


丹尼爾:蛋兄,問個問題唄。RAG 裏的文檔應該怎麼切割比較好呢?按固定的字符數或詞數?按句?按段落?加個重疊窗口?感覺這些都太簡單粗暴,容易把相關的內容給拆散了
蛋先生:恩,你説得對。這些方法一刀切,確實沒辦法考慮上下文的語義關係。現在大模型越來越強大,完全可以藉助它們的能力,比如 LumberChunker
丹尼爾:LumberChunker?
蛋先生:這個名字起得非常有意思。"Lumber"是指經過精細加工的木材。這個方法就像一位經驗豐富的木匠,不是簡單地用鋸子亂砍,而是根據木材的紋理和特性,將文檔切割成結構合理、大小適中的塊。每一塊都能保留完整的語義,同時又不會超出大模型的處理能力
丹尼爾:哇塞,聽起來很酷,具體是怎麼切的呢?
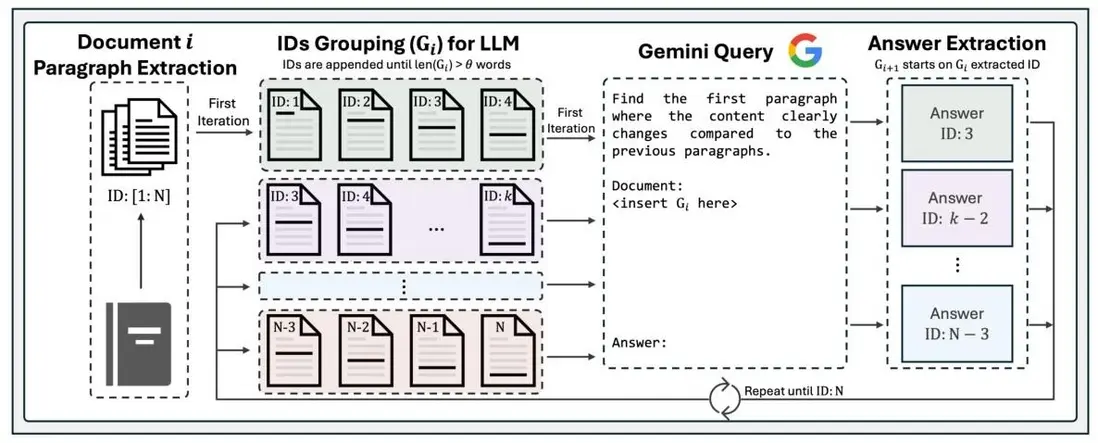
蛋先生:我們直接來走一遍切塊流程,相信聰明的你一下就懂了
LumberChunker 的切塊流程
✎ 第一步,自然拆分
蛋先生:咱們先把文章按自然段落拆開,比如用空行或縮進作為分界。這樣切出來的就是人類寫作時天然的語義單位了
丹尼爾:明白,就是先把原文分成幾段
✎ 第二步,初步分組
蛋先生:接着我們來給每個段落計算 token 數,並設定一個上限閥值,比如 550 tokens。從第一個段落開始往後加,假設第 1、2、3 段加起來小於 550,但再加上第 4 段就超過閾值,那就先把第 1 ~ 3 段打包成一組
丹尼爾:哦?就是以長度上限作為分組的依據嗎?
蛋先生:是的,這個 token 數閾值主要是考慮了模型輸入長度的限制,同時將它作為分組的依據,一舉兩得
丹尼爾:妙啊!
✎ 第三步,找語義斷裂點
蛋先生:最後我們把剛才那一組(第 1 ~ 3 段)送進大模型,讓它判斷:
# 提示語簡單示例
“從哪個段落開始,內容跟第一個段落關係不大了?”
模型會返回一個索引數字,比如:
-1 表示這幾個段落語義連貫,全相關
2 表示從第 2 段之後,主題開始變化
丹尼爾:如果是 -1 呢?
蛋先生:那就説明第 1 ~ 3 段語義一致,比如都是在講“人工智能基礎、機器學習、深度學習”,那它們就組成一個完整的語義塊。然後我們繼續拿第 4 段當新起點
丹尼爾:哦,那如果模型輸出為 2 呢?
蛋先生:那就表示第 1、2 段關係緊密,第 3 段開始語義發生變化。於是我們就可以把 1、2 段作為一個語義塊生成 embedding,第 3 段作為新一組的開頭
✎ 第四步,循環以上流程
丹尼爾:然後呢?
蛋先生:我們在上面的流程處理後,拿到了新的起點段落,然後重複以上流程,直到所有段落都被處理完畢
丹尼爾:哎呦不錯哦,又簡單又有效,這樣看上去每個相關的塊基本都可以在一起,不會被硬拆開
蛋先生:沒錯,有了高質量的分塊,RAG 系統在檢索相關信息時會更準確,因為每個塊都是語義完整的單元,不會因為分塊不當導致信息丟失或混亂
丹尼爾:看來 LumberChunker 確實是個智能的"木匠",切得恰到好處啊!
寫在最後
若已看完上述對話,可通過下圖進一步加深對 LumberChunker 的理解
“親們,都到這了,要不,點贊或收藏或關注支持下我唄 o( ̄▽ ̄)d”
