

ReSearch是一種創新性框架,通過強化學習技術訓練大語言模型執行"推理搜索",無需依賴推理步驟的監督數據。該方法將搜索操作視為推理鏈的有機組成部分,其中搜索的時機與方式由基於文本的推理過程決定,而搜索結果進一步引導後續推理。研究分析表明,ReSearch在強化學習訓練過程中自然地形成了高級推理能力,包括反思與自我糾正機制。
技術方法
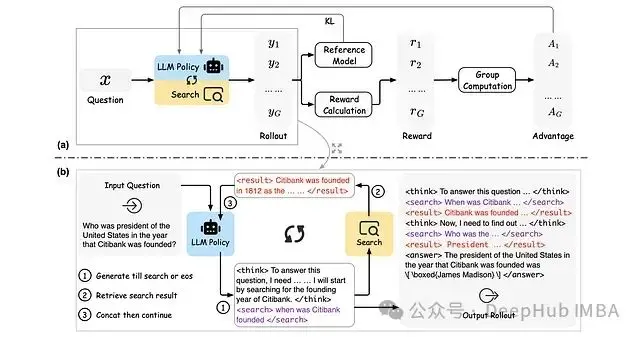
ReSearch的訓練架構概述
與傳統的僅包含文本推理的推理過程相比,ReSearch框架中的推理過程融合了搜索查詢與檢索結果。系統採用
<search>和
</search>標籤來封裝搜索查詢,使用
<result>和
</result>標籤來封裝檢索結果,這些格式規範在提示模板中明確定義。整個推理過程構成了基於文本的思考、搜索查詢和檢索結果之間的迭代循環。具體實現中,當生成過程遇到
</search>標籤時,系統會提取最近的
<search>與當前
</search>標籤之間的內容作為查詢語句,用於檢索相關事實信息,檢索結果則被
<result>和
</result>標籤封裝。隨後,系統將現有推理與檢索結果串聯作為下一輪輸入,以迭代方式生成後續響應,直至生成過程遇到結束句子(EOS)標記。
基礎模型的提示模板:
A conversation between User and Assistant.
The user asks a question, and the assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
During thinking, the assistant can invoke the wikipedia search tool to search for fact information about specific topics if needed.
The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags respectively,
and the search query and result are enclosed within <search> </search> and <result> </result> tags respectively.
For example,
<think> This is the reasoning process. </think>
<search> search query here </search>
<result> search result here </result>
<think> This is the reasoning process. </think>
<answer> The final answer is \boxed{answer here} </answer>.
In the last part of the answer, the final exact answer is enclosed within \boxed{} with latex format.
User: prompt. Assistant:指令模型的系統提示:
You are a helpful assistant that can solve the given question step by step with the help of the wikipedia search tool.
Given a question, you need to first think about the reasoning process in the mind and then provide the answer.
During thinking, you can invoke the wikipedia search tool to search for fact information about specific topics if needed.
The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags respectively,
and the search query and result are enclosed within <search> </search> and <result> </result> tags respectively.
For example,
<think> This is the reasoning process. </think>
<search> search query here </search>
<result> search result here </result>
<think> This is the reasoning process. </think>
<answer> The final answer is \boxed{answer here} </answer>.
In the last part of the answer, the final exact answer is enclosed within \boxed{} with latex format.與原始GRPO不同,ReSearch中的損失函數計算經過了特殊處理。由於推理過程中包含的檢索結果並非由訓練策略生成,而是由搜索環境檢索得到,因此在損失計算中對檢索結果部分進行了掩碼處理,以避免訓練策略對檢索結果產生不必要的偏好。
ReSearch的獎勵函數設計包含兩個核心組成部分:答案獎勵和格式獎勵:
- 答案獎勵:通過F1分數計算
\boxed{}中的最終答案與真實答案之間的正確性。 - 格式獎勵:驗證推理過程是否正確遵循了提示模板中規定的格式規範,重點檢查標籤的正確使用以及答案中
\boxed{}的存在。
推理過程的最終獎勵函數表達式如下:

實驗配置
研究團隊在Qwen2.5–7B、Qwen2.5–7B-Instruct、Qwen2.5–32B和Qwen2.5–32B-Instruct模型上進行了訓練與評估。訓練僅使用MuSiQue的訓練集(19,938個樣本),該數據集包含多種類型的多跳問題,並經過嚴格的質量控制構建。模型訓練週期為2個完整週期。
在知識檢索方面,研究採用E5-base-v2作為檢索引擎,選用2018年12月的Wikipedia數據作為知識庫。
評估採用了四個標準基準測試集來評估多跳問答任務性能:HotpotQA、WikiMultiHopQA、MuSiQue和Bamboogle。其中,HotpotQA、WikiMultiHopQA和MuSiQue通過不同的眾包多跳挖掘策略在維基百科或維基數據中構建,而Bamboogle則是一個手動構建的挑戰性數據集,包含雙跳問題,其難度足以使主流互聯網搜索引擎無法提供準確答案。
評估結果
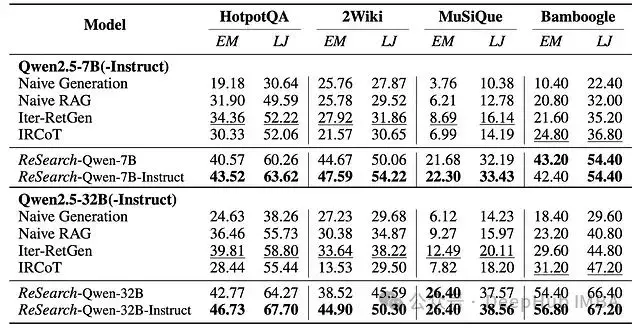
多跳問答基準測試上的精確匹配(EM,%)和LLM-as-a-Judge(LJ,%)評估結果
ReSearch框架在評估中展現了顯著的性能優勢:
- 顯著超越基線模型:在所有基準測試中,ReSearch相比最佳基線模型,7B參數規模模型在精確匹配指標上平均提升了15.81%,在LLM-as-a-Judge指標上提升了17.56%;32B參數規模模型在精確匹配指標上平均提升了14.82%,在LLM-as-a-Judge指標上提升了15.46%。
- 指令微調效果顯著:以指令微調過的LLM作為ReSearch的基礎模型,相較於使用基礎LLM,性能獲得進一步提升。這一現象在所有基準測試和不同模型規模上均表現一致。
- 泛化能力強勁:儘管僅在MuSiQue數據集上進行訓練,ReSearch仍能有效泛化到其他具有不同問題類型和結構的基準測試中,證明所學習的推理能力具有跨數據集的通用性。
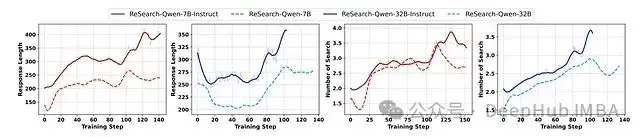
訓練過程中的響應長度和搜索操作數量變化
訓練動態分析揭示了以下規律:
- 響應長度呈增長趨勢:響應長度在訓練過程中普遍呈現增長趨勢,指令微調模型生成的響應通常長於基礎模型。32B規模模型展現了獨特的模式,初始階段響應長度下降,隨後再次上升,這可能反映了模型從依賴固有知識到有效利用檢索結果的學習過程轉變。
- 搜索操作持續增加:搜索操作數量在整個訓練過程中穩步增長,表明模型逐漸學習到如何通過迭代搜索解決複雜多跳問題的能力。
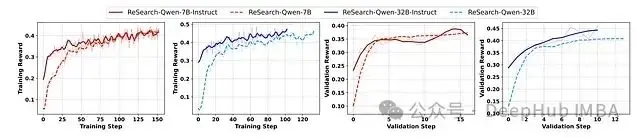
訓練過程中的訓練和驗證獎勵變化
獎勵指標分析表明:
- 獎勵增長模式:訓練和驗證獎勵在初始訓練階段呈現急劇上升趨勢,隨後進入平緩的持續提升階段。指令微調模型從較高的獎勵水平開始訓練。7B規模模型最終收斂至相近的獎勵水平,而32B指令微調模型始終維持高於其基礎對應模型的獎勵水平。
https://avoid.overfit.cn/post/c10d4d6466604f1a9fe1866e18125e9b
作者:Ritvik Rastogi