









一種高效、便捷的部署方式。
隨着大模型技術的快速發展,業界的關注點正逐步從模型訓練往模型推理轉變。這一轉變不僅反映了大模型在實際業務中的廣泛應用需求,也體現了技術優化和工程化落地的趨勢。
魔搭社區(ModelScope)作為開源大模型的聚集地,結合阿里雲邊緣雲 ENS ,提供了一種高效、便捷的部署方式。通過按需付費和彈性伸縮,開發者可以快速部署和使用大模型,享受雲計算的便利。本文介紹了魔搭社區與阿里雲邊緣雲 ENS 的結合使用體驗,包括部署流程、環境配置、效果驗證等內容。
魔搭社區(ModelScope)是中國規模和影響力最大的開源模型社區 。致力於構建模型即服務(MaaS)生態,提供從模型探索、體驗、訓練、推理到部署的一站式服務。該平台匯聚了超過 5 萬個 AI 模型,涵蓋自然語言處理、計算機視覺、語音、多模態、科學計算等領域,服務超過 1400 萬開發者。
阿里雲邊緣雲 ENS 是由大規模地域分散的邊緣節點相互協同組成的一朵可遠程管控,安全可信,標準易用的分佈式雲。以廣覆蓋為核心定位,為客户提供低時延、本地化、小型化三大核心價值。全球擁有超過 3200 個邊緣節點,中國內地省份與運營商 100% 覆蓋,海外覆蓋 70+ 重點國家和地區。
01 |如何新建部署入口
進入魔搭社區 - 模型服務 - 部署服務(SwingDeploy) - 免費部署到魔搭推理API - 新建部署。
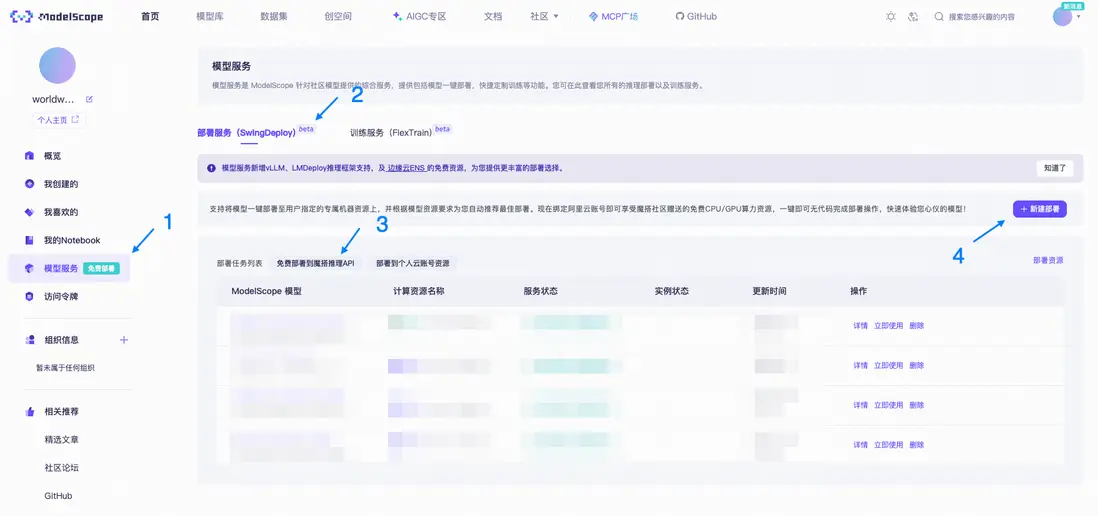
魔搭社區新建部署界面
02| 模型選擇和服務部署配置
1、模型選擇
社區提供了熱門模型的優先推薦列表,也支持通過搜索功能為您查找特定模型。下面我們以 Qwen3-8B-GGUF 為例進行介紹,其可以運行在免費 GPU 資源上。
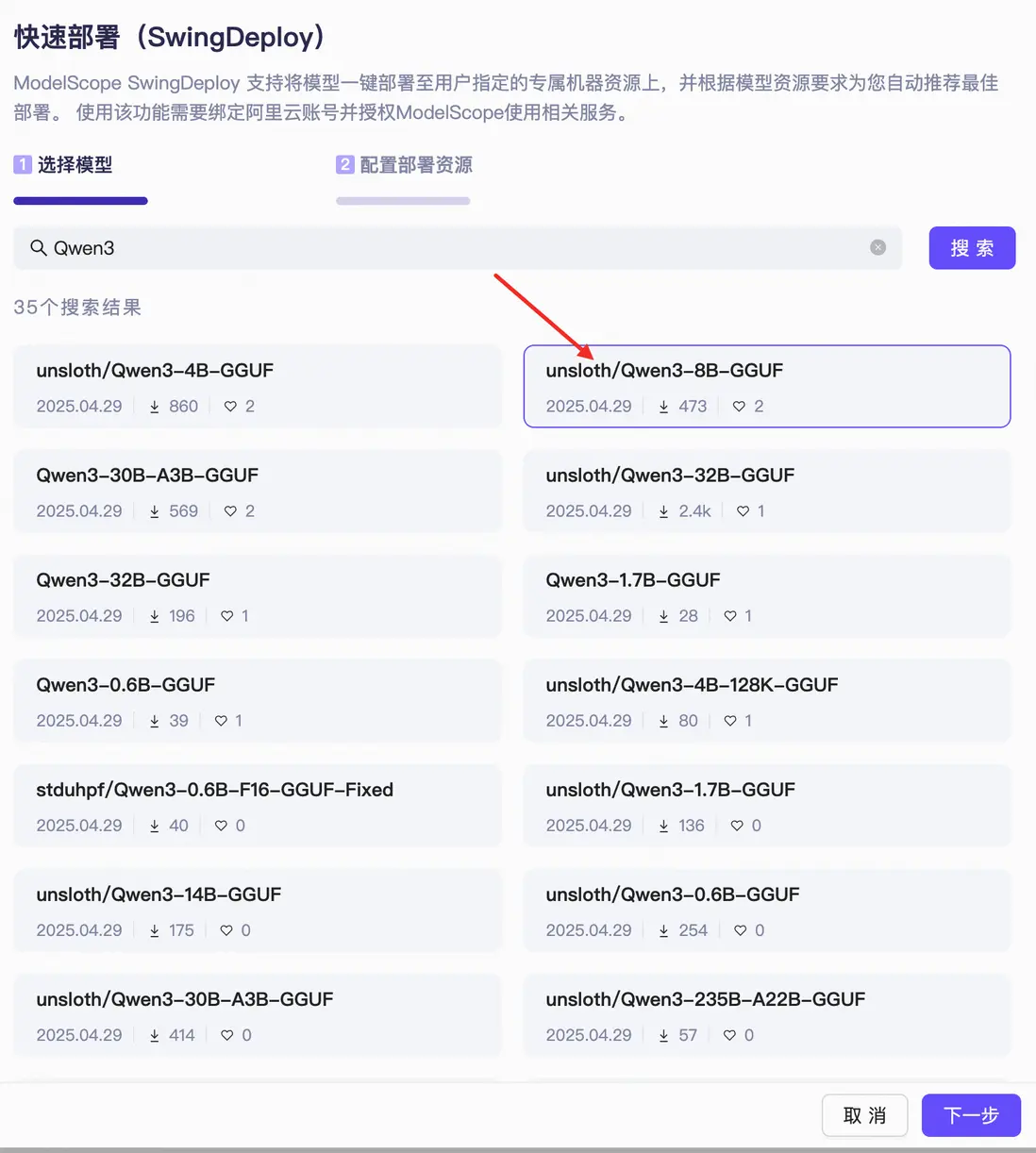
2、服務部署配置
| 基礎配置
針對該模型,我們選擇 Ollama 作為推理框架,並在免費部署資源中選用邊緣節點服務(ENS)進行部署。對於其他模型,您可以根據需求靈活選擇推理框架、以及 CPU 部署或 GPU 部署。
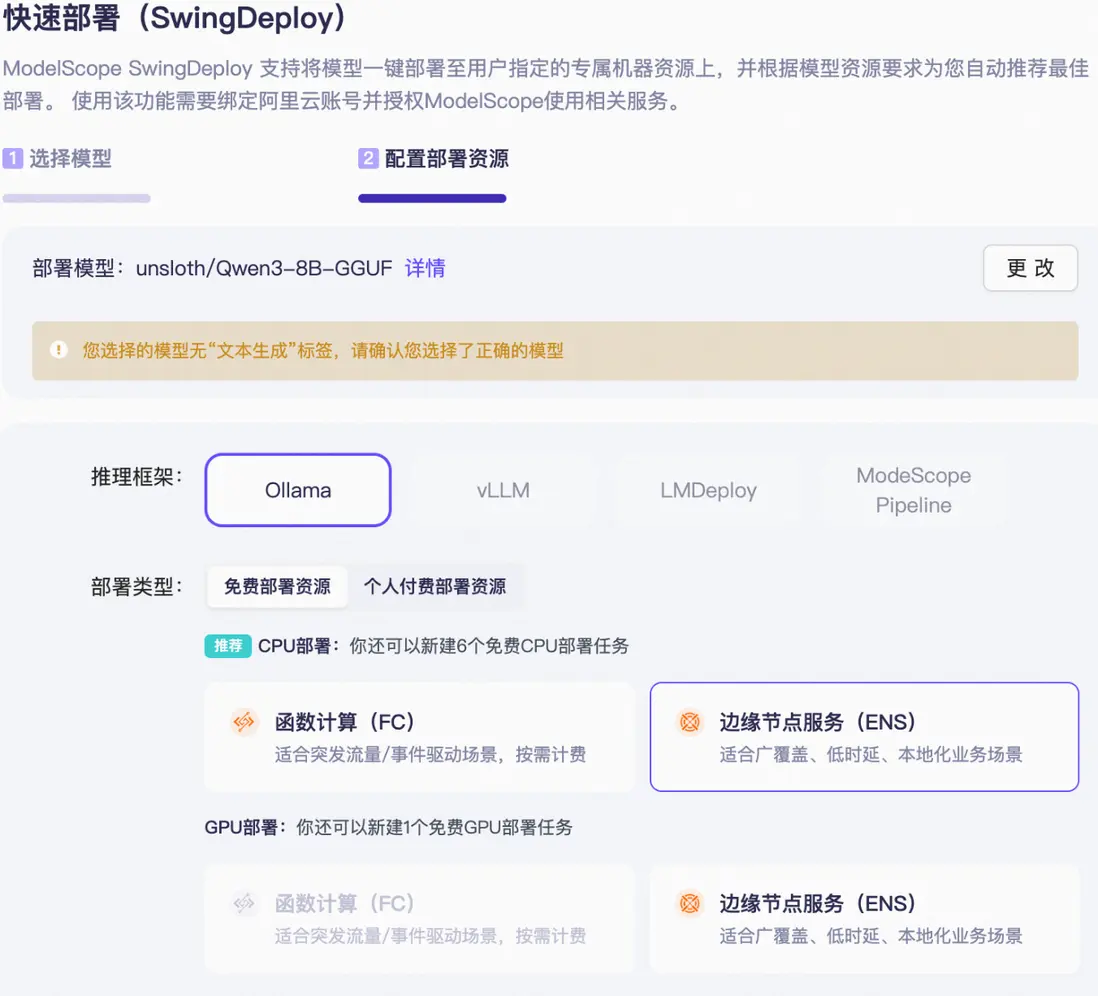
SwingDeploy 基礎配置設置
單賬號配額:
- 支持10個免費 CPU 服務實例、1個 GPU 服務實例。
- 當資源不夠時,服務創建會報錯,並且服務狀態為資源不足。
- 當前免費算力供應緊張,正在安排擴容,請保持關注。
|高級配置
- 支持在列表中更換模型文件,以選擇特定的量化版本。
- SwingDeploy 提供默認的 Modelfile配置文件,同時也支持用户自定義編輯。
- 如有需要,可自定義配置環境變量。
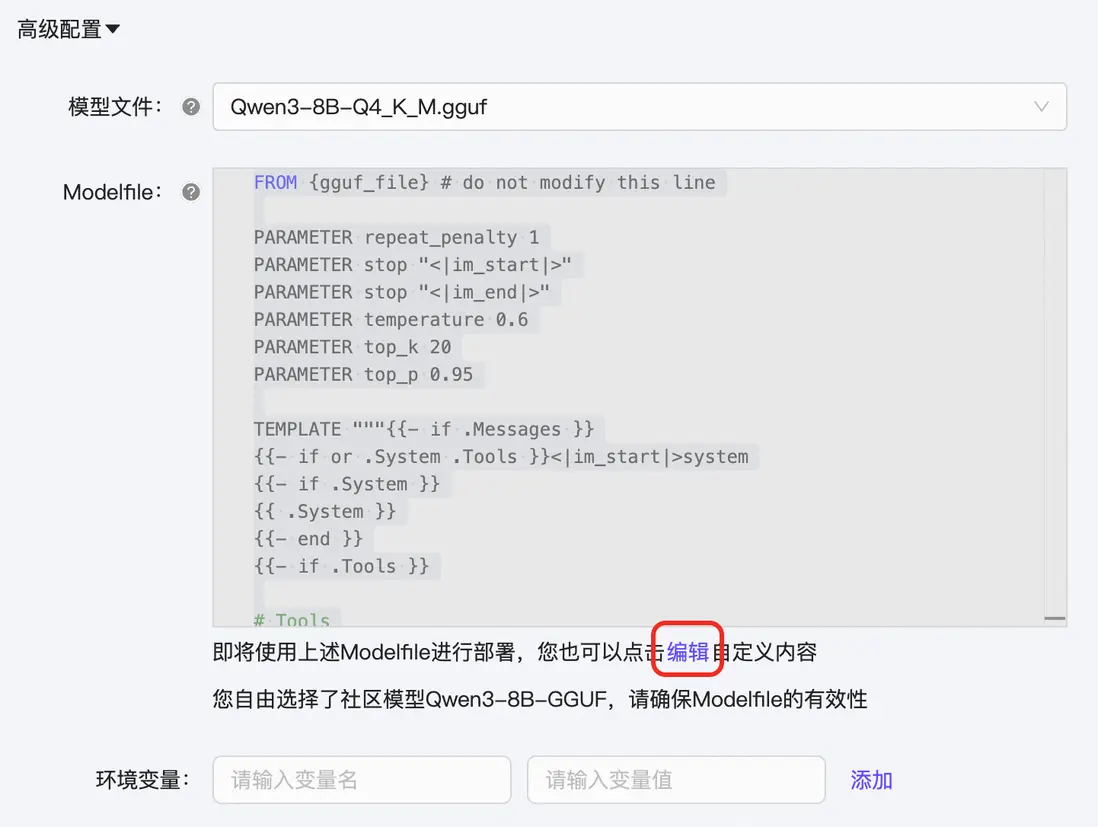
SwingDeploy 高級配置設置
完成上述操作後,點擊右下角“一鍵部署”按鈕,即可開始部署服務。
模型部署需要一定耗時,包括模型下載、製作、資源生產和部署,請您耐心等待。可以在 SwingDeploy 控制枱確認服務狀態。
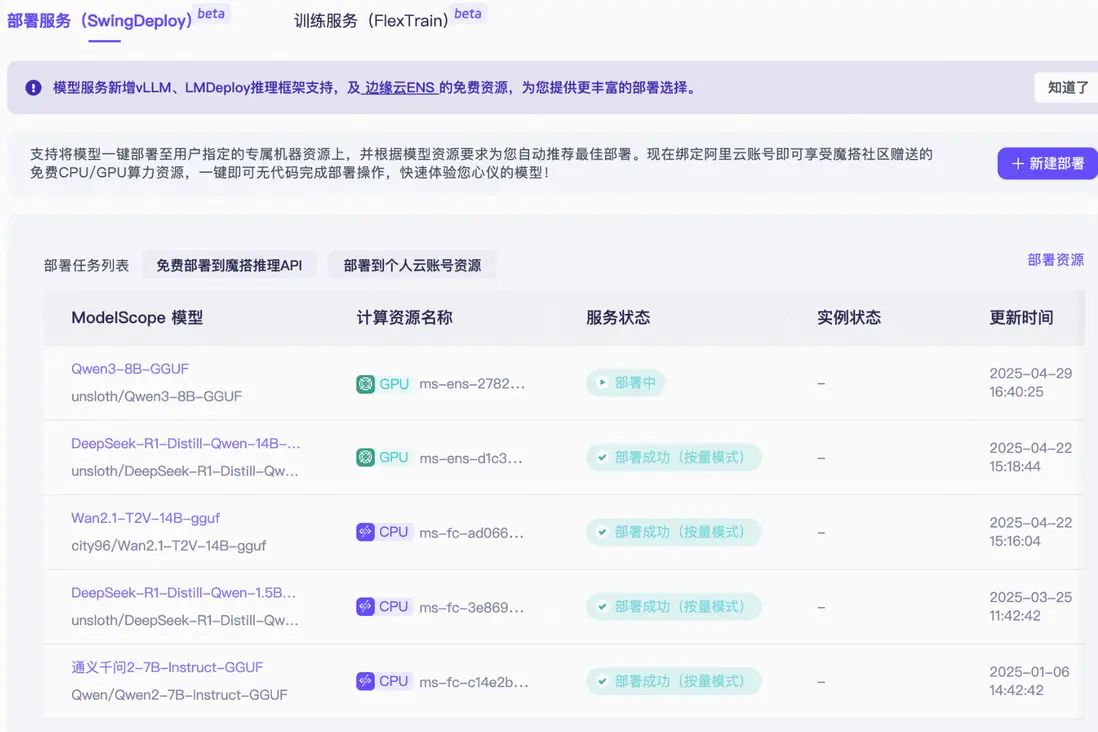
SwingDeploy 控制枱
03| 效果驗證
在部署任務列表中,點擊具體任務操作列下的“詳情”按鈕,即可查看任務詳情。詳情頁展示服務實例的創建時間、更新時間、實例類型、模型文件、推理框架、部署資源及參數等信息,並提供一份示例代碼,支持通過 OpenAPI SDK 進行調用。
以下代碼基於示例代碼改造,實現了一個簡易的終端問答Bot,用於測試模型效果。我們優化了終端的輸入輸出交互體驗。如需運行此代碼,請根據您在魔搭部署任務詳情頁中的配置信息,替換服務地址、API Key 以及模型路徑。
from openai import OpenAI
import sys
from prompt_toolkit import PromptSession
from prompt_toolkit.styles import Style
import time
import tiktoken
import shutil
# 初始化 OpenAI 客户端,base_url,api_key,model請按實際情況填寫。
client = OpenAI(
base_url=<填寫魔搭側的服務地址>,
api_key=<填寫魔搭側的服務api_key>
)
model = <填寫模型路徑,如unsloth/Qwen3-8B-GGUF>
def num_tokens_from_string(string: str) -> int:
"""計算文本中的 tokens 數量"""
encoding = tiktoken.get_encoding("cl100k_base")
num_tokens = len(encoding.encode(string))
return num_tokens
def get_terminal_size():
"""獲取終端大小"""
return shutil.get_terminal_size()
def clear_current_line():
"""清除當前行"""
terminal_width = get_terminal_size().columns
print('\r' + ' ' * terminal_width + '\r', end='', flush=True)
def chat_with_model():
# 創建 prompt session 和自定義樣式
session = PromptSession()
style = Style.from_dict({
'prompt': '#00aa00 bold',
})
messages = [
{
'role': 'system',
'content': '你是一個有幫助的助手。'
}
]
print("歡迎使用AI助手!輸入'退出'或'quit'可以結束對話。")
while True:
try:
# 使用 prompt_toolkit 處理輸入
user_input = session.prompt('\n你: ', style=style)
if user_input.lower() in ['退出', 'quit']:
print("再見!")
break
messages.append({
'role': 'user',
'content': user_input
})
print("\nAI助手: ", end='', flush=True)
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True
)
full_response = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end='', flush=True)
full_response += content
end_time = time.time()
elapsed_time = end_time - start_time
# 計算 tokens
response_tokens = num_tokens_from_string(full_response)
tokens_per_second = response_tokens / elapsed_time
# 確保統計信息顯示在新行,並在顯示後額外添加換行
print("\n") # 先確保有一個空行
stats = f"[統計] 響應tokens: {response_tokens}, 用時: {elapsed_time:.2f}秒, 速率: {tokens_per_second:.2f} tokens/s"
print(stats)
print() # 添加額外的換行確保滾動
sys.stdout.flush() # 強制刷新輸出緩衝區
messages.append({
'role': 'assistant',
'content': full_response
})
except Exception as api_error:
print(f"\n請求API時發生錯誤: {str(api_error)}")
print() # 額外的換行
continue
except KeyboardInterrupt:
print("\n\n檢測到中斷,正在退出...")
print() # 額外的換行
break
except Exception as e:
print(f"\n發生錯誤: {str(e)}")
print() # 額外的換行
continue
if __name__ == "__main__":
try:
chat_with_model()
except Exception as e:
print(f"程序發生錯誤: {str(e)}")
print() # 額外的換行
sys.exit(1)服務運行後,效果展示如下:
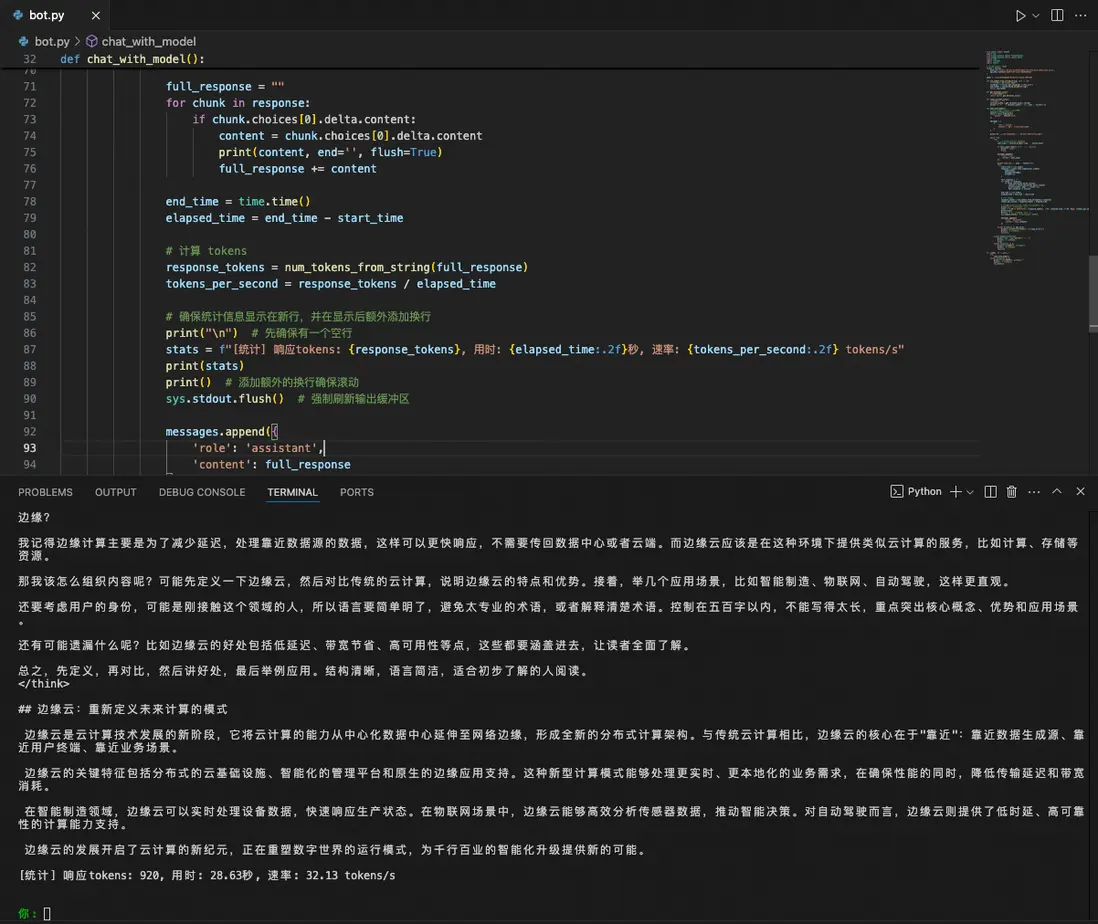
服務運行後,效果展示
https://www.youku.com/video/XNjQ4NjA2MTg0MA==
服務運行後,效果視頻展示
通過本文的介紹,我們展示了如何利用魔搭社區(ModelScope)與阿里雲邊緣雲ENS相結合,快速部署和驗證大模型的實際效果。
未來,隨着大模型技術的不斷演進和應用場景的持續拓展,我們相信這種“模型即服務”(MaaS)的模式將為更多企業和開發者帶來創新機遇。
希望本文能為您提供有價值的參考,也期待您在實際項目中探索出更多可能性。
讓我們一起擁抱大模型時代,共同推動技術落地與業務升級!



