

摘要
本項目的目標是使用深度學習來識別樂曲風格,如一首歌曲是流行樂還是搖滾樂。
我們將把樂曲特徵轉換為圖像數據,再利用 HuBERT 進行訓練,生成的模型可以存儲到你自己的 Hugging Face 帳號中。
本教程的 Jupyter 文件地址:
https://openbayes.com/console/public/tutorials/ODwKxev36xS
本教程的視頻地址:
https://www.bilibili.com/video/BV11E421w76X
運行環境
因為 AI 需要在 GPU 上運算,而一般的 PC 是沒有 GPU 的,所以我們要借用雲端的算力。
我選擇的雲端算力平台是 OpenBayes,你使用下面的鏈接進行註冊,將可以獲得免費 4 小時 RTX-4090 顯卡的使用時長。
註冊鏈接如下:
https://openbayes.com/console/signup?r=comehope_JrJj
點擊它,會出現下面的登錄界面,填寫用户名、郵箱、密碼、手機號和短信驗證碼,就可以完成註冊,如下圖所示。

克隆教程
註冊成功之後,進入到個人控制枱,在左側菜單中選擇“公共資源/公共教程”,搜索“hubert”,找到“基於 HuBERT 實現歌曲風格分類”這篇教程,如下圖所示。

打開這篇教程,點擊右上角的“克隆”按鈕,如下圖所示。

在接下來“從模板創建:基本信息”的界面中點擊“下一步:選擇算力”按鈕,如下圖所示。

所謂算力,就是顯卡類型,請選擇“RTX 4090”,這裏會顯示您獲贈的時長。再選擇鏡像類型中,選擇“TensorFlow”,然後,顯示右下角的“下一步:審核”按鈕,如下圖所示。

接下來列出了剛才選擇過的算力和鏡像,點擊右下角的“繼續執行”按鈕,如下圖所示。

接下來,系統會自動分配資源,稍待片刻,等到頁面中顯示“打開工作空間”按鈕,點擊它,就可以進入運行中的教程了,如下圖所示。

工作空間的界面如下圖所示。

接下來,運行“教程.jpynb”文件即可。以下內容與 “教程.jpynb” 的內容完全相同,建議您在 Jupyter 中運行,可以實時看到運行結果。
教程正文
在開始正文之前,需要一點準備工作。
請準備好你的 Hugging Face Token,在訓練結束之後,我們會把新模型上傳到 Hugging Face。
請安裝本教程依賴的第三方庫。
!pip install -r /openbayes/home/requirements.txt -q音頻處理的基本概念
在開始正式編碼之前,讓我們瞭解音頻文件中包含了什麼信息,以及如何使用它們。
接下來我們會討論幾個術語:
- 採樣率
- 波形圖(時域圖)
- 頻域圖
- 時頻圖
- 梅爾時頻圖
採樣率
採樣率決定了連續音頻樣本之間的時間間隔,你可以把它看作是音頻數據的時間分辨率,類似於圖片分辨率,值越高,就越清晰,數據量也就越大。
例如,對 5 秒的聲音進行採樣,當採樣率為 16,000 Hz 時,得到的數據量是 80,000 個值。
關於採樣率要注意兩點:一是要確保數據集中所有的音頻都應具用相同的採樣率;二是數據集的採樣率必須與預訓練模型的採樣率相同,否則需要先對數據集進行重採樣處理。無論執行何種音頻任務,始終保持採樣率一致都非常重要。
波形圖(時域圖)
聲音的振幅描述了某一特定時刻的聲壓級,以分貝(dB)為單位。樣本的位深度(如 8-bit 或 16-bit)決定了描述該幅度值的精度。
我們可以繪製隨時間變化的樣本值,描繪出聲音幅度的變化,這也稱為聲音的時域圖。
時域圖對於識別音頻信號的特定特徵非常有用,例如各個聲音事件的時間、信號的整體響度以及音頻中存在的任何不規則或噪聲。
我們來觀察一個小號聲音的時域圖。
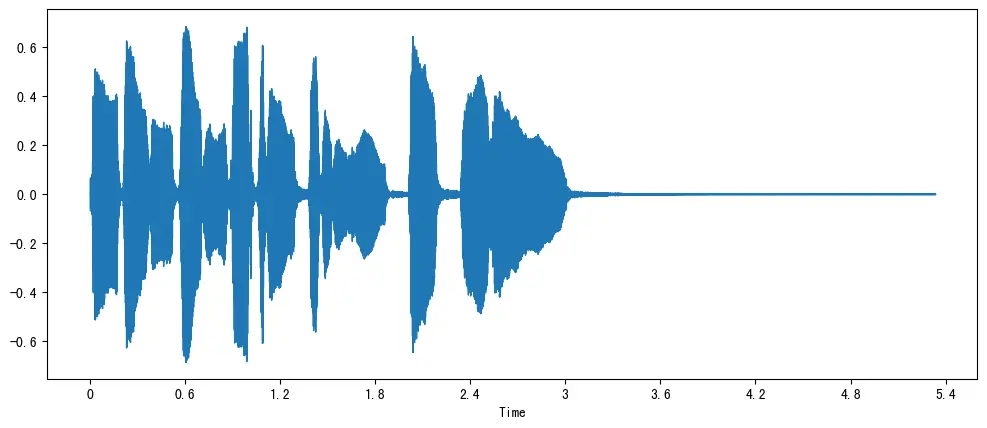
在上圖中,y 軸表示信號的幅度,x 軸表示時間,每個點對應於對該聲音進行採樣時獲取的單個樣本值。另外請注意,librosa 已將音頻的幅度映射為浮點值,並且幅度在 [-1.0, 1.0] 範圍內。
頻域圖
可視化音頻數據的另一種方法是繪製音頻信號的頻譜,也稱為頻域圖。
下圖是時域圖與頻域圖的區別。
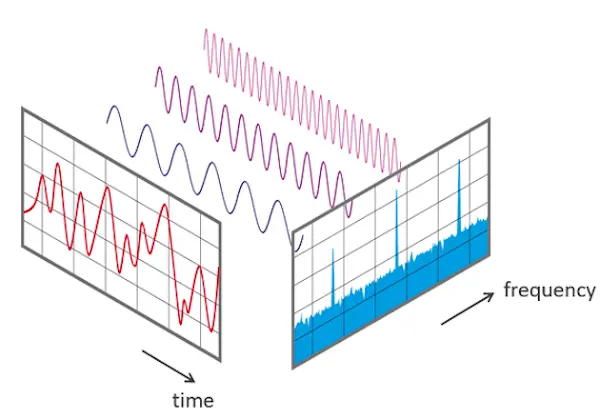
對採樣數據進行離散傅里葉變換(DFT,Discrete Fourier Transform),就能計算出聲音的頻譜,它描述了構成信號的各個頻率及其強度。
雖然可以繪製整個聲音的頻譜,但繪製一小段時間的頻譜更有利於我們觀察。在這裏,我們選擇對前 4096 個樣本進行 DFT 運算,這大約是演奏的第一個音符的長度。
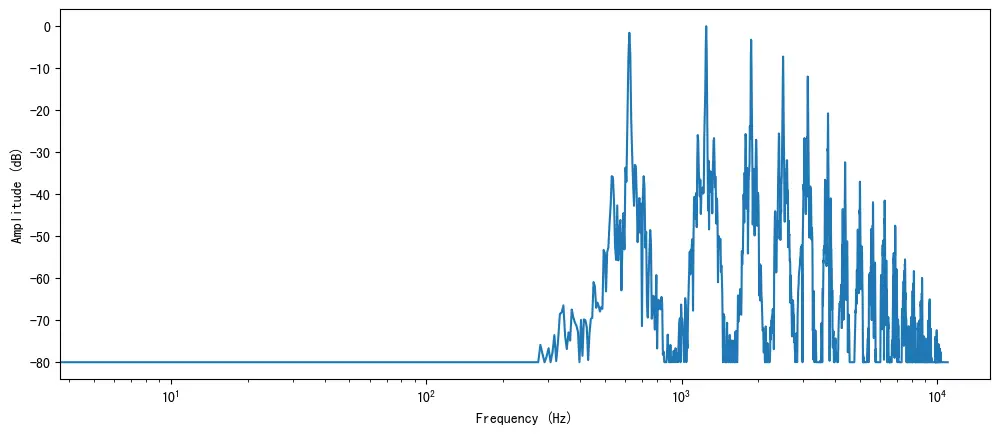
上圖繪製了該音頻片段中存在的各種頻率分量的強度。頻率值位於 x 軸上,通常以對數刻度繪製,幅度位於 y 軸上。
可以觀察到,頻域圖中顯示了幾個尖峯值。這些發音與正在演奏的音符的和聲相對應,和聲越高越安靜。
時頻圖
時域圖繪製了音頻信號隨時間變化的幅度,頻域圖顯示了一段時間內各個頻率的幅度,它是給定時刻的頻率的快照。如果我們想查看音頻信號的頻率如何隨時間而變化,該怎麼辦?解決方案是採用多個 DFT 運算,每個僅覆蓋一小部分時段(通常持續幾毫秒),並將所有小時段的頻譜疊加起來,得到時頻圖。執行此計算的算法稱為短傅立葉變換(Short Fourier Transform,STFT)。
讓我們繪製此前小號聲音的時頻圖。

在上圖中,x 軸代表時間,y 軸代表以 Hz 為單位的頻率,顏色的明度表示每個時間點頻率分量的功率幅度,以分貝 (dB) 為單位。
我們可以觀察到圖像中有多個豎直的切片,每個豎直的切片相當於前面繪製的一個頻譜圖,但是它被豎起來,並且分貝值被可視化為顏色的明度。
默認情況下,librosa.stft() 將音頻信號分割為 2048 個樣本長的小片段,在頻率分辨率和時間分辨率之間進行了良好的平衡。
由於時頻圖和時域圖是同一數據的不同視圖,因此可以使用逆 STFT 將時頻圖轉回原始波形的時域圖。 在這種情況下,我們可以使用相位重建算法(例如經典的 Griffin-Lim 算法),或使用稱為向量的神經網絡來從頻譜圖中重建波形。
梅爾時頻圖
梅爾時頻圖是語音處理和機器學習任務中常用的時頻圖的變體。它也是隨着時間的推移記錄音頻信號的頻率內容,但頻率軸有所不同,簡單地説就是頻率範圍變小了,更適合處理人類的語音。

梅爾頻段定義了一組頻率範圍,使用一組濾波器分離出這些頻率,這些被定義的頻率都在人耳敏感的頻率範圍之內。我們關心的最高頻率(以 Hz 為單位),通常是 4k 或 8k。
模型
儘管 Transformer 架構最初是設計用於處理文本數據的,但已經出現許多用 Transformer 設計的用於處理音頻數據的架構。這些模型在作為輸入的音頻數據類型和內部功能的細微差別方面可能有所不同,但總體而言,它們傾向於遵循與原始 Transformer 非常相似的方法。
在這裏,我們將使用 HuBERT,它是一種僅編碼器模型,非常適合音頻分類任務。它的主要思想是屏蔽輸入音頻的某些部分,並且訓練模型來學習如何重新預測這些被屏蔽的片段。它還使用簇集成來生成偽標籤,幫助指導預測被掩蓋部分的學習過程。
數據集
我們將使用 GTZAN 數據集,它包含 500 多個 30 秒長的音頻樣本,其中包含多種風格的音樂。
加載數據集。
from datasets import load_dataset
dataset=load_dataset('marsyas/gtzan')劃分訓練集與測試集。shuffle=True 確保採樣的數據被隨機分配到訓練集和測試集,est_size=.2 表示用 80% 的數據進行訓練,再用 20% 的數據進行評估。
然後查看其中一個訓練樣本。
dataset=dataset['train'].train_test_split(seed=42, shuffle=True, test_size=.2)
print(dataset['train'][2])
print('sampling rate: ', dataset['train'][2]['audio']['sampling_rate'])
id2label_function=dataset['train'].features['genre'].int2str
print('genre: ', id2label_function(dataset['train'][2]['genre']))我們可以看到音頻文件被表示為一維數組,其中數組的值表示該特定時間步長的幅度。 另外,這首歌曲的採樣率為 22050 Hz,風格為 disco(迪斯科)。
然後,我們需要確認一下數據集中所有樣本的採樣率是否一致。
sampling_rate_check=None
all_same=True
for set_name in ['train', 'test']:
for sample in dataset[set_name]:
sampling_rate=sample['audio']['sampling_rate']
if sampling_rate_check is None:
sampling_rate_check=sampling_rate
else:
if sampling_rate !=sampling_rate_check:
all_same=False
break
if all_same:
print(f'All samples have the same sampling rate')
else:
print('The samples in the dataset have different sampling rates')我們再數數不同標籤的樣本數量。
import plotly.express as px
paper_color='#f5f7f6'
bg_color='#f5f7f6'
colormap='cividis'
labels={}
def count_genres(dataset):
for sample in dataset:
genre_label=id2label_function(sample['genre'])
if genre_label in labels:
labels[genre_label]+=1
else:
labels[genre_label]=1
count_genres(dataset['train'])
count_genres(dataset['test'])
genres=list(labels.keys())
counts=list(labels.values())
for index, g in enumerate(genres):
print(counts[index], g)可以看到,除了爵士樂有 99 個樣本,其他每個風格都有 100 個樣本。
處理數據,以備訓練
與 NLP(自然語言處理)中的標記化過程類似,音頻模型要求輸入給模型的數據以模型可以理解的格式進行編碼。我們將使用 AutoFeatureExtractor,它可以有效地為任何給定模型選擇正確的特徵提取器。
from transformers import AutoFeatureExtractor
import os
os.environ['MODEL']='ntu-spml/distilhubert'
feature_extractor=AutoFeatureExtractor.from_pretrained(os.getenv('MODEL'), do_normalize=True, return_attention_mask=True)檢測一下模型的採樣率:
sampling_rate=feature_extractor.sampling_rate
print(f'DistilHuBERT Sampling Rate: {sampling_rate} Hz')然後,用模型的採樣率對數據集數據進行編碼。
讀取每一個音頻文件的前 30 秒。編碼的結果保存在 dataset_encode 中。
max_duration=30.0
def preprocess_function(examples):
audio_arrays=[x['array'] for x in examples['audio']]
inputs=feature_extractor(audio_arrays, sampling_rate=sampling_rate, max_length=int(sampling_rate*max_duration), truncation=True, return_attention_mask=True)
return inputs
dataset_encoded=dataset.map(preprocess_function, remove_columns=['audio', 'file'], batched=True, batch_size=100, num_proc=1)
dataset_encoded再按照 Trainer 類的要求,把標籤列重命名為 label。
dataset_encoded=dataset_encoded.rename_column('genre', 'label')
dataset_encoded把歌曲風格標籤從整型映射為字符串,反之亦然。
id2label={str(i): id2label_function(i) for i in range(len(dataset_encoded['train'].features['label'].names))}
label2id={v:k for k, v in id2label.items()}
print(label2id)訓練
加載模型。
from transformers import AutoModelForAudioClassification
num_labels=len(id2label)
model=AutoModelForAudioClassification.from_pretrained(os.getenv('MODEL'),num_labels=num_labels, label2id=label2id, id2label=id2label)定義評價指標為準確度 accuracy。
import evaluate
metric=evaluate.load('accuracy')
def compute_metrics(eval_pred):
predictions=np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)定義訓練參數。
from transformers import TrainingArguments
training_args=TrainingArguments(
output_dir='ft-hubert-on-gtzan',
evaluation_strategy='epoch',
save_strategy='epoch',
load_best_model_at_end=True,
metric_for_best_model='accuracy',
learning_rate=5e-5,
seed=42,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
max_steps=100,
num_train_epochs=2,
warmup_ratio=0.1,
fp16=True,
save_total_limit=2,
run_name='ft-hubert-on-gtzan'
)開始訓練,在 RTX 4090 上大約需要10分鐘。
from transformers import Trainer
trainer=Trainer(model=model, args=training_args, train_dataset=dataset_encoded['train'], eval_dataset=dataset_encoded['test'], tokenizer=feature_extractor, compute_metrics=compute_metrics)
trainer.train()把訓練好的新模型推送到 Hugging Face,以後就可以直接使用這個模型了。
你需要用你自己的 Hugging Face Token 替換下面的 token 變量字符串,以便用你自己的身份登錄。
from huggingface_hub import login
token = "your_hugging_face_token"
login(token)
kwargs={
'tasks': 'audio-classification'
}
trainer.push_to_hub(**kwargs)推理
現在,把我們在 suno 上創作的兒歌《小毛驢》交給模型來推理吧。
《小毛驢》
我有一隻小毛驢我從來也不騎
有一天我心血來潮騎着去趕集
我手裏拿着小皮鞭我心裏正得意
不知怎麼嘩啦啦啦我摔了一身泥注意,輸出的結果是不同風格的概率分佈,概率最高的風格排在最前面。
下面定義一個管道來實現對模型的調用,你應該把 your_hugging_face_username 換成你的 Hugging Face 用户名。
from transformers import pipeline
your_hugging_face_username = 'comehope'
pipe=pipeline(kwargs['tasks'], model=your_hugging_face_username + '/ft-hubert-on-gtzan')其中一首改編樂曲:
array, sampling_rate = librosa.load("xiaomaolv-1.mp3")
Audio(data=array, rate=sampling_rate)推理它的曲風:
pipe("xiaomaolv-1.mp3")是不是很有意思?
你也來試試吧。
記得使用我的註冊鏈接哦,可以獲得免費 4 小時 4090 時長呢~
https://openbayes.com/console/signup?r=comehope_JrJj