

Pandas是我們最常用的數據處理Python庫之一。儘管您可能已經與它共事多年,但可能還有許多您尚未探索的實用方法。我將向您展示一些可能未曾聽説但在數據整理方面非常實用的方法。
我目前日常使用的是pandas 2.2.0,這是本文時可用的最新版本。
import pandas as pd
import numpy as np
print(pd.__version__)
1、agg
你可能已經熟悉使用pandas進行聚合操作,比如使用sum或min等方法。可能也已經結合groupby使用過這些方法。agg方法可以在DataFrame上執行一個或多個聚合操作。
通過將字典傳遞給agg方法,指示要為DataFrame的每一列計算哪些聚合操作(sum、mean、max等)。字典的鍵表示我們要對其執行聚合操作的列,而值表示我們要執行的操作。
data = {
"A": [1, 2, 3, 4],
"B": [5, 6, 7, 8],
"C": [9, 10, 11, 12],
}
df = pd.DataFrame(data)
df.agg({"A": "sum", "B": "mean", "C": "max"})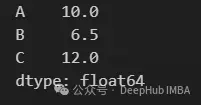
agg並不僅限於為每列傳遞單個操作。在下一段代碼中可以計算列A總和和平均值
df.agg({"A": ["sum", "mean"], "B": "mean", "C": "max"})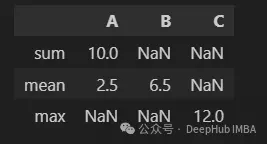
在生成的DataFrame中,可以觀察到一些NaN值,這些值對應於字典中沒有請求的列和操作的組合。
下面我們添加一個分組列。要計算每個兩個組內所有三列的平均值和總和。
data = {
"group": [1, 1, 2, 2],
"A": [1, 2, 3, 4],
"B": [5, 6, 7, 8],
"C": [9, 10, 11, 12],
}
df = pd.DataFrame(data)
df.groupby("group").agg(["mean", "sum"])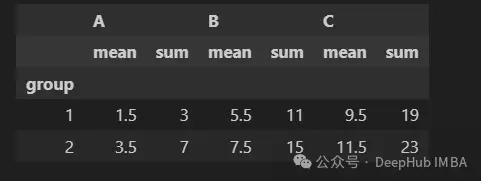
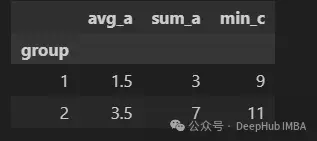
最後,就是我們可以將最終生成的列重新命名:
df.groupby("group").agg(
avg_a=("A", "mean"),
sum_a=("A", "sum"),
min_c=("C", "min"),
)
2、assign
assign方法用於創建帶有附加列的新DataFrame,並根據現有列或操作分配值。
df = pd.DataFrame({"Value": [10, 15, 20, 25, 30, 35]})
df.assign(value_cat=np.where(df["Value"] > 20, "high", "low"))
這種方法在鏈式操作中最有用,因為我們不一定對中間步驟感興趣,並且並不想將中間結果添加到原始DataFrame中。
df.assign(value_cat=np.where(df["Value"] > 20, "high", "low")).groupby(
"value_cat"
).mean()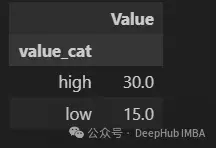
3、combine_first
combine_first方法用於組合兩個Series(或DataFrame中的列),從第一個Series中選擇值,並用第二個Series中的相應值填充任何缺失的值。
如果你對SQL熟悉的話,那麼pandas的combine_first方法類似於SQL中的COALESCE函數。
s1 = pd.Series([1, 2, np.nan, 4, np.nan, 6])
s2 = pd.Series([10, np.nan, 30, 40, np.nan, 60])
s1.combine_first(s2)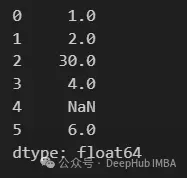
可以看到s1中缺失的值被s2的值填充。如果s2也是缺失值,則結果為缺失值。這種方法也可以用於DataFrame的列。
如果我們希望使用2列以上的列來更新缺失的值,我們也可以鏈接combine_firstmethods。
4、cumsum / cummin / cummax / cumprod
cumsum、cummin、cummax和cumprod方法用於計算Series或DataFrame中元素的累積和、最小值、最大值和乘積。
data = {
'A': [3, 1, 2, 0.5, 5, 10],
}
df = pd.DataFrame(data)
df["cumsum"] = df["A"].cumsum()
df["cummin"] = df["A"].cummin()
df["cummax"] = df["A"].cummax()
df["cumprod"] = df["A"].cumprod()
df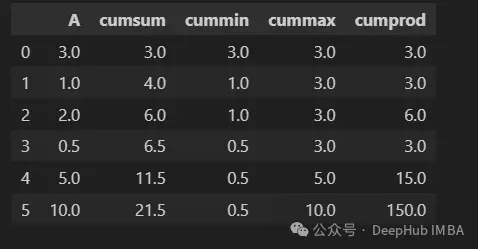
5、cut / qcut
cut函數將數據劃分為相同寬度的桶。這意味着每個桶都有相同的範圍,但是每個桶中的數據點數量可能不同。
df = pd.DataFrame(
{
"name": ["Alice", "Bob", "Charlie", "Dylan", "Eve", "Frank"],
"years_of_exp": [10, 2, 0, 5, 6, 8],
}
)
pd.cut(df["years_of_exp"], bins=3)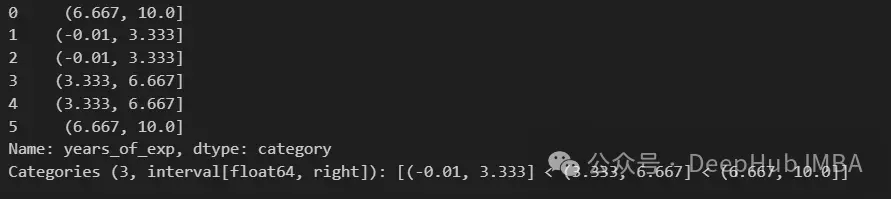
cut函數將所有觀測值分類到三個長度相等(長度約為3.33)的桶中。
這裏需要強調下區間符號。
[0,10]:區間兩邊都閉合,即同時包含0和10
(0,10):間隔兩邊都不閉合,即不包括0和10
[0,10):區間左側閉合,表示包含0,但不包含10。我們可以定義桶的區間
exp_bins = [0, 2, 5, 10]
pd.cut(df["years_of_exp"], bins=exp_bins)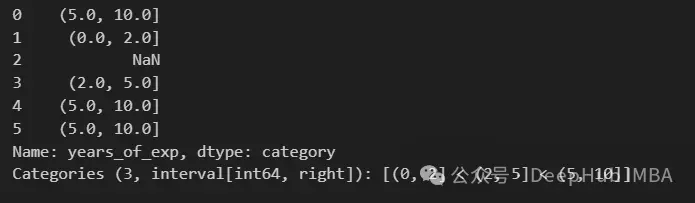
在輸出中看到一個NaN值。這是因為最低值不包括在範圍內。我們可以通過將include_lowest設置為True來解決這個問題。
還可以為桶分配自定義標籤名稱,這在特徵工程時特別有用
exp_labels = ["Junior level", "Mid level", "Senior level"]
pd.cut(df["years_of_exp"], bins=exp_bins, include_lowest=True, labels=exp_labels)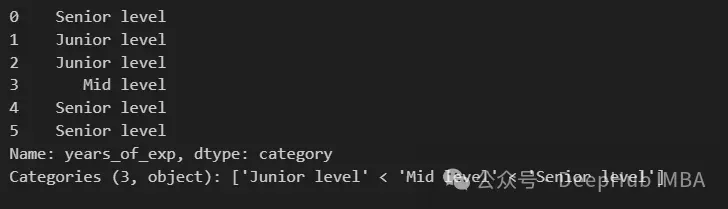
qcut函數根據分位數將數據劃分為桶。這確保了每個桶具有大致相同數量的數據點。
pd.qcut(df["years_of_exp"], q=3)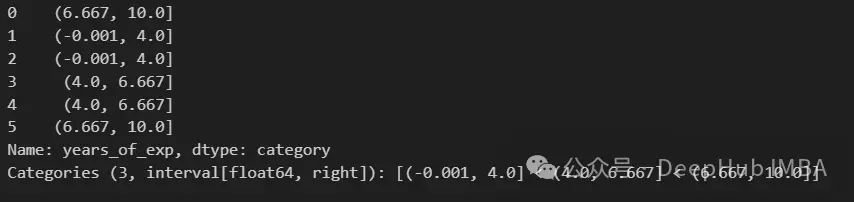
使用qcut每個桶中都有2個值。cut根據區間劃分數據,而qcut則根據分位數劃分數據。
6、duplicate / drop_duplicate
duplicate方法返回一個boolean Series,指示DataFrame中的每個元素是否重複(True)或不重複(False)。
data = {"A": [1, 2, 2, 3, 4, 4], "B": ["x", "y", "y", "z", "w", "w"]}
df = pd.DataFrame(data)
df.duplicated()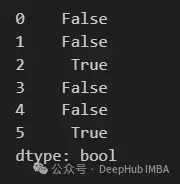
duplicate的默認設置 keep="first" ,保留第一個匹配的值,並將所有後續的觀測值標記為duplicate.
也可以使用 keep="last" 保留最後的值,還可以使用keep=False 將所有的重複值標記為True
df.duplicated(keep=False)
最後使用drop_duplduplicate方法直接刪除重複項。drop_duplduplicate方法也可以設置keep參數
df.drop_duplicates()7、isin
isin方法用於篩選Series和dataframe,該方法返回一個布爾Series,顯示列中的每個值是否在指定值範圍內。
data = {
"Name": ["Alice", "Bob", "Charlie", "David", "Eve"],
"Value": [1, 1, 1, 2, 2],
}
df = pd.DataFrame(data)
selected_names = ["Alice", "David", "Eve"]
df[df["Name"].isin(selected_names)]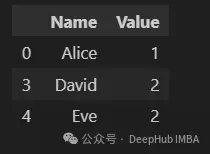
8、merge_ordered
merge_ordered函數用來合併兩個dataframe。當我們有兩個具有順序的dataframe,並且希望在保持索引的順序的同時合併它們時(比如説時間序列),這個函數特別有用。
df1 = pd.DataFrame(
{
"date": pd.date_range(start="2022-01-01", periods=5)[::-1],
"value_df1": [10, 15, 20, 25, 30],
}
)
df2 = pd.DataFrame(
{
"date": pd.date_range(start="2022-01-03", periods=4)[::-1],
"value_df2": [100, 150, 250, 300],
}
)
pd.merge_ordered(df1, df2, on="date", fill_method="ffill")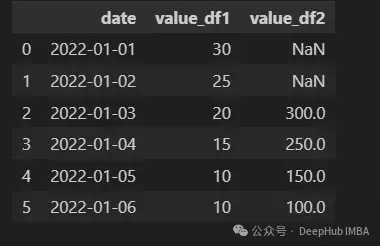
merge_ordered中連接的默認是outer join,所以fill_method需要設置一種方法來填充缺失值。
9、pct_change
pct_change用於計算Series或DataFrame中當前元素和先前元素之間的百分比變化。它用於分析價值隨時間變化的百分比,特別是在金融時間序列數據中,例如股票價格。
data = {
"date": pd.date_range(start="2022-01-01", end="2022-01-05"),
"price": [100, 105, 98, 110, 120],
}
df = pd.DataFrame(data).set_index("date")
df["price"].pct_change()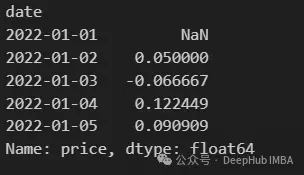
10、select_dtypes
select_dtypes用於根據數據類型篩選DataFrame中的列。我們可以使用它來選擇具有特定數據類型的列,例如數字類型(int64、float64)、對象類型(str、object)、布爾類型或日期時間類型等。
我們選擇整數列和浮點列,即數字列。
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 22],
"salary": [50000.0, 60000.0, 45000.0],
"date_joined": ["2022-01-01", "2022-02-15", "2021-12-10"],
"remote_worker": [True, False, True]
}
df = pd.DataFrame(data)
df.select_dtypes(include=["int64", "float64"])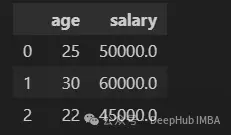
或者可以直接這樣寫
df.select_dtypes(include="number")select_dtypes,還可以指定要排除哪些數據類型
df.select_dtypes(exclude="object")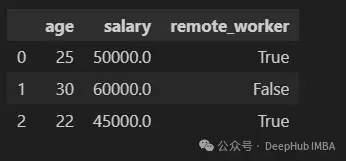
總結
pandas是一個非常龐大的庫,我們最常用的只是其中的一些方法,可能還有許多尚未探索的實用方法。希望本文介紹的10各高級技巧可以幫你更有效地處理各種數據,更靈活地滿足各種數據處理需求。
https://avoid.overfit.cn/post/2baf150e08a1418584b03f804de21b6d