









原文發佈於 CloudPilot AI
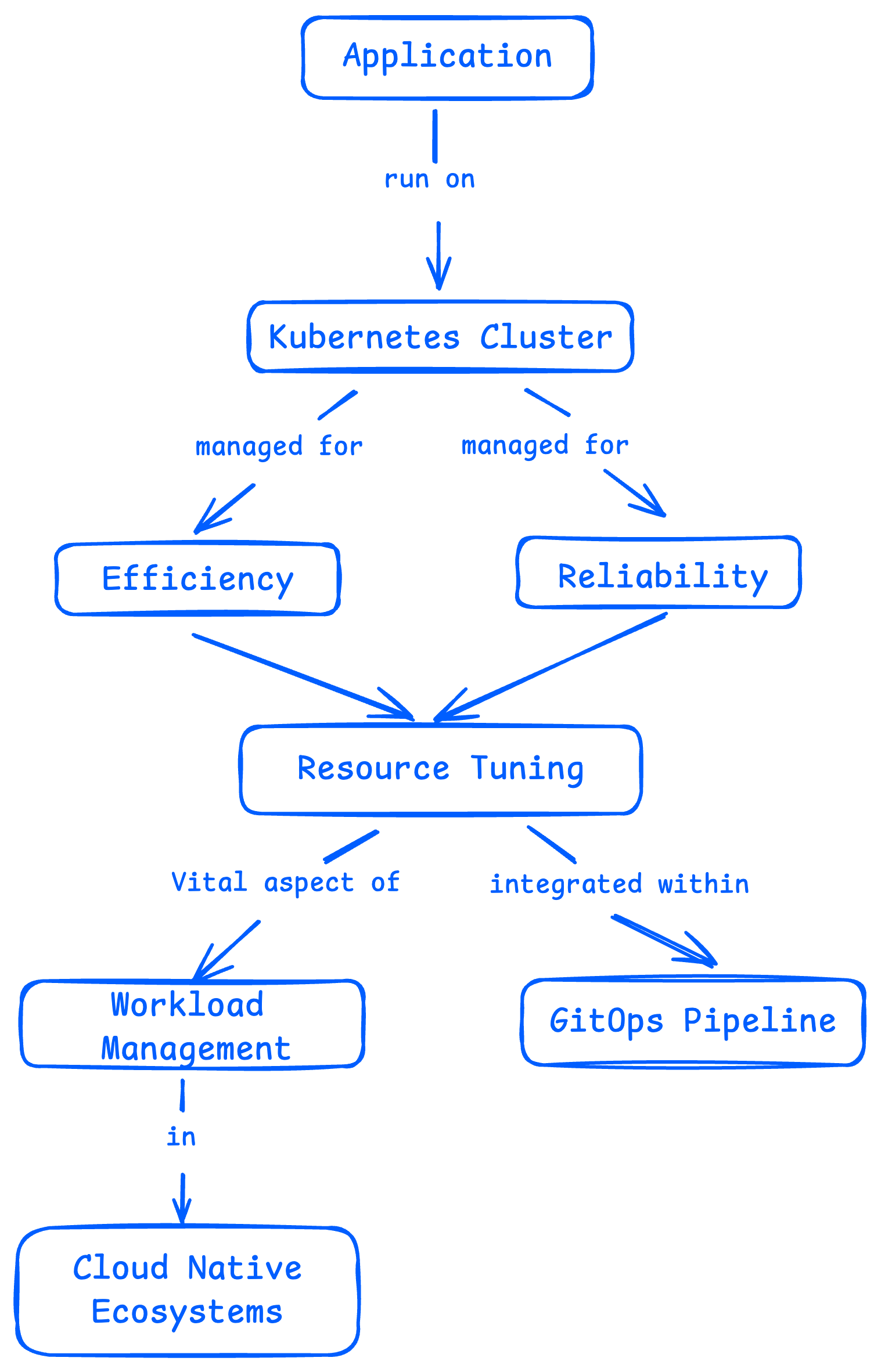
在雲原生環境中,Kubernetes 資源配置是一項非常關鍵的工作,尤其是當你通過 GitOps 流程來管理集羣時更是如此。
這篇文章會帶你瞭解資源管理中常見的一些“坑”——比如資源預留太多,配額浪費嚴重,或者因為資源不足而無法部署新服務。同時我們也會介紹幾種不花一分錢的方法,幫你更輕鬆地解決這些問題。
資源配置的核心邏輯和常見挑戰
Kubernetes 的資源配置,其實主要圍繞兩個核心機制展開:資源配額(Resource Quotas) ,以及 Pod 的請求值和限制值(Requests & Limits) 。這兩者共同作用,用來限制應用對資源的佔用,確保整個集羣既健康又高效地運行。
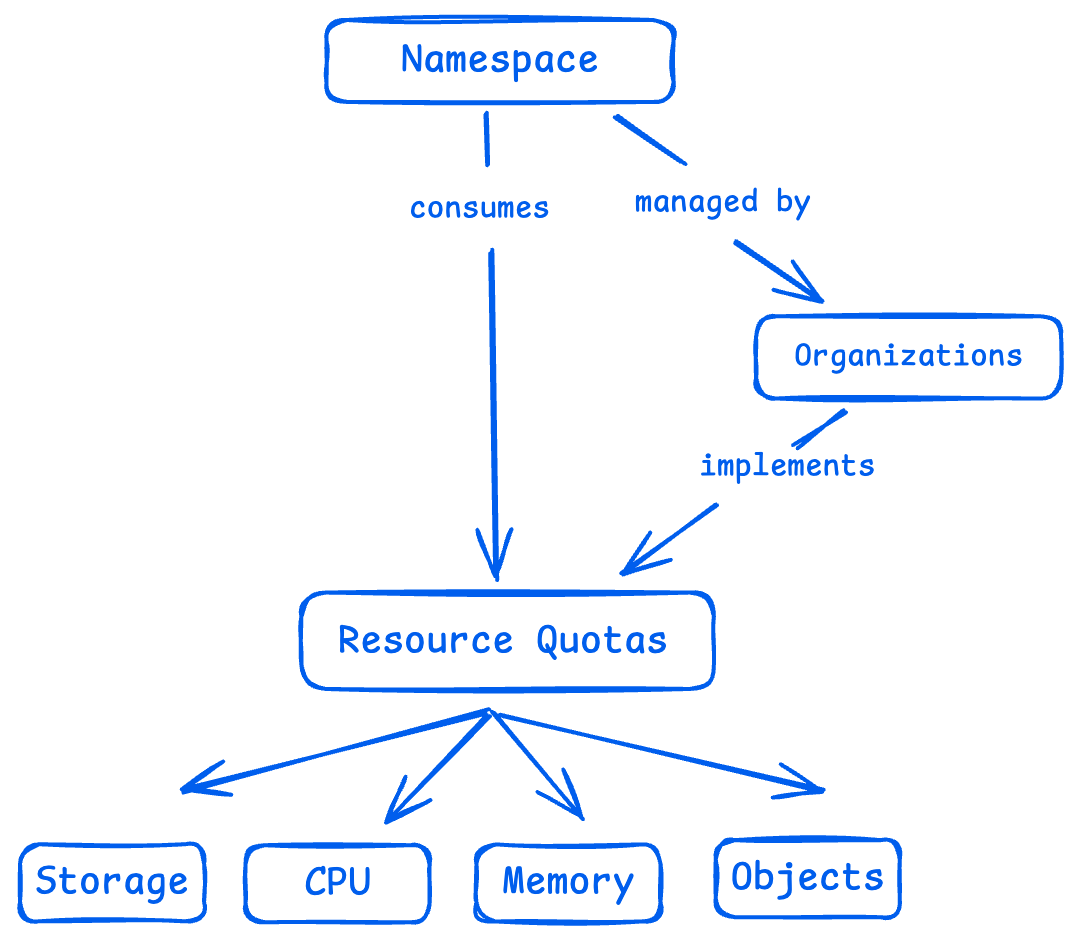
資源配額(Resource Quotas)
資源配額是 Kubernetes 提供的一種控制機制,用來限定某個命名空間(namespace)下能使用的資源總量。除了 CPU 和內存這種常見資源,它還能限制比如 Pod、Service、PersistentVolumeClaim(持久化存儲申請)等對象的數量。
這麼做的目的很簡單:防止某個團隊或者服務“獨佔資源”,影響到其他人的正常運行。通過資源配額,平台管理員可以實現資源的公平分配,避免“搶資源大戰”,同時讓整個集羣的性能更加可控、可預期。
資源配額帶來的挑戰,開發和運維團隊可能深有體會:
-
很難拿捏“剛剛好”的配額: 配得太少,服務跑不起來;配得太多,又容易浪費資源,甚至讓其他服務“餓死”;
-
配額一旦超了,成本也跟着飆升: 過度預留資源不僅燒錢,還可能讓整個平台的資源利用率大打折扣;
-
協調配額成了日常負擔: 每次資源不夠用,都要和平台、運維、開發多方來回溝通調整配額設置。稍微出點差錯,就可能卡住部署流程,影響上線節奏。
簡單來説,資源配額雖然是個好工具,但調不好反而成了團隊協作和系統效率的“絆腳石”。
Pod 的 Requests 和 Limits
Pod 的 Requests 和 Limits 是用來規定容器在運行過程中可以使用的 CPU 和內存資源範圍。
其中,Request 是“起步資金” ,確保容器有足夠的資源順利啓動並穩定運行;而 Limit 則像“信用卡額度” ,防止某個容器過度佔用資源,拖慢同一節點上的其他服務。

但在實際操作中,這部分配置常常讓開發和運維團隊頭疼不已,主要問題包括:
-
設置得太低時,可能導致:
-
-
容器啓動緩慢,或由於 CPU 不足出現響應延遲;
-
容器因為內存不足頻繁崩潰。
-
-
設置得太高時,則容易:
-
- 浪費資源,甚至超出命名空間的 ResourceQuota 限制;
- 導致新 Pod 無法調度,因為節點上的資源已經被高請求值佔滿;
- 拖累其他應用,造成限速(throttling)或被 OOM Kill(內存溢出強制終止)。
換句話説,設置 Requests 和 Limits 並不是“越多越好”或“越省越穩”,而是需要不斷調試和權衡,找到既滿足性能又不過度浪費的平衡點。
關於 Kubernetes 服務啓動時所需資源激增的問題,可以查看這篇文章尋找解決方案:KubeCon 演講文字實錄 | 從瓶頸到突破:征服 Kubernetes 中的應用程序啓動高峯
解決部署延遲與資源分配難題
如何判斷 ResourceQuota 是否阻礙了部署
在 Kubernetes 的部署過程中,有一個非常常見、但又讓人頭大的問題:Pod 因為觸達了資源配額上限而無法部署。這種情況往往出現在關鍵更新或滾動發佈時,對開發者來説影響極大,甚至會直接阻斷上線流程。
要解決這個問題,首先得搞清楚 ResourceQuota 是如何影響部署策略的。有了這層理解,開發者就能提前預判風險,在部署前做好準備,避免臨時踩坑,從而提升整個發佈流程的流暢度。
舉個例子,如果你設定了一個 Deployment 使用滾動更新(rolling update),但新版 Pod 一直沒法跑起來,你可能會在事件日誌中看到類似這樣的提示信息:
# kubectl get events -n recipes
LAST SEEN TYPE REASON OBJECT MESSAGE
18s Warning FailedCreate replicaset/recipes-5cb59585d4 (combined from similar events): Error creating: pods "recipes-5cb59585d4-7r78l" is forbidden: exceeded quota: compute-resources, requested: requests.cpu=250m,requests.memory=128Mi, used: requests.cpu=375m,requests.memory=384Mi, limited: requests.cpu=375m,requests.memory=384Mi
# kubectl describe resourcequota -n recipes
Name: compute-resources
Namespace: recipes
Resource Used Hard
-------- ---- ----
limits.cpu 375m 2
limits.memory 384Mi 2Gi
requests.cpu 375m 375m
requests.memory 384Mi 384Mi
當你發現資源配額阻礙了部署,接下來的處理通常就比較“低效”了:團隊必須手動排查當前配額使用情況,並和平台管理員協商資源調整。
這一來一回,不僅打斷了工作節奏,還可能導致部署週期大幅延後。
別再靠猜來配置容器資源請求了
“我到底該設置多少資源才合適?”——這是開發過程中經常會遇到的問題,尤其是當應用還處於開發早期或者頻繁變動時,更是無從下手。
大多數時候,初始的資源設置其實都是“靠感覺”,為了確保應用能跑起來,就先預留多一點,哪怕沒有任何歷史數據支撐。
比如説,一個 Deployment 在運行時並沒有做資源監控。此時你用 kubectl top 查看,發現它只用了 5 millicores 的 CPU 和 15MB 的內存。
表面上看,一切正常。但這並不能説明它在實際壓力下的表現,而這組數據也揭示了另一個問題——它現在的資源請求,可能比真實需求高出 25 倍之多。

這種“過度預留”不僅浪費資源,還可能佔用了本來可以分配給其他服務的空間,導致整個集羣效率下降。
# kubectl top pods -n recipes
NAME CPU(cores) MEMORY(bytes)
recipes-postgresql-0 5m 15Mi
# kubectl get pods -n recipes -o json | jq '.items[] | {name: .metadata.name, limits: .spec.containers[].resources.limits, requests: .spec.containers[].resources.requests}'
{
"name": "recipes-postgresql-0",
"limits": {
"cpu": "125m",
"memory": "256Mi"
},
"requests": {
"cpu": "125m",
"memory": "256Mi"
}
}
為了真正做到資源配置的“精細化”,通常需要讓 Pod 在正常負載下運行一段時間,收集性能指標,再進行分析和調整,然後再把優化後的結果應用到 Pod 的配置中。
這個流程既耗時又複雜,難怪很多 Kubernetes 集羣存在資源利用率偏低的問題——與其頻繁調優,不如一開始就多申請點資源來得省事。
簡化這個過程!
好消息是,有一些小工具和 Kubernetes 自帶的能力,可以幫我們緩解這些煩惱。
腳本:檢查命名空間中的 ResourceQuota 使用情況
下面這個腳本就非常實用,適合開發者或平台用户在遇到部署失敗、懷疑資源配額相關問題時隨時運行。
它會檢查當前命名空間下所有的 ResourceQuota 使用情況,評估資源是否緊張,並根據使用率給出哪些資源項可能需要上調配額的建議。這樣一來,不用等到部署掛了才發現問題,而是可以主動預警、及時處理。
# KUBERNETES_DISTRIBUTION_BINARY=kubectl NAMESPACE=recipes CONTEXT=gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster bash -c "$(curl -s https://raw.githubusercontent.com/runwhen-contrib/rw-cli-codecollection/main/codebundles/k8s-namespace-healthcheck/resource_quota_check.sh)" _
Resource Quota and Usage for Namespace: recipes in Context: gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster
===========================================
Quota: compute-resources
limits.cpu: OK ( 18 %)
limits.memory: OK ( 18 %)
requests.cpu: AT LIMIT ( 100 %) - Immediately increase the resource quota for requests.cpu in recipes
requests.memory: AT LIMIT ( 100 %) - Immediately increase the resource quota for requests.memory in recipes
-----------------------------------
Recommended Next Steps:
[
{
"remediation_type": "resourcequota_update",
"increase_percentage": "40",
"limit_type": "hard",
"current_value": "375",
"suggested_value": "525",
"quota_name": "compute-resources",
"resource": "requests.cpu",
"usage": "at or above 100%",
"severity": "1",
"next_step": "Increase the resource quota for requests.cpu in `recipes`"
},
{
"remediation_type": "resourcequota_update",
"increase_percentage": "40",
"limit_type": "hard",
"current_value": "384",
"suggested_value": "537",
"quota_name": "compute-resources",
"resource": "requests.memory",
"usage": "at or above 100%",
"severity": "1",
"next_step": "Increase the resource quota for requests.memory in `recipes`"
}
]
自動化生成 Pod 資源請求建議
要精準地設置 Pod 需要的資源量,確實需要一段時間的監控和分析,然後再做調整。
幸運的是,Kubernetes 自帶了一個非常實用的工具——Vertical Pod Autoscaler(垂直 Pod 自動伸縮器,VPA),它可以幫你解決這個問題!
Kubernetes 目前有兩種彈性伸縮方式:
- Horizontal Pod Autoscaler(水平 Pod 自動伸縮器),通過增加或減少 Pod 副本數來應對負載變化,不過這跟調整單個 Pod 的資源請求無關,沒用在這裏。
- Vertical Pod Autoscaler(垂直 Pod 自動伸縮器),專門監控單個 Pod 的資源使用情況,判斷是應該“擴”資源還是“縮”資源。它可以自動調整,也可以只給出建議。
針對“我到底應該設置多少資源?”這個問題,Vertical Pod Autoscaler 就很合適。
雖然自動調整運行中的 Pod 在某些場景(比如 GitOps 流程)可能不太適用,但你完全可以讓它運行在 “推薦模式” ,只給出調整建議。
藉助 Kubernetes 內置的指標服務,或者配合 Prometheus,VPA 能幫你做出合理的資源配置建議,大大減少猜測的盲目性。
當然,市場上還有一些更高級的資源推薦算法和工具,比如 CloudPilot AI,能實時監控集羣資源使用情況,對資源利用率的節點進行資源優化,減少浪費,適合有更高要求的團隊。
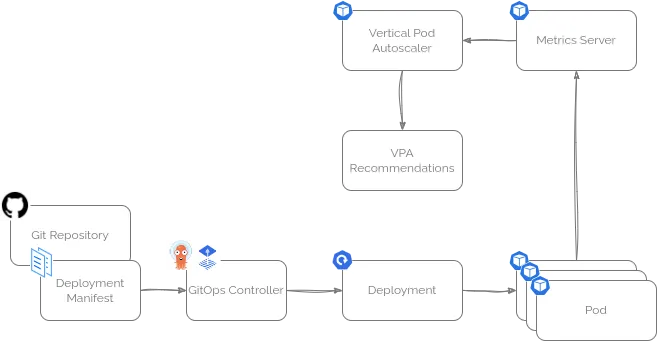
啓用 VPA 的推薦模式
你可以很方便地按照官方文檔,或者通過 Helm Chart,把 VPA 部署到正在運行的 Kubernetes 集羣中。
使用 Helm Chart 的好處是靈活,可以輕鬆開啓推薦器(recommender)功能,同時關閉自動更新(updater)和准入控制器(admissionController)這兩個組件——如果你暫時不需要它們的話。
舉個例子,下面是一個用於在沙箱集羣中通過 FluxCD 部署 VPA 的 HelmRelease 配置示例:
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: vpa
namespace: vpa
spec:
releaseName: vpa
# (https://github.com/FairwindsOps/charts/blob/master/stable/vpa/values.yaml)
chart:
spec:
chart: vpa
sourceRef:
kind: HelmRepository
name: fairwinds-stable
namespace: flux-system
interval: 5m
values:
recommender:
enabled: true
updater:
enabled: false
admissionController:
enabled: false
配置 VPA 為指定 Deployment 提供資源推薦
在成功部署 VPA 後,你可以創建一個 VerticalPodAutoscaler 資源清單,指定它要監控哪個 Deployment,並且只生成資源配置的推薦,而不會自動修改 Pod。
比如,下面這個 VPA 配置示例就是針對某個特定 Deployment,只輸出資源調整建議,避免自動變更 Pod。這對於使用 GitOps 管理的環境來説非常重要,能保證配置變更都在版本控制之下,避免自動更新帶來的不確定性。
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: recipes-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: recipes
updatePolicy:
updateMode: "Off" #Set to off since the 'recipes' deployment manifest is managed with GitOps
腳本:自動獲取命名空間內 Pod 的資源推薦
有了 VPA 之後,這個腳本可以幫助開發者自動查詢當前命名空間中各個 Pod 的資源推薦情況。
需要注意的是,雖然 VPA 本身提供了接口可以直接查詢推薦結果,但這些數據通常比較原始,需要進一步解讀並轉化為具體的調整方案。
這個腳本就是為了解決這個問題,它會整理出詳細的推薦信息和配置變更建議,方便自動化處理和後續執行。
# KUBERNETES_DISTRIBUTION_BINARY=kubectl NAMESPACE=recipes CONTEXT=gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster LABELS= bash -c "$(curl -s https://raw.githubusercontent.com/runwhen-contrib/rw-cli-codecollection/main/codebundles/k8s-podresources-health/vpa_recommendations.sh)" _
VPA Recommendations for Namespace: recipes for Context: gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster
===========================================
Recommendation for recipes-nginx in Deployment recipes: Adjust CPU request from 125 to 20 millicores
Recommendation for recipes-nginx in Deployment recipes: Adjust Memory request from 64 to 50 Mi
Recommendation for recipes in Deployment recipes: Adjust CPU request from 125 to 20 millicores
Recommendation for recipes in Deployment recipes: Adjust Memory request from 64 to 50 Mi
Recommended Next Steps:
[
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "cpu",
"current_value": "125",
"suggested_value": "20",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes-nginx",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust CPU request from 125 to 20 millicores"
},
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "memory",
"current_value": "64",
"suggested_value": "50",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes-nginx",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust Memory request from 64 to 50 Mi"
},
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "cpu",
"current_value": "125",
"suggested_value": "20",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust CPU request from 125 to 20 millicores"
},
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "memory",
"current_value": "64",
"suggested_value": "50",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust Memory request from 64 to 50 Mi"
}
]
將資源調優融入GitOps流水線
前面提到的腳本幫你找出了哪些資源配置需要調整,以及具體該怎麼改,最後一步就是把這些推薦結果整合進 GitOps 流水線裏。
雖然不同團隊的 GitOps 流程會有所差異,但一般來説,可以把腳本輸出中“Recommended Next Steps”(推薦的後續操作)部分的 JSON 內容提取出來,傳給一個自動化腳本。
這個腳本會根據推薦內容更新 GitOps 代碼倉庫,並通過既有的審批流程通知相關負責人,確保資源調整變更有序、安全地落地。這樣一來,資源配置的優化就能無縫融入日常的開發和交付節奏。
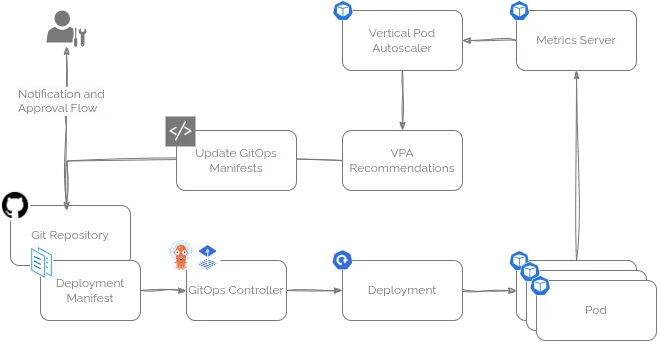
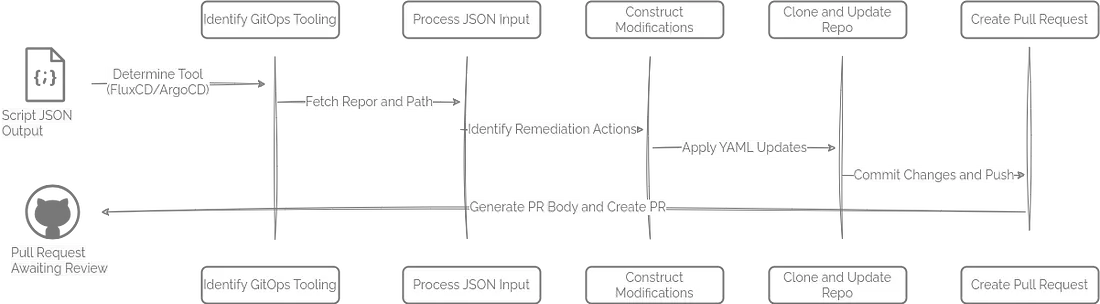
舉個例子,這個腳本(https://github.com/runwhen-contrib/rw-cli-codecollection/blob/main/codebundles/k8s-gitops-gh-remediate/update_github_manifests.sh)適用於存放在 GitHub 上的 GitOps 倉庫,兼容 ArgoCD 和 FluxCD 兩種 GitOps 引擎。它的工作流程大致如下:
- 首先識別負責管理資源的 GitOps 控制器(FluxCD 或 ArgoCD);
- 獲取對應的 Git 倉庫地址以及存放 Kubernetes 清單(manifest)文件的路徑;
- 解析輸入的 JSON,識別需要修正的資源操作,並按類型分類,比如資源配額更新、資源請求建議、PVC 容量擴容等;
- 針對每個需要修正的操作,動態生成對應的 YAML 文件變更內容;
- 克隆目標 Git 倉庫,創建一個新的分支,將修改後的 YAML 文件寫入並提交;
- 自動生成一份詳細的 Pull Request(PR)説明,闡述修改原因並附帶相關信息鏈接,然後發起針對主分支的 PR;
- 最後輸出 PR 鏈接,方便團隊成員進行代碼審查和審批。
這個流程讓資源調優的變更能自動、有序地推進,減少人工干預和出錯風險。
總 結
資源管理,特別是在性能和成本之間找到最佳平衡,對處於生產環境的平台來説確實是一項複雜的挑戰。本文介紹了一些免費且實用的腳本和工具,適合作為平台或應用團隊入門的參考。
目前市面上也有許多廠商投入大量資源,提供更深入的應用使用洞察和資源調優方案,比如 CloudPilot AI (我們即將推出一個全新的Dashboard,將帶來更直觀的成本監控體驗,敬請期待!) ,這些方案尤其適合規模大、環境複雜的場景。




