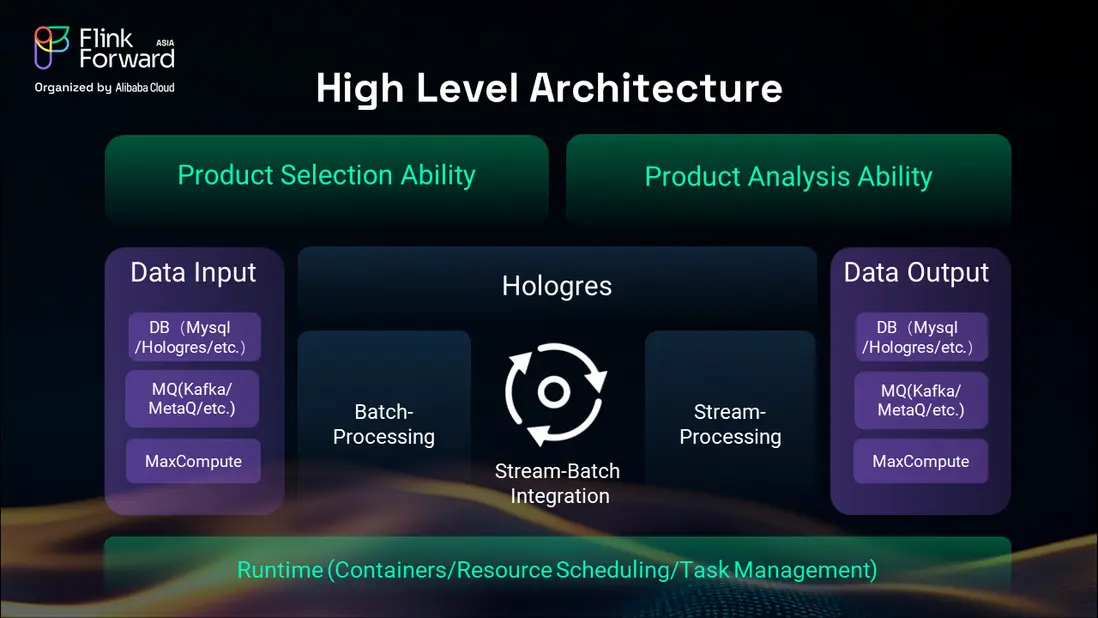
我們的解決方案以阿里雲實時計算 Flink 和 Hologres 為核心組件,構建了一個支持實時流處理與批處理能力的統一架構。該架構通過成熟的容器化和資源調度系統提供運行時可用性,並具備複雜的任務管理能力。
該平台與 Lazada 現有的多種數據庫無縫集成,最大限度地降低了集成複雜性並減少了遷移風險。對 Kafka 和 MetaQ 等常見消息隊列的支持,確保了與我們現有數據管道基礎設施的兼容性。
在批處理方面,我們使用 MaxCompute(內部稱為 ODPS)進行輸入和輸出操作。Hologres 在批處理和流處理方面均表現出卓越的性能,能夠滿足我們商品選品平台對高吞吐量的需求,同時為實時分析保持低延遲。
這種集成化方法使我們的業務團隊能夠一鍵創建商品選品任務,系統自動為特定市場和活動生成平台上最具潛力的 SKU 組合。系統支持實時分析能力,使業務團隊能夠在閃購等實時活動中監控活動表現並進行庫存調整。
數據架構:分層處理,精準匹配業務需求
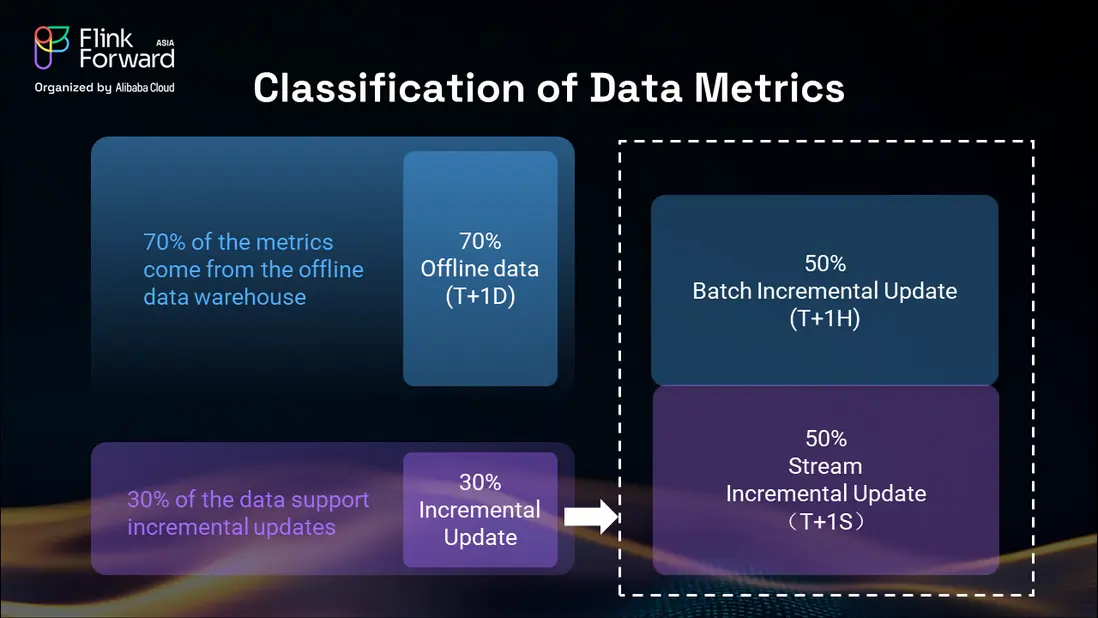
我們的分析顯示,電商平台上約 70% 的指標來自離線批處理數據倉庫操作,通常具有 T+1D(次日)的延遲。其餘 30% 由需要更及時更新的增量數據構成,我們進一步將其分為兩個不同的數據流。
其中一半的增量數據來自每小時的批處理更新(T+1H),包括聚合指標和已處理的分析數據,這些數據不需要實時處理,但需要比每日批處理更頻繁地更新。另一半則是實時流數據(T+1S),包括用户瀏覽行為、下單操作、GMV 計算以及動態價格變動。
這一實時部分尤為重要,因為賣家可以隨時更改價格,平台也能即時發起營銷活動或創建補貼券。這些動態變化必須立即反映在我們的增量數據流中,以確保商品選品和定價信息的準確性。
批處理與增量數據的整合
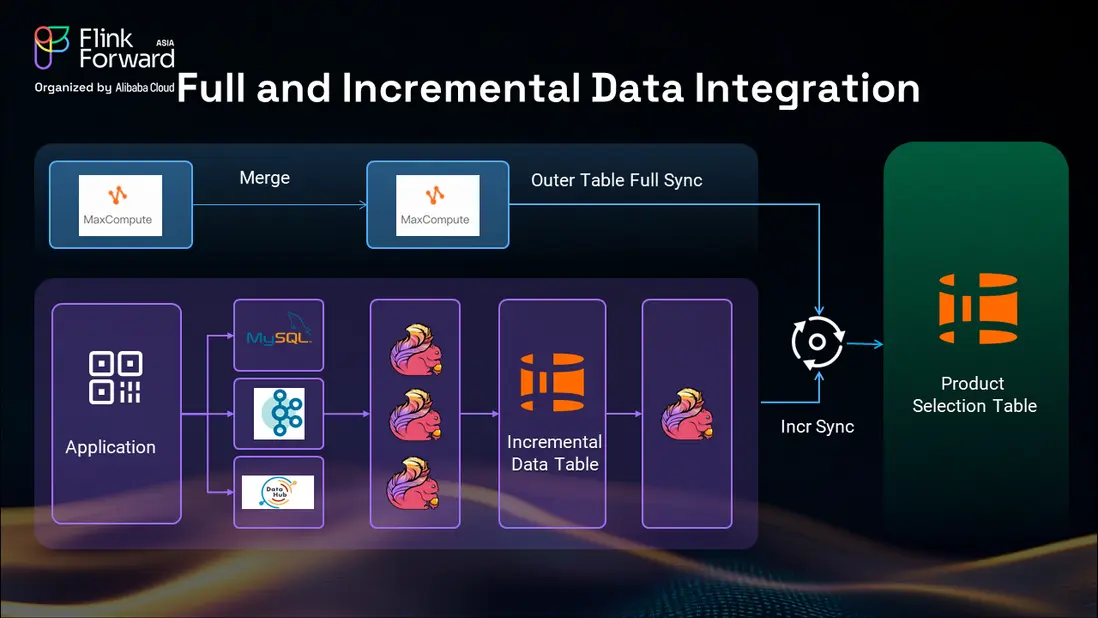
對於批處理數據部分,我們採用從 MaxCompute 向 Hologres 進行表同步的方式,利用阿里生態系統內統一的元數據管理。這一方法在淘寶的運營中已被證明成功,提供了可靠且高效的批處理數據處理能力。
增量數據處理涉及多個數據源,包括 MySQL、Kafka 和來自 MaxCompute 的每小時數據更新。我們使用 Flink 將這些數據同步到 Hologres 中的一箇中間增量數據表,該表作為不同數據源的匯聚點。
這種中間表方式具有多個優勢。首先,它支持更便捷的 binlog 重放和靈活的恢復機制,確保在災難恢復場景下的數據完整性。其次,它允許我們在中間階段整合異構的上游數據源,而不是在最終的商品選品表中進行,從而減少了處理時間和複雜性。
中間增量數據表還充當了外部系統數據的緩衝區,通過僅保留必要的增量變更來幫助優化存儲成本。我們使用 Flink 管道管理 binlog 更新,為主業務操作維護一個主分區,並設置兩個備用分區,以便在災難恢復或數據回填操作期間快速切換。
異構數據源管理
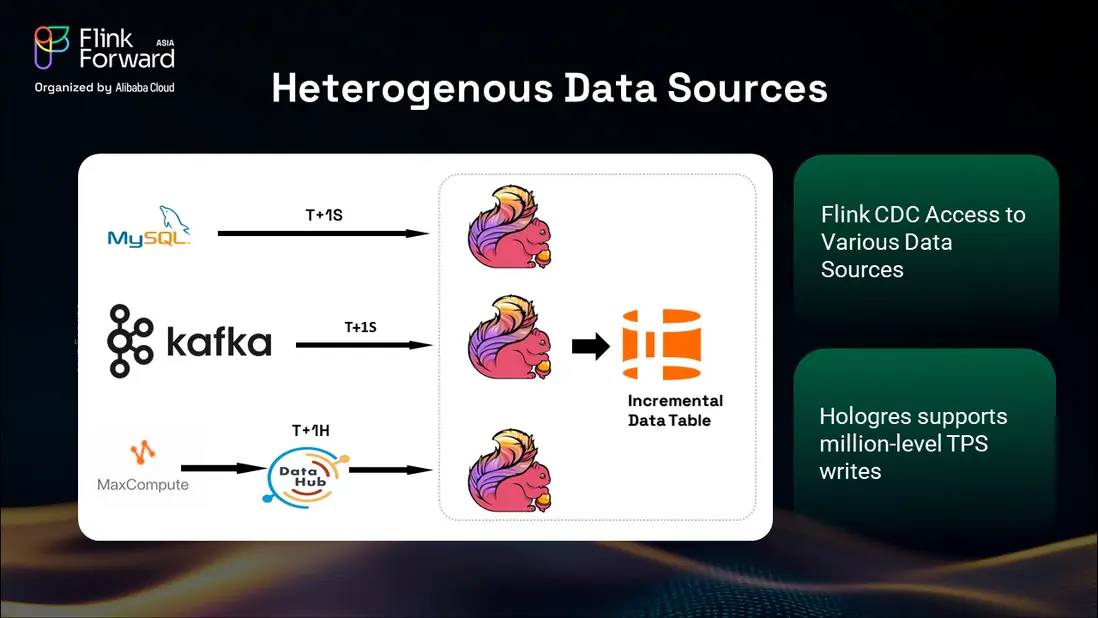
我們的平台通過 Flink 的變更數據捕獲(CDC)能力,成功處理了多樣化的數據源。來自 MySQL 和 Kafka 流的實時數據以亞秒級延遲(T+1S)處理,而來自 MaxCompute 的每小時更新則為時效性要求較低的指標提供 T+1H 處理。
Flink CDC 接入使我們能夠監控各數據源的數據變化,而 Hologres 支持百萬級 TPS 的寫入,確保系統能夠在大型促銷活動期間應對峯值流量負載。這種組合為大規模電商運營所需的可擴展性和性能提供了保障。
Hologres 的分片技術結合其高 TPS 寫入能力,使我們能夠通過 Flink 管道從 Kafka 和 MaxCompute 並行處理每秒數百萬筆交易。這一能力對於在整個龐大的商品目錄中保持數據實時性至關重要。
日常運維與工作流管理
我們的日常操作流程體現了大規模電商數據處理所需的複雜編排。每天開始時,系統會在數據表中創建一個初始分區,該分區基於前一天的離線全量數據快照。
系統監控同步任務,並在初始同步完成後,基於增量數據表觸發 binlog 重放操作。此過程包含複雜的監控機制,用於判斷重放任務何時完成,因為在重放過程中仍會有新的實時數據持續到達。
我們使用兩個觸發點來識別任務完成:一是監控數據流入模式以檢測增量重放是否結束,二是跟蹤重放數據與當前時間的接近程度。這種雙觸發機制在保持操作效率的同時,確保了數據的全面捕獲。
這種輕量級解決方案結合了全週期批處理與通過 Hologres 中間增量數據表實現的實時增量更新,為我們的日常運營提供了可靠性與性能的雙重保障。
兩大技術突破:Roaring Bitmap 與 JSON-B
Roaring Bitmap 在標籤管理中的實現
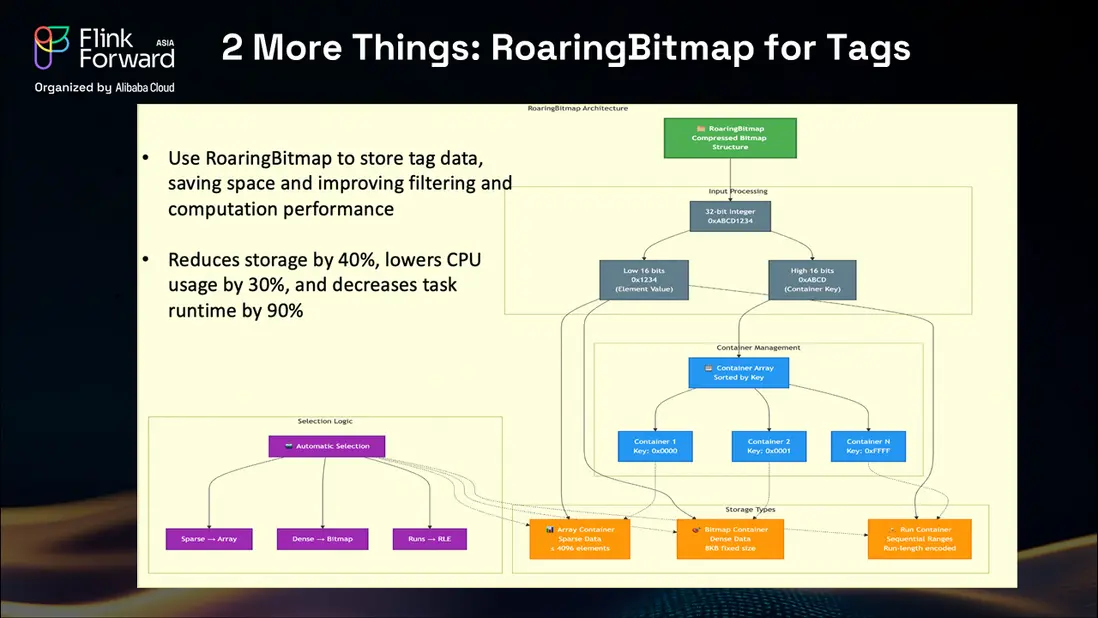
我們最重要的技術創新之一是 Roaring Bitmap 技術在標籤管理中的應用。在電商平台中,有兩個系統嚴重依賴標籤:用户畫像和商品分類。對於用户,我們需要了解其偏好,包括品類偏好、商品類型和價格區間。對於商品,我們必須用詳細屬性進行標記,如顏色、產地、材質和風格特徵。
標籤給數據系統帶來了巨大挑戰,原因在於其動態性和龐大的數量。在我們最初的 Hologres 部署中,我們使用數組存儲標籤,這在標籤檢索和分析操作中造成了顯著的性能瓶頸。
我們的團隊研究並實現了 Roaring Bitmap 技術,該技術使用 32 位整數並將其拆分為低 16 位和高 16 位,從而高效壓縮標籤數據。系統使用三種數據容器:稀疏數據使用數組容器,高密度數據使用位圖容器,連續範圍使用 run 容器。
這一實現帶來了顯著的性能提升:存儲需求減少 40%,CPU 使用量下降 30%,與標籤相關的操作整體運行時間減少 90%。這些改進顯著增強了我們的商品選品平台在大規模場景下處理複雜標籤場景的能力。
JSON-B 對半結構化數據的支持

電商平台產生大量半結構化數據,尤其是來自社交媒體評論、商品評價和複雜業務關係的數據。我們的商品選品平台需要處理商品與活動、訂單及各種業務決策相互關聯的場景,從而形成複雜的半結構化數據關係。
Hologres 的 JSON-B 支持為我們提供了所需的靈活性,它在列式存儲的同時,允許根據具體需求在存儲模式之間切換。當不需要列式存儲時,我們使用標準存儲模式;而當分析查詢需要列式訪問時,我們可以輕鬆切換到優化的列式存儲。
這種靈活性在涉及下游團隊的商品選品場景中被證明極為寶貴,尤其是在將商品數據與業務操作在比單個 SKU 更細的粒度上結合時。JSON-B 的實現使我們能夠在保持查詢性能和存儲效率的同時,處理複雜的業務關係。
業務影響與成果

基於 Flink 和 Hologres 構建的商品選品平台,在多個維度上帶來了顯著的業務價值。目前,我們運行超過 200 個實時任務,每天處理超過 20TB 的數據,增量更新每天處理 1 億條記錄。
這種高吞吐能力使我們的業務團隊能夠在閃購和促銷活動等關鍵時期,消費實時增量指標並及時做出商業決策。平台在處理海量數據的同時保持實時響應的能力,徹底改變了我們進行商品選品和活動管理的方式。
技術效益與成本優化

從技術角度看,基於 Flink 和 Hologres 的簡化架構,相比我們之前的系統,顯著降低了開發和維護成本。統一平台的方法消除了管理多個獨立系統的複雜性,同時提供了更優越的性能和可靠性。
機器資源成本降低了 50%,使我們能夠將節省的資金重新投入到擴展 SKU 選品能力和提升客户體驗上。簡化的架構還減少了系統維護所需的技術專業知識,使我們的團隊能夠專注於創新,而非運維負擔。
平台支持多種數據新鮮度要求的能力,意味着我們既可以滿足活動期間對時效性極強的實時分析需求,也能支持用於戰略規劃的全面歷史分析。這種靈活性被證明對滿足組織內多樣化的業務需求極為寶貴。
增強的業務能力
我們增強後的商品選品平台現在能夠根據業務需求,支持多種數據新鮮度和分析時間範圍。無論是團隊在活動執行期間需要實時數據,還是為年度規劃需要全面的歷史分析,平台都能提供適當的數據粒度和性能。
消除以往的數據限制,使我們的標籤能力得以顯著擴展。我們現在可以導入大量標籤數據集,包括通過翻譯和適配流程,引入來自中國市場的天貓和淘寶商品標籤。這一能力極大地提升了系統有效理解和分類商品的能力。
通過 Hologres 處理多樣化上游系統的能力,對外部數據源的支持也得到了極大增強。無論數據來自阿里巴巴內部系統還是外部賣家平台,我們的統一平台都能高效地處理和整合信息。
如今,該平台已發展成為一個混合事務與分析系統,為業務團隊提供了運營任務和戰略分析的全面能力。這種統一方法消除了對多個專用系統的依賴,同時提高了整體效率和數據一致性。
未來規劃:AI 集成與高級分析

展望未來,我們的技術規劃重點集中在人工智能集成和高級分析能力上。我們已經開始為基於主題的場景實施 AI 驅動的商品選品,例如為特定市場創建聖誕節、F1 賽事或明星演唱會相關的活動。
我們的 AI 驅動選品系統能夠基於活動主題和歷史表現數據,從數十億可用商品中推薦最具潛力的 SKU。這一能力利用了 Hologres 的向量查詢功能,以及即將推出的 64 位 Roaring Bitmap 支持,這將實現更復雜的標籤管理和 AI 生成的商品理解。
我們預計 AI 生成的商品標籤將比人工生成的標籤產生更多數據,這需要更強的存儲和處理能力。擴展後的 Roaring Bitmap 支持將在處理這種數據量增長的同時保持查詢性能方面發揮關鍵作用。
新品類發現與趨勢分析
我們未來的發展還包括識別平台上尚未上架、甚至在整個電商生態系統中都尚未出現的產品的能力。這涉及檢測概念性商品和新興趨勢,這些可能代表新的商業機會。
通過與開放搜索引擎的集成以及 AI 驅動的趨勢分析,我們將能夠主動識別新的商品組合機會。這一能力旨在幫助我們的業務團隊提前捕捉市場機遇,通過識別新興的客户需求和商品類別來搶佔先機。
客户滿意度的無止境追求推動着商品選品的持續創新。客户不斷尋求更具吸引力、更新穎、更令人滿意的產品組合,這為我們技術團隊應用前沿技術解決真實業務問題創造了持續的機會。
技術實現洞察
性能優化策略
我們的實施揭示了若干對大規模電商平台至關重要的性能優化策略。使用中間數據表作為緩衝區,顯著提高了系統的彈性和恢復能力,同時降低了數據源管理的複雜性。
分區策略被證明在維護和災難恢復場景中保持系統可用性方面至關重要。我們採用的三分區方法(一個主分區,兩個備用分區)能夠在無服務中斷的情況下實現無縫切換,確保關鍵操作期間的業務連續性。
Flink 的流處理能力與 Hologres 的高性能存儲相結合,產生了超越各組件單獨能力之和的協同效應。這一集成表明,選擇能夠相互增強優勢的互補技術至關重要。
可擴展性考量
從一開始就為可擴展性而設計,對於應對 Lazada 的增長軌跡至關重要。我們的架構能夠在無需根本性重新設計的情況下,適應不斷增長的數據量、用户流量和業務複雜性。
對異構數據源的支持確保了隨着 Lazada 進入新市場或增加新業務線,我們能夠集成新的數據流和業務系統。這種靈活性對我們支持在東南亞的快速擴張至關重要。
通過高效的數處理和存儲策略實現的資源優化,使我們能夠經濟高效地擴展。在性能提升的同時將機器成本降低 50%,證明了正確的架構選擇能夠同時帶來技術和經濟效益。
經驗教訓與最佳實踐
數據架構設計原則
我們的經驗突顯了在電商環境中設計高效數據架構的若干關鍵原則。首先,通過分層架構實現關注點分離,能夠在保持系統整體一致性的同時,對不同組件進行獨立優化。
其次,中間數據層在管理複雜性和提供靈活性方面的價值不可低估。這些層充當緩衝區、轉換點和恢復機制,顯著提升了系統的彈性和可維護性。
第三,從一開始就為批處理和流處理工作負載進行設計,確保系統能夠在不犧牲架構的前提下滿足多樣化的業務需求。我們採用 Flink 和 Hologres 所實現的統一方法,正是這一原則的典範。
技術選型標準
選擇能夠相互補充並與現有基礎設施對齊的技術,可以降低集成複雜性並加快實施進度。我們選擇 Flink 和 Hologres,既利用了阿里生態系統現有的投入,又獲得了所需的先進能力。
擁有強大社區支持的開源技術,提供了長期可持續性和持續的創新。活躍的 Flink 社區確保了對流處理和實時分析新興用例的持續開發和支持。
性能特徵必須與業務需求相匹配,特別是對於處理高吞吐、低延遲工作負載的系統。Hologres 的百萬級 TPS 能力對於滿足我們在大型促銷活動期間的峯值流量需求至關重要。
結語
Lazada 利用阿里雲實時計算 Flink 和 Hologres 對商品選品平台的改造,展示了現代流處理和實時分析技術對電商運營的深遠影響。我們從一個分散、以批處理為主的系統,轉型為一個統一、實時的平台,在技術、運營和業務層面都帶來了巨大收益。
基礎設施成本降低 50%,結合數據新鮮度和分析能力的顯著提升,驗證了投資現代數據架構的戰略價值。更重要的是,平台在關鍵商業事件中支持實時決策的能力,徹底改變了我們進行活動管理和優化客户體驗的方式。
我們的經驗表明,成功的數字化轉型不僅需要技術採納,更需要深思熟慮的架構設計、謹慎的技術選型以及對業務需求的深刻理解。Apache Flink 的流處理能力與 Hologres 的高性能分析相結合,產生了單靠任一技術都無法獨立實現的能力。
隨着我們繼續通過 AI 集成和高級分析能力演進平台,我們所構建的基礎為未來的創新提供了所需的靈活性和性能。滿足客户需求的無盡旅程推動着持續改進,確保我們的技術投資能夠帶來持久的業務價值。
對於正在考慮類似轉型的組織,我們的經驗表明,現代流處理和實時分析的好處遠不止於技術改進。能夠實時做出數據驅動的決策、用統一基礎設施支持多樣化業務需求、並經濟高效地擴展,這些優勢直接轉化為業務成功。
電商的未來在於以業務速度處理和分析數據,而我們對 Flink 和 Hologres 的實施,已為 Lazada 在這一數據驅動的格局中蓬勃發展做好了準備。隨着我們不斷突破實時分析和 AI 驅動洞察的可能邊界,我們仍致力於與更廣泛的技術社區分享我們的經驗。