

引言
近期,阿里通義千問團隊創新性提出了 GSPO 算法,PAI-ChatLearn 框架第一時間支持並復現了GSPO的強化學習訓練過程,本文將介紹在 PAI 平台復現 GSPO 的最佳實踐。
GSPO 算法介紹
強化學習(Reinforcement Learning, RL)是拓展語言模型、增加其深度推理與問題求解能力的關鍵技術範式。為了持續拓展 RL,首要前提是確保穩定、魯棒的訓練過程。現有的 RL 算法(如 GRPO)在長期訓練中,會暴露出嚴重的不穩定性問題並招致不可逆轉的模型崩潰,阻礙了通過增加計算以獲得進一步的性能提升。
針對這個問題,通義團隊提出了GSPO(Group Sequence Policy Optimization)算法。GSPO 算法與其他 RL 算法相比,定義了序列級別的重要性比率,並在序列層面執行裁剪、獎勵和優化。
相較於 GRPO,GSPO 在以下方面展現出突出優勢:
- 強大高效:GSPO 具備顯著更高的訓練效率,並且能夠通過增加計算獲得持續的性能提升;
- 穩定性出色:GSPO 能夠保持穩定的訓練過程,並且根本地解決了混合專家(Mixture-of-Experts,MoE)模型的 RL 訓練穩定性問題;
- 基礎設施友好:由於在序列層面執行優化,GSPO 原則上對精度容忍度更高,具有簡化 RL 基礎設施的誘人前景。
PAI-ChatLearn 強化學習框架介紹
ChatLearn是阿里雲人工智能平台 PAI 推出高性能一體化強化學習框架,第一時間支持並復現了 GSPO 的強化學習訓練過程。PAI-ChatLearn具備如下幾個優勢:
- 易用性
通過計算圖構建的方式,支持用户只需要封裝幾個函數就可以實現不同種類強化學習算法訓練。同時ChatLearn 支持靈活的資源調度機制,支持各模型的資源獨佔或複用,通過系統調度策略支持高效的串行/並行執行和高效的顯存共享。
- 高性能
支持Sequence Packing、Sequence Parallel、Group GEMM等加速技術,極大提升了GPU利用率。
- 支持不同推理和訓練引擎
支持vLLM和SGLang推理框架以及FSDP和Megatron作為訓練框架進行高效穩定的強化學習訓練
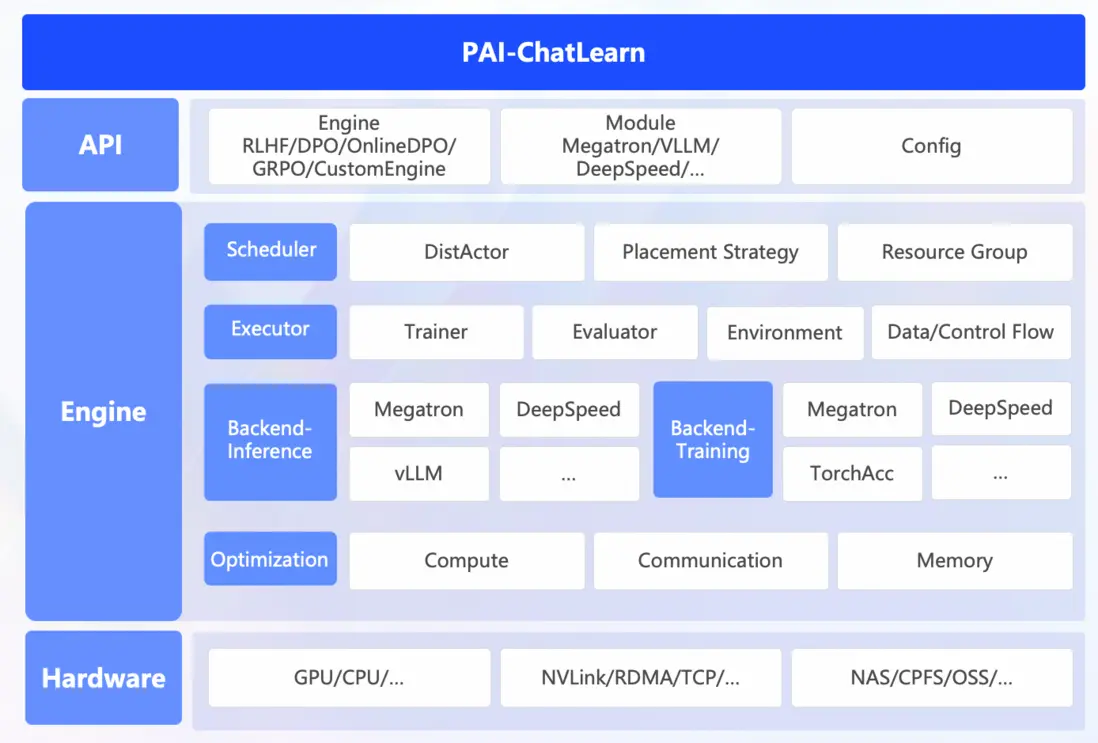
PAI-ChatLearn 整體架構
本文將介紹如何基於 PAI-ChatLearn 框架,在 2機8xH20 上快速開始基於 Megatron-Core 及 vLLM 引擎的GSPO 訓練。
端到端流程
GSPO 強化學習訓練全過程的復現,將在阿里雲人工智能平台 PAI 上完成。PAI 提供雲原生的 AI 分佈式訓練平台 PAI-DLC 和交互式建模 PAI-DSW,為開發者和企業提供靈活、穩定、易用和高性能的大模型開發、訓練環境,支持快速完成 GSPO 全過程復現。
Step 1:環境配置
- Docker鏡像準備
在 PAI-DLC 或 PAI-DSW 復現 GSPO 全過程,填寫如下鏡像地址,啓動實例:
dsw-registry.cn-shanghai.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.6.0-vllm0.8.5-ubuntu24.04-cuda12.6-py312可以使用 vpc 地址來加速鏡像拉取速度,請根據實例所在region修改鏡像地址。以上海 Region的 PAI-DSW實例為例,使用如下鏡像
dsw-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.6.0-vllm0.8.5-ubuntu24.04-cuda12.6-py312
若在非PAI的環境中使用可直接拉取如下公網鏡像地址進行實驗:
dsw-registry.cn-shanghai.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.6.0-vllm0.8.5-ubuntu24.04-cuda12.6-py312
- 代碼準備
git clone https://github.com/alibaba/ChatLearn.git
wget https://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/csrc/Pai-Megatron-Patch.tar
tar -xvf Pai-Megatron-Patch.tarStep 2:數據&模型準備
以MATH-lighteval數據集作為示例,完成數據集下載和模型準備。
cd ChatLearn
# download dataset
mkdir -p dataset
modelscope download --dataset AI-ModelScope/MATH-lighteval --local_dir dataset/MATH-lighteval
# preprocess dataset
python chatlearn/data/data_preprocess/math_lighteval.py --input_dir dataset/MATH-lighteval --local_dir dataset/MATH-lighteval
# download model weight
modelscope download --model Qwen/Qwen3-30B-A3B --local_dir pretrained_models/Qwen3-30B-A3BStep 3:模型轉換
使用下述腳本,將Qwen3-30B-A3B的Huggingface格式的模型轉換到 MCore 格式。
CHATLEARN_ROOT=$(pwd)
cd ../Pai-Megatron-Patch/toolkits/distributed_checkpoints_convertor
bash scripts/qwen3/run_8xH20.sh \
A3B \
${CHATLEARN_ROOT}/pretrained_models/Qwen3-30B-A3B \
${CHATLEARN_ROOT}/pretrained_models/Qwen3-30B-A3B-to-mcore \
false \
true \
bf16Step 4:訓練
運行以下命令開始 GSPO 強化學習訓練。
cd ${CHATLEARN_ROOT}
bash scripts/train_mcore_vllm_qwen3_30b_gspo.sh實驗結果
我們在MATH-lighteval上對比了GRPO與GSPO兩種算法的收斂效果。代表 GSPO 和 GRPO 的兩條曲線都呈明顯的上升趨勢,説明隨着訓練的進行,兩種方法在該任務上的性能都在穩步提升。同時,GSPO 的曲線持續位於 GRPO 上方,反映出 GSPO 相對於基線方法在收斂上具有一定優勢。
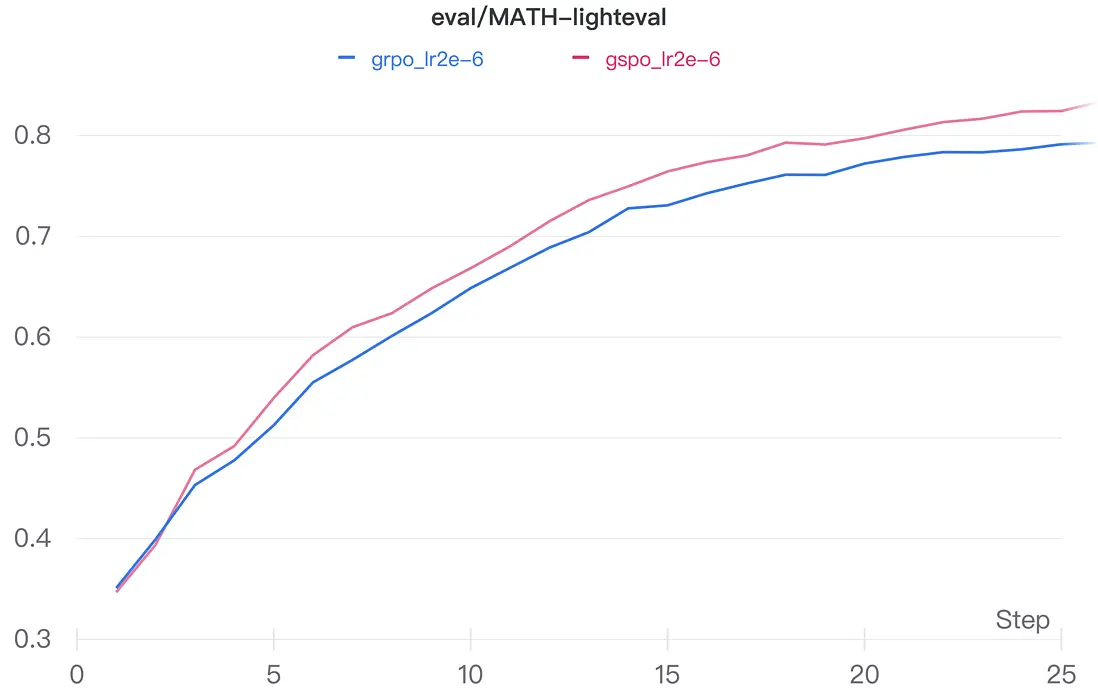
GRPO與GSPO兩種算法的收斂效果
對於兩組實驗的實際clip比例,我們能得到與論文量級接近的結果。
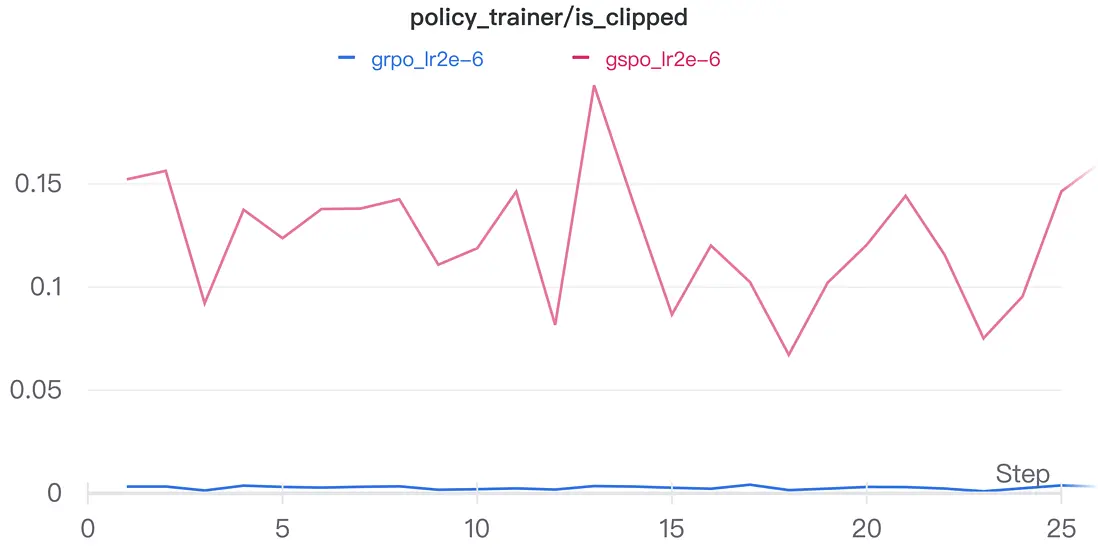
結語
在大模型蓬勃發展的今天,阿里雲人工智能平台 PAI 提供圍繞大模型全生命週期的平台能力支持,將持續推出在強化學習、模型蒸餾、數據預處理等方向的最佳實踐和技術解讀。誠邀您共同探索企業級AI工程化的最佳實踐,獲取智能化轉型的核心技術密鑰。