

第4章網絡層:數據平面

4.1 導論
4.1.1 章節定位:從網絡 “邊緣” 到 “核心”
(1)網絡分層學習的過渡
- 前序章節(1-3 章):聚焦網絡 “邊緣”,覆蓋應用層(HTTP、DNS)、傳輸層(TCP、UDP),核心是端系統間的進程通信(如瀏覽器與 Web 服務器的交互);
- 本章(第 4 章)+ 第 5 章:進入網絡 “核心”,聚焦網絡層,核心是主機到主機的分組交付(如主機 A 經多台路由器到主機 B);
- 教材版本差異:本版教材將網絡層拆分為數據平面(第 4 章) 與控制平面(第 5 章),前版教材未拆分(將兩者合併講解),這是本版的最大區別。
(2)導論的角色
導論作為第 4 章的開篇,核心是 “建立網絡層數據平面的基礎認知”,為後續 4.2(路由器組成)、4.3(IP 協議)、4.4(SDN)的學習鋪墊框架性理解。
4.1.2 導論的核心學習目標

導論需達成的 4 個核心目標,也是本章數據平面的學習基礎:
- 理解網絡層數據平面的基本原理,明確 “數據平面” 與 “控制平面” 的定義及區別;
- 掌握網絡層向上層(傳輸層)提供的核心服務(主機到主機的分組交付);
- 區分網絡層的兩大功能 —— 轉發(數據平面)與路由(控制平面),理解兩者的配合關係;
- 初步認識網絡層服務模型(如 “盡力而為”),瞭解不同網絡架構的服務差異(如 IP vs ATM)。
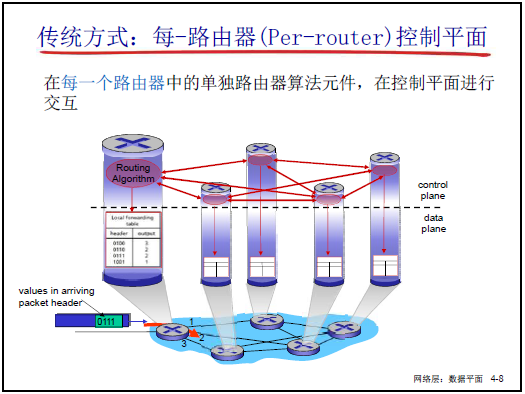
4.1.3 核心概念:數據平面與控制平面
數據平面與控制平面是網絡層的兩大核心組成,課件 4-7 通過 “本地執行” 與 “全局決策” 的邏輯明確兩者差異,結合老師的講解補充如下:
| 維度 | 數據平面(Data Plane) | 控制平面(Control Plane) |
|---|---|---|
| 課件對應 | 課件 4-7 “數據平面” 模塊 | 課件 4-7 “控制平面” 模塊 |
| 功能定位 | 本地執行功能:單台網絡設備(如路由器)對到來的分組做 “入 - 出” 轉發,核心是 “怎麼轉” | 全局決策功能:規劃 “源主機到目標主機” 的端到端路徑,核心是 “轉哪條” |
| 作用範圍 | 僅單台網絡設備(如 1 台路由器) | 整個網絡(跨多台路由器、端系統) |
| 核心依賴 / 輸出 | 依賴 “路由表(傳統)/ 流表(SDN)”,輸出 “轉發動作”(如從端口 2 轉發) | 輸出 “路由表 / 流表”,為數據平面提供轉發決策依據 |
| 老師舉例 | 路由器插 3 塊網卡(以太網、ATM、幀中繼):接收以太網幀→解封裝到網絡層→查目標 IP→從幀中繼端口轉發 | 春遊去植物園選路線:規劃 “五里墩 / 黃山路 / 南二環” 的全局路徑,而非單個路口的轉彎 |
| 實現方式 | 傳統:IP 協議按目標 IP 查路由表;SDN:按多字段查流表 | 傳統:路由器分佈式交互路由信息(如 OSPF);SDN:遠程控制器集中計算路徑 |
4.1.4 網絡層兩大核心功能:轉發(數據平面)與路由(控制平面)

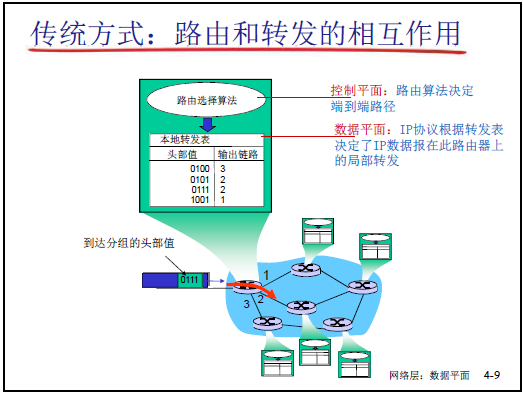
(1)轉發(Forwarding):數據平面的核心動作
- 定義:單台網絡設備(如路由器)從 “入端口” 接收分組,通過查 “轉發表 / 流表”,選擇 “出端口” 將分組轉發出去的局部功能,不關心端到端路徑;
- 老師補充例子(修正後):路由器插 3 塊網卡(以太網、ATM、幀中繼),接收以太網幀後:
- 數據鏈路層解封裝,提取 IP 分組;
- 網絡層提取目標 IP 地址,查本地路由表;
- 確定從幀中繼網卡轉發,將 IP 分組封裝為幀中繼幀;
- 從幀中繼端口發送到下一跳;
- 傳統轉發 vs SDN 轉發:
- 傳統轉發:僅依賴 IP 分組的目標 IP 地址,查 “轉發表”,動作只有 “轉發”;
- SDN 轉發:依賴多字段(源 MAC、目標 IP、源端口等),查 “流表”,動作可包括轉發、Block、修改字段等。
(2)路由(Routing):控制平面的核心動作
- 定義:規劃 “源主機到目標主機” 的全局路徑(如 “主機 A→路由器 1→路由器 3→主機 B”),通過路由算法生成 “路由表 / 流表” 的功能;
- 老師類比:路由相當於 “春遊前規劃去植物園的整體路線”,轉發相當於 “到五里墩路口後選擇左轉 / 右轉的局部動作”;
- 傳統路由實現:
- 每台路由器運行路由協議(如 RIP、OSPF),與其他路由器分佈式交互路由信息(如 “我到主機 A 的距離是 2 跳”);
- 通過路由算法(如最短路徑算法)計算最優路徑;
- 生成 “本地轉發表”,下發到數據平面用於轉發。
(3) 轉發與路由的四種組合

轉發與路由各有 “傳統方式” 和 “SDN 方式”,共 4 種組合(導論僅分類,不深入細節):
- 傳統轉發 + 傳統路由(互聯網主流):IP 協議查路由錶轉發,路由表由分佈式協議生成;
- 傳統轉發 + SDN 路由:SDN 控制器生成路由表,設備按傳統方式(目標 IP)轉發;
- SDN 轉發 + 傳統路由:設備按多字段查流錶轉發,流表由傳統路由協議生成;
- SDN 轉發 + SDN 路由(新型核心):控制器集中生成流表,設備多字段匹配 + 多動作轉發。
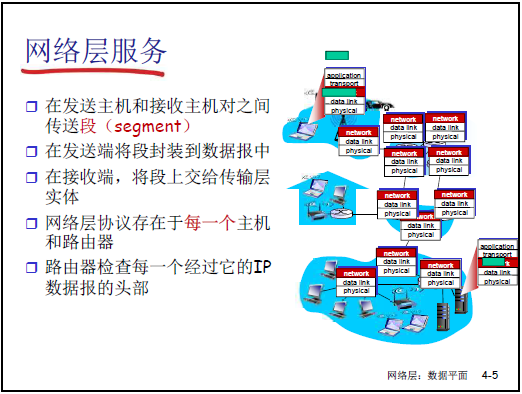
4.1.5 網絡層向上層提供的核心服務:主機到主機的分組交付
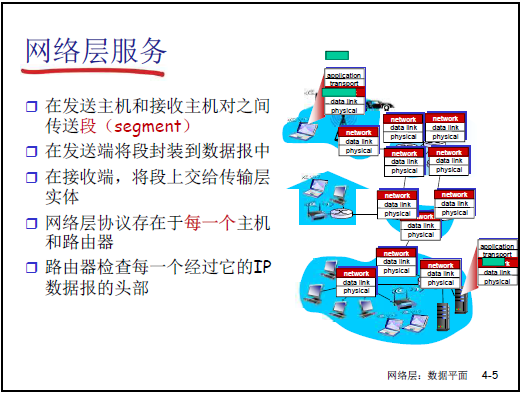
網絡層的核心服務是 “主機到主機的分組交付”,流程如下:
(1)服務流程
- 發送端封裝:傳輸層(TCP 段 / UDP 數據報)→ 交給網絡層→ IP 協議封裝為IP 數據報(添加源 IP、目標 IP、TTL 等頭部);
- 網絡核心轉發:每台路由器接收幀→ 解封裝到網絡層→ 查路由表 / 流表→ 重新封裝為下一跳物理網絡的幀(如 ATM 幀→以太網幀);
- 接收端解封裝:目標主機解封裝 IP 數據報→ 提取 TCP 段 / UDP 數據報→ 交給傳輸層,最終交付應用層。
(2)服務的兩個關鍵特性
- 服務範圍:主機到主機(Host-to-Host),區別於傳輸層的 “進程到進程”(如 TCP 的進程通信);
- 協議實體分佈:每台主機、每台路由器中均包含網絡層協議實體(如 IP 模塊)—— 主機的 IP 模塊負責封裝 / 解封裝,路由器的 IP 模塊負責轉發;
- 逐跳解封裝:IP 數據報在傳輸過程中,每經過一台路由器都要 “解封裝(幀→IP)→轉發→重新封裝(IP→新幀)”,僅目標主機完成最終解封裝(IP→TCP/UDP)。
4.1.6 網絡層服務模型:基於指標的標準化服務
(1) 服務模型的定義

服務模型是 “網絡層向上層提供服務的標準化描述”—— 當 “可靠性、延遲、保序性、帶寬” 等服務指標取特定值時,形成的固定服務類型(如 “盡力而為”“恆定帶寬”)。
課件 4-11 明確服務指標分為兩類:
- 針對單個數據報:可靠性(是否不丟失 / 不出錯)、延遲保障(是否≤40ms);
- 針對系列數據報(如視頻流):保序性(接收順序與發送順序一致)、帶寬保障(是否固定 10Mbps)、延遲差(系列分組的延遲差值,延遲差 = 0 適配多媒體)。
(2) 典型服務模型對比
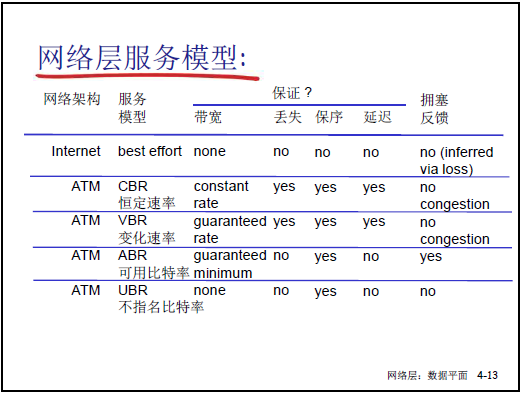
通過表格對比 IP、ATM 的服務模型,結合老師的講解補充如下:
| 網絡架構 | 服務模型 | 帶寬保障 | 丟失保障 | 保序保障 | 延遲保障 | 擁塞反饋 |
|---|---|---|---|---|---|---|
| Internet | 盡力而為(Best Effort) | 無 | 無 | 無 | 無 | 無(通過丟失推斷) |
| ATM | CBR(恆定比特率) | 恆定速率(如 64kbps) | 有 | 有 | 有 | 無 |
| ATM | VBR(可變比特率) | 保障最小速率 | 有 | 有 | 有 | 無 |
| ATM | ABR(可用比特率) | 保障最小速率 | 無 | 有 | 無 | 有 |
| ATM | UBR(未指定比特率) | 無 | 無 | 有 | 無 | 無 |
① IP 的 “盡力而為” 模型(重點)
- 核心特點:所有指標均無保障,是 “委婉的稱呼”(老師類比:“老闆交辦任務説‘盡力而為’,實際不承諾結果”);
- 實際表現:無帶寬 / 丟包 / 保序 / 延遲保障,不向主機反饋擁塞狀態,是互聯網的基礎服務模型。
② ATM 的有保障模型(對比案例)
ATM 是 “有連接” 的網絡層技術,明確其 4 類模型均比 IP 的 “盡力而為” 更具保障,如 CBR 適合語音傳輸(恆定帶寬),ABR 適合彈性業務(動態調整帶寬)。
4.1.7 關鍵區分:網絡層 “有連接” 與傳輸層 “面向連接”

強調兩者的核心差異在於 “是否涉及中間路由器”,補充如下:
| 連接類型 | 網絡層 “有連接”(如 ATM) | 傳輸層 “面向連接”(如 TCP) |
|---|---|---|
| 課件對應 | 課件 4-12 “網絡層連接” 模塊 | 課件 4-12 “傳輸層連接” 模塊 |
| 涉及設備 | 源主機、目標主機 + 中間所有路由器 | 僅源主機、目標主機(中間路由器無連接狀態) |
| 狀態維護 | 所有設備維護 “連接狀態”(如 ATM 的虛電路表) | 僅端系統維護 “連接狀態”(如 TCP 的 TCB) |
| 老師舉例 | ATM 網絡:通信前建立虛電路,路徑上所有路由器維護虛電路表 | TCP 三次握手:僅主機 A 和主機 B 維護連接狀態,路由器僅轉發 IP 分組 |
| 核心差異 | 連接覆蓋 “端到端 + 中間節點”,是 “主機到主機” 的連接 | 連接僅覆蓋 “端到端”,是 “進程到進程” 的連接 |
導論核心總結
導論作為第 4 章的開篇,核心是建立 “數據平面” 的基礎框架,關鍵結論如下:
- 網絡層分為數據平面(本地轉發)和控制平面(全局路由),本版教材拆分講解是核心差異;
- 轉發是數據平面的核心,依賴路由表 / 流表;路由是控制平面的核心,生成轉發決策依據;
- 網絡層服務是 “主機到主機的分組交付”,IP 的 “盡力而為” 是互聯網的基礎服務模型;
- 網絡層 “有連接” 與傳輸層 “面向連接” 的本質區別是 “是否涉及中間路由器”。
4.2 路由器組成
4.2.1路由器結構概況
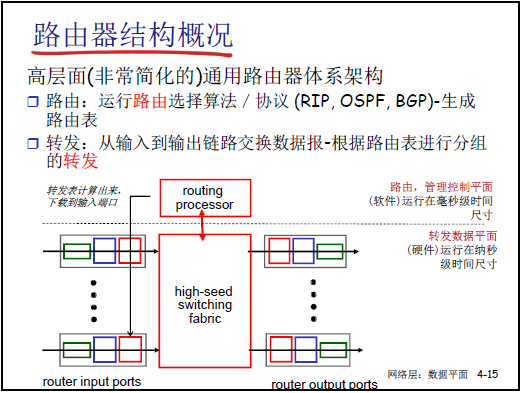
(1)核心架構與功能分工
- 高層面通用架構:路由器核心分為控制平面與數據平面,二者通過 “路由表” 銜接,配合輸入端口、輸出端口與高速交換機構(high-speed switching fabric)完成分組轉發。
- 控制平面(軟件實現,毫秒級響應):由路由處理器(processor routing)運行路由選擇算法 / 協議(如 RIP、OSPF、BGP),計算並生成路由表,最終將路由表下載到所有輸入端口的網絡層模塊。
- 數據平面(硬件實現,納秒級響應):基於輸入端口接收的路由表,將輸入端口的分組通過交換機構轉發到合適的輸出端口,完成 “局部轉發”(單個路由器內的分組交換)。
- 補充細節:
- 實際路由器的 “輸入端口” 與 “輸出端口” 是整合的(同一物理端口可雙向傳輸),在此中分開講解是為了簡化原理;
- 多個路由器的 “局部轉發” 通過鏈路串聯,最終實現源主機到目標主機的端到端分組交付。
4.2.2輸入端口功能
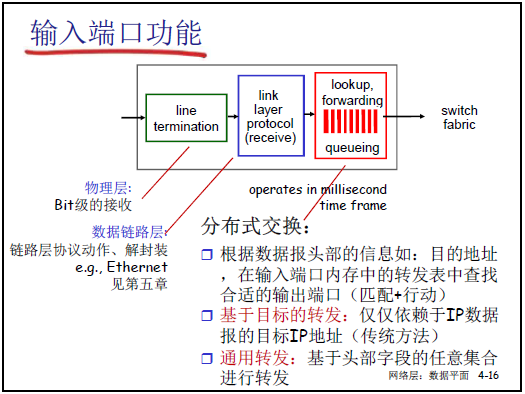
(1)分層功能實現(從物理層到網絡層)
輸入端口是分組進入路由器的 “第一站”,需完成物理層接收、鏈路層解封裝、網絡層轉發決策,具體流程如下:
| 分層 | 功能描述(課件核心內容) | 補充細節 |
|---|---|---|
| 物理層 | 完成 “比特級接收”(line termination),將鏈路上的物理信號(電磁波 / 光信號)轉換為數字信號(0/1)。 | 轉換粒度可為 “比特” 或 “字(word)”,取決於物理編碼方式。 |
| 數據鏈路層 | 執行鏈路層協議動作(如以太網解封裝),校驗幀完整性(如 CRC),判斷幀的目標 MAC 地址是否匹配本端口,提取幀中封裝的 IP 分組。 | 若目標 MAC 不匹配,直接丟棄幀;僅提取匹配幀的數據部分(即 IP 分組)交給網絡層。 |
| 網絡層 | 基於分組頭部信息(如目標 IP 地址),在輸入端口內存的轉發表中執行 “匹配 + 行動”,確定轉發到的輸出端口。 | 傳統轉發僅依賴 “目標 IP 地址”,SDN 通用轉發可基於頭部多字段(如源 MAC、TCP 端口);分組需先在隊列(queueing)中排隊,等待轉發決策。 |
4.2.3基於目標的轉發與最長前綴匹配(對應課件圖 4-17、4-19、4-20)
(1)基於目標的轉發(傳統方式)
-
轉發表結構(課件圖 4-17):轉發表通過 “目標地址範圍” 關聯 “輸出接口”,示例如下:
-
問題:若地址範圍劃分不規整,可能導致匹配歧義(如分組地址同時落在多個範圍)。

(2)最長前綴匹配(解決歧義的核心機制)
-
定義:查找轉發表時,選擇與分組目標地址 “前綴重疊最長” 的表項,確保匹配唯一。轉發表示例優化如下:
-
硬件支持:採用 TCAMs(三態內容可尋址存儲器)實現,可在 1 個時鐘週期內完成檢索,不受表項數量影響(如 Cisco Catalyst 系列路由器可存儲約 1 百萬條路由表項)。
-
舉例驗證:
- 分組目標地址(DA)1:11001000 00010111 00010110 10100001 → 匹配前綴 “00010****”,轉發到接口 0;
- 分組目標地址(DA)2:11001000 00010111 00011000 10101010 → 匹配前綴 “00011000 ****”,轉發到接口 1。


(3)輸入端口緩存與頭端阻塞
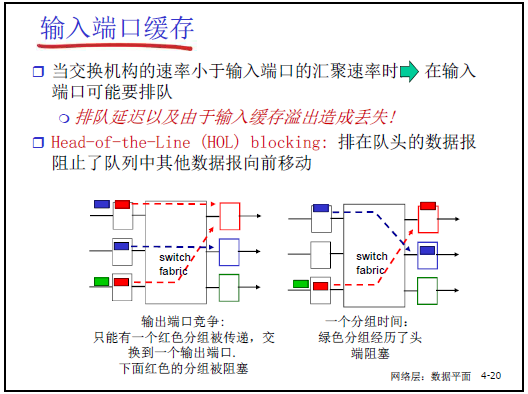
- 緩存必要性:當交換機構的速率<輸入端口的匯聚速率時,輸入端口需通過緩存(隊列)暫存分組,避免因 “瞬時速率不匹配” 導致分組丟失(如 “雙十一” 期間大量分組向 “天貓方向” 轉發,輸入速率驟增)。
- 頭端阻塞(Head-of-the-Line, HOL):
- 定義:若隊列頭部的分組因目標輸出端口繁忙無法轉發,會阻塞隊列中後續所有分組(即使後續分組的目標輸出端口空閒)。
- 示例:課件圖中 “綠色分組” 目標端口空閒,但因 “紅色分組”(隊頭)阻塞,無法提前轉發;若緩存溢出,後續分組會被丟棄(這是分組丟失的常見原因之一)。
4.2.4交換機構(對應課件圖 4-21、4-22、4-23、4-24)
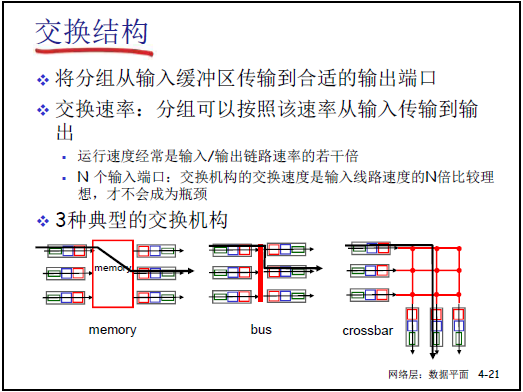
交換機構是連接輸入端口與輸出端口的 “橋樑”,核心功能是將輸入端口緩存的分組傳輸到目標輸出端口,需滿足 “交換速率≥N 倍輸入 / 輸出鏈路速率”(N 為輸入端口數量),避免成為性能瓶頸。課件中定義了 3 種典型交換機構:
(1)基於內存的交換
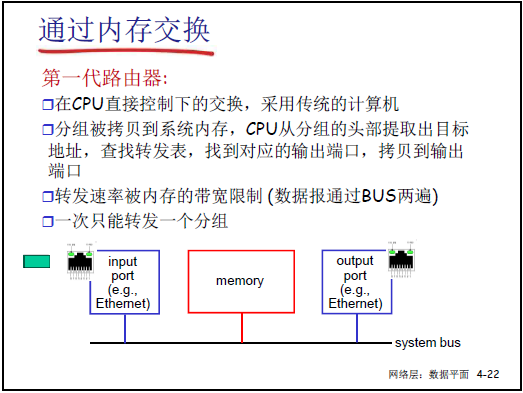
- 架構:採用傳統通用計算機實現,分組需通過系統總線(system bus)在 “輸入端口→內存→CPU→內存→輸出端口” 之間傳輸。
- 工作流程:
- 輸入端口將分組拷貝到系統內存;
- CPU 從分組頭部提取目標地址,查詢路由表確定輸出端口;
- CPU 將分組從內存拷貝到輸出端口。
- 特點與侷限:
- 是 “第一代路由器” 的實現方式(如思科早期產品),依賴軟件轉發;
- 瓶頸:分組需過系統總線 2 次,轉發速率受內存帶寬限制,一次僅能轉發 1 個分組。
- 補充:互聯網第一台路由器由麻省理工團隊用通用計算機軟件實現,後續衍生出思科公司;但該方式因速率低,僅適用於早期小規模網絡。
(2)基於總線的交換

- 架構:輸入端口與輸出端口共享一條高速總線(bus),分組通過總線直接從輸入端口傳輸到輸出端口(無需經過 CPU / 內存)。
- 工作流程:
- 輸入端口在分組頭部添加 “目標輸出端口地址”;
- 分組通過總線廣播,所有輸出端口監聽總線;
- 僅目標輸出端口接收分組,其他端口丟棄分組。
- 特點與應用:
- 優勢:分組僅過總線 1 次,轉發速率遠高於 “基於內存的交換”;
- 速率示例:Cisco 1900(1Gbps 總線)、Cisco 5600(32Gbps 總線);
- 侷限:總線存在競爭,速率受總線帶寬限制;適用於接入網、企業網路由器,不適用於骨幹網。
(3)基於互聯網絡(Crossbar / 榕樹網)的交換
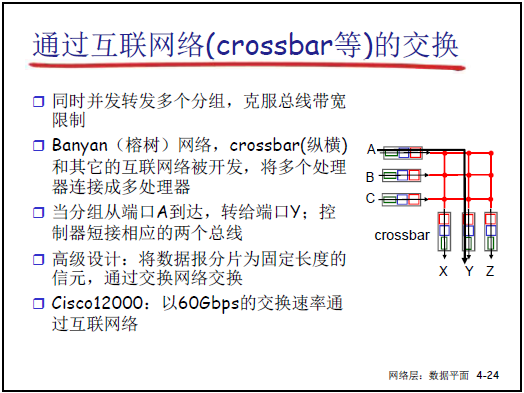
- 架構:採用 Crossbar(縱橫交叉開關)或 Banyan(榕樹網)結構,可同時併發轉發多個分組(每個交叉節點可獨立控制通斷)。
- 工作流程:
- 分組從輸入端口到達後,控制器控制對應交叉節點 “短接”(如端口 A→Y、端口 B→Z 可同時通斷);
- 高級設計:將變長分組分割為固定長度的 “信元”,確保通過交換網絡的時間一致,簡化調度。
- 特點與應用:
- 優勢:無總線競爭,支持併發轉發,交換速率極高;
- 速率示例:Cisco 12000 系列(60Gbps 及以上交換速率);
- 適用場景:互聯網骨幹路由器,可應對大規模高帶寬分組轉發需求。
4.2.5輸出端口(對應課件圖 4-25、4-26、4-27)
(1)輸出端口功能
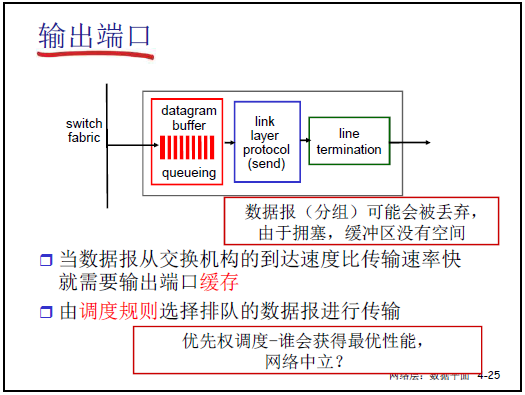
輸出端口是分組離開路由器的 “最後一站”,需完成 “分組緩存→鏈路層封裝→物理層發送”,具體流程如下:
| 分層 | 功能描述(課件核心內容) | 老師補充細節 |
|---|---|---|
| 網絡層 | 接收交換機構轉發的分組,在數據報緩存(datagram buffer)中排隊,由調度規則選擇分組發送順序。 | 排隊原因:多個輸入端口同時向同一輸出端口轉發,導致 “輸入速率>輸出速率”(如多用户同時訪問天貓,輸出端口帶寬不足)。 |
| 鏈路層 | 執行鏈路層協議(發送端),將 IP 分組封裝為幀(添加幀頭 / 幀尾、源 MAC 地址、目標 MAC 地址、CRC 校驗碼)。 | 封裝需符合鏈路類型(如以太網),下一章會詳細講解鏈路層協議(如接入控制、CRC 計算)。 |
| 物理層 | 將幀的數字信號轉換為物理信號(電磁波 / 光信號),通過鏈路發送到下一個路由器 / 主機。 | 轉換粒度可為 “比特” 或 “字”,需與鏈路的物理編碼方式匹配。 |
(2)輸出端口排隊
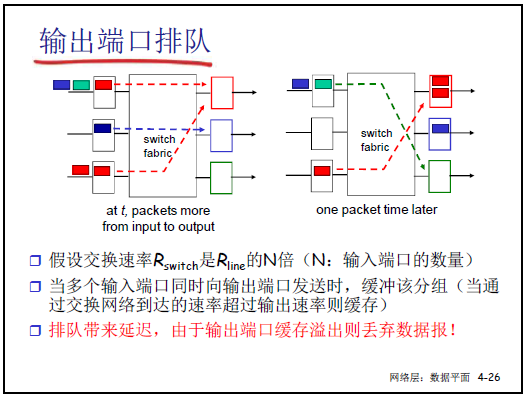
- 排隊原因:即使交換速率是鏈路速率的 N 倍(N 為輸入端口數),當多個輸入端口向同一輸出端口併發轉發時,分組到達速率仍可能超過輸出端口的傳輸速率,需通過緩存排隊。
- 後果:排隊會產生 “排隊延遲”;若緩存溢出,後續到達的分組會被丟棄(這是分組丟失的另一常見原因,如 “訂單發送後天貓未收到” 可能是分組在此處丟失)。
(3)緩存大小計算

-
RFC 3439 拇指規則(經驗公式):平均緩存大小 = 典型 RTT(往返時間,如 250ms)× 鏈路容量 C。
示例:10Gbps 鏈路的緩存大小 = 250ms × 10Gbps = 2.5Gbit。
-
優化公式(多流場景):當網絡存在 N(極大)個流時,緩存大小 = (RTT×C)/√N,避免緩存過大導致分組超時(如緩存 80T 會使分組排隊到 “訂單超時”,用户重複發送)。
4.2.6調度機制
調度機制的核心是 “選擇隊列中下一個要傳輸的分組”,需兼顧 “公平性” 與 “服務質量(QoS)”,課件中定義了 4 類典型調度策略:
(1)FIFO(先入先出)調度

- 規則:嚴格按照分組到達順序發送(“先來先傳”),是最基礎的調度方式。
- 丟棄策略:當緩存滿時,選擇以下方式丟棄分組:
- Tail Drop(尾丟棄):丟棄剛到達的分組(“誰後到誰丟”);
- Priority(按優先級丟棄):丟棄優先級低的分組(如保留 VIP 用户分組,丟棄普通用户分組);
- Random(隨機丟棄):隨機選擇一個分組丟棄(“拼人品”,避免單一分組持續被丟棄)。
- 舉例:日常 “排隊打飯” 本質是 FIFO,但緩存滿時若按 “尾丟棄”,晚到的訂單分組會丟失。
(2)優先權調度
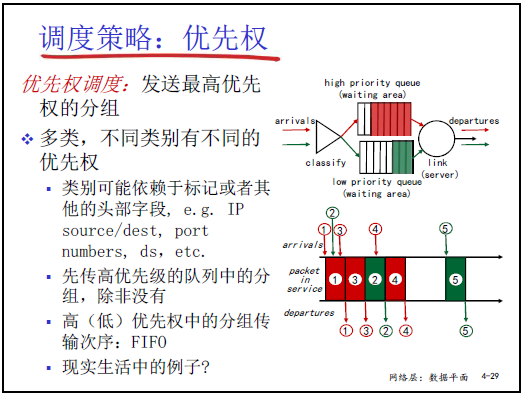
- 規則:
- 將分組按 “優先級” 分為多類(如實時多媒體分組為高優先級,Telnet 分組為低優先級);
- 優先發送高優先級隊列的分組(“有高優先級就不傳低優先級”),同一優先級隊列內按 FIFO 順序發送。
- 優先級劃分依據:可基於分組頭部字段(如 IP 地址、TCP 端口號、DS 標誌位),具體標記方式屬於 “高級計算機網絡” 內容(研究生階段講解)。
- 舉例:網絡中 “視頻通話分組”(高優先級)優先於 “文字聊天分組”(低優先級),確保視頻流暢。
(3) Round Robin(RR,輪轉調度)
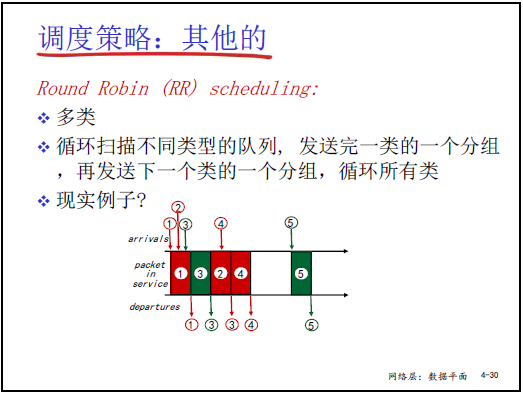
- 規則:
- 將分組分為多類(如紅、綠、藍三類);
- 循環掃描各類隊列,每類隊列每次發送 1 個分組(“紅→綠→藍→紅→綠→藍”)。
- 特點:保證各類分組 “公平輪轉”,避免單一類別長期佔用鏈路。
- 類比:類似針式打印機的 “色帶輪轉”(打完一個位置後移到下一個,避免色帶局部磨損),確保每類分組都有發送機會。
(4)Weighted Fair Queuing(WFQ,加權公平隊列)
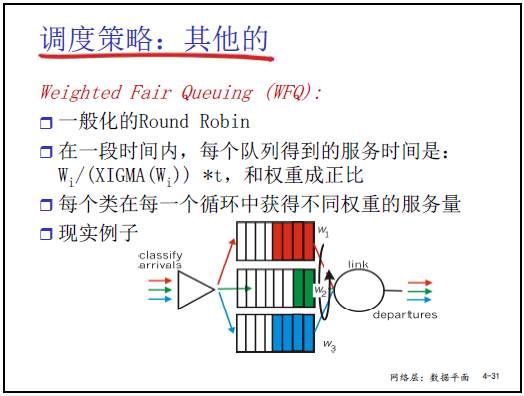
- 規則:
- 為每類分組分配 “權重 W_i”(如紅類 20%、綠類 50%、藍類 30%,總和為 100%);
- 在時間 t 內,第 i 類隊列獲得的服務時間 = (W_i / ΣW_i) × t,即按權重分配鏈路帶寬。
- 舉例:若鏈路帶寬為 1Mbps,紅類(20% 權重)獲 200kbps、綠類(50%)獲 500kbps、藍類(30%)獲 300kbps,既保證公平又支持差異化服務(如綠類對應核心業務,分配更多帶寬)。
4.3 IP: Internet Protocol 總結
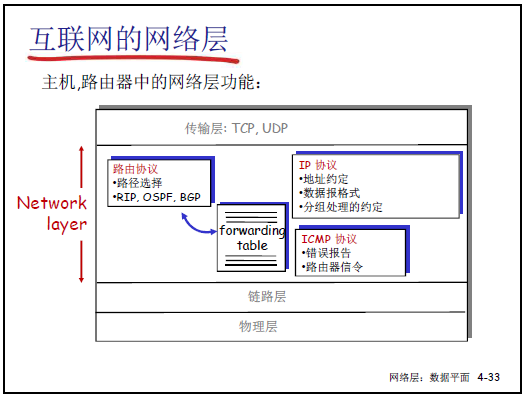
4.3.1 IP 數據報格式
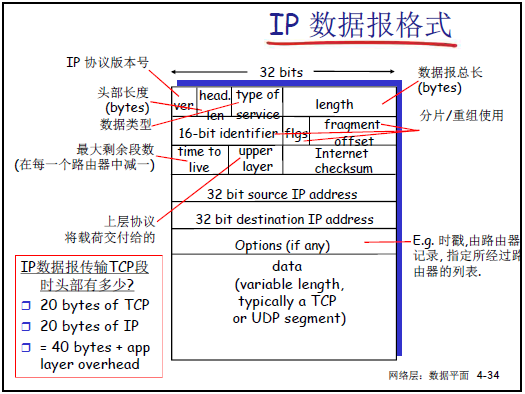
-
頭部結構(32 位為單位):
-
包含 IP 協議版本號(如 IPv4 為 4)、頭部長度(單位為 4 字節塊)、數據報總長度(頭部 + 數據,最大 65535 字節)、服務類型(Type of Service,用於 QoS 相關標識)。
-
分片 / 重組字段:16 位標識(同一數據報分片標識相同)、3 位標誌(最低位表是否還有分片,0 為最後一片)、13 位偏移量(分片在原數據報中的位置,以 8 字節為單位)。
-
其他核心字段:生存時間(TTL,每經過路由器減 1,為 0 則丟棄)、16 位頭部校驗和(驗證頭部完整性)、32 位源 IP 地址、32 位目的 IP 地址、上層協議字段(指示數據部分交付給 TCP/UDP 等上層協議)。
-
可選字段(Options):如時間戳、指定必經路由器列表,長度可變(0-40 字節)。
-
-
數據部分:通常為 TCP 或 UDP 段,整體構成 IP 數據報載荷。
4.3.2 IP 分片和重組
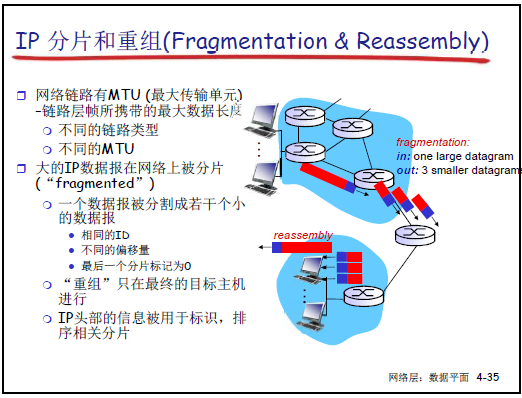
(1)核心背景
-
MTU(最大傳輸單元):鏈路層幀可攜帶的最大數據長度,不同鏈路類型 MTU 不同(如以太網 MTU 通常 1500 字節)。
-
當 IP 數據報長度超過鏈路 MTU 時,需在路由器進行分片,重組僅在最終目標主機完成(路由器不重組分片)。
(2)分片示例

-
原數據報:4000 字節(20 字節頭部 + 3980 字節數據),MTU=1500 字節。
-
第一片:20 字節頭部 + 1480 字節數據,總長度 1500 字節,標識 = x,標誌 = 1(有後續分片),偏移量 = 0。
-
第二片:20 字節頭部 + 1480 字節數據,總長度 1500 字節,標識 = x,標誌 = 1,偏移量 = 1480/8=185。
-
第三片:20 字節頭部 + 1020 字節數據(3980-1480-1480=1020),總長度 1040 字節,標識 = x,標誌 = 0(最後一片),偏移量 = 2960/8=370。
-
4.3.3 IPv4 地址
(1)IP 編址導論
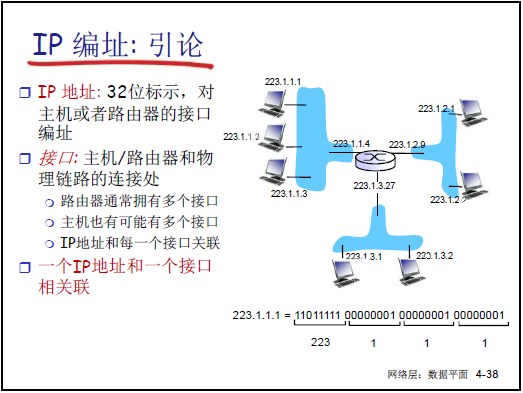
-
IP 地址為 32 位二進制數,用於標識主機或路由器的接口(而非設備):
-
路由器通常有多個接口,每個接口對應一個 IP 地址;主機可能有多個接口(如有線 + 無線),每個接口也對應一個 IP 地址。
-
示例:接口 IP =223.1.1.1(二進制 11011111 00000001 00000001 00000001),通過接口連接物理鏈路(如以太網、WiFi)。
-
(2)子網(Subnets)與子網掩碼
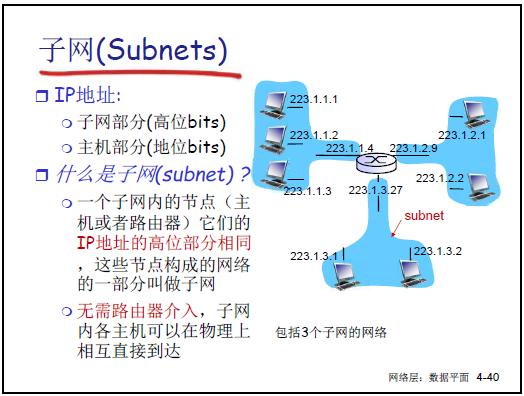
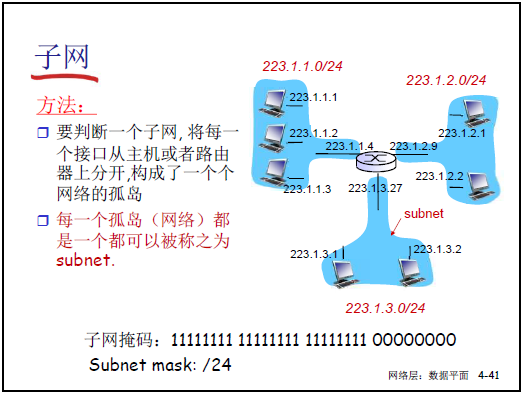
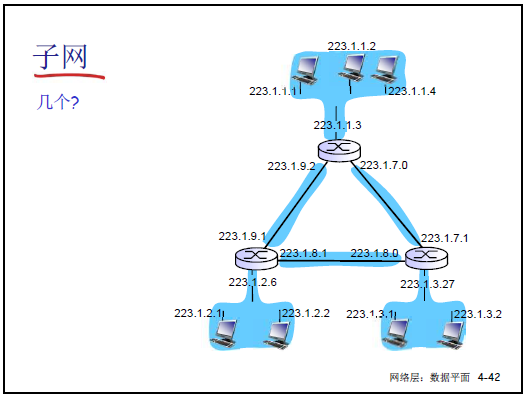
-
子網定義:IP 地址高位(子網部分)相同的節點(主機 / 路由器)集合,子網內節點無需路由器可直接通信。
-
子網表示:如 [223.1.1.0/24](CIDR 表示法,“/24” 表前 24 位為子網部分),對應子網掩碼 [255.255.255.0](二進制 11111111 11111111 11111111 00000000)。
-
子網掩碼作用:32 位二進制,“1” 對應 IP 地址的子網部分,“0” 對應主機部分;通過 “IP 地址 & 子網掩碼” 可提取子網號,用於路由匹配。
(3)IP 地址分類與特殊地址
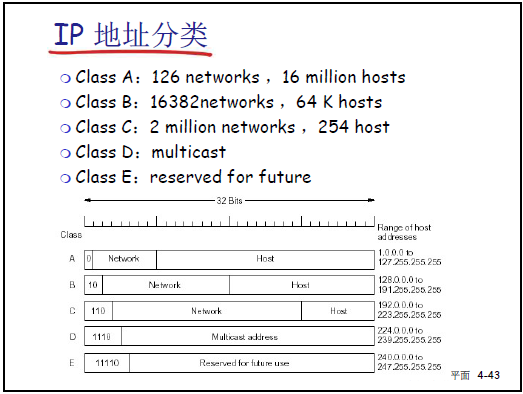

-
地址分類:
-
A 類:首位 0,範圍 1.0.0.0-126.255.255.255,共 126 個網絡,每個網絡 16777214 個主機(排除子網 / 主機全 0 / 全 1)。
-
B 類:前兩位 10,範圍 128.0.0.0-191.255.255.255,共 16382 個網絡,每個網絡 65534 個主機。
-
C 類:前三位 110,範圍 192.0.0.0-223.255.255.255,共 2097152 個網絡,每個網絡 254 個主機。
-
D 類:前四位 1110,用於多播(如 224.0.0.0-239.255.255.255;E 類:前四位 1111,預留未來使用。
-
-
特殊地址:
-
子網部分全 0:表示本網絡;主機部分全 0:表示本主機。
-
主機部分全 1:廣播地址,用於向子網內所有主機發送數據(如 223.1.1.255)。
-
127.x.x.x:迴路地址(如 127.0.0.1),用於主機自測(發送給該地址的數據包不經過網絡,直接回環到本機上層協議)。
-
(4)內網(專用)IP 地址

-
定義:地址空間中預留的專用地址,不分配為公網地址,僅在局域網內有效,路由器不轉發目標為專用地址的數據包。
-
專用地址範圍:
-
A 類:10.0.0.0-10.255.255.255(子網掩碼 255.0.0.0)。
-
B 類:172.16.0.0-172.31.255.255(子網掩碼 255.255.0.0)。
-
C 類:192.168.0.0-192.168.255.255(子網掩碼 255.255.255.0)。
(5)CIDR(無類域間路由)

-
背景:解決 A/B/C 類地址浪費問題(如 B 類網絡過大、C 類過小),子網部分可在 IP 地址任意位置劃分。
-
格式:a.b.c.d/x,x 為子網長度(如 200.23.16.0/23,前 23 位為子網部分,子網掩碼 11111111 11111111 11111110 00000000)。
(6)轉發表和轉發算法
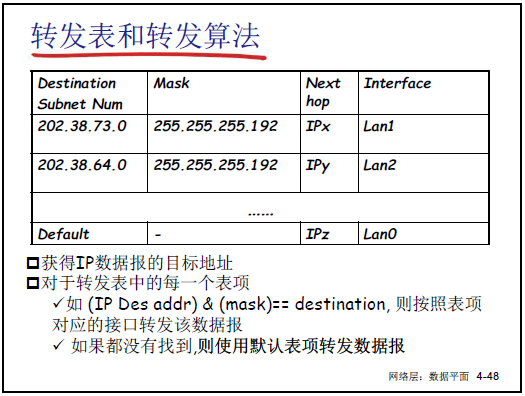
-
轉發表結構:包含 “目標子網號、掩碼、下一跳 IP、輸出接口” 四列。
-
轉發流程:
- 提取 IP 數據報的目的 IP 地址。
- 對轉發表中每個表項,計算 “目的 IP & 掩碼”,若結果等於 “目標子網號”,則按該表項的 “輸出接口” 轉發。
- 若所有表項均不匹配,按 “默認表項”(通常指向默認網關)轉發。
(7)IP 地址獲取方式

①手工配置
-
Windows:控制面板→網絡→TCP/IP 屬性,手動輸入 IP、子網掩碼、默認網關、DNS 服務器。
-
UNIX/Linux:編輯 /etc/rc.config 等配置文件,寫入 IP 相關參數。
②DHCP(動態主機配置協議)

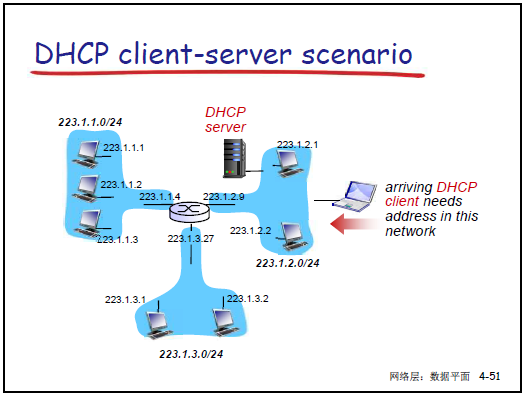
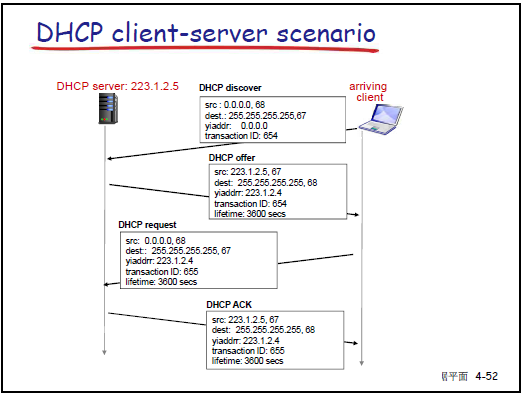

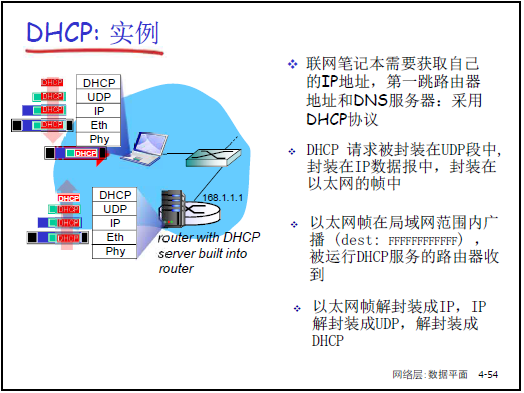
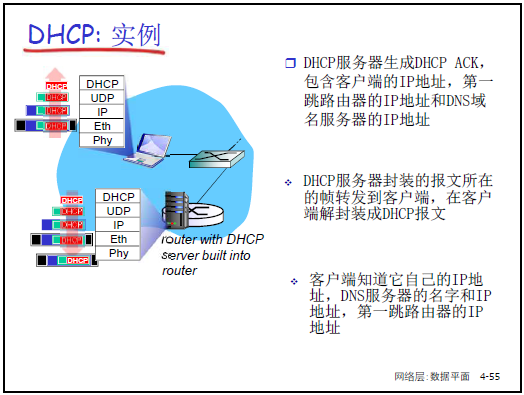
-
目標:實現 “即插即用”,主機動態從 DHCP 服務器獲取 IP 及配套信息,支持租期更新、移動用户接入。
-
工作流程:
- DHCP Discover:主機廣播請求(源 IP 0.0.0.0,目的 IP 255.255.255.255),尋找 DHCP 服務器。
- DHCP Offer:DHCP 服務器廣播響應,提供 IP 地址、租期(如 3600 秒)、子網掩碼等。
- DHCP Request:主機廣播請求,確認使用某 DHCP 服務器提供的 IP。
- DHCP ACK:DHCP 服務器廣播確認,正式分配 IP 及配套信息(默認網關、DNS 服務器地址)。
-
DHCP 返回信息:IP 地址、子網掩碼、第一跳路由器(默認網關)IP、DNS 服務器 IP。

(8)機構地址塊獲取與路由聚集
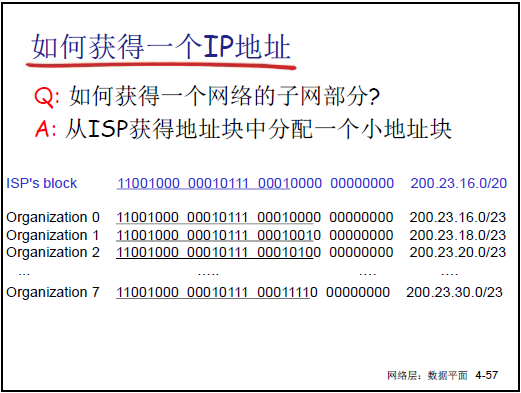
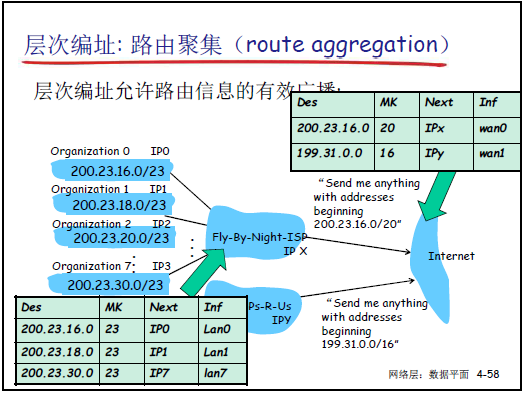
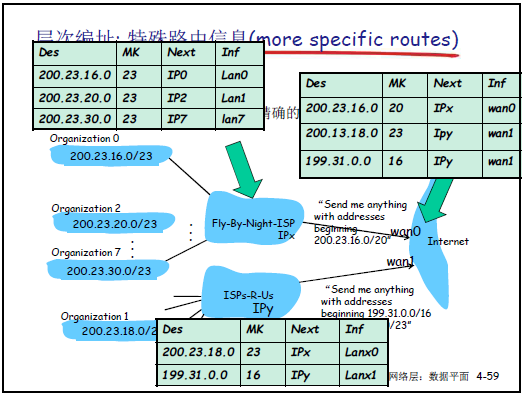

-
地址塊獲取:
-
方式 1:從 ISP(互聯網服務提供商)分配(如 ISP 從 ICANN 獲得大地址塊,再拆分給下屬機構)。
-
方式 2:直接向 ICANN(互聯網名稱與數字地址分配機構)申請,ICANN 負責全球 IP 地址分配、DNS 管理。
-
-
路由聚集:基於層次編址,將多個連續子網的路由信息合併為一條,減少廣域網路由表項數量。例如:200.23.16.0/23、200.23.18.0/23等 8 個子網,可聚集為 200.23.16.0/20(前 20 位相同),降低路由信息傳輸與計算代價。
4.3.4 NAT(網絡地址轉換)
(1)動機
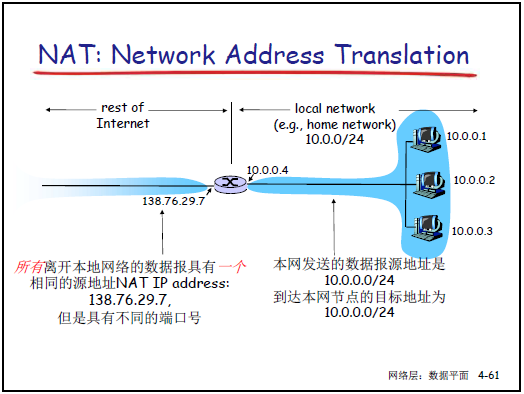

-
節省公網 IP:局域網內設備使用專用 IP,共用一個公網 IP 訪問互聯網。
-
靈活性:內網設備地址變化無需通知外界,更換 ISP 時僅需修改 NAT 路由器的公網 IP,不影響內網。
-
安全性:內網設備對外不可見,減少外部直接攻擊風險。
(2)實現原理

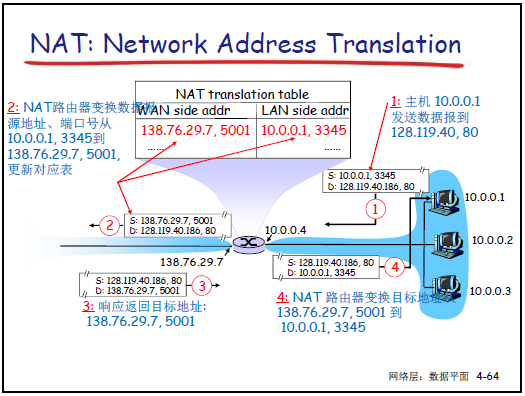
-
NAT 路由器核心功能:維護 “NAT 轉換表”(記錄內網 IP + 端口與公網 IP + 端口的映射關係)。
-
外出數據包:替換源 IP 為 NAT 公網 IP,源端口為新端口(未被佔用),目標 IP / 端口不變,更新轉換表。
-
進入數據包:根據目標 IP + 端口查詢轉換表,替換為內網 IP + 端口,源 IP / 端口不變。
-
-
端口資源:16 位端口字段支持 65535 個同時連接,滿足局域網多設備併發訪問需求。
(3)爭議與 NAT 穿越

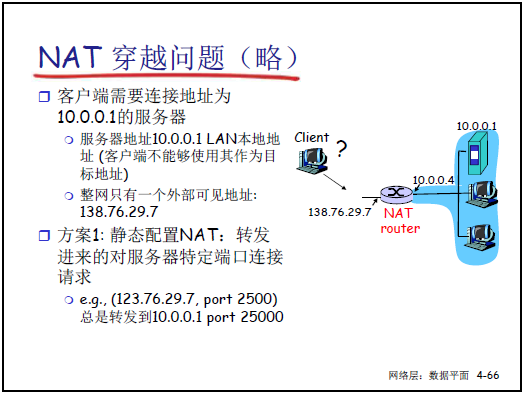
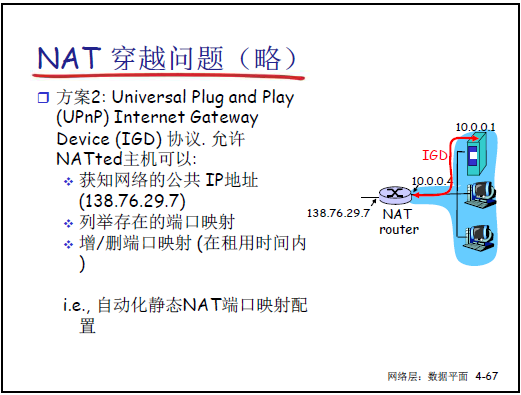
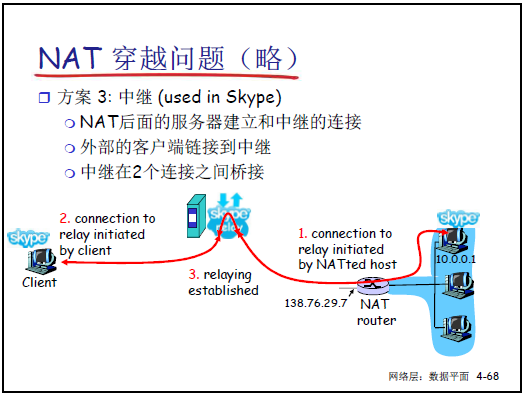
-
爭議:
-
違反分層原則:路由器(網絡層設備)處理傳輸層端口信息。
-
違反端到端原則:需在中間設備(NAT 路由器)維護連接狀態,增加網絡複雜性。
-
外網無法主動訪問內網設備:需特殊機制實現 “NAT 穿越”。
-
-
NAT 穿越方案:
-
靜態配置:固定映射公網 IP + 端口到內網 IP + 端口(如公網 138.76.29.7:2500 映射到內網 10.0.0.1:2500)。
-
UPnP(通用即插即用):內網設備通過 UPnP 協議自動查詢、添加 / 刪除 NAT 映射表項。
-
中繼(如 Skype):內網設備主動與中繼服務器建立連接,外網設備通過中繼服務器與內網設備通信。
-
4.3.5 IPv6
(1)動機

-
IPv4 地址耗盡:32 位 IPv4 地址僅約 43 億個,無法滿足物聯網等場景需求;IPv6 為 128 位地址,地址空間極大(可滿足長期需求)。
-
簡化頭部處理:移除校驗和(由鏈路層 / TCP/UDP 校驗)、固定頭部長度(40 字節),加速路由器轉發。
-
支持 QoS:新增 “優先級”“流標籤” 字段,便於對不同數據流提供差異化服務。
-
取消路由器分片:僅目標主機重組,路由器若遇 MTU 不足,直接丟棄數據包併發送 ICMPv6 “Packet Too Big” 報文,由源主機調整數據包大小。
(2)IPv6 頭部格式

-
固定 40 字節頭部:
-
版本(4 位,IPv6 為 6)、優先級(4 位,數據流優先級)、流標籤(20 位,標識同一數據流)。
-
載荷長度(16 位,頭部後的數據長度)、下一跳(8 位,指示上層協議或選項)、跳限制(8 位,類似 IPv4 的 TTL)。
-
源 IP 地址(128 位)、目的 IP 地址(128 位)。
-
(3)與 IPv4 的關鍵差異

-
移除頭部校驗和:降低路由器處理開銷。
-
選項處理:選項通過 “下一跳” 字段標識,不包含在固定頭部中,保持頭部簡潔。
-
ICMPv6:新增報文類型(如 “Packet Too Big”),整合 IPv4 中 IGMP(多播組管理)功能,支持多播組加入 / 退出。
(4)IPv4 到 IPv6 的平移

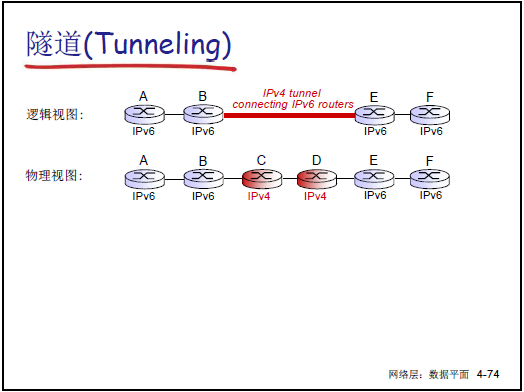
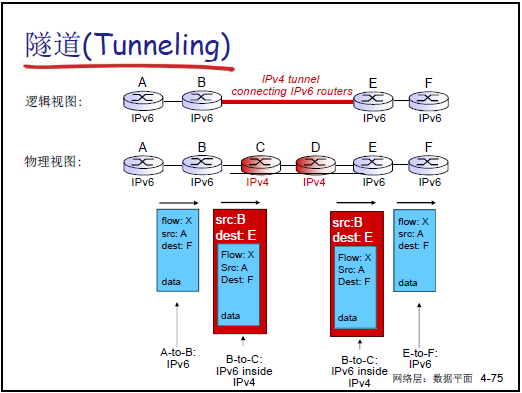
-
核心挑戰:無法通過 “標記日(Flag Day)” 一次性升級(設備數量龐大,用户 / 應用兼容性要求高),需平滑過渡。
-
隧道技術:在 IPv4 網絡中傳輸 IPv6 數據包,將 IPv6 數據包封裝為 IPv4 數據包的載荷,通過 IPv4 路由器傳輸,到達目標 IPv6 網絡後解封裝。例如:兩個 IPv6 “孤島” 通過 IPv4 “海洋” 通信,藉助隧道實現數據互通。
(5)IPv6 應用現狀
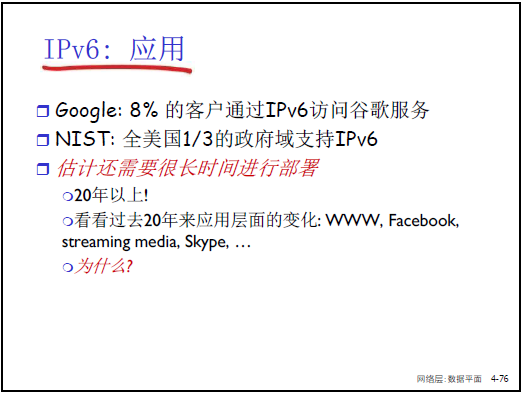
-
部分場景已落地:谷歌約 8% 用户通過 IPv6 訪問服務,美國 NIST(國家標準與技術研究院)1/3 政府域支持 IPv6。
-
部署週期長:預計需 20 年以上完成全面過渡,因設備升級、應用兼容性適配需長期推進。
4.4 通用轉發和 SDN
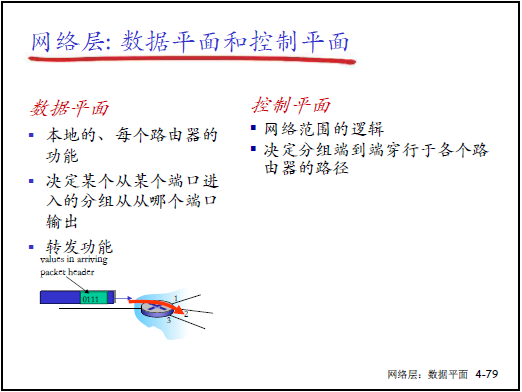
4.4.1 傳統網絡的控制平面與數據平面
(1)網絡層功能的平面劃分

- 核心邏輯:網絡層功能分為 “數據平面” 與 “控制平面”,兩者配合實現主機到主機的分組交付;
- 類比:
- 轉發(數據平面):類似 “通過單個路口的進出過程”(局部動作);
- 路由(控制平面):類似 “從源到目標的旅行路徑規劃”(全局決策)。
(2)傳統控制平面的實現方式
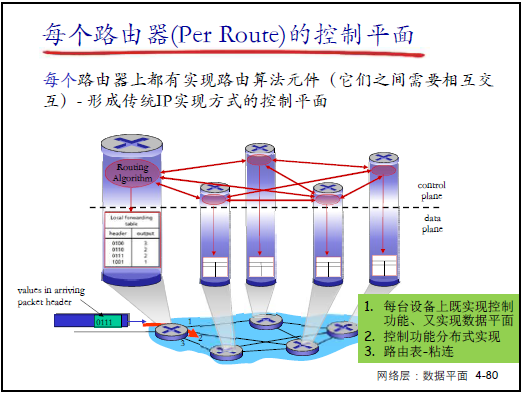
- 垂直集成:每台路由器同時實現控制平面與數據平面功能:
- 控制平面:路由器運行 “路由協議實體”,通過與其他路由器的路由通告(如 “告知鄰居下一跳”)計算路由表;
- 數據平面:路由器的 “RP 協議實體” 按路由表對分組執行轉發;
- 分佈式實現:每台路由器僅實現控制平面的一部分功能,通過路由協議交互(如 OSPF),共同完成全局路由計算(老師舉例:“全球幾百萬台路由器,各自算路由表,再配合實現全網可達”);
- 核心粘連:路由表是控制平面與數據平面交互的關鍵(控制平面生成路由表,數據平面依賴路由錶轉發)。
4.4.2 傳統網絡的問題:中間盒與垂直集成缺陷
(1)數量眾多、功能各異的中間盒

- 中間盒類型:除路由器外,還有交換機、防火牆、NAT、IDS(入侵檢測系統)、負載均衡設備等;
- 核心問題:
- 功能與設備綁定:每個網絡功能需專屬設備實現,且每台設備均 “垂直集成控制 + 數據平面”;
- 維護難度大:網絡管理員需掌握不同設備的拓撲、工作原理及配置(老師舉例:“新人難以快速上手,網絡管理員薪資高,因需維護大量複雜設備”);
- 升級成本高:新增功能需部署新設備,無法通過軟件靈活調整。
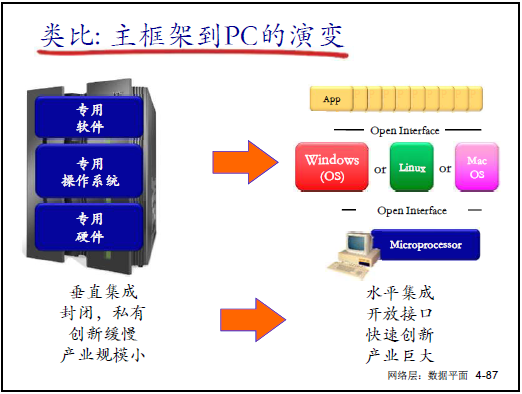
(2)垂直集成的核心缺陷(對應課件 4-82、4-83)


-
垂直集成的三層綁定:
- 硬件綁定:設備硬件為廠商專屬(如華為路由器硬件);
- OS 綁定:硬件需運行廠商私有 OS(如華為專用 OS、新華三 Commware OS);
- 協議綁定:OS 上運行廠商私有實現的標準協議(如 IP、OSPF);
- 老師舉例:“買華為設備不能拆賣 —— 無法用華為硬件跑其他 OS,也不能用其他硬件跑華為軟件,被廠商‘綁架’”;
-
傳統方式的三大問題:
- 成本高、生態差:垂直集成無競爭,設備昂貴,阻礙第三方創新;
- 功能固化、靈活度低:無法實現流量工程(如拆分流量),升級需全網設備變更(如 IPv4→IPv6 難);
- 管理複雜:配置錯誤影響全網,新增功能需部署新設備;
-
突破方向:2005 年提出 “控制平面與數據平面分離 + 集中控制”,即 SDN 雛形。
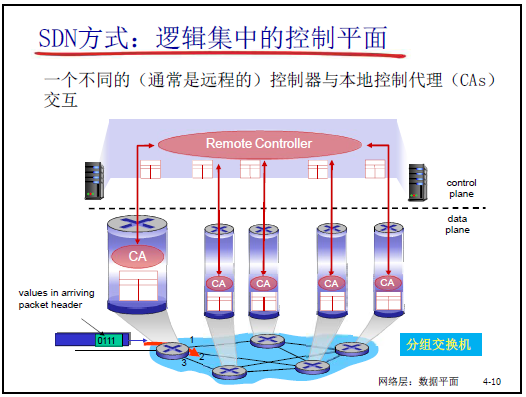
4.4.3 SDN 的核心思路與架構
(1)SDN 的核心思想:控制與數據平面分離
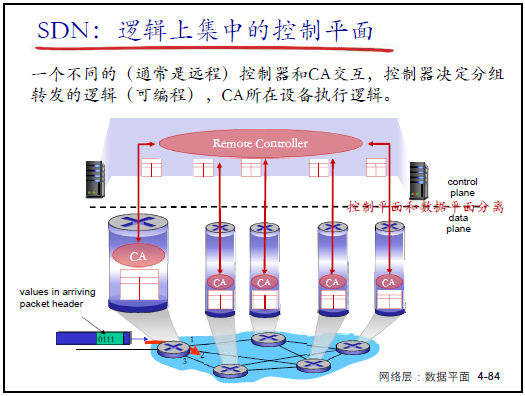

- 核心邏輯:打破傳統 “垂直集成”,將控制平面從設備中剝離,由遠程控制器集中實現;
- 架構分工:
- 數據平面:分組交換機(SDN 交換機)—— 僅按流表執行 “匹配 + 行動”,功能單一(如轉發、丟棄、修改字段);
- 控制平面:控制器 + 網絡應用 —— 控制器集中計算流表,網絡應用(如路由 APP、防火牆 APP)實現具體網絡功能;
- 強調:“運營商僅需部署一種 SDN 交換機,下發不同流表即可實現路由器、防火牆等功能,大幅降低設備維護成本”。
(2)SDN 的優勢

- 開放生態:水平集成控制平面,交換機、控制器、網絡應用可由不同廠商提供(如白盒交換機廠商競爭,價格降低);
- 易管理:控制器掌握全網狀態,集中編程替代分佈式配置,減少誤操作;
- 可編程:通過修改網絡應用或流表,快速升級網絡功能(如無需等待 “標記日”,改流表即可調整路由)。
(3)SDN 的三大核心特點
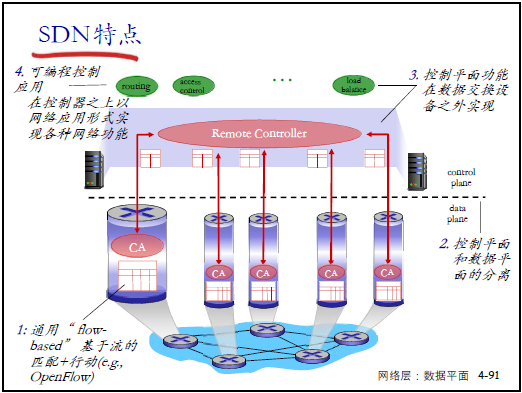
- 基於流的 “匹配 + 行動” 機制(如 OpenFlow):匹配多字段(源 IP、端口等),支持多動作;
- 控制平面與數據平面分離:數據平面僅執行,控制平面集中決策;
- 控制平面在數據設備外實現:網絡功能以 APP 形式運行在控制器上,支持靈活擴展。
(4)SDN 架構的三大組件
① 數據平面:SDN 分組交換機
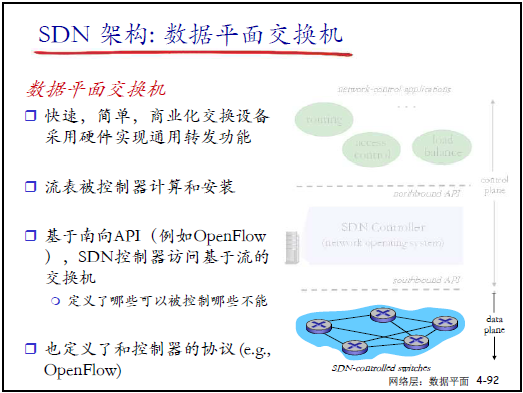
- 特點:快速、簡單、標準化,硬件實現轉發功能;
- 核心交互:通過南向 API(如 OpenFlow)接收控制器下發的流表,上報自身狀態(如端口流量);
- 補充:“交換機像‘執行者’,不做複雜計算,僅按流錶行動,成本低且易批量部署”。
② 控制平面:SDN 控制器(網絡 OS)
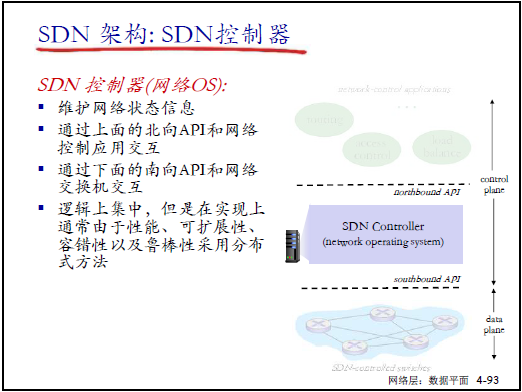
- 核心功能:維護全網狀態、計算流表、通過南北向接口交互;
- 接口分工:
- 北向接口:與網絡應用交互,接收功能需求(如防火牆 APP 需 “block 128.119.1.1”);
- 南向接口:與交換機交互,下發流表、接收狀態上報;
- 部署特點:邏輯上集中,物理上可分佈式部署(保障性能與可靠性)。
③ 控制應用
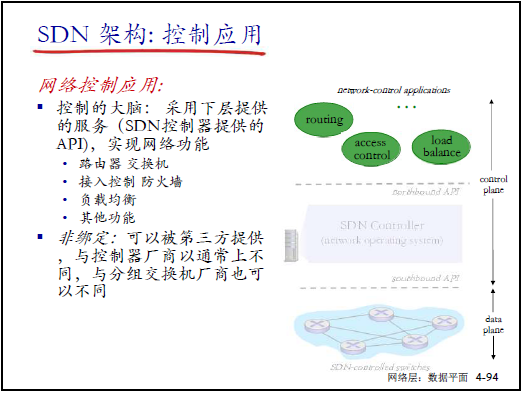
- 定位:網絡的 “智能中樞”,基於控制器 API 實現網絡功能(如路由、防火牆、負載均衡);
- 優勢:與廠商解耦 —— 第三方可開發應用(如創業公司開發新型流量調度 APP),促進創新。
4.4.4 OpenFlow:SDN 的 “匹配 + 行動” 標準
(1)流表:SDN 轉發的核心
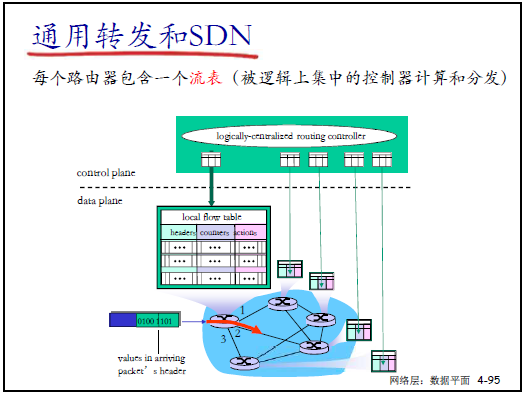


- 流的定義:由分組頭部字段(如源 IP、目標 MAC、TCP 端口)共同定義的分組集合;
- 通用轉發規則四要素:
- 模式(Pattern):分組頭部字段與流表項匹配(支持通配符,如 “src=10.1..”);
- 行動(Action):對匹配分組執行的操作(轉發、丟棄、上報控制器等);
- 優先權(Priority):解決多表項匹配歧義(優先級高的先執行);
- 計數器(Counters):統計匹配的分組數、字節數(用於流量監控)。
(2)OpenFlow 流表項結構
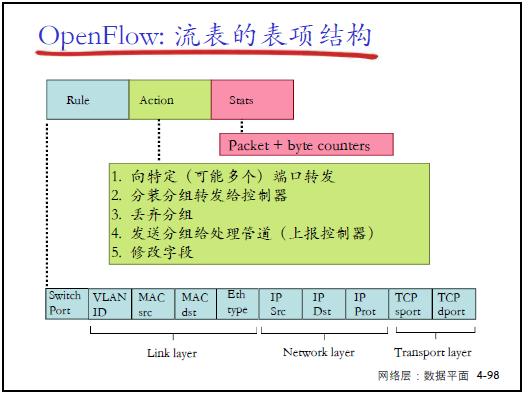
- 表項組成:Rule(匹配規則)+ Action(行動)+ Stats(統計);
- 匹配規則(Rule):覆蓋鏈路層(MAC)、網絡層(IP)、傳輸層(TCP/UDP 端口)字段;
- 行動(Action):支持轉發到端口、丟棄、修改字段、上報控制器等;
- 統計(Stats):記錄匹配的分組數、字節數。
(3)OpenFlow 應用實例
① 實現傳統設備功能
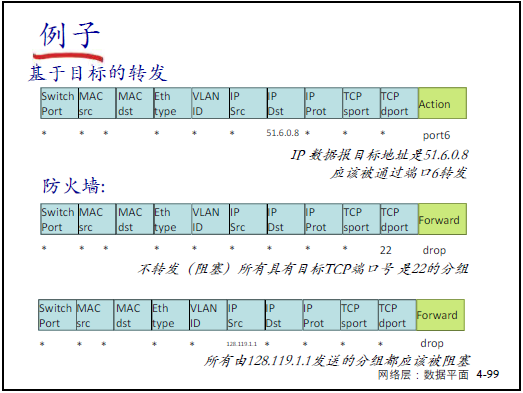
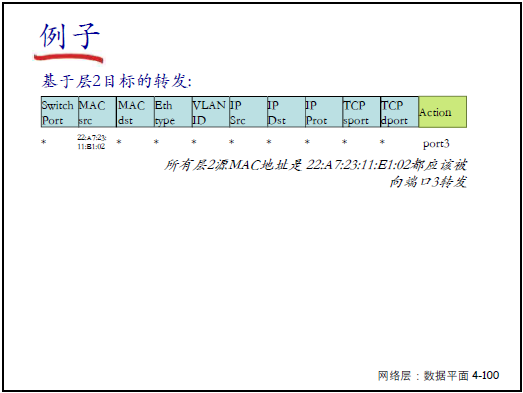
- 路由器:匹配 “目標 IP(最長前綴)”,行動 “轉發到指定端口”;
- 防火牆:匹配 “TCP 端口 = 22” 或 “源 IP=128.119.1.1”,行動 “丟棄”;
- 交換機:匹配 “源 MAC=22:A7:23:11:E1:02”,行動 “轉發到端口 3”;
- NAT:匹配 “源 IP=10.0.0.1”,行動 “修改源 IP 為 138.76.29.7”。
② 統一網絡設備功能

- 核心邏輯:所有網絡設備(路由器、防火牆、NAT 等)均可通過 “匹配 + 行動” 抽象描述,實現 “一種設備支持多場景”;
- 老師強調:“運營商僅需管理一種 SDN 交換機,通過流表切換功能,可維護性大幅提升”。
4.4.5 SDN 的流量工程優勢
(1)傳統路由的流量工程困境
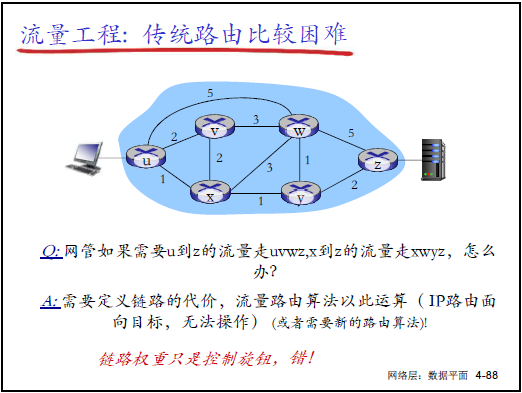
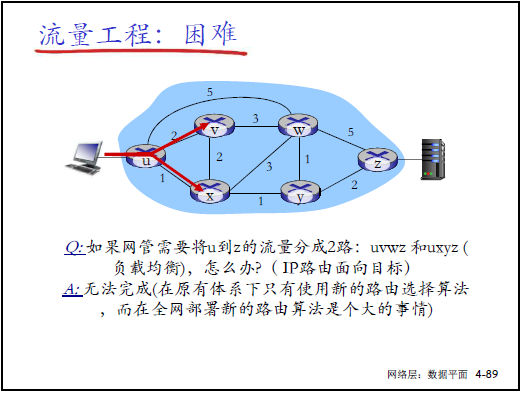
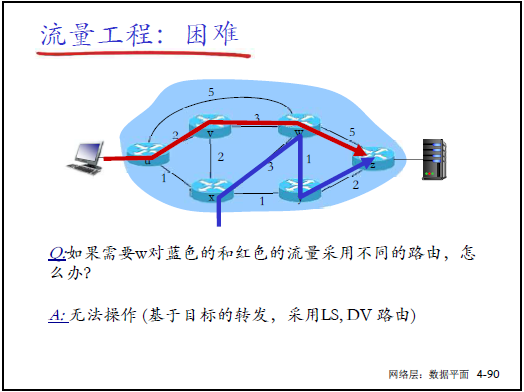
- 傳統侷限:僅基於 “目標 IP + 鏈路代價” 選路,無法實現:
- 路徑控制(如指定 U→Z 走特定路徑);
- 流量拆分(如 U→Z 的流量分兩路負載均衡);
- 流量區分(如藍色流量與紅色流量走不同路徑)。
(2)SDN 的流量控制實例
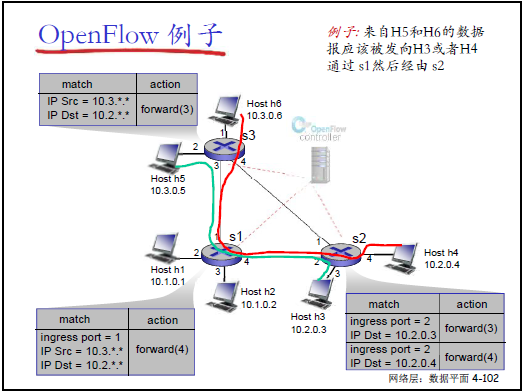
-
場景:控制 H5(10.3.0.5)→H3(10.2.0.3)走 “S1→S3”,H6(10.3.0.6)→H4(10.2.0.4)走 “S1→S2”;
-
流表配置(S1 為例):
匹配條件 行動 ingress port=1,IP src=10.3..,IP dst=10.2.. forward(4) ingress port=2,IP dst=10.2.0.3 forward(3) -
優勢:通過多字段匹配(入端口、源 IP、目標 IP),精準控制路徑,傳統路由無法實現。
4.4.6 4.4 核心總結
- 傳統網絡:控制 + 數據平面垂直集成,轉發表由分佈式路由協議生成,功能固化;
- SDN:控制 + 數據平面分離,流表由集中式控制器生成,網絡可編程;
- 關鍵銜接:流表 / 轉發表的計算邏輯(控制平面如何生成規則),將在第 5 章詳細講解。
參考資料來源:中科大鄭烇、楊堅全套《計算機網絡(自頂向下方法 第7版,James F.Kurose,Keith W.Ross)》課程