

推理型大語言模型現在確實火了。這類模型的特點是會先對問題做充分思考,然後再給出答案,而不是直接回復。
雖然早期訓練推理型 LLM 的方法多半被各家公司當作核心機密,但最近的DeepSeek-R1、DeepSeekMath、Kimi-k1.5 和 DAPO 這些項目都公開了相關流程。
這些方法讓 LLM 在推理過程中生成更長的思維鏈(Chain-of-Thought,CoT)輸出,推理效果因此得到提升。同時它們還引入了改進的強化學習算法,比如 GRPO 和 DAPO,這些算法是對 OpenAI 最初 PPO 方法的高效升級。

這篇文章會先介紹 GRPO(Group Relative Policy Optimization,組相對策略優化)的基本概念,這是目前訓練推理型 LLM 最常用的強化學習算法之一。然後我們會動手寫代碼訓練一個推理 LLM,在實踐中理解整個流程。
RLHF 與 PPO 的簡單回顧
想理解 GRPO,我們得先回到最初用來對齊 LLM 的強化學習算法。
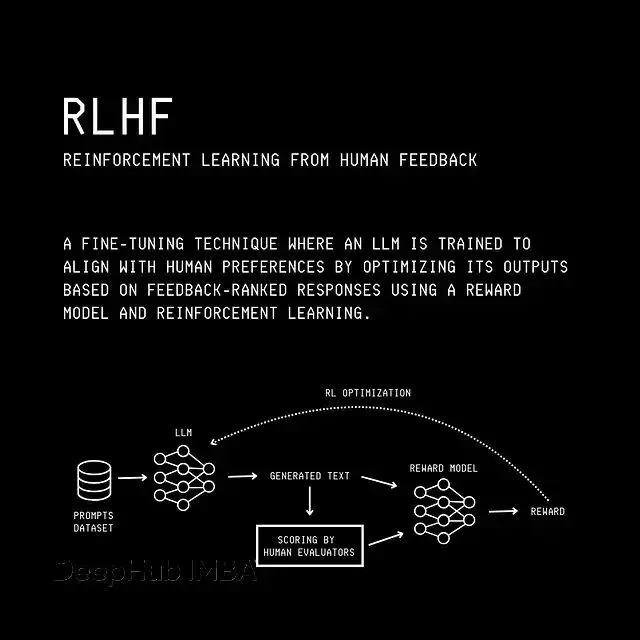
這個算法叫 Proximal Policy Optimization(PPO,近端策略優化),用它將 LLM 對齊到人類偏好的過程叫做 Reinforcement Learning From Human Feedback(RLHF,基於人類反饋的強化學習)。
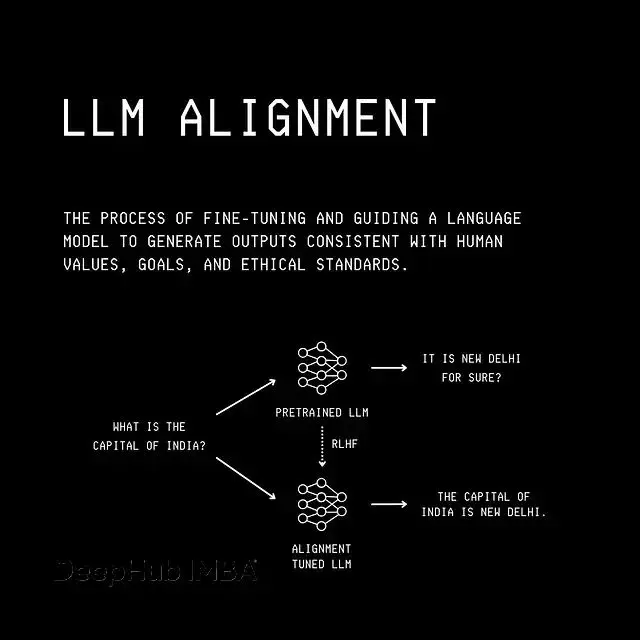
LLM 對齊與 RLHF 可視化
RLHF 主要包含三個步驟:
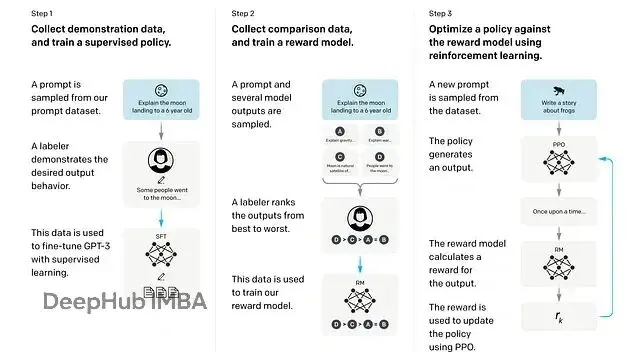
步驟 1:訓練監督微調策略
從預訓練的 LLM 開始,在包含提示與人工編寫回答的數據集上做微調。這樣得到的模型在 RL 術語中叫"監督策略",它能針對給定提示生成更符合人類偏好的回答。
步驟 2:訓練獎勵模型
為每個提示收集多個模型輸出,讓人工標註者對這些輸出排序,判斷哪個更好。然後用這些數據訓練一個"獎勵模型",它會對給定輸出返回一個標量分數作為人類偏好的代理。
步驟 3:用獎勵模型做強化學習
從步驟 1 的監督策略複製一份作為"訓練策略",同時保留一份凍結副本叫"參考策略"。給訓練策略輸入提示,用獎勵模型對輸出打分,然後用 PPO 基於這個獎勵繼續微調訓練策略。
在 LLM 的強化學習中,"狀態"指模型到某個時刻已生成的所有 token(也就是"上下文"),"動作"是下一個要預測的 token。
PPO 訓練 LLM 時會用一個"價值模型"(通常從獎勵模型初始化)來估計從給定狀態出發的未來總期望獎勵,叫做"Value"。接着用這個 Value 計算"優勢"(Advantage,使用 GAE),它衡量在某狀態下采取某動作相對於訓練策略期望行為的好壞程度。
PPO 更新訓練策略時就用到這個 Advantage。同時價值模型也會在訓練過程中不斷更新,以便在每個訓練步提供更好的未來總期望獎勵估計。

PPO 可視化,其中 Q 為查詢,O 為訓練策略的輸出,KL 為訓練策略模型與參考模型之間的 KL 散度,R 為獎勵,V 為價值,A 為優勢。
從 PPO 到 GRPO
GRPO 最初由 DeepSeekMath 論文提出,現在廣泛用於訓練推理型 LLM。
GRPO 和 PPO 的主要區別是:GRPO 不用價值模型來估計 Advantage。
它通過對同一提示下模型生成的一組輸出進行相對打分來計算 Advantage,這也就是 GRPO 中"相對"這詞的來源。
PPO 關注的是某個輸出是否比價值模型的期望更好。
GRPO 關注的是某個輸出是否比同一提示下所有輸出的平均水平更好,這個平均值就作為價值的基線或代理。

GRPO 可視化,其中 Q 為查詢,O(1..G) 為訓練策略的多條輸出,KL 為訓練策略模型與參考模型之間的 KL 散度,R(1..G) 為每條輸出對應的獎勵,A(1..G) 為每條輸出對應的優勢。
用 GRPO 訓練推理 LLM
本文的的所有代碼都可以在 Google Colaboratory 筆記本中完成,運行環境用的是免費層的 T4 GPU。
基礎模型選擇 Qwen2.5–3B-Instruct(指令微調版)。
我們用 Unsloth——一個開源 Python 庫和平台,專門用來優化和加速 LLM 微調。Unsloth 的好處是你只需定義獎勵和訓練配置,它會在內部管理參考策略與訓練策略以及所有 GPU 操作。這大大簡化了 GRPO 訓練流水線。
下面和 Unsloth 相關的函數參數基本都不言自明,如果第一次接觸可以查閲 Unsloth 文檔。
安裝依賴
import os
os.environ["UNSLOTH_VLLM_STANDBY"] = "1" # 獲取額外 30% 的上下文長度
# 安裝依賴
!pip install unsloth_zoo
!pip install — upgrade unsloth vllm==0.9.2 numpy torchvision bitsandbytes xformers
!pip install triton==3.2.0
!pip install transformers==4.55.4
!pip install — no-deps trl==0.22.2加載模型和分詞器,這裏加載 Qwen2.5–3B-Instruct 模型及其分詞器。
from unsloth import FastLanguageModel
import torch
# 上下文長度
max_seq_length = 1024
# 加載模型與分詞器
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen2.5-3B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True, # 啓用 4-bit 量化
fast_inference = True, # 啓用 vLLM 快速推理
max_lora_rank = 8,
gpu_memory_utilization = 0.9,
)用 LoRA 做參數高效微調,由於算力資源有限,我們不會訓練 LLM 的全部參數,而是用 LoRA(低秩適配)來提升訓練效率。
# 使用 LoRA 進行參數高效微調
model = FastLanguageModel.get_peft_model(
model,
r = 8,
# 需要微調的模塊
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 8,
use_gradient_checkpointing = "unsloth",
random_state = 1234,
)用著名的 GSM8K 數據集(小學到初中難度的數學文字題集合)來訓練模型的推理能力。下面對數據集中的題目做格式化處理,以便用於訓練。
import re
from datasets import load_dataset, Dataset
# 系統提示詞
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
# 包裹推理與答案的模板
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
# 從模型輸出中抽取 <answer>...</answer> 內文本的函數
def extract_xml_answer(text):
if "<answer>" not in text or "</answer>" not in text:
return ""
return text.split("<answer>", 1)[-1].split("</answer>", 1)[0].strip()
# 從 GSM8K 標籤中抽取正確答案,標籤形如 '... #### final_answer'
def extract_hash_answer(text):
return text.split("####")[-1].strip() if "####" in text else None
# 加載 GSM8K 數據集並格式化為對話式提示的函數
def get_gsm8k_dataset(split = "train"):
data = load_dataset("openai/gsm8k", "main")[split]
return data.map(
lambda x: {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": x["question"]},
],
"answer": extract_hash_answer(x["answer"]),
}
)
dataset = get_gsm8k_dataset()下面定義用來評估推理模型訓練效果的獎勵函數。
# 獎勵函數:檢查從補全中抽取的答案
# 是否與給定的真實答案完全一致。
# 一致則返回 2.0,否則返回 0.0。
def correctness_reward_func(prompts, completions, answer, **kwargs):
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
# 獎勵函數:檢查抽取的回答是否為整數。
# 若為數字則返回 0.5,否則返回 0.0。
def int_reward_func(completions, **kwargs):
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
# 獎勵函數:強約束的 XML 格式檢查,
# 要求響應必須嚴格匹配以下結構:
# <reasoning>\n...\n</reasoning>\n<answer>\n...\n</answer>\n
# 格式正確返回 0.5,否則返回 0.0。
def strict_format_reward_func(completions, **kwargs):
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
# 獎勵函數:較寬鬆的 XML 格式檢查:
# 響應需包含 <reasoning>...</reasoning> 與 <answer>...</answer>,
# 但允許空格與換行的靈活性。
# 匹配返回 0.5,否則返回 0.0。
def soft_format_reward_func(completions, **kwargs):
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
# 輔助函數:統計併為 XML 標籤計分
def count_xml(text):
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
# 獎勵函數:將 count_xml 應用於補全輸出。
# 根據標籤正確性進行 XML 結構計分,並對尾部冗餘內容施加懲罰。
def xmlcount_reward_func(completions, **kwargs):
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]定義 GRPO 訓練器的參數。
from trl import GRPOConfig, GRPOTrainer
# 訓練參數
training_args = GRPOConfig(
use_vllm = True, # 使用 vLLM 進行快速推理
learning_rate = 5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type = "cosine",
optim = "adamw_8bit",
logging_steps = 1,
per_device_train_batch_size = 4,
gradient_accumulation_steps = 1,
num_generations = 4,
max_prompt_length = 256,
max_completion_length = 200,
max_steps = 250,
save_steps = 250,
max_grad_norm = 0.1,
report_to = "none",
output_dir = "outputs",
)
# GRPO 訓練器
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs = [
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func,
],
args = training_args,
train_dataset = dataset,
)用下面的命令啓動訓練。
# 開始訓練
trainer.train()強化學習模型工作原理是探索解空間,所以訓練通常比較慢。LLM 可能需要數百步才能學會更好的推理,這意味着你需要等幾個小時才能得到不錯的結果。
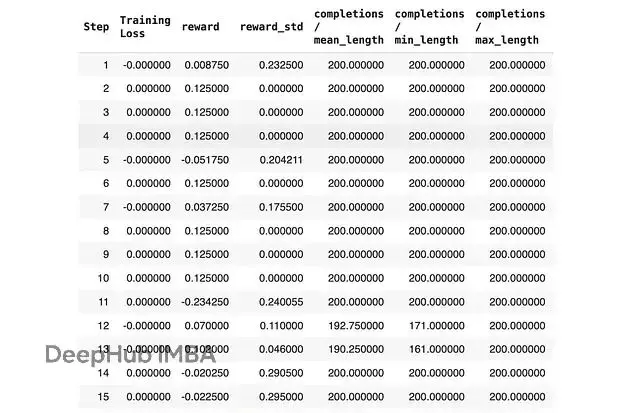
上圖為部分訓練日誌
保存模型有很多方式,我們主要關心的是保存 LoRA 適配器。
# 保存 LoRA 適配器
model.save_lora("grpo_saved_lora")最後對比一下訓練前後模型的輸出。
from vllm import SamplingParams
# 訓練前的模型推理
query = "How many r's are in strawberry?"
text = tokenizer.apply_chat_template([
{"role" : "user", "content" : query},
], tokenize = False, add_generation_prompt = True)
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
[text],
sampling_params = sampling_params,
lora_request = None,
)[0].outputs[0].text
print(output)訓練前模型的輸出:
There are 2 r's in the word "strawberry."接下來試試經過 GRPO 訓練的模型:
# 訓練後的模型推理
text = tokenizer.apply_chat_template([
{"role" : "system", "content" : SYSTEM_PROMPT},
{"role" : "user", "content" : query},
], tokenize = False, add_generation_prompt = True)
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
text,
sampling_params = sampling_params,
lora_request = model.load_lora("grpo_saved_lora"),
)[0].outputs[0].text
print(output)訓練後模型的輸出:
<reasoning>
To find out how many times the letter 'r' appears in the word "strawberry", we can go through the word character by character and count each occurrence of 'r'. In "strawberry", the letter 'r' appears 3 times: once in the beginning, once in the middle, and once at the end of the word.
</reasoning>
<answer>
3
</answer>效果相當不錯!可以看到模型現在會在回答問題前先進行推理,並且給出了正確答案。
下面是使用 GRPO 訓練 Qwen 2.5(3B)訓練過程的概覽示意圖:
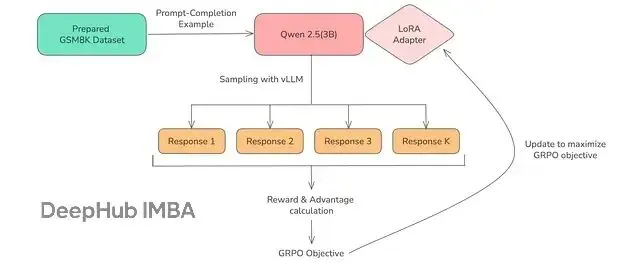
本文的完整代碼:
https://avoid.overfit.cn/post/1506330de8e349eab552ec1000417a27
作者:Dr. Ashish Bamania