對事務工作接觸了不少,這裏完整的從基本概念,原理,分析,案列等等梳理下事務機制的底層邏輯;
事務機制的底層邏輯
事務的基本特性、機制及原理
百度百科定義
事務(Transaction),一般是指要做的或所做的事情。在計算機術語中是指訪問並可能更新數據庫中各種數據項的一個程序執行單元(unit)。事務通常由高級數據庫操縱語言或編程語言(如SQL,C++或Java)書寫的用户程序的執行所引起,並用形如begin transaction和end transaction語句(或函數調用)來界定。事務由事務開始(begin transaction)和事務結束(end transaction)之間執行的全體操作組成。
事務的幾個特性
原子性(Atomicity)
原子性是指事務包含的所有操作要麼全部成功,要麼全部失敗回滾,這和前面兩篇博客介紹事務的功能是一樣的概念,因此事務的操作如果成功就必須要完全應用到數據庫,如果操作失敗則不能對數據庫有任何影響。
一致性(Consistency)
一致性是指事務必須使數據庫從一個一致性狀態變換到另一個一致性狀態,也就是説一個事務執行之前和執行之後都必須處於一致性狀態。
拿轉賬來説,假設用户A和用户B兩者的錢加起來一共是5000,那麼不管A和B之間如何轉賬,轉幾次賬,事務結束後兩個用户的錢相加起來應該還得是5000,這就是事務的一致性。
隔離性(Isolation)
隔離性是當多個用户併發訪問數據庫時,比如操作同一張表時,數據庫為每一個用户開啓的事務,不能被其他事務的操作所幹擾,多個併發事務之間要相互隔離。
即要達到這麼一種效果:對於任意兩個併發的事務T1和T2,在事務T1看來,T2要麼在T1開始之前就已經結束,要麼在T1結束之後才開始,這樣每個事務都感覺不到有其他事務在併發地執行。
持久性(Durability)
持久性是指一個事務一旦被提交了,那麼對數據庫中的數據的改變就是永久性的,即便是在數據庫系統遇到故障的情況下也不會丟失提交事務的操作。
例如我們在使用JDBC操作數據庫時,在提交事務方法後,提示用户事務操作完成,當我們程序執行完成直到看到提示後,就可以認定事務以及正確提交,即使這時候數據庫出現了問題,也必須要將我們的事務完全執行完成,否則就會造成我們看到提示事務處理完畢,但是數據庫因為故障而沒有執行事務的重大錯誤。
並行事務會引發什麼問題?
4個事務特性的存在是必須要遵守的,如果隔離性不存在,併發事務會引發什麼問題呢?
以常見的MYSQL為例,MySQL 服務端是允許多個客户端連接的,這意味着 MySQL 會出現同時處理多個事務的情況。
那麼在同時處理多個事務的時候,就可能出現髒讀(dirty read)、不可重複讀(non-repeatable read)、幻讀(phantom read)的問題。
接下來,通過舉例子給大家説明,這些問題是如何發生的。
髒讀
如果一個事務「讀到」了另一個「未提交事務修改過的數據」,就意味着發生了「髒讀」現象。
舉個栗子:
假設有 A 和 B 這兩個事務同時在處理,事務 A 先開始從數據庫中讀取小林的餘額數據,然後再執行更新操作,如果此時事務 A 還沒有提交事務,而此時正好事務 B 也從數據庫中讀取小林的餘額數據,那麼事務 B 讀取到的餘額數據是剛才事務 A 更新後的數據,即使沒有提交事務。
因為事務 A 是還沒提交事務的,也就是它隨時可能發生回滾操作,如果在上面這種情況事務 A 發生了回滾,那麼事務 B 剛才得到的數據就是過期的數據,這種現象就被稱為髒讀。
不可重複讀
在一個事務內多次讀取同一個數據,如果出現前後兩次讀到的數據不一樣的情況,就意味着發生了「不可重複讀」現象。
舉個栗子:
假設有 A 和 B 這兩個事務同時在處理,事務 A 先開始從數據庫中讀取小林的餘額數據,然後繼續執行代碼邏輯處理,在這過程中如果事務 B 更新了這條數據,並提交了事務,那麼當事務 A 再次讀取該數據時,就會發現前後兩次讀到的數據是不一致的,這種現象就被稱為不可重複讀。
幻讀
在一個事務內多次查詢某個符合查詢條件的「記錄數量」,如果出現前後兩次查詢到的記錄數量不一樣的情況,就意味着發生了「幻讀」現象。
舉個栗子:
假設有 A 和 B 這兩個事務同時在處理,事務 A 先開始從數據庫查詢賬户餘額大於 100 萬的記錄,發現共有 5 條,然後事務 B 也按相同的搜索條件也是查詢出了 5 條記錄。
接下來,事務 A 插入了一條餘額超過 100 萬的賬號,並提交了事務,此時數據庫超過 100 萬餘額的賬號個數就變為 6。
然後事務 B 再次查詢賬户餘額大於 100 萬的記錄,此時查詢到的記錄數量有 6 條,發現和前一次讀到的記錄數量不一樣了,就感覺發生了幻覺一樣,這種現象就被稱為幻讀。
事務的隔離級別有哪些?
前面我們提到,當多個事務併發執行時可能會遇到「髒讀、不可重複讀、幻讀」的現象,這些現象會對事務的一致性產生不同程序的影響。
- 髒讀:讀到其他事務未提交的數據;
- 不可重複讀:前後讀取的數據不一致;
- 幻讀:前後讀取的記錄數量不一致。
這三個現象的嚴重性排序如下:

SQL 標準提出了四種隔離級別來規避這些現象,隔離級別越高,性能效率就越低,這四個隔離級別如下:
- 讀未提交(*read uncommitted*),指一個事務還沒提交時,它做的變更就能被其他事務看到;
- 讀提交(*read committed*),指一個事務提交之後,它做的變更才能被其他事務看到;
- 可重複讀(*repeatable read*),指一個事務執行過程中看到的數據,一直跟這個事務啓動時看到的數據是一致的,MySQL InnoDB 引擎的默認隔離級別;
- 串行化(*serializable* );會對記錄加上讀寫鎖,在多個事務對這條記錄進行讀寫操作時,如果發生了讀寫衝突的時候,後訪問的事務必須等前一個事務執行完成,才能繼續執行;
按隔離水平高低排序如下:

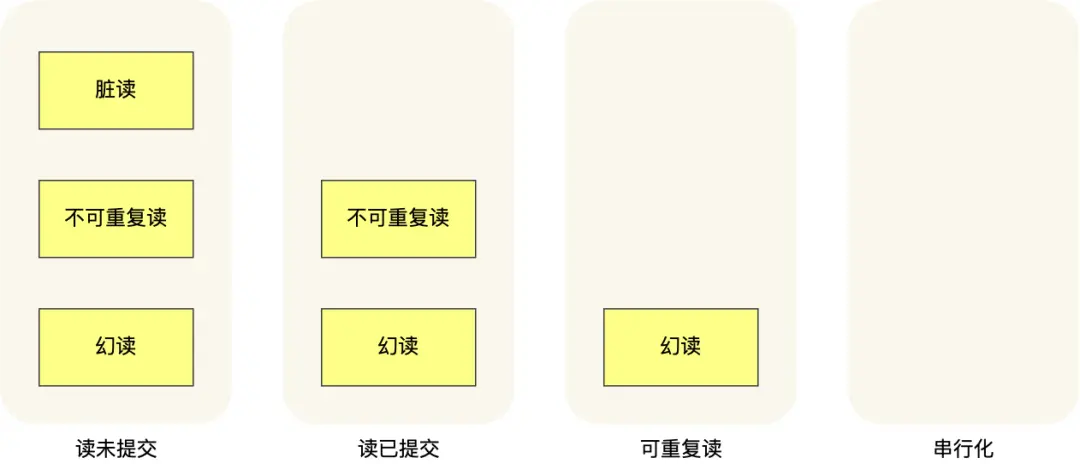
針對不同的隔離級別,併發事務時可能發生的現象也會不同。
也就是説:
- 在「讀未提交」隔離級別下,可能發生髒讀、不可重複讀和幻讀現象;
- 在「讀提交」隔離級別下,可能發生不可重複讀和幻讀現象,但是不可能發生髒讀現象;
- 在「可重複讀」隔離級別下,可能發生幻讀現象,但是不可能髒讀和不可重複讀現象;
- 在「串行化」隔離級別下,髒讀、不可重複讀和幻讀現象都不可能會發生。
所以,要解決髒讀現象,就要升級到「讀提交」以上的隔離級別;要解決不可重複讀現象,就要升級到「可重複讀」的隔離級別,要解決幻讀現象不建議將隔離級別升級到「串行化」。
不同的數據庫廠商對 SQL 標準中規定的 4 種隔離級別的支持不一樣,有的數據庫只實現了其中幾種隔離級別,我們討論的 MySQL 雖然支持 4 種隔離級別,但是與SQL 標準中規定的各級隔離級別允許發生的現象卻有些出入。
MySQL 在「可重複讀」隔離級別下,可以很大程度上避免幻讀現象的發生(注意是很大程度避免,並不是徹底避免),所以 MySQL 並不會使用「串行化」隔離級別來避免幻讀現象的發生,因為使用「串行化」隔離級別會影響性能。
MySQL InnoDB 引擎的默認隔離級別雖然是「可重複讀」,但是它很大程度上避免幻讀現象
- 針對快照讀(普通 select 語句),是通過 MVCC 方式解決了幻讀,因為可重複讀隔離級別下,事務執行過程中看到的數據,一直跟這個事務啓動時看到的數據是一致的,即使中途有其他事務插入了一條數據,是查詢不出來這條數據的,所以就很好了避免幻讀問題。
- 針對當前讀(select ... for update 等語句),是通過 next-key lock(記錄鎖+間隙鎖)方式解決了幻讀,因為當執行 select ... for update 語句的時候,會加上 next-key lock,如果有其他事務在 next-key lock 鎖範圍內插入了一條記錄,那麼這個插入語句就會被阻塞,無法成功插入,所以就很好了避免幻讀問題。
接下來,舉個具體的例子來説明這四種隔離級別,有一張賬户餘額表,裏面有一條賬户餘額為 100 萬的記錄。然後有兩個併發的事務,事務 A 只負責查詢餘額,事務 B 則會將我的餘額改成 200 萬,下面是按照時間順序執行兩個事務的行為:
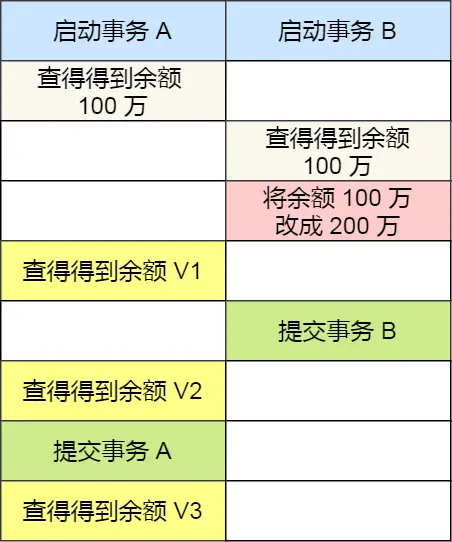
在不同隔離級別下,事務 A 執行過程中查詢到的餘額可能會不同:
- 在「讀未提交」隔離級別下,事務 B 修改餘額後,雖然沒有提交事務,但是此時的餘額已經可以被事務 A 看見了,於是事務 A 中餘額 V1 查詢的值是 200 萬,餘額 V2、V3 自然也是 200 萬了;
- 在「讀提交」隔離級別下,事務 B 修改餘額後,因為沒有提交事務,所以事務 A 中餘額 V1 的值還是 100 萬,等事務 B 提交完後,最新的餘額數據才能被事務 A 看見,因此額 V2、V3 都是 200 萬;
- 在「可重複讀」隔離級別下,事務 A 只能看見啓動事務時的數據,所以餘額 V1、餘額 V2 的值都是 100 萬,當事務 A 提交事務後,就能看見最新的餘額數據了,所以餘額 V3 的值是 200 萬;
- 在「串行化」隔離級別下,事務 B 在執行將餘額 100 萬修改為 200 萬時,由於此前事務 A 執行了讀操作,這樣就發生了讀寫衝突,於是就會被鎖住,直到事務 A 提交後,事務 B 才可以繼續執行,所以從 A 的角度看,餘額 V1、V2 的值是 100 萬,餘額 V3 的值是 200萬。
這四種隔離級別具體是如何實現的呢?
- 對於「讀未提交」隔離級別的事務來説,因為可以讀到未提交事務修改的數據,所以直接讀取最新的數據就好了;
- 對於「串行化」隔離級別的事務來説,通過加讀寫鎖的方式來避免並行訪問;
- 對於「讀提交」和「可重複讀」隔離級別的事務來説,它們是通過 Read View 來實現的,它們的區別在於創建 Read View 的時機不同,大家可以把 Read View 理解成一個數據快照,就像相機拍照那樣,定格某一時刻的風景。「讀提交」隔離級別是在「每個語句執行前」都會重新生成一個 Read View,而「可重複讀」隔離級別是「啓動事務時」生成一個 Read View,然後整個事務期間都在用這個 Read View。
Read View 在 MVCC 裏如何工作的?
上面提到過 Read View,我們經常會聽到MVCC的解決方案,MVCC的意思用簡單的話講就是對數據庫的任何修改的提交都不會直接覆蓋之前的數據,而是產生一個新的版本與老版本共存,使得讀取時可以完全不加鎖。這樣讀某一個數據時,事務可以根據隔離級別選擇要讀取哪個版本的數據,過程中完全不需要加鎖。
那Read View是怎麼在MVCC裏工作的?
我們需要了解兩個知識:
- Read View 中四個字段作用;
- 聚簇索引記錄中兩個跟事務有關的隱藏列;
那 Read View 到底是個什麼東西?
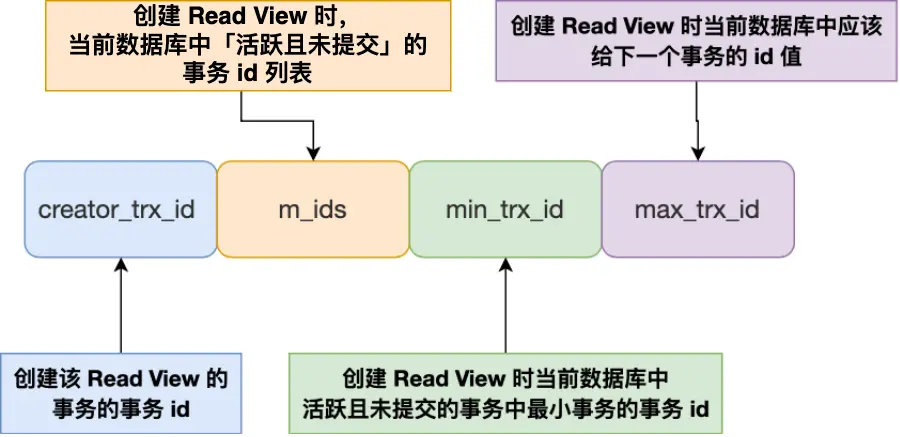
Read View 有四個重要的字段:
- m\_ids :指的是在創建 Read View 時,當前數據庫中「活躍事務」的事務 id 列表,注意是一個列表,“活躍事務”指的就是,啓動了但還沒提交的事務。
- min\_trx\_id :指的是在創建 Read View 時,當前數據庫中「活躍事務」中事務 id 最小的事務,也就是 m\_ids 的最小值。
- max\_trx\_id :這個並不是 m\_ids 的最大值,而是創建 Read View 時當前數據庫中應該給下一個事務的 id 值,也就是全局事務中最大的事務 id 值 + 1;
- creator\_trx\_id :指的是創建該 Read View 的事務的事務 id。
知道了 Read View 的字段,我們還需要了解聚簇索引記錄中的兩個隱藏列。
假設在賬户餘額表插入一條小林餘額為 100 萬的記錄,然後我把這兩個隱藏列也畫出來,該記錄的整個示意圖如下:
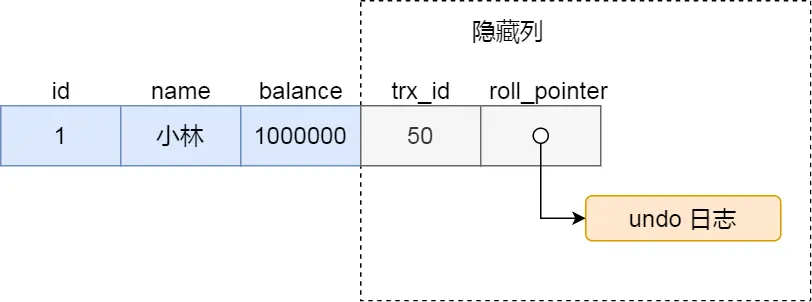
對於使用 InnoDB 存儲引擎的數據庫表,它的聚簇索引記錄中都包含下面兩個隱藏列:
- trx\_id,當一個事務對某條聚簇索引記錄進行改動時,就會把該事務的事務 id 記錄在 trx\_id 隱藏列裏;
- roll\_pointer,每次對某條聚簇索引記錄進行改動時,都會把舊版本的記錄寫入到 undo 日誌中,然後這個隱藏列是個指針,指向每一箇舊版本記錄,於是就可以通過它找到修改前的記錄。
在創建 Read View 後,我們可以將記錄中的 trx\_id 劃分這三種情況:
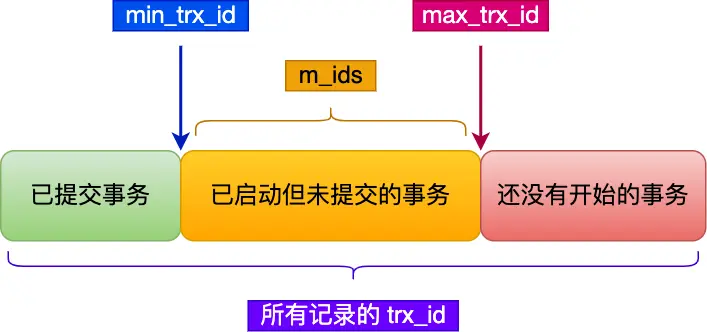
一個事務去訪問記錄的時候,除了自己的更新記錄總是可見之外,還有這幾種情況:
- 如果記錄的 trx\_id 值小於 Read View 中的 min\_trx\_id 值,表示這個版本的記錄是在創建 Read View 前已經提交的事務生成的,所以該版本的記錄對當前事務可見。
- 如果記錄的 trx\_id 值大於等於 Read View 中的 max\_trx\_id 值,表示這個版本的記錄是在創建 Read View 後才啓動的事務生成的,所以該版本的記錄對當前事務不可見。
-
如果記錄的 trx\_id 值在 Read View 的min\_trx\_id和max\_trx\_id之間,需要判斷 trx\_id 是否在 m\_ids 列表中:
- 如果記錄的 trx\_id 在 m\_ids 列表中,表示生成該版本記錄的活躍事務依然活躍着(還沒提交事務),所以該版本的記錄對當前事務不可見。
- 如果記錄的 trx\_id 不在 m\_ids列表中,表示生成該版本記錄的活躍事務已經被提交,所以該版本的記錄對當前事務可見。
所以這裏完整理解下來,這種通過「版本鏈」來控制併發事務訪問同一個記錄時的行為就叫 MVCC(多版本併發控制)。
可重複讀是如何工作的?
可重複讀隔離級別是啓動事務時生成一個 Read View,然後整個事務期間都在用這個 Read View。
假設事務 A (事務 id 為51)啓動後,緊接着事務 B (事務 id 為52)也啓動了,那這兩個事務創建的 Read View 如下:
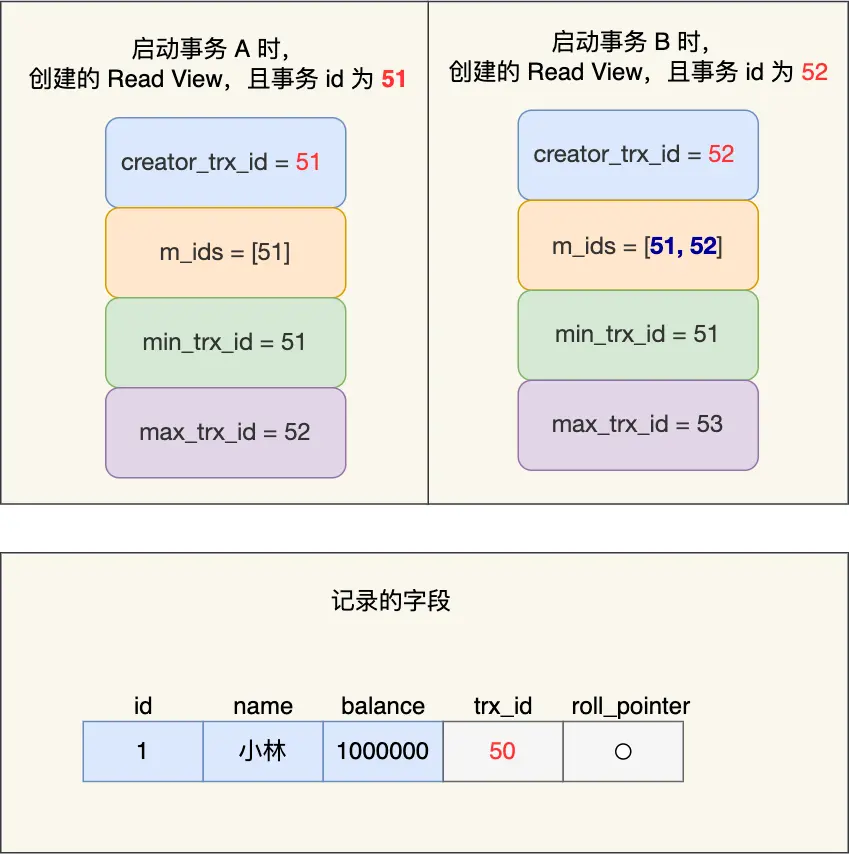
事務 A 和 事務 B 的 Read View 具體內容如下:
- 在事務 A 的 Read View 中,它的事務 id 是 51,由於它是第一個啓動的事務,所以此時活躍事務的事務 id 列表就只有 51,活躍事務的事務 id 列表中最小的事務 id 是事務 A 本身,下一個事務 id 則是 52。
- 在事務 B 的 Read View 中,它的事務 id 是 52,由於事務 A 是活躍的,所以此時活躍事務的事務 id 列表是 51 和 52,活躍的事務 id 中最小的事務 id 是事務 A,下一個事務 id 應該是 53。
接着,在可重複讀隔離級別下,事務 A 和事務 B 按順序執行了以下操作:
- 事務 B 讀取小林的賬户餘額記錄,讀到餘額是 100 萬;
- 事務 A 將小林的賬户餘額記錄修改成 200 萬,並沒有提交事務;
- 事務 B 讀取小林的賬户餘額記錄,讀到餘額還是 100 萬;
- 事務 A 提交事務;
- 事務 B 讀取小林的賬户餘額記錄,讀到餘額依然還是 100 萬;
接下來,跟大傢俱體分析下。
事務 B 第一次讀小林的賬户餘額記錄,在找到記錄後,它會先看這條記錄的 trx\_id,此時發現 trx\_id 為 50,比事務 B 的 Read View 中的 min\_trx\_id 值(51)還小,這意味着修改這條記錄的事務早就在事務 B 啓動前提交過了,所以該版本的記錄對事務 B 可見的,也就是事務 B 可以獲取到這條記錄。
接着,事務 A 通過 update 語句將這條記錄修改了(還未提交事務),將小林的餘額改成 200 萬,這時 MySQL 會記錄相應的 undo log,並以鏈表的方式串聯起來,形成版本鏈,如下圖:
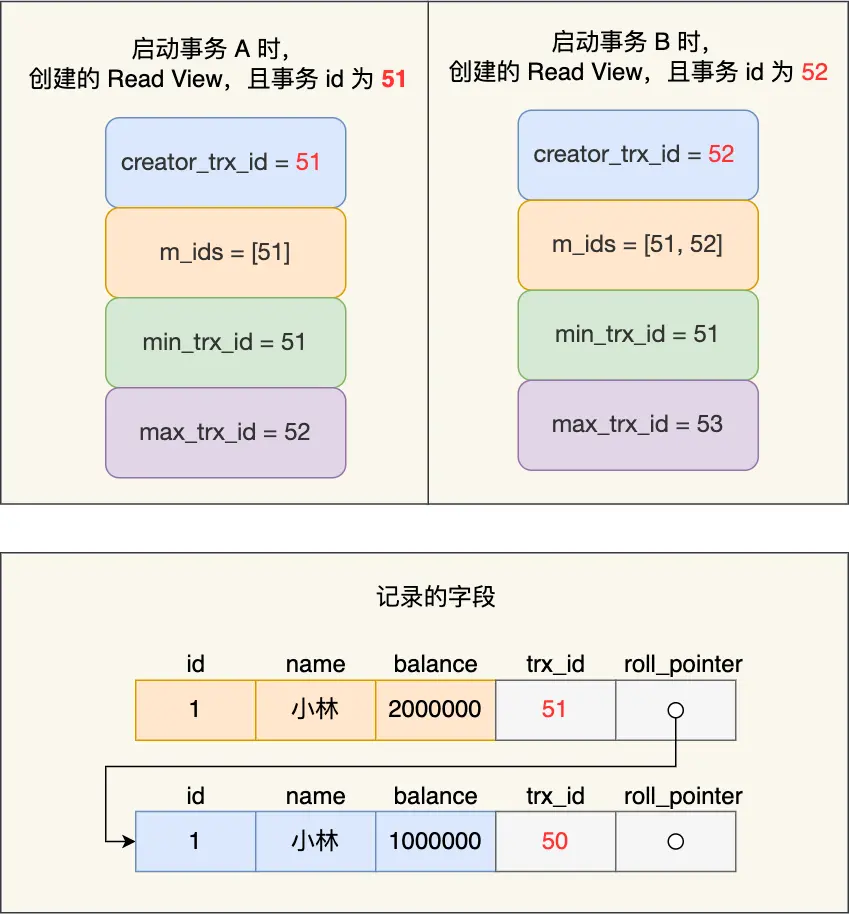
你可以在上圖的「記錄的字段」看到,由於事務 A 修改了該記錄,以前的記錄就變成舊版本記錄了,於是最新記錄和舊版本記錄通過鏈表的方式串起來,而且最新記錄的 trx\_id 是事務 A 的事務 id(trx\_id = 51)。
然後事務 B 第二次去讀取該記錄,發現這條記錄的 trx\_id 值為 51,在事務 B 的 Read View 的 min\_trx\_id 和 max\_trx\_id 之間,則需要判斷 trx\_id 值是否在 m\_ids 範圍內,判斷的結果是在的,那麼説明這條記錄是被還未提交的事務修改的,這時事務 B 並不會讀取這個版本的記錄。而是沿着 undo log 鏈條往下找舊版本的記錄,直到找到 trx\_id 「小於」事務 B 的 Read View 中的 min\_trx\_id 值的第一條記錄,所以事務 B 能讀取到的是 trx\_id 為 50 的記錄,也就是小林餘額是 100 萬的這條記錄。
最後,當事物 A 提交事務後,由於隔離級別時「可重複讀」,所以事務 B 再次讀取記錄時,還是基於啓動事務時創建的 Read View 來判斷當前版本的記錄是否可見。所以,即使事物 A 將小林餘額修改為 200 萬並提交了事務, 事務 B 第三次讀取記錄時,讀到的記錄都是小林餘額是 100 萬的這條記錄。
就是通過這樣的方式實現了,「可重複讀」隔離級別下在事務期間讀到的記錄都是事務啓動前的記錄。
讀提交是如何工作的?
讀提交隔離級別是在每次讀取數據時,都會生成一個新的 Read View。
也意味着,事務期間的多次讀取同一條數據,前後兩次讀的數據可能會出現不一致,因為可能這期間另外一個事務修改了該記錄,並提交了事務。
那讀提交隔離級別是怎麼工作呢?我們還是以前面的例子來聊聊。
假設事務 A (事務 id 為51)啓動後,緊接着事務 B (事務 id 為52)也啓動了,接着按順序執行了以下操作:
- 事務 B 讀取數據(創建 Read View),小林的賬户餘額為 100 萬;
- 事務 A 修改數據(還沒提交事務),將小林的賬户餘額從 100 萬修改成了 200 萬;
- 事務 B 讀取數據(創建 Read View),小林的賬户餘額為 100 萬;
- 事務 A 提交事務;
- 事務 B 讀取數據(創建 Read View),小林的賬户餘額為 200 萬;
那具體怎麼做到的呢?我們重點看事務 B 每次讀取數據時創建的 Read View。前兩次 事務 B 讀取數據時創建的 Read View 如下圖:
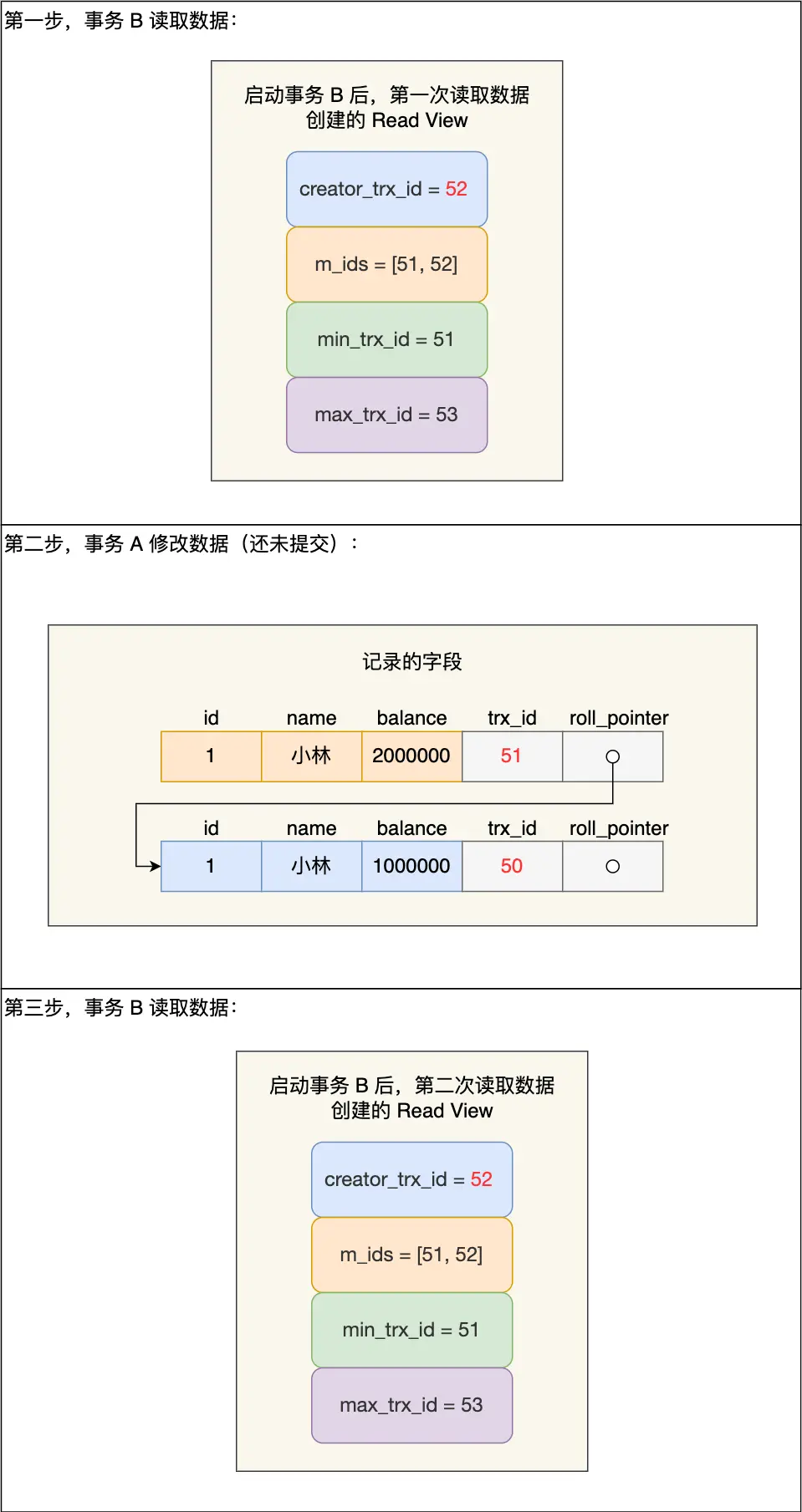
我們來分析下為什麼事務 B 第二次讀數據時,讀不到事務 A (還未提交事務)修改的數據?
事務 B 在找到小林這條記錄時,會看這條記錄的 trx\_id 是 51,在事務 B 的 Read View 的 min\_trx\_id 和 max\_trx\_id 之間,接下來需要判斷 trx\_id 值是否在 m\_ids 範圍內,判斷的結果是在的,那麼説明這條記錄是被還未提交的事務修改的,這時事務 B 並不會讀取這個版本的記錄。而是,沿着 undo log 鏈條往下找舊版本的記錄,直到找到 trx\_id 「小於」事務 B 的 Read View 中的 min\_trx\_id 值的第一條記錄,所以事務 B 能讀取到的是 trx\_id 為 50 的記錄,也就是小林餘額是 100 萬的這條記錄。
我們來分析下為什麼事務 A 提交後,事務 B 就可以讀到事務 A 修改的數據?
在事務 A 提交後,由於隔離級別是「讀提交」,所以事務 B 在每次讀數據的時候,會重新創建 Read View,此時事務 B 第三次讀取數據時創建的 Read View 如下:
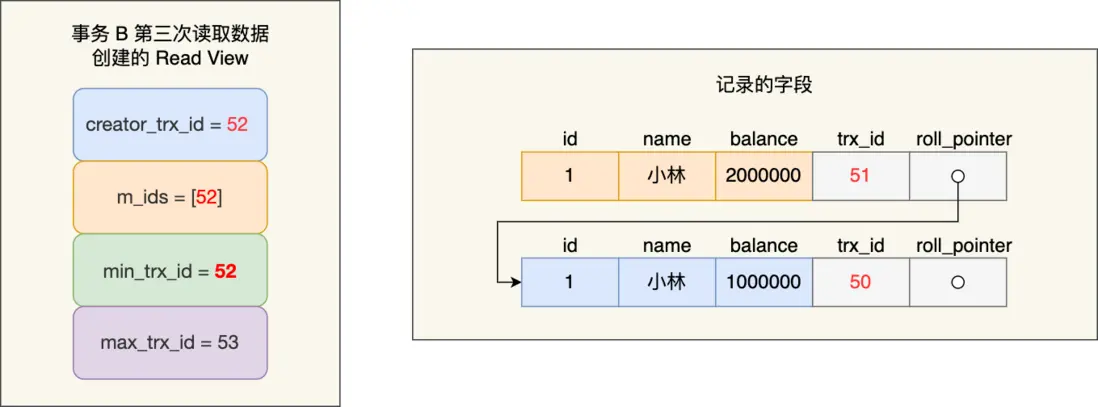
事務 B 在找到小林這條記錄時,會發現這條記錄的 trx\_id 是 51,比事務 B 的 Read View 中的 min\_trx\_id 值(52)還小,這意味着修改這條記錄的事務早就在創建 Read View 前提交過了,所以該版本的記錄對事務 B 是可見的。
正是因為在讀提交隔離級別下,事務每次讀數據時都重新創建 Read View,那麼在事務期間的多次讀取同一條數據,前後兩次讀的數據可能會出現不一致,因為可能這期間另外一個事務修改了該記錄,並提交了事務。
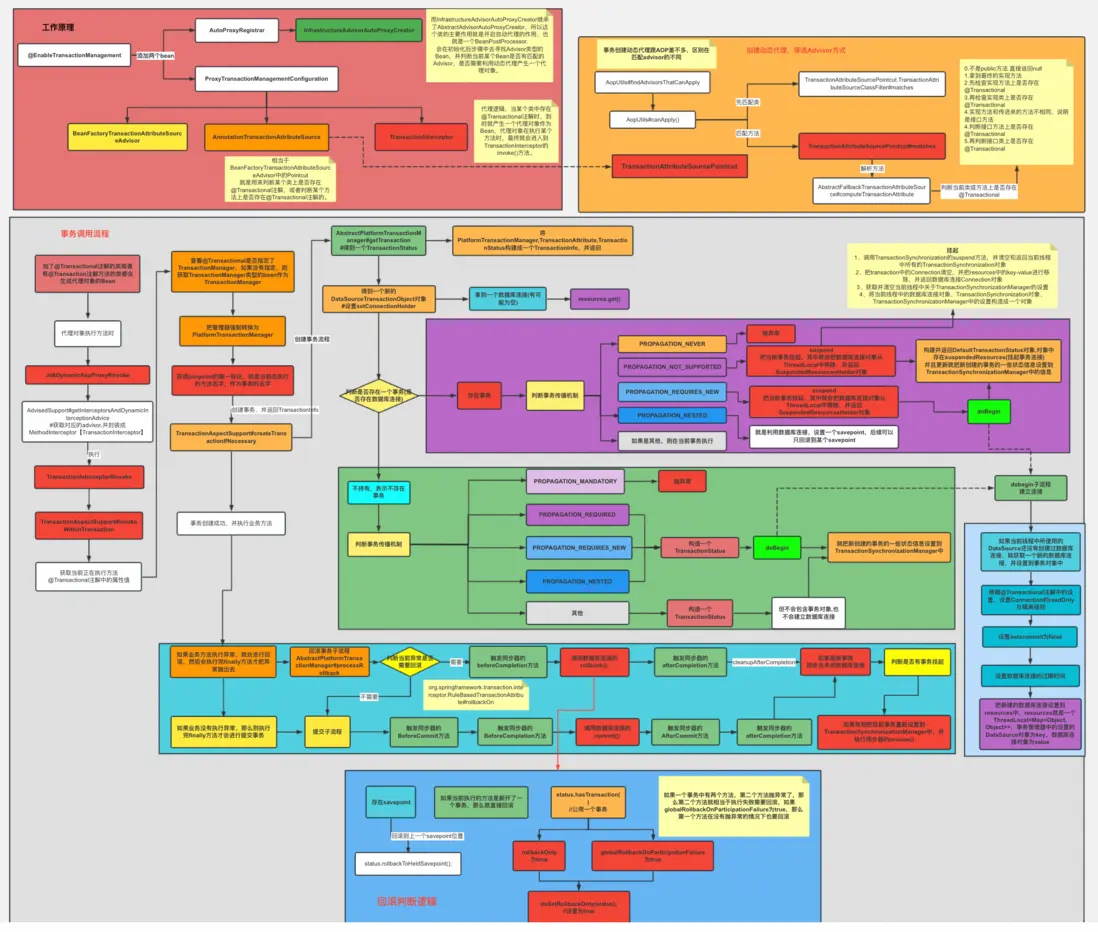
事務的傳播機制
之前看過,事務隔離級別描述的是縱向事務併發調用時的行為模式,而事務傳播機制描述的是橫向事務傳遞時的行為模式。如圖:
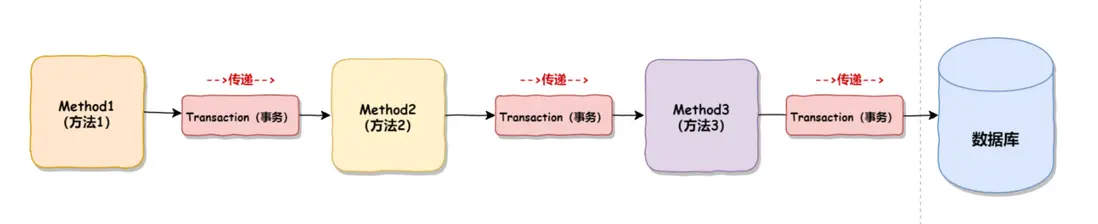
為什麼會有事務傳播機制?
spring 對事務的控制,是使用 aop 切面實現的,我們不用關心事務的開始,提交 ,回滾,只需要在方法上加 @Transactional 註解,這時候就有問題了。
場景一: methodA方法調用了 methodB 方法,但兩個方法都有事務,這個時候如果 methodB 方法異常,是讓 methodB 方法提交,還是兩個一起回滾?
場景二:methodA方法調用了 methodB 方法,但是隻有 methodA 方法加了事務,是否把 methodB 也加入 methodA 的事務,如果 methodB 異常,是否回滾 methodA。場景三:methodA方法調用了 methodB 方法,兩者都有事務,methodB 已經正常執行完,但 methodA異常,是否需要回滾 serviceB 的數據?
事務傳播機制原理
原理方面,簡單來説: Spring 事務傳播行為是通過事務管理器來實現的。Spring 使用 AOP 代理封裝了原始的方法調用,以此來管理事務的邊界和行為。當方法被調用時,AOP 建立的攔截器會根據指定的傳播屬性來確定如何開啓或者參與事務。
例如,如果傳播屬性是 REQUIRES_NEW,Spring 事務管理器會先暫停當前的事務,然後創建一個新的事務。事務的實際處理是通過底層的事務管理器,如 JDBC DataSourceTransactionManager 或 JPA JpaTransactionManager 來完成的。這些事務管理器與具體的持久化技術相集成,並負責實際的事務資源(如數據庫連接)的獲取、事務的提交或回滾。
事務的傳播特性給予開發者在設計應用時更大的靈活性,使得可以根據不同的業務邏輯選擇最合適的事務管理策略。要實現這些事務傳播特性,Spring 通常需要與底層數據庫或JTA(Java Transaction API)事務管理器配合使用,以確保事務的正確傳播和管理。
事務原理分析
通過註解切面,結合上面事務傳播機制如何去管理控制事務的提交與回滾;
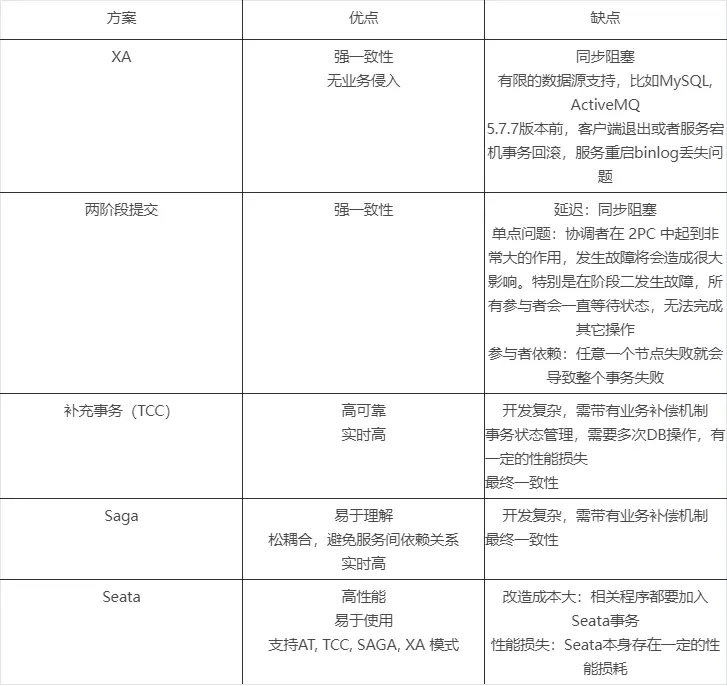
多數據源事務處理機制
業務場景往往可能會涉及到多數據源數據一致性問題,往往可能會涉及到多數據源的事務處理,業界也有很多方案,各有優缺點;