

RAG系統在生產環境中有個老大難問題:脆弱。演示時用精心準備的問題去問,效果看起來很驚豔。但真正上線後,用户的問題五花八門,向量數據庫返回的文檔語義上相似但實際答非所問,LLM又特別喜歡討好,拿着一堆噪音數據照樣能編出一套看似合理的答案。
那麼問題出在哪呢?標準RAG是典型的開環架構:輸入 → 嵌入 → 檢索 → 生成,一條線走到底。每個環節都假設上游輸出是完美的,一旦某步出錯,錯誤就會一路傳導到最終結果。
要做企業級的RAG應用,必須轉向閉環系統,也就是所謂的自愈RAG。這裏的核心思路是讓系統具備自省能力:檢測到問題後能自主糾正,而不是把錯誤直接甩給用户。
第一部分:自動檢索
RAG的第一個坑其實是用户本身。沒人會按照向量搜索的最佳實踐來寫查詢,要麼用行話縮寫,要麼問題模糊不清,要麼一個問題裏塞了好幾件事。自愈系統需要在輸入端加一道"防護欄",把這些原始查詢轉換成高質量的檢索請求。
策略1:假設文檔嵌入(HyDE)
傳統檢索是拿短問題去匹配長文檔,比如用"crag架構"這幾個字去搜整段技術文檔。這種模態不匹配會嚴重影響召回質量。
HyDE的思路是這樣的,先讓LLM根據問題"編造"一個假設性的答案,然後用這個假設答案去做向量檢索。因為假設答案和真實文檔在形態上更接近,匹配效果自然更好。
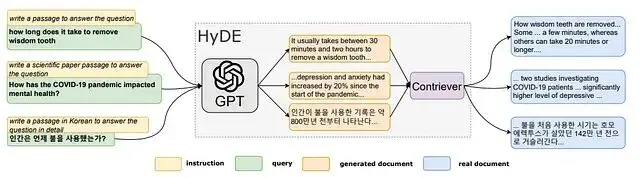
文檔片段展示了其工作方式,HyDE能處理各類查詢,且不需要修改底層的GPT-3和Contriever/mContriever模型。
比如説:
用户查詢:"CRAG評分器怎麼工作的?"
HyDE生成:"CRAG評分器通過評估檢索文檔的相關性來運作,它會對每個文檔打分……"(虛構內容)
向量搜索:用生成的內容去檢索,而不是用原始問題
代碼實現(hyde.py):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine import TransformQueryEngine
from llama_index.llms.openai import OpenAI
# 1. 配置用於生成假設文檔的LLM
Settings.llm = OpenAI(model="gpt-4-turbo", temperature=0.7)
def build_hyde_engine(index):
# 初始化HyDE轉換
# include_original=True 確保同時搜索原始查詢和假設文檔
hyde = HyDEQueryTransform(include_original=True)
# 創建標準檢索引擎
base_query_engine = index.as_query_engine(similarity_top_k=5)
# 用TransformQueryEngine包裝
# 這個中間件會攔截查詢,生成假設文檔,然後執行搜索
hyde_engine = TransformQueryEngine(base_query_engine, query_transform=hyde)
return hyde_engine
# 使用示例
# index = VectorStoreIndex.from_documents(docs)
# engine = build_hyde_engine(index)
# response = engine.query("Explain the self-correction mechanism in CRAG")策略2:查詢分解
用户問"Llama-3和GPT-4在代碼任務上誰表現更好",簡單檢索很難找到一篇文檔同時包含兩個模型的對比數據。查詢分解就是把這種複合問題拆成原子級子查詢:"Llama-3代碼能力"和"GPT-4代碼能力",分別檢索後再合併結果。
代碼實現(query_decomposition.py):
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
# 定義輸出結構
class SubQueries(BaseModel):
"""待檢索的子問題集合"""
questions: List[str] = Field(description="List of atomic sub-questions.")
# 配置規劃用的LLM
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
system_prompt = """You are an expert researcher. Break down the user's complex query.
into simple, atomic sub-queries that a search engine can answer."""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{query}")
])
# 構建處理鏈
planner = prompt | llm.with_structured_output(SubQueries)
def plan_query(query: str):
result = planner.invoke({"query": query})
return result.questions
# 使用示例
# sub_qs = plan_query("Compare Llama-3 and GPT-4 on coding benchmarks")
# print(sub_qs)
# 輸出:第二部分:控制層
文檔檢索回來瞭如何判斷它們靠不靠譜?CRAG的做法是在流程里加一個"評分員"角色,對每個檢索到的文檔進行相關性評估。如果發現數據質量不行,系統不會硬着頭皮生成答案,而是觸發備用方案(比如去搜網頁)。
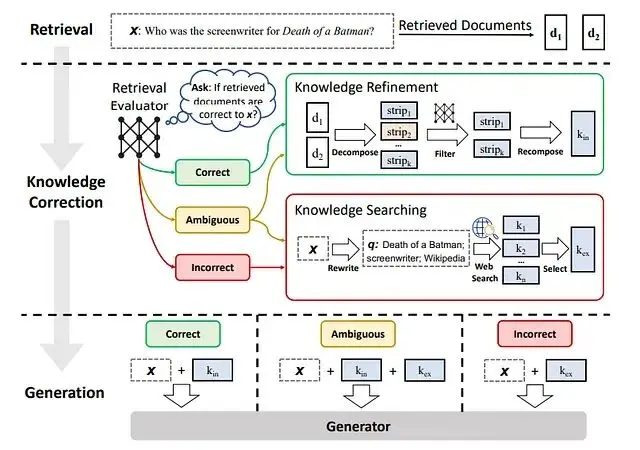
檢索評估器的工作原理:評估檢索文檔與輸入的相關性,估算置信度,然後根據結果觸發不同的後續動作——{正確、錯誤、模糊}三種狀態對應不同處理路徑。
這種分支決策邏輯用圖結構來實現最合適,LangGraph正好派上用場。
CRAG工作流程如下:
- 檢索:拿到候選文檔
- 評分:LLM判斷每個文檔"相關"還是"不相關"
- 決策:相關就直接生成答案;不相關則改寫查詢後去搜網頁
代碼實現(corrective_rag.py):
from typing import List, TypedDict
from langchain_core.prompts import PromptTemplate
from langchain_core.documents import Document
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import ChatOpenAI
from langgraph.graph import END, StateGraph, START
# --- 1. 狀態定義 ---
class GraphState(TypedDict):
question: str
generation: str
web_search: str # 'Yes'或'No'標記
documents: List
# --- 2. 組件初始化 ---
grader_llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
generator_llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
web_tool = TavilySearchResults(k=3)
# --- 3. 節點定義 ---
def grade_documents(state):
"""
自愈核心節點:過濾低質量文檔
"""
print("---CHECK RELEVANCE---")
question = state["question"]
documents = state["documents"]
# 二分類結構化輸出
structured_llm = grader_llm.with_structured_output(dict)
prompt = PromptTemplate(
template="""You are a grader assessing relevance.
Doc: {context}
Question: {question}
Return JSON with key 'score' as 'yes' or 'no'.""",
input_variables=["context", "question"],
)
chain = prompt | structured_llm
filtered_docs = []
web_search = "No"
for d in documents:
grade = chain.invoke({"question": question, "context": d.page_content})
if grade.get('score') == 'yes':
filtered_docs.append(d)
else:
# 丟失上下文時觸發回退
web_search = "Yes"
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def transform_query(state):
"""
自我糾正:重寫查詢以提升網頁搜索效果
"""
print("---TRANSFORM QUERY---")
question = state["question"]
# 簡易重寫鏈
prompt = PromptTemplate(template="Rewrite this for web search: {question}", input_variables=["question"])
chain = prompt | generator_llm
better_q = chain.invoke({"question": question}).content
return {"question": better_q}
def web_search_node(state):
print("---WEB SEARCH---")
docs = web_tool.invoke({"query": state["question"]})
# 網頁結果追加到已有文檔
web_results = [Document(page_content=d["content"]) for d in docs]
return {"documents": state["documents"] + web_results}
def generate(state):
print("---GENERATE---")
# 這裏接標準RAG生成鏈
# generation = rag_chain.invoke(...)
return {"generation": "Final Answer Placeholder"}
# --- 4. 圖構建 ---
workflow = StateGraph(GraphState)
# 添加節點
workflow.add_node("retrieve", lambda x: {"documents": []}) # 檢索佔位
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("transform_query", transform_query)
workflow.add_node("web_search_node", web_search_node)
workflow.add_node("generate", generate)
# 添加邊
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
def decide_to_generate(state):
if state["web_search"] == "Yes":
return "transform_query"
return "generate"
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{"transform_query": "transform_query", "generate": "generate"}
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
app = workflow.compile()第三部分:自動排序
向量檢索用的雙編碼器(Bi-Encoder)速度快但精度有限。文檔被壓縮成單個向量後,很多語義細節都丟了。解決辦法是引入交叉編碼器(Cross-Encoder)做二次排序。
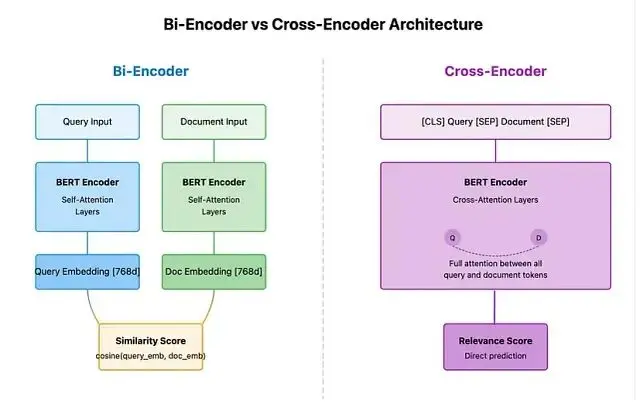
交叉編碼器把查詢和文檔作為一個整體輸入,直接輸出相關性分數的計算開銷比較大,所以一般採用兩階段策略:
- 粗篩:向量庫快速召回Top 50
- 精排:交叉編碼器對這50個文檔重新打分,保留Top 5
代碼實現(reranker.py):
from sentence_transformers import CrossEncoder
class Reranker:
def __init__(self):
# 加載MS MARCO優化過的模型
self.model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
def rerank(self, query, documents, top_k=5):
# 構造配對:[[query, doc1], [query, doc2]...]
pairs = [[query, doc] for doc in documents]
# 批量打分
scores = self.model.predict(pairs)
# 排序截取
results = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
return [doc for doc, score in results[:top_k]]第四部分:自動學習
高級的自愈系統不只是即時修復問題,還會從歷史錯誤中學習,避免同樣的坑反覆踩。實現方式是動態少樣本學習(Dynamic Few-Shot Learning)。
當系統生成了一個好答案(用户點了贊),就把這對查詢-答案存到一個專門的"黃金樣本庫"裏。後續遇到相似問題時,檢索這些成功案例注入到prompt中,相當於用系統自己的成功經驗來指導新的回答。
代碼實現(dynamic_prompting.py):
from llama_index.core import VectorStoreIndex, Document
from llama_index.core.prompts import PromptTemplate
class LearningManager:
def __init__(self):
self.good_examples = []
self.index = None
def add_good_example(self, query, answer):
"""用户點贊時調用"""
doc = Document(text=f"Q: {query}\nA: {answer}")
self.good_examples.append(doc)
# 重建索引(生產環境建議用支持增量更新的向量庫)
self.index = VectorStoreIndex.from_documents(self.good_examples)
def get_dynamic_prompt(self, current_query):
if not self.index:
return ""
# 檢索相似的歷史成功案例
retriever = self.index.as_retriever(similarity_top_k=2)
nodes = retriever.retrieve(current_query)
examples_text = "\n\n".join([n.text for n in nodes])
return f"Here are examples of how to answer correctly:\n{examples_text}"
# 在管道中使用
# manager = LearningManager()
# few_shot_context = manager.get_dynamic_prompt(user_query)
# final_prompt = f"{few_shot_context}\n\nQuestion: {user_query}..."進階方向:DSPy自動優化
如果想要更程序化的優化方式,DSPy是個值得關注的框架。它把prompt當成可優化的程序來處理,他會跑一遍驗證集並根據準確率等指標自動重寫prompt和更新少樣本示例。
import dspy
# 1. 定義RAG簽名
class GenerateAnswer(dspy.Signature):
"""用簡短事實性答案回答問題"""
context = dspy.InputField()
question = dspy.InputField()
answer = dspy.OutputField()
# 2. 定義模塊
class RAG(dspy.Module):
def __init__(self):
super().__init__()
self.retrieve = dspy.Retrieve(k=3)
self.generate = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
return self.generate(context=context, question=question)
# 3. 優化
# MIPROv2會運行管道,遇到失敗就重試並重寫指令
# 目標是最大化指定metric(精確匹配、語義相似度等)
optimizer = dspy.MIPROv2(metric=dspy.evaluate.SemanticF1)
optimized_rag = optimizer.compile(RAG(), trainset=training_data)完整系統集成
各個組件都準備好了:HyDE、查詢分解、CRAG、交叉編碼器重排序、動態提示。現在把它們串成一個完整的自愈RAG系統。這個編排層負責協調整個流程:解析查詢、增強檢索、校驗上下文、優化相關性、收集反饋學習、最終生成穩定可靠的答案。
import os
import json
import asyncio
from typing import List, Dict, Any, Optional
from datetime import datetime
# 導入各組件
from hyde import build_hyde_engine, Settings
from query_decomposition import plan_query, SubQueries
from corrective_rag import app as crag_app, GraphState
from reranker import Reranker
from dynamic_prompting import LearningManager
# 核心依賴
from llama_index.core import VectorStoreIndex, Document, SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from sentence_transformers import CrossEncoder
class SelfHealingRAGSystem:
"""
完整自愈RAG系統,整合全部組件
"""
def __init__(self, openai_api_key: str = None):
"""初始化RAG系統"""
# API密鑰配置
if openai_api_key:
os.environ["OPENAI_API_KEY"] = openai_api_key
# 組件初始化
print("🚀 Initializing Self-Healing RAG System...")
# 核心LLM
self.llm = OpenAI(model="gpt-4-turbo", temperature=0.3)
Settings.llm = self.llm
# 初始化各組件
self.reranker = Reranker()
self.learning_manager = LearningManager()
self.vector_index = None
self.hyde_engine = None
# 演示數據
self.sample_documents = self._create_sample_documents()
self._setup_vector_index()
# 統計
self.query_stats = {
"total_queries": 0,
"hyde_used": 0,
"decomposed_queries": 0,
"crag_activated": 0,
"reranked": 0,
"learning_applied": 0
}
print("✅ System initialized successfully!")
def _create_sample_documents(self) -> List[Document]:
"""創建演示用的示例文檔"""
sample_texts = [
"""Retrieval-Augmented Generation (RAG) is a technique that combines
pre-trained language models with external knowledge retrieval. RAG systems
retrieve relevant documents from a knowledge base and use them to generate
more accurate and factual responses.""",
"""Corrective RAG (CRAG) introduces a self-correction mechanism that grades
retrieved documents for relevance. If documents are deemed irrelevant, the
system triggers alternative retrieval strategies like web search.""",
"""HyDE (Hypothetical Document Embeddings) improves retrieval by generating
hypothetical documents that answer the query, then searching for real documents
similar to these hypothetical ones.""",
"""Cross-encoder reranking provides more accurate document scoring compared
to bi-encoder similarity search. It processes query-document pairs together
to produce refined relevance scores.""",
"""DSPy enables automatic prompt optimization by treating prompts as programs
that can be compiled and optimized against specific metrics like accuracy
or semantic similarity.""",
"""Self-healing RAG systems implement feedback loops that learn from successful
query-answer pairs, storing them as examples for future similar queries to
improve performance over time.""",
"""Query decomposition breaks complex multi-part questions into atomic
sub-queries that can be individually processed and then combined for
comprehensive answers.""",
"""Vector databases enable semantic search by converting documents into
high-dimensional embeddings that capture semantic meaning rather than
just keyword matches."""
]
return [Document(text=text, metadata={"id": i}) for i, text in enumerate(sample_texts)]
def _setup_vector_index(self):
"""用示例文檔構建向量索引"""
print("📚 Setting up vector index...")
self.vector_index = VectorStoreIndex.from_documents(self.sample_documents)
self.hyde_engine = build_hyde_engine(self.vector_index)
print("✅ Vector index ready!")
def enhanced_retrieve(self, query: str, use_hyde: bool = True, top_k: int = 5) -> List[Document]:
"""支持HyDE的增強檢索"""
print(f"🔍 Retrieving documents for: '{query}'")
if use_hyde:
print(" 🧠 Using HyDE for enhanced retrieval...")
response = self.hyde_engine.query(query)
# 從HyDE響應提取文檔
documents = response.source_nodes
self.query_stats["hyde_used"] += 1
else:
print(" 📖 Using standard retrieval...")
retriever = self.vector_index.as_retriever(similarity_top_k=top_k)
nodes = retriever.retrieve(query)
documents = nodes
# 轉換為Document對象
docs = []
for node in documents:
doc = Document(
page_content=node.text if hasattr(node, 'text') else str(node),
metadata=node.metadata if hasattr(node, 'metadata') else {}
)
docs.append(doc)
print(f" ✅ Retrieved {len(docs)} documents")
return docs
def decompose_and_retrieve(self, query: str) -> tuple[List[str], List[Document]]:
"""分解複雜查詢並分別檢索"""
print(f"🔧 Decomposing query: '{query}'")
try:
sub_queries = plan_query(query)
if len(sub_queries) > 1:
print(f" 📝 Decomposed into {len(sub_queries)} sub-queries:")
for i, sq in enumerate(sub_queries, 1):
print(f" {i}. {sq}")
# 對每個子查詢檢索
all_docs = []
for sq in sub_queries:
docs = self.enhanced_retrieve(sq, use_hyde=False, top_k=3)
all_docs.extend(docs)
self.query_stats["decomposed_queries"] += 1
return sub_queries, all_docs
else:
print(" ➡️ Query doesn't need decomposition")
docs = self.enhanced_retrieve(query)
return [query], docs
except Exception as e:
print(f" ⚠️ Error in decomposition: {e}")
docs = self.enhanced_retrieve(query)
return [query], docs
def apply_crag(self, query: str, documents: List[Document]) -> tuple[List[Document], str]:
"""應用CRAG過濾文檔"""
print("🔍 Applying CRAG (Corrective RAG)...")
try:
# 準備CRAG狀態
state = GraphState(
question=query,
generation="",
web_search="No",
documents=documents
)
# 正常情況下會跑完整CRAG流程
# 這裏為演示做簡化處理
filtered_docs = []
for doc in documents[:3]: # 演示限制
# 簡單相關性檢查(實際應該用LLM)
if any(keyword in doc.page_content.lower() for keyword in query.lower().split()):
filtered_docs.append(doc)
if len(filtered_docs) < len(documents):
self.query_stats["crag_activated"] += 1
print(f" 🚨 CRAG filtered {len(documents) - len(filtered_docs)} irrelevant documents")
return filtered_docs, "Documents filtered by CRAG"
except Exception as e:
print(f" ⚠️ Error in CRAG: {e}")
return documents, "CRAG not applied due to error"
def apply_reranking(self, query: str, documents: List[Document], top_k: int = 3) -> List[Document]:
"""交叉編碼器重排序"""
print("🎯 Applying cross-encoder reranking...")
try:
# 提取文本用於重排序
doc_texts = [doc.page_content for doc in documents]
if len(doc_texts) > 1:
reranked_texts = self.reranker.rerank(query, doc_texts, top_k)
# 映射回Document對象
reranked_docs = []
for text in reranked_texts:
for doc in documents:
if doc.page_content == text:
reranked_docs.append(doc)
break
self.query_stats["reranked"] += 1
print(f" ✅ Reranked to top {len(reranked_docs)} documents")
return reranked_docs
else:
print(" ➡️ Not enough documents for reranking")
return documents
except Exception as e:
print(f" ⚠️ Error in reranking: {e}")
return documents
def apply_dynamic_prompting(self, query: str) -> str:
"""動態少樣本學習"""
print("🧠 Applying dynamic prompting...")
try:
few_shot_context = self.learning_manager.get_dynamic_prompt(query)
if few_shot_context:
self.query_stats["learning_applied"] += 1
print(" ✅ Applied learned examples from previous successes")
else:
print(" ➡️ No relevant past examples found")
return few_shot_context
except Exception as e:
print(f" ⚠️ Error in dynamic prompting: {e}")
return ""
def generate_answer(self, query: str, documents: List[Document], few_shot_context: str = "") -> str:
"""基於檢索文檔生成答案"""
print("✍️ Generating final answer...")
# 合併文檔內容
context = "\n\n".join([doc.page_content for doc in documents[:3]])
# 構建prompt,可選包含少樣本示例
prompt_parts = []
if few_shot_context:
prompt_parts.append(few_shot_context)
prompt_parts.extend([
"Context:",
context,
f"\nQuestion: {query}",
"\nAnswer based on the provided context:"
])
prompt = "\n".join(prompt_parts)
try:
response = self.llm.complete(prompt)
answer = response.text.strip()
print(" ✅ Answer generated successfully")
return answer
except Exception as e:
print(f" ⚠️ Error generating answer: {e}")
return f"I apologize, but I encountered an error generating an answer: {e}"
def full_pipeline(self, query: str, user_feedback: bool = None, previous_answer: str = None) -> Dict[str, Any]:
"""
運行完整自愈RAG管道
"""
start_time = datetime.now()
print(f"\n🔄 Starting Self-Healing RAG Pipeline")
print(f"Query: '{query}'")
print("=" * 60)
self.query_stats["total_queries"] += 1
# 步驟1:查詢增強
sub_queries, documents = self.decompose_and_retrieve(query)
# 步驟2:文檔校驗(CRAG)
filtered_docs, crag_status = self.apply_crag(query, documents)
# 步驟3:文檔重排序
reranked_docs = self.apply_reranking(query, filtered_docs)
# 步驟4:動態提示
few_shot_context = self.apply_dynamic_prompting(query)
# 步驟5:答案生成
answer = self.generate_answer(query, reranked_docs, few_shot_context)
# 步驟6:學習(如有反饋)
if user_feedback is True and previous_answer:
try:
self.learning_manager.add_good_example(query, previous_answer)
print("📚 Added successful example to learning system")
except Exception as e:
print(f"⚠️ Error adding to learning system: {e}")
end_time = datetime.now()
processing_time = (end_time - start_time).total_seconds()
result = {
"query": query,
"sub_queries": sub_queries,
"documents_found": len(documents),
"documents_filtered": len(filtered_docs),
"final_documents": len(reranked_docs),
"answer": answer,
"crag_status": crag_status,
"processing_time": processing_time,
"components_used": self._get_components_used()
}
print("\n" + "=" * 60)
print(f"✅ Pipeline completed in {processing_time:.2f} seconds")
print(f"📊 Documents: {len(documents)} → {len(filtered_docs)} → {len(reranked_docs)}")
return result
def _get_components_used(self) -> List[str]:
"""獲取本次查詢用到的組件"""
components = ["Vector Retrieval"]
if self.query_stats["hyde_used"] > 0:
components.append("HyDE")
if self.query_stats["decomposed_queries"] > 0:
components.append("Query Decomposition")
if self.query_stats["crag_activated"] > 0:
components.append("CRAG")
if self.query_stats["reranked"] > 0:
components.append("Cross-Encoder Reranking")
if self.query_stats["learning_applied"] > 0:
components.append("Dynamic Prompting")
return components
def get_system_stats(self) -> Dict[str, Any]:
"""獲取系統統計信息"""
return {
"total_queries": self.query_stats["total_queries"],
"hyde_usage_rate": f"{(self.query_stats['hyde_used'] / max(1, self.query_stats['total_queries']) * 100):.1f}%",
"decomposition_rate": f"{(self.query_stats['decomposed_queries'] / max(1, self.query_stats['total_queries']) * 100):.1f}%",
"crag_activation_rate": f"{(self.query_stats['crag_activated'] / max(1, self.query_stats['total_queries']) * 100):.1f}%",
"reranking_rate": f"{(self.query_stats['reranked'] / max(1, self.query_stats['total_queries']) * 100):.1f}%",
"learning_rate": f"{(self.query_stats['learning_applied'] / max(1, self.query_stats['total_queries']) * 100):.1f}%",
"learned_examples": len(self.learning_manager.good_examples)
}
def demo_interactive_session():
"""交互式演示"""
print("""
🎯 Self-Healing RAG System Demo
================================
This system demonstrates:
• HyDE: Hypothetical Document Embeddings
• Query Decomposition: Breaking complex queries
• CRAG: Corrective RAG with document grading
• Cross-Encoder Reranking: Precision ranking
• Dynamic Learning: Few-shot from success examples
""")
# 初始化系統
system = SelfHealingRAGSystem()
# 演示用查詢
demo_queries = [
"What is RAG and how does it work?",
"Compare HyDE and standard retrieval methods",
"How does CRAG improve retrieval quality and what are the benefits of cross-encoder reranking?",
"Explain the self-correction mechanisms in modern RAG systems",
"What are the advantages of DSPy optimization for prompts?"
]
print("🔥 Running Demo Queries...")
print("=" * 50)
results = []
for i, query in enumerate(demo_queries, 1):
print(f"\n📋 Demo Query {i}/{len(demo_queries)}")
result = system.full_pipeline(query)
results.append(result)
print(f"\n💡 Answer:")
print(f"{result['answer']}")
print(f"\n📊 Components Used: {', '.join(result['components_used'])}")
# 模擬正反饋用於學習
if i > 1: # 第二個查詢開始加反饋
system.full_pipeline(query, user_feedback=True, previous_answer=result['answer'])
# 最終統計
print("\n" + "=" * 60)
print("📈 SYSTEM PERFORMANCE STATISTICS")
print("=" * 60)
stats = system.get_system_stats()
for key, value in stats.items():
print(f"{key.replace('_', ' ').title()}: {value}")
return system, results
if __name__ == "__main__":
# 設置OpenAI API密鑰
# os.environ["OPENAI_API_KEY"] = "your-key-here"
demo_interactive_session()總結
經典的RAG到自愈RAG,本質上是從"檢索"到"推理"的升級。HyDE和查詢分解確保問對問題;CRAG和交叉編碼器確保讀對文檔;自動學習機制則讓系統不再反覆犯同樣的錯。這套組合下來,RAG系統的泛化性會有質的提升。
https://avoid.overfit.cn/post/d95478d7799646acbed0e0d2dc2c480d
作者:Subrata Samanta