









背景
OceanBase 從 4.3.0 版本開始,推出了加速 AP 查詢的列存引擎,具體包含:
- 新的列式編碼
- 列預聚合信息
- 列存執行引擎
- 向量化內存格式
- 新的查詢優化器,能根據規則和代價動態選擇行存和列存引擎。
OceanBase 列存引擎發佈之後,AP 分析能力得到了大幅提升,在與一系列競品的對比測試中都有比較好的表現,正式踏入了 HTAP 領域。
為了節省存儲成本和簡化用户的運維,OceanBase 將 TP 和 AP 業務放在一套系統中,共享一份數據。實際的業務場景中,尤其是核心業務,往往有大量數據更新,這些業務也需要對數據做一些實時的數據分析,因此對 OceanBase 分析引擎提出了比較高的挑戰。
在實戰營(第三季)第一期的課程文檔中,大家知道 OceanBase 採用的是 LSM Tree 的存儲架構,數據分層存儲,新數據追加寫入最熱層,並且只記錄最新值。這種寫入方式對 TP 系統比較友好(寫多讀少),但是因為查詢採用的是 Merge-On-Read 的處理方式,所以當增量數據比較多時,對 AP 分析能力有一定的影響(讀放大)。
為了消除增量數據對分析引擎的性能影響,OceanBase 在 4.3.5 版本中提出了 Merge-On-Write 表,將更新拆分成 delete / insert 寫入增量數據中,查詢時分別對增量和基線數據進行處理,從而顯著地提高了更新頻繁場景下 OceanBase 的實時分析能力。
Merge-On-Write 表特性
OceanBase 存儲介紹
先簡單來回顧和複習一下:
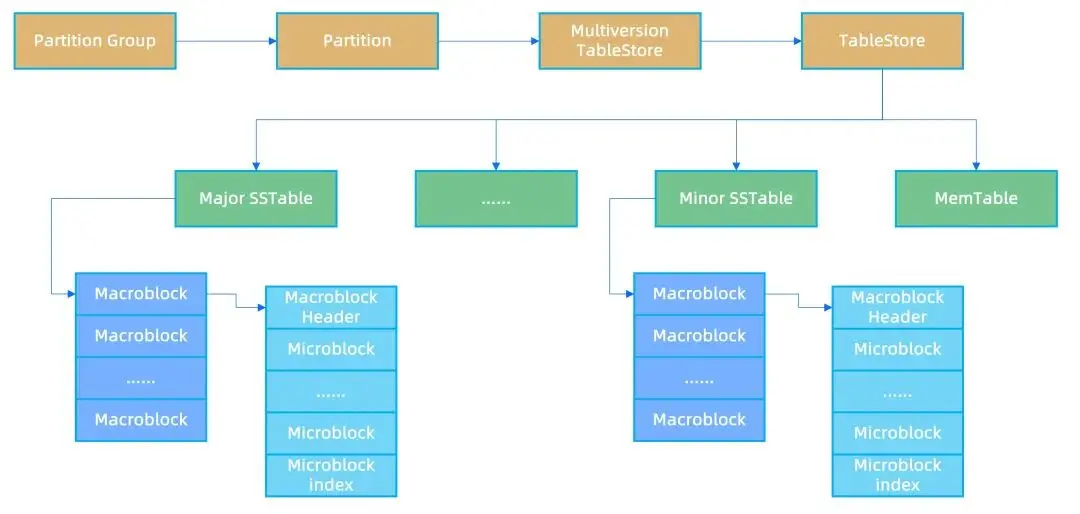
- OceanBase 採用的是 LSM Tree 的存儲架構,每張表的每個分區中,數據在磁盤上存儲的邏輯單位是 SSTABLE,LSM Tree 的每層數據包含一個或者多個 SSTABLE,每個 SSTABLE 內部數據按主鍵順序排列。
- 基線 SSTABLE 也被稱為 Major SSTABLE,主要用來優化查詢。基線 SSTABLE 是選取某個快照點,對提交版本在快照內的數據做全量合併之後生成的 SSTABLE。
- 為了優化寫 IO,SSTABLE 內數據按固定 2MB 大小切割成宏塊(MacroBlock),宏塊是數據文件寫 IO 的基本單位。
- 為了優化讀 IO,每個宏塊內的數據按 16KB 切割成一個個微塊(MicroBlock),微塊是數據讀 IO 的基本單位。
Merge-On-Read 表查詢及其痛點
OceanBase 當前存儲架構中,為了優化寫入性能和節省存儲空間,增量 SSTABLE 只記錄主鍵和更新列的值。
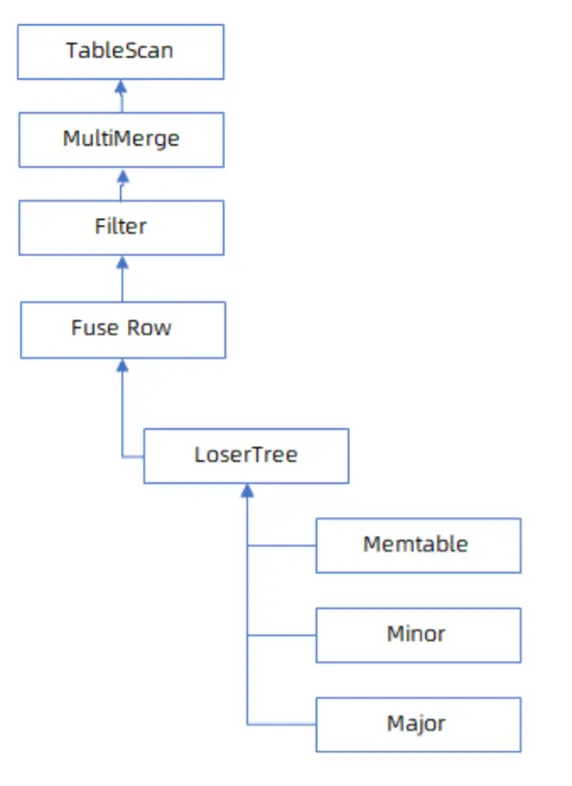
查詢時為了獲取主鍵的最新值,需要依次讀取 MemTable、增量 SSTABLE、基線 SSTABLE,融合每層讀到的數據獲取完整行,這種在查詢時對數據進行融合的流程叫做 Merge-On-Read。
Merge-On-Read 能較好地支持按主鍵點查,但是對於範圍查詢不太友好。當各層 SSTABLE 之間主鍵存在重疊和交叉時,對於每層 SSTABLE 吐出的行,需要用敗者樹(最小/大堆)來對各層吐出的數據進行融合和去重,這樣執行引擎只能按行來計算下壓謂詞和投影,整體處理性能不高。
在當前版本中,OceanBase 對這種處理方式做了比較多的優化,例如在查詢過程中能動態判斷某層 SSTABLE 的宏塊/微塊內的數據與其它 SSTABLE 內的數據是否有交叉。如果某個宏塊、微塊內的主鍵和其它的微塊沒有交叉,説明這批主鍵只在這個宏塊、微塊內存在,可以不需要走敗者樹,只對這個 SSTABLE 進行掃描。
説明:上面這段內容,不理解也無妨。
大意就是説 OceanBase 存儲引擎有一些實現上的優化,來緩解讀放大的問題。
Merge-On-Read 查詢流程中實現單邊掃描優化之後,雖然 AP 能力得到了一定的增強,但是增數數據較多時,尤其增量與基線之間主鍵存在大量交叉時,整體的查詢性能仍然會受到一定影響。
Merge-On-Write 表查詢流程
與 merge-on-read 不同,merge-on-write 能更好地解決對基線數據做大量更新之後的查詢性能問題。
為了不影響查詢的性能,merge-on-write 會將更新數據的修改,移到寫入階段。業界中常用的做法是在舊行上標記 delete bitmap,然後在尾部追加寫入新行。查詢時,只需要讀取原始數據和相應的 delete bitmap,便可以對相同主鍵的數據進行去重,獲取最新值。
OceanBase 也參考了業界的經典方案,添加了 merge-on-write 表類型,將查詢的部分熱點的 merge 動作,前置到寫入模塊。
但考慮到 HTAP 業務中數據的更新量比較大,OceanBase 需要支持的業務比較複雜,需要維護每個快照點的多版本信息,這樣對於 delete bitmap 的多版本信息維護將是一個比較大的挑戰,並且在數據部分,OceanBase 已經有了一套比較成熟的 MVCC 多版本管理機制。
因此 OceanBase 對 merge-on-write 方案做了一些改進,寫入時更新行會將 update 改寫成 delete + insert,update 時會讀出舊值,將融合之後的最新行的全列數據 insert 寫入 memtable(即下圖中的 mini),每行數據都會記錄其提交版本信息。
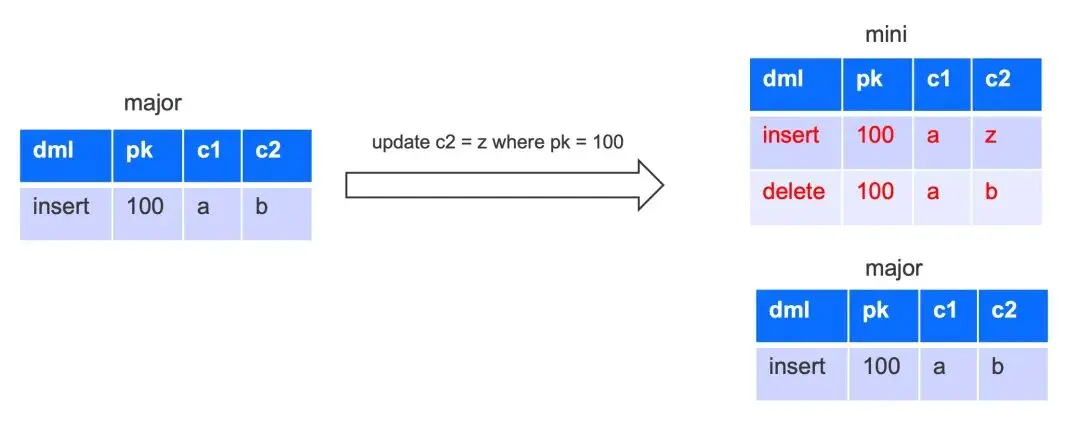
OceanBase merge-on-write 表的查詢過程中,將增量數據和基線數據分成了兩個部分,而不是像原來一樣放入一棵敗者樹中進行比較。
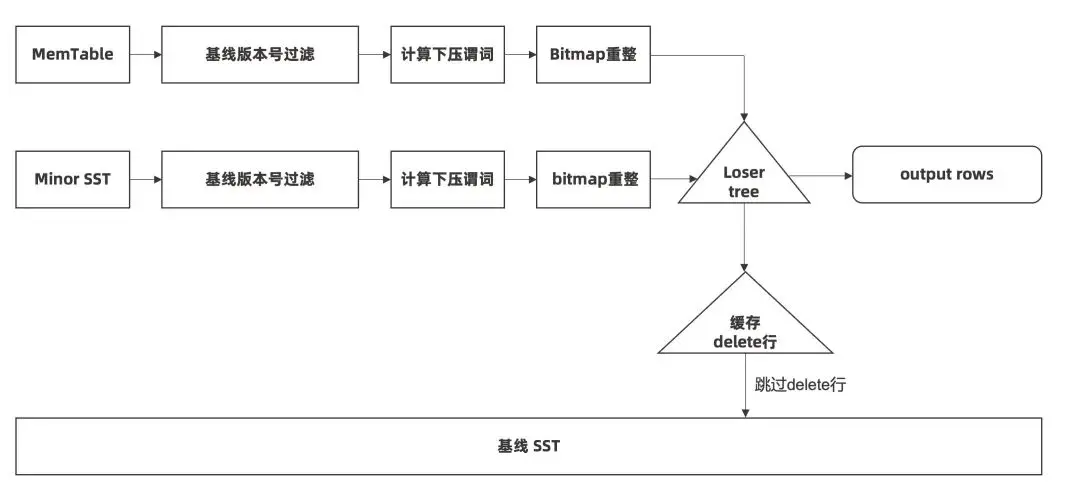
掃描時先選取提交版本號大於基線的增量數據進行掃描,計算下壓謂詞,再做投影。
若投影時,發現增量數據有對基線數據做修改,會將相應的更新信息緩存住,掃描基線時會跳過相應的主鍵行。相對於原有查詢流程的主要優化點是:
- 增量部分存儲了全列信息,可以預先計算下壓謂詞;
- 增量數據和基線數據不在一棵敗者樹中,當增量數據被下壓謂詞過濾之後,能大幅減少基線數據跳重複行的次數,從而大幅提高了增量和基線的批處理能力。
説明:
上面這一大段的內容,不理解也無妨。
大意就是説:在 MOW 表中,memtable 中不像以前一樣,只存主鍵和被更新的列,而是會存儲最新行的全部列的數據。這樣在一定程度上,可以減少查詢時增量數據和基線數據歸併的實現複雜度,進而實現更好的查詢優化。
Merge-On-Write 表的實驗數據
OceanBase merge-on-write 表相對於 merge-on-read 表的區別主要是:
- 寫入時會將 update 拆解為 delete + insert,insert 行會寫入所有列的最新值。
- 增量部分原來因為沒有填充舊值,不能預先計算下壓謂詞,需要將各層數據融合之後才能計算過濾條件;寫入全列之後,增量部分也可以直接計算過濾條件。
- 原來增量數據和基線數據的查詢會用一棵敗者樹,當有主鍵交叉或者重疊時,弱化了基線數據的批處理能力。在查詢流程中將這兩部分拆開之後,基線數據的批處理只有在過濾之後仍有 delete 行的條件下,才會按批去做主鍵去重,基線的批處理能力得到了很大的增強。
説明:
上面這一大段的內容,不理解也無妨。因為涉及到了底層實現,所以大家不用害怕,也不必花時間深究。
後面的這一小部分 “適用場景” 和 “使用方法”,才是本期課程中希望大家瞭解的重點內容(精華內容總是被濃縮的狀態)~
詳細的實驗數據,先不在這裏放了,推薦大家到本文最後的 “邊學邊練,效果拔羣” 部分,通過在線體驗來獲取吧~
Merge-On-Write 表的適用場景
merge-on-write 表適用於 HTAP 和 AP 類的分析場景。如果是 TP 場景,則不建議開啓,因為 merge-on-write 表的增量數據會記錄查詢融合後的全行信息,影響數據更新效率和存儲空間。
業務中有大量數據更新並且需要實時做複雜的分析查詢時,可以指定表的類型為 merge-on-write 表。
Merge-On-Write 表的使用方法
OceanBase 中可以指定 merge_engine = delete_insert 來使用 merge-on-write表,它在4.3.5.3 及以後的版本生效。
下面是具體的使用方法:
- 創建表時指定。
create table table_name xxx
[merge_engine = {delete_insert | partial_update}]
[with column group(xxx)]- merge_engine = delete_insert : 表示採用 merge on write 的寫入和查詢模式;
- merge_engine 不指定或者指定 merge_engine = partial_update,仍採用以前部分列更新的流程,即 merge-on-read 的模式。- 使用示例:
// 創建一張純列存表,更新模型是 merge-on-write
create table t1(c1 int, c2 int)
merge_engine = delete_insert
with column group(each column);-
租户配置項中指定。
- 如果不想修改業務代碼,OceanBase 也支持指定租户新建表的默認 merge_engine。
- 租户配置項只在建表語句中沒有顯示指定 merge_engine 的情況下生效,若建表語句中顯式指定了表的 merge_engine,則按建表語句中指定的格式進行解析。
// 用户創建表默認 merge_engine = delete_insert
// 在建表語句中自動添加 merge_engine = delete_insert
alter system set default_table_merge_engine = delete_insert;未來展望
merge-on-write 表的增量數據包含了數據的全行信息,在生成增量 SSTABLE 時,對於頻繁查詢的列,可以在 SSTABLE 的中間層生成 skip index 預聚合信息(詳見:列 Skip Index 屬性)。
説明:
加上 skip index 之後,OceanBase 的 AP 性能,就可以直接上桌去和 StarRocks 等純 AP 數據庫掰掰手腕了。
處理增量數據時,可以像基線數據一樣,基於 skip index 對訪問數據進行裁剪。當增量 SSTABLE 中訪問的宏塊、微塊數據可以用 skip index 進行裁剪時,整體的查詢性能會有數量級的提升。
關於增量 SSTABLE 自適應添加 skip index,會在下一版本對外發布,歡迎大家持續關注~(聽研發説,下一個版本,性能會在現在的基礎上,繼續再翻上個幾倍。算了,這個秘密還是不提前泄露出去了)~~
What is more ?
如果您現在使用的 OceanBase 版本是低於 4.3.5 的老版本,可以考慮通過調整 table mode 這種更傳統的方法,來緩解存儲引擎的讀放大問題。
具體方法詳見 OceanBase 社區公眾號上的這篇文章 ——《在 OceanBase 中,如何應對存儲引擎的讀放大問題?》。
Q & A
最後在這裏記錄用户在閲讀之後,在技術交流羣裏提出的問題,以及羣友的回覆:
問: LSM Tree 架構下,對一個非主鍵字段 c1 一直更新不同的值, 那隨着不斷更新,select c1 from tab的效率是不是一直在變慢?
答:沒合併前,如果持續更新,理論上是會一直變慢的。
問:但我看 OB 在 trans node 的變更鏈上一直是在頭上添加新增的最新值,為什麼會原來越慢?
答:因為每次修改記錄的都是變化的數據,你只改 c1,它就只記錄 c1 的最新值。而查詢往往要查詢很多列,查詢數據需要合併多個結果集。LSMTree 讀就是這樣,不只是 OB 這樣。
問:查詢其它列慢我想通的。每次只查 c1 列還會變慢不太理解。
答:如果只是 get(例如走主鍵)是不會影響的,buffer 錶針對的是 scan 的查詢慢。如果中間的多版本行或者 delete 行比較多,掃描的過程中需要跳過比較多的無效行。跳的無效行越多,查詢就會越慢。
對本文內容有任何疑問的朋友,歡迎到評論區留言提問,小編會第一時間回覆大家!(不限於 MOW 表和 buffer 表,其他任何和 Oceanbase 有關的問題都可以。知無不言,言無不盡~)
Commercial Break
0x00. 邊學邊練,效果拔羣!
實戰營中 MOW 表性能提升的在線體驗地址:《Delete-Insert 存儲引擎》[2]。
- 常規生產環境的測試結果:merge-on-write 表,查詢性能相對於 merge-on-read 表,會有 5 倍以上的提升。
- 這個實驗有導入數據(大概要 100 秒左右)之類耗時較長的操作,大家可以一次性把實驗文檔所有 SQL 語句全都複製到右邊的實驗環境裏去執行,然後一邊等待最後的實驗結果,一邊閲讀下面的文章內容。
- 在實驗環境是在純列存表上做了一個小規模數據的測試,在這個測試中,性能差異可能沒有那麼明顯(不過 2 ~ 3 倍應該還是有的,為確保測試準確性,建議在實驗環境中多次重複執行最後的性能對比 SQL,並取平均值)。實際在更大規模數據或更高併發場景下(生產環境),才能真正體現出 merge-on-write 表的優勢。
-
文檔不可盡信,實踐才出真知。
- OceanBase 官網文檔《創建表》[3]中的創建 MOW 表的語法如下(截至 2025.10.22):
CREATE TABLE table_name column_definition
MERGE_ENGINE = {delete_insert | partial_update}
WITH COLUMN GROUP([all columns,] each column);- 語法中的 WITH COLUMN GROUP,看上去是建 MOW 表的必選項,所以貌似只有列存表和行列混存表才能被設置 MOW 屬性。
- 大家可以試一試,去掉 WITH COLUMN GROUP xxx,看看能不能把純行存表也設置為 MOW 表?
- 大家還可以嘗試看看能不能把實驗環境中最初的兩個建表語句改成純行存表,然後再對比一下行存 MOW 表相比普通行存表的性能提升(多次執行查詢,取平均值),看看能不能達到蒲華大佬宣稱的性能提升 5 倍以上?
CREATE TABLE ct1 (
c1 INT,
c2 INT,
c3 DATE
) MERGE_ENGINE = DELETE_INSERT;
CREATE TABLE ct1_normal (
c1 INT,
c2 INT,
c3 DATE
);小編的猜想:
因為行存表的查詢性能一般會比列存表更差,所以如果行存表可以設置 MOW 屬性的話,性能提升幅度大概率也會比列存表更顯著。(換句話説就是:進步快,源於起點低~ 🤣)
大家可以在實驗環境中通過測試,來驗證下這個傢伙的猜想是否正確?
如果不正確,可以再思考下為何不正確?

- 課後小測地址:【DBA 實戰營】 Merge-On-Write 表[4],在第三季的實戰營活動中,每通過一個課後練習,就會自動獲得 10 個社區積分,並獲得一次抽獎的資格。抽獎時有機會獲得實體禮物或更高額的積分獎勵。
小提示:
- 需要先登錄 OceanBase 賬號,才能初始化屏幕右邊的實驗環境進行實驗。
- 在實驗環境裏,幹什麼都可以。大家不要受限於屏幕左邊的實驗手冊,可以天馬行空地做一些你感興趣的事情,<font style="color:rgb(136, 136, 136);background-color:rgba(0, 0, 0, 0);">或者驗證一些你對 OceanBase 官網文檔的疑問、以及自己的猜想等等。
- 歡迎大家平時在學習 OceanBase 的過程中,也都能充分利用在線體驗頁面為您提供的一些實驗環境,來體驗 OceanBase 中您感興趣的新特性。
參考資料
[1]
列 Skip Index 屬性: https://www.oceanbase.com/docs/common-oceanbase-database-stan...
[2]
《Delete-Insert 存儲引擎》: https://www.oceanbase.com/demo/delete-insert-engine
[3]
《創建表》: https://www.oceanbase.com/docs/common-oceanbase-database-stan...
[4]
【DBA 實戰營】 Merge-On-Write 表: https://exam.oceanbase.com/pre?did=ha_vN5Zs3SP_5KD378wV1




