

AI能否像人類一樣從錯誤中學習?反思型Agent系統不僅能生成回答,還會主動審視自己的輸出,找出問題並持續改進。
反思策略本質上就是讓LLM對自己的行為進行自我批評。有時反思器還會調用外部工具或檢索系統來提升批評的準確性。這樣一來系統輸出的就不再是一次性的回答,而是經過多輪生成-審閲循環優化後的結果。
目前主流的反思系統主要分為三類:
基礎Reflection Agent比較輕量,就是簡單的生成器加反思器循環。生成器負責起草、反思器負責批評,然後生成器根據反饋進行修訂。這種方式在很多編輯類任務中效果不錯。
Reflexion Agent更加結構化,會在可追蹤的日誌中記錄歷史行為、假設和反思內容。特別適合那些需要從多次失敗中汲取經驗的問題求解場景。
語言Agent樹搜索(LATS)採用搜索策略探索多條行動路徑,對結果進行反思,然後裁剪或保留有前景的分支。在規劃和多步推理任務中表現最佳。
本文重點討論前兩種:Reflection和Reflexion,並用LangChain與LangGraph來實現完整的工作流程。
基礎Reflection Agent的工作原理
Reflection Agent的核心在於兩個角色之間的互動:
生成器負責起草初始回答,反思器則審查這個草稿,指出缺陷並提出改進建議。
這種循環會進行幾輪,每一輪都讓輸出變得更加精煉和可靠。AI實際上在實時學習自己的錯誤,就像作家根據編輯意見反覆修改稿件一樣。
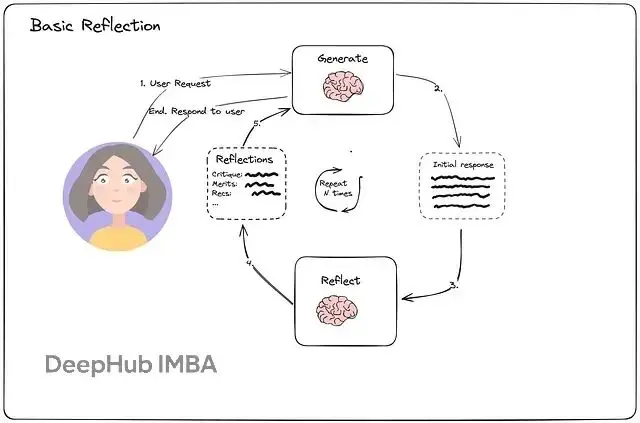
接下來用LangGraph構建一個LinkedIn帖子生成的Reflection Agent。LangGraph專門用於創建自我改進的AI系統,能夠模擬人類的反思思維過程——Agent不會止步於第一稿,而是持續打磨直到內容足夠優秀。
這個演示會展示如何設置生成器和反思器角色,使用LangChain進行結構化提示,並通過LangGraph將所有組件編織成一個迭代反饋循環。
動手構建Reflection Agent
先從LinkedIn內容創建Agent入手,實現基礎的Reflection模式。流程很直接:Agent起草帖子,獨立的"反思器"對其進行評析,然後系統根據反饋修訂內容。
環境配置
我們這裏按需逐步引入,保持學習流程的清晰度。首先用
.env文件設置API集成的環境變量:
ANTHROPIC_API_KEY="your-anthropic-api-key"
# LANGCHAIN_API_KEY="your-langchain-api-key" # optional
# LANGCHAIN_TRACING_V2=True # optional
# LANGCHAIN_PROJECT="multi-agent-swarm" # optional然後將這些加載到notebook中:
from langchain_anthropic import ChatAnthropic
from dotenv import load_dotenv
load_dotenv()
load_dotenv(dotenv_path="../.env", override=True) # mention the .env path
# Initialize Anthropic model
llm = ChatAnthropic(
model="claude-3-7-sonnet-latest", # Claude model ID
temperature=0,
# max_tokens=1024
)這裏選擇Anthropic的claude-3–7-sonnet-latest作為對話模型。當然也可以換成其他LLM,LangChain支持相當廣泛的集成。
生成器組件
配置好LLM後,創建第一個Agent組件:LinkedIn帖子生成器。這個Agent會起草帖子,後續通過自我審查來優化。
先為帖子創建生成提示:
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
post_creation_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert LinkedIn content creator tasked with crafting compelling, professional, and high-performing LinkedIn posts. "
"Create the most effective LinkedIn post possible based on the user's requirements. "
"If the user provides feedback or suggestions, respond with an improved version that incorporates their input while enhancing overall quality and engagement.",
),
MessagesPlaceholder(variable_name="messages"),
]
)ChatPromptTemplate用來組織提示,包含兩個部分:
系統消息定義助理的角色。這裏助理扮演專業LinkedIn內容策略師,負責生成高質量帖子,收到反饋時能夠修訂以提升可讀性、互動性和整體效果。
MessagesPlaceholder作為用户輸入的動態槽位。運行時會被用户請求填充,確保生成的帖子相關且定製化。
接下來用管道操作符(
|)將提示與LLM連接,形成完整的處理鏈:
linkedin_post_generator=post_creation_prompt|llm管道操作符充當橋樑:將
post_creation_prompt的輸出直接傳遞給LLM,使其能根據用户指令生成結構化帖子。
用簡單示例測試生成器:
# Example LinkedIn post creation session
generated_post = ""
post_request = HumanMessage(
content="Create a LinkedIn post on AI tools for developers under 200 words."
)
print("=== INITIAL LINKEDIN POST ===")
for chunk in linkedin_post_generator.stream({"messages": [post_request]}):
print(chunk.content, end="")
generated_post += chunk.content
print("\n" + "="*60 + "\n")預期響應:
=== INITIAL LINKEDIN POST ===
Here's a compelling LinkedIn post for developers about AI tools:
🤖 Fellow developers, let's talk about AI tools that are actually worth your time!
After testing dozens of AI tools, here are 5 game-changers that have transformed my development workflow:
1. GitHub Copilot
Real-time code suggestions that feel like pair programming with an AI. Seriously cuts down on boilerplate code.
2. ChatGPT API
Not just for chat - it's incredible for debugging, code optimization, and even architecture discussions. Pro tip: Use it to explain complex code blocks.
3. Amazon CodeWhisperer
Like Copilot's cousin, but with deeper AWS integration. Perfect for cloud-native development.
4. Tabnine
Context-aware code completions that learn from your coding style. Works across 30+ languages!
5. DeepCode
Catches bugs before they happen with AI-powered code reviews. Has saved my team countless hours.
💡 Pro Tip: These tools should augment, not replace, your development skills. Use them to enhance productivity, not as a crutch.
What AI tools are you using in your dev workflow? Drop them in the comments! 👇
[#SoftwareDevelopment](#SoftwareDevelopment) [#AI](#AI) [#CodingTools](#CodingTools) [#TechCommunity](#TechCommunity) [#Programming](#Programming)
Thoughts? Would you like any adjustments to make it more engaging?
============================================================內容生成器已經能獨立工作,下一步是添加反思能力來評估和改進內容。
反思組件
有了LinkedIn帖子生成器,現在創建一個"批評Agent",本質上就是社交媒體策略師。這個Agent會從多個維度分析生成的帖子:互動潛力、品牌一致性、語調和整體優化效果。
# SOCIAL MEDIA STRATEGIST REFLECTION
social_media_critique_prompt=ChatPromptTemplate.from_messages([
(
"system",
"""You are a LinkedIn content strategist and thought leadership expert. Analyze the given LinkedIn post and provide a comprehensive critique focusing on:
**Content Quality & Professionalism:**
- Overall quality, tone clarity, and LinkedIn best practices alignment
- Structure, readability, and professional credibility building
- Industry relevance and audience targeting
**Engagement & Algorithm Optimization:**
- Hook effectiveness and storytelling quality
- Engagement potential (likes, comments, shares)
- LinkedIn algorithm optimization factors
- Word count and formatting effectiveness
**Technical Elements:**
- Hashtag relevance, reach, and strategic placement
- Call-to-action strength and clarity
- Use of formatting (line breaks, bullet points, mentions)
Provide specific, actionable feedback that includes:
- Key strengths and improvement areas
- Concrete suggestions for enhancing engagement and professionalism
- Practical recommendations for the next revision
Keep your critique constructive and focused on measurable improvements, prioritizing actionable insights that will guide the post's revision and lead to tangible content enhancements."""
),
MessagesPlaceholder(variable_name="messages")
])
social_media_critic=social_media_critique_prompt|llm看看策略師對生成帖子的評估:
print("=== SOCIAL MEDIA STRATEGIST FEEDBACK ===")
feedback_result = ""
for chunk in social_media_critic.stream({"messages": [post_request, HumanMessage(content=generated_post)]}):
print(chunk.content, end="")
feedback_result += chunk.content
print("\n" + "="*60 + "\n")預期響應:
=== SOCIAL MEDIA STRATEGIST FEEDBACK ===
Here's a comprehensive critique of your LinkedIn post:
**Content Quality & Professionalism:**
Strengths:
- Well-structured with clear, valuable information
- Professional tone that balances expertise with accessibility
- Excellent use of practical examples and specific tools
- Good industry relevance for developer audience
Areas for Improvement:
- Could add brief specific benefits/use cases for each tool
- Consider including one personal experience/result
**Engagement & Algorithm Optimization:**
Strengths:
- Strong hook with "Fellow developers"
- Good length (within optimal 1,300 character range)
- Effective use of emojis
- Strong call-to-action in comments
Optimization Suggestions:
- Consider starting with a compelling statistic or personal result
- Add numbers to benefits (e.g., "reduced coding time by 40%")
- Break up longer paragraphs further for better readability
**Technical Elements:**
Strengths:
- Good hashtag selection
- Clear formatting with numbered lists
- Effective use of emojis as visual breaks
Recommendations:
- Add 1-2 relevant @mentions of tool companies
- Consider more specific hashtags (e.g., [#AIforDevelopers](#AIforDevelopers))
- Add line breaks between sections for better scanning
**Specific Improvement Suggestions:**
1. Enhanced Hook:
"🚀 These 5 AI tools helped me cut coding time by 40% last month! Here's my real-world review after 100+ hours of testing..."
2. Add Credibility:
Brief one-liner about your experience/role before the list
3. Tool Descriptions:
Add one specific metric/result for each tool
Example: "GitHub Copilot: Cut my boilerplate coding time by 60%. Perfect for repetitive tasks."
4. Hashtags:
Add: [#DevTools](#DevTools) [#AIinTech](#AIinTech) [#DeveloperLife](#DeveloperLife)
Overall, it's a strong post that could be enhanced with more specific results and personal experiences to boost engagement and credibility.
============================================================策略師的反饋提供了具體可操作的洞察。這正是反思模式的強大之處:不只是生成內容,而是系統性地評估並識別改進機會。
迭代改進
現在有了生成器和批評者,可以實現基礎反思循環:將批評反饋送回生成器進行改進。
print("=== REFINED LINKEDIN POST ===")
for chunk in linkedin_post_generator.stream(
{"messages": [post_request, AIMessage(content=generated_post), HumanMessage(content=feedback_result)]}
):
print(chunk.content, end="")
print("\n" + "="*60 + "\n")預期響應:
=== REFINED LINKEDIN POST ===
Thank you for the detailed feedback! Here's an improved version incorporating your suggestions:
🚀 These 5 AI tools helped me cut coding time by 40% last month! Here's my real-world review after 100+ hours of testing...
As a senior full-stack developer leading a team of 12, I've vetted countless AI tools. These are the ones actually delivering ROI:
1. GitHub Copilot
Cut boilerplate coding time by 60%. Saved our team 15+ hours last sprint on repetitive tasks.
@GitHub
2. ChatGPT API
Reduced debugging time by 35%. We use it to analyze 100+ lines of complex code in seconds.
@OpenAI
3. Amazon CodeWhisperer
30% faster AWS infrastructure deployment. Game-changer for cloud architecture.
@AWSCloud
4. Tabnine
Increased code completion accuracy by 45%. Learning from our codebase across 5 different projects.
@Tabnine
5. DeepCode
Caught 23 critical bugs last month before production. Reduced QA cycles by 25%.
@DeepCode
💡 Real Talk: These tools supercharged our productivity, but they're not magic. They work best when combined with solid development practices and code review processes.
⚡️ Personal Win: Implemented these tools across our team and saw sprint velocity increase by 28% in just two months.
What's your experience with AI dev tools? Share your metrics below! 👇
[#AIforDevelopers](#AIforDevelopers) [#DevTools](#DevTools) [#SoftwareDevelopment](#SoftwareDevelopment) [#CodingTools](#CodingTools) [#DeveloperLife](#DeveloperLife) [#TechInnovation](#TechInnovation)這就是核心反思模式的流程:
original request → initial post → critique → improved post消息序列確保上下文得以保留,同時允許生成器迭代地接受反饋並進行完善。
上面我們用的是手動的方式實現了功能,不過手動方式雖然適合簡單內容任務,但面對複雜工作流會很快變得繁瑣。這時就需要LangGraph來提供結構化框架,高效編排多個Agent。
用LangGraph編排工作流
LangGraph讓構建複雜Agent工作流變得可能:
狀態管理:跨多步跟蹤上下文
條件邏輯:決定是否繼續或終止循環
自動編排:Agent間的無縫通信
定義
ContentState來組織工作流。結合
Annotated和
add_messages,確保消息在整個過程中正確累積。
from typing import Annotated, List, Sequence
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import InMemorySaver
from typing_extensions import TypedDict
class ContentState(TypedDict):
messages: Annotated[list, add_messages]接下來創建代表生成器和批評者的工作流節點:
async def post_creation_node(state: ContentState) -> ContentState:
"""Generate or improve LinkedIn post based on current state."""
return {"messages": [await linkedin_post_generator.ainvoke(state["messages"])]}
async def social_critique_node(state: ContentState) -> ContentState:
"""Provide social media strategy feedback for the LinkedIn post."""
# Transform message types for the strategist
message_role_map = {"ai": HumanMessage, "human": AIMessage}
# Keep the original request and transform subsequent messages
transformed_messages = [state["messages"][0]] + [
message_role_map[msg.type](content=msg.content) for msg in state["messages"][1:]
]
strategy_feedback = await social_media_critic.ainvoke(transformed_messages)
# Return feedback as human input for the post generator
return {"messages": [HumanMessage(content=strategy_feedback.content)]}定義好兩個圖節點後,創建決定工作流繼續還是結束的條件邏輯:
def should_continue_refining(state: ContentState):
"""Determine whether to continue the creation-feedback cycle."""
if len(state["messages"]) > 6:
# End after 3 complete creation-feedback cycles
return END
return "social_critique"現在構建並配置完整工作流:
# Build the workflow graph
content_workflow_builder = StateGraph(ContentState)
content_workflow_builder.add_node("create_post", post_creation_node)
content_workflow_builder.add_node("social_critique", social_critique_node)
# Define workflow edges
content_workflow_builder.add_edge(START, "create_post")
content_workflow_builder.add_conditional_edges("create_post", should_continue_refining)
content_workflow_builder.add_edge("social_critique", "create_post")
# Add conversation memory
content_memory = InMemorySaver()
linkedin_workflow = content_workflow_builder.compile(checkpointer=content_memory)可視化最終工作流:
from IPython.display import Image, display
# Show the agent
display(Image(linkedin_workflow.get_graph().draw_png()))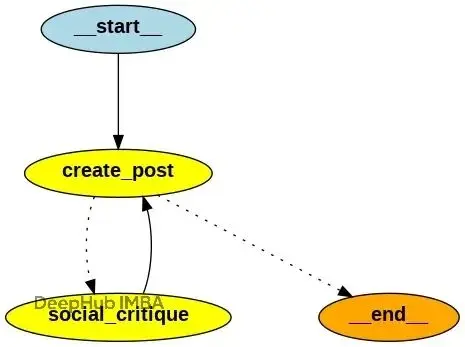
測試運行
最後用簡單示例測試自動化的
linkedin_workflow:
session_config = {"configurable": {"thread_id": "user1"}}
content_brief = HumanMessage(
content="Create a LinkedIn post on AI tools for developers under 180 words."
)
async for workflow_event in linkedin_workflow.astream(
{"messages": [content_brief]},
session_config,
):
print("Workflow Step:", workflow_event)
print("-" * 50)輸出展示了完整的工作流執行過程,從初始生成到策略師反饋再到最終的優化版本。每一步都在持續改進內容質量。
基礎反思工作流在內容改進方面表現不錯,但在需要外部信息的知識密集型任務中存在侷限。這就引出了Reflexion模式。
Reflexion Agent的進化
Shinn等人提出的Reflexion模式在基礎反思上做了擴展:結合自我批評、外部知識整合和結構化輸出解析。
與簡單反思不同,Reflexion允許Agent在利用額外信息的同時實時從錯誤中學習。
典型工作流包括:
初始生成:Agent產生回答,同時給出自我批評和研究查詢
外部研究:根據批評中識別的知識缺口觸發網絡搜索或其他信息檢索
知識整合:將新洞察納入改進的回答中
迭代完善:重複循環直到回答達到期望質量
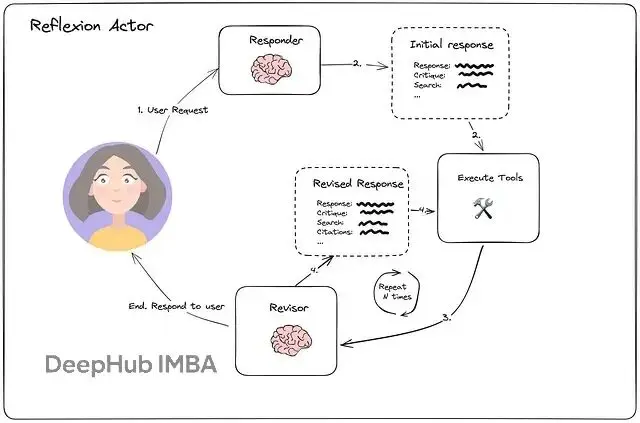
Reflexion Agent由三個相互關聯的角色構成:Actor、Evaluator和Self-Reflection。
Actor執行任務:寫代碼、解決問題或在環境中採取行動。
Evaluator提供內部反饋,評估Actor輸出的質量。
Self-Reflection模塊生成文本反思,捕捉哪裏出錯或如何改進。
這些反思存儲在記憶中:
短期記憶跟蹤當前嘗試的軌跡、長期記憶積累以往反思的經驗,指導未來迭代。
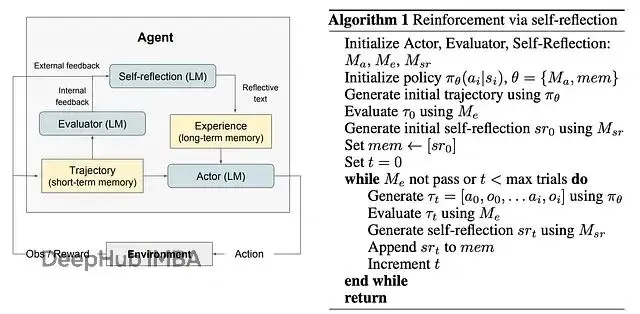
(a) Reflexion示意圖 (b) Reflexion強化算法
過程是迭代的:Actor嘗試,Evaluator評分,Self-Reflection批評,Actor在下次嘗試中利用這些反饋。循環持續到任務成功或達到最大迭代次數。
比如,如果Actor某步失敗,反思可能會記錄:
"陷入了循環;下次嘗試不同策略或工具。"
下一次迭代在這條反思指導下更可能成功。Reflexion能處理多樣化反饋:數值獎勵、錯誤消息或人工提示,都能融入反思過程。
Reflexion的效果相當顯著,在HumanEval等編碼基準上加入Reflexion的GPT-4 Agent達到91%成功率,而沒有反思時僅為80%。在決策模擬(AlfWorld)中,ReAct + Reflexion Agent解決了134個挑戰中的130個,明顯超越了非反思對照組。
這突出了Reflexion的核心能力:讓AI Agent能夠思考自己的行動並保留學到的經驗,從而持續改進,更有效地處理複雜任務。
構建Reflexion Agent
Reflexion Agent的核心是一個Actor:生成初始回答,對其進行批評,然後帶着改進重新執行任務。支撐這個循環的關鍵子組件有:
工具執行:訪問外部知識源
初始響應器:生成首稿並附帶自我反思
修訂器:結合以往反思產出優化結果
構建工具
由於Reflexion需要外部知識,首先定義從網絡獲取信息的工具。這裏用
TavilySearchResults——Tavily搜索API的封裝,讓Agent能進行網絡搜索並收集支撐證據。
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapper
# Initialize search tool
web_search = TavilySearchAPIWrapper()
tavily_tool = TavilySearchResults(api_wrapper=web_search, max_results=5)定義提示模板
接下來定義指導actor行為的提示模板。提示相當於Agent的"角色説明",規定應該做什麼、不該做什麼。Agent被指示:
提供初始解釋、對自己的答案進行反思和批評、生成用於填補知識缺口的搜索查詢
# Agent prompt template
actor_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert technical educator specializing in machine learning and neural networks.
Current time: {time}
1. {primary_instruction}
2. Reflect and critique your answer. Be severe to maximize improvement.
3. Recommend search queries to research information and improve your answer.""",
),
MessagesPlaceholder(variable_name="messages"),
(
"user",
"\n\n<s>Reflect on the user's original question and the"
" actions taken thus far. Respond using the {function_name} function.</reminder>",
),
]
).partial(
time=lambda: datetime.datetime.now().isoformat(),
)強制結構化輸出
在多步工作流中,通常建議為每個子Agent定義結構化輸出模型。為確保一致性,用Pydantic模型定義結構化輸出:
# Pydantic models for structured output
class Reflection(BaseModel):
missing: str = Field(description="Critique of what is missing.")
superfluous: str = Field(description="Critique of what is superfluous")
class GenerateResponse(BaseModel):
"""Generate response. Provide an answer, critique, and then follow up with search queries to improve the answer."""
response: str = Field(description="~250 word detailed answer to the question.")
reflection: Reflection = Field(description="Your reflection on the initial answer.")
research_queries: list[str] = Field(
description="1-3 search queries for researching improvements to address the critique of your current answer."
)用Pydantic的
BaseModel定義兩個數據類:
Reflection捕捉自我批評,要求Agent指出哪些信息缺失和哪些多餘。
GenerateResponse構造最終輸出,確保Agent提供主要回答、包含基於
Reflection類的反思,並提供
research_queries列表。
這種結構化方法保證Agent產出一致且可解析的回答。
添加重試邏輯
結構化解析可能在輸出不匹配schema時失敗。為此添加帶schema反饋的重試邏輯:
# Agent with retry logic
class AdaptiveResponder:
def __init__(self, chain, output_parser):
self.chain = chain
self.output_parser = output_parser
def generate(self, conversation_state: dict):
llm_response = None
for retry_count in range(3):
llm_response = self.chain.invoke(
{"messages": conversation_state["messages"]}, {"tags": [f"attempt:{retry_count}"]}
)
try:
self.output_parser.invoke(llm_response)
return {"messages": llm_response}
except ValidationError as validation_error:
# Fix: Convert schema dict to JSON string
schema_json = json.dumps(self.output_parser.model_json_schema(), indent=2)
conversation_state = conversation_state + [
llm_response,
ToolMessage(
content=f"{repr(validation_error)}\n\nPay close attention to the function schema.\n\n{schema_json}\n\nRespond by fixing all validation errors.",
tool_call_id=llm_response.tool_calls[0]["id"],
),
]
return {"messages": llm_response}這裏有一個關鍵點:當結構化輸出驗證失敗時,將schema和錯誤詳情回傳給LLM進行自我糾正,這樣不會讓程序卡死
綁定數據模型
將
GenerateResponse模型作為工具綁定,這會強制LLM嚴格按照定義的結構輸出。
# Initial answer chain
initial_response_chain = actor_prompt_template.partial(
primary_instruction="Provide a detailed ~250 word explanation suitable for someone with basic programming background.",
function_name=GenerateResponse.__name__,
) | llm.bind_tools(tools=[GenerateResponse])
response_parser = PydanticToolsParser(tools=[GenerateResponse])
initial_responder = AdaptiveResponder(
chain=initial_response_chain, output_parser=response_parser
)調用
initial_response_chain後,會得到包含初始答案、自我批評和生成的搜索查詢的結構化輸出。用簡單查詢測試初始響應器:
example_question = "What is the difference between supervised and unsupervised learning?"
initial = initial_responder.generate(
{"messages": [HumanMessage(content=example_question)]}
)
initial預期響應會展示完整的結構化輸出,包括技術解釋、自我反思和改進查詢。
修訂階段
修訂步驟代表反思循環的最終階段。目的是整合三個關鍵要素:原始草稿、自我批評和研究結果,產生精煉且有證據支撐的回答。
先定義新的指令集,明確指導修訂器:
將批評整合到修訂過程中、添加與研究證據對應的數字引用、在解釋中區分相關性和因果性、包含結構化的"References"部分,只提供乾淨的URL
# Revision instructions
improvement_guidelines = """Revise your previous explanation using the new information.
- You should use the previous critique to add important technical details to your explanation.
- You MUST include numerical citations in your revised answer to ensure it can be verified.
- Add a "References" section to the bottom of your answer (which does not count towards the word limit).
- For the references field, provide a clean list of URLs only (e.g., ["https://example.com", "https://example2.com"])
- You should use the previous critique to remove superfluous information from your answer and make SURE it is not more than 250 words.
- Keep the explanation accessible for someone with basic programming background while being technically accurate.
"""為強制輸出結構需要引入Pydantic schema
ImproveResponse,它類繼承自
GenerateResponse並增加
sources字段,確保每個改進的答案都附帶可驗證的參考來源。
class ImproveResponse(GenerateResponse):
"""Improve your original answer to your question. Provide an answer, reflection,
cite your reflection with references, and finally
add search queries to improve the answer."""
sources: list[str] = Field(
description="List of reference URLs that support your answer. Each reference should be a clean URL string."
)定義好schema後,構建修訂鏈指導原則綁定到LLM並解析輸出:
# Revision chain
improvement_chain = actor_prompt_template.partial(
primary_instruction=improvement_guidelines,
function_name=ImproveResponse.__name__,
) | llm.bind_tools(tools=[ImproveResponse])
improvement_parser = PydanticToolsParser(tools=[ImproveResponse])
response_improver = AdaptiveResponder(chain=improvement_chain, output_parser=improvement_parser)創建工具節點
下一步是在LangGraph工作流中執行工具調用。
雖然響應器和修訂器使用不同schema,但都依賴同一個外部工具(搜索API)。Reflexion的關鍵區別在於:能夠識別知識缺口並主動研究解決方案。
實現搜索集成:
# Tool execution function
def execute_search_queries(research_queries: list[str], **kwargs):
"""Execute the generated search queries."""
return tavily_tool.batch([{"query": search_term} for search_term in research_queries])
# Tool node
search_executor = ToolNode(
[
StructuredTool.from_function(execute_search_queries, name=GenerateResponse.__name__),
StructuredTool.from_function(execute_search_queries, name=ImproveResponse.__name__),
]
)這體現了LangGraph工作流中的工具集成。ToolNode自動處理工具執行和結果格式化,讓整合外部知識源變得無縫。
構建完整圖
最後一部就是將響應器、工具執行器和修訂器組裝成循環圖結構,這種結構捕捉了Reflexion的迭代本質:每個循環都強化最終答案。
首先定義圖狀態和循環控制函數:
# Graph state definition
class State(TypedDict):
messages: Annotated[list, add_messages]
# Helper functions for looping logic
def get_iteration_count(message_history: list):
""" Counts backwards through messages until it hits a non-tool, non-AI message
This helps determine how many tool execution cycles have occurred recently"""
iteration_count = 0
# Iterate through messages in reverse order (most recent first)
for message in message_history[::-1]:
if message.type not in {"tool", "ai"}:
break
iteration_count += 1
return iteration_count
def determine_next_action(state: list):
"""
Conditional edge function that determines whether to continue the loop or end.
Args:
state: Current workflow state containing messages
Returns:
str: Next node to execute ("search_and_research") or END to terminate
Logic:
- Counts recent iterations using get_iteration_count()
- If we've exceeded MAXIMUM_CYCLES, stop the workflow
- Otherwise, continue with another tool execution cycle
"""
# in our case, we'll just stop after N plans
current_iterations = get_iteration_count(state["messages"])
if current_iterations > MAXIMUM_CYCLES:
return END
return "search_and_research"構建完整的Reflexion工作流:
# Graph construction
MAXIMUM_CYCLES = 5
workflow_builder = StateGraph(State)
# Add nodes
workflow_builder.add_node("create_draft", initial_responder.generate)
workflow_builder.add_node("search_and_research", search_executor)
workflow_builder.add_node("enhance_response", response_improver.generate)
# Add edges
workflow_builder.add_edge(START, "create_draft")
workflow_builder.add_edge("create_draft", "search_and_research")
workflow_builder.add_edge("search_and_research", "enhance_response")
# Add conditional edges for looping
workflow_builder.add_conditional_edges("enhance_response", determine_next_action, ["search_and_research", END])
# Compile the graph
reflexion_workflow = workflow_builder.compile()可視化圖結構:
from IPython.display import Image, display
# Show the agent
display(Image(reflexion_workflow.get_graph().draw_png()))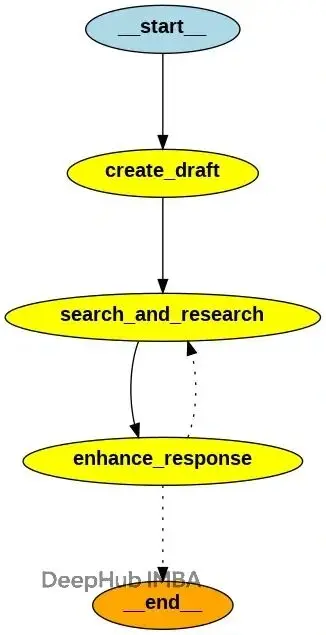
測試完整的Reflexion Agent:
# Run the agent with the neural networks question
target_question = "How do neural networks actually learn?"
print(f"Running Reflexion agent with question: {target_question}")
print("=" * 60)
events = reflexion_workflow.stream(
{"messages": [("user", target_question)]},
stream_mode="values",
)
for i, step in enumerate(events):
print(f"\nStep {i}")
print("-" * 40)
step["messages"][-1].pretty_print()Reflexion Agent的執行過程展現了完整的學習循環:
生成帶自我批評的初始技術解釋
識別需要研究的具體知識缺口
執行有針對性的網絡搜索獲取最新信息
將發現整合到綜合性、帶引用的回答中
重複過程直到解釋達到質量標準
兩種模式的選擇策略
我們已經實現了兩種模式,現在可以看看它們各自的適用場景:
選擇Reflection的情況:內容偏向創意或風格性時;現有內部知識已經足夠;更看重速度而非全面性;需要控制token和成本。
選擇Reflexion的情況:準確性和事實正確性至關重要;內容需要最新或專業信息;必須提供引用和參考來源;質量比速度更重要;關鍵決策因素在於任務是否需要外部知識獲取;如果主要目標是優化現有知識,選Reflection;如果任務需要發現並整合新信息,選Reflexion。
總結
Reflection和Reflexion都代表了AI系統設計的重要進步,各有獨特優勢和理想應用場景。
Reflection在內容精修、創意工作以及注重效率的場景中表現突出。而Reflexion通過整合外部研究和結構化反饋,在知識密集或需要引用的應用中提供更高準確性。
雖然這些方法可能需要更多LLM調用(因而耗費更多時間和成本),但它們顯著提升了產出高質量、可靠結果的可能性。更重要的是,通過在記憶中存儲改進軌跡或用於微調,能幫助模型避免未來重複相同錯誤。
https://avoid.overfit.cn/post/5f95082922614ac48cbfd84c0646199e
作者:Piyush Agnihotri
