









大家好!今天我們來聊一個 MySQL 核心知識點:B+樹索引的查詢過程。可能你每天都在用SELECT語句查詢數據,但你想過這背後到底發生了什麼嗎?MySQL 是怎麼從成千上萬的數據中快速找到你要的那一條記錄的?帶着這個問題,我們一起揭開 MySQL B+樹索引的神秘面紗!
先説説為什麼 MySQL 選擇 B+樹?
在聊查詢過程前,我們得先明白 MySQL 為啥選 B+樹做索引結構。想象一下,如果數據庫用簡單的數組存儲數據,要找一個值就得從頭遍歷到尾,這也太慢了!
B+樹有幾個超棒的特點:
- 它是一個多叉平衡樹,高度很低(通常 3-4 層就能存儲上百萬數據)
- 所有數據都存在葉子節點,中間節點只存儲分隔鍵和子節點指針
- 葉子節點通過鏈表相連,方便範圍查詢
與其他索引結構相比:
- 哈希索引:雖然等值查詢速度極快(O(1)),但無法支持範圍查詢和排序
- 二叉樹:樹高太高,I/O 次數多
- B 樹:與 B+樹最大的區別在於,B 樹的非葉子節點也存儲完整數據,這導致每個節點能容納的鍵值對更少,相同數據量下 B 樹高度更高,查詢需要更多 I/O 操作。此外,B 樹不支持葉節點間的鏈表,範圍查詢時可能需要回到父節點多次尋路,效率低下
MySQL 的存儲結構:頁是核心
在深入 B+樹查詢前,我們得了解 MySQL 的存儲單位——頁(Page)。
想象一下,如果你有一本書要查找內容,你肯定不是一個字一個字地找,而是一頁一頁地翻。MySQL 也是這樣,它以頁為單位讀取數據。
一個頁通常是 16KB,裏面可能包含很多行記錄。當 MySQL 需要讀取數據時,不是讀取單條記錄,而是將整個頁加載到內存的緩衝池中。
緩衝池管理機制
緩衝池不僅僅是簡單的內存空間,它採用了改進的 LRU(最近最少使用)算法:
- 新讀取的頁不會直接放入 LRU 列表頭部,而是放入 midpoint 位置(默認是 5/8 處)
- 頻繁訪問的頁會被移到列表頭部,長時間不用的頁會被淘汰
- 支持預讀(Read-Ahead)機制,當順序讀取多個頁時,系統會預先加載後續可能用到的頁
一個具體例子:員工表查詢
我們創建一個簡單的員工表來演示 B+樹查詢過程:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
department VARCHAR(50),
salary DECIMAL(10,2),
INDEX idx_age (age)
);假設表中已有上萬條數據,為了演示完整流程,我們將展示兩種查詢:
-- 使用主鍵索引(聚簇索引)的查詢
SELECT * FROM employees WHERE id = 12345;
-- 使用二級索引的查詢(涉及回表)
SELECT * FROM employees WHERE age = 28;B+樹索引查詢的完整過程
1. 從緩衝池查找數據頁
MySQL 首先檢查這條數據是否已經在內存的緩衝池(Buffer Pool)中。如果在,直接從內存獲取,非常快!如果不在,就需要從磁盤讀取。
2. 定位表空間文件
如果數據不在內存中,MySQL 會定位到這張表的表空間文件(ibd 文件)。
3. 從 B+樹的根節點開始查找
MySQL 通過數據字典找到表的根頁(root page),這是 B+樹的入口。
4. 逐層向下查找
假設我們的 B+樹有 3 層,使用主鍵查找(id=12345)的過程如下:
第一層(根節點):
- 頁中存儲了多個鍵值對,例如鍵 1000 指向頁號 A,鍵 5000 指向頁號 B,鍵 10000 指向頁號 C...
- 系統比較 12345 和這些鍵:12345 > 10000,所以繼續查找頁號 C 對應的子節點
第二層(內部節點):
- 加載頁號 C 到內存
- 頁中可能包含鍵 10000 指向頁號 D,鍵 12000 指向頁號 E,鍵 15000 指向頁號 F...
- 12345 > 12000 且 12345 < 15000,所以繼續查找頁號 E 對應的子節點
第三層(葉子節點):
- 加載頁號 E 到內存
- 這一頁包含了實際的數據記錄,系統在頁內進行搜索
- 找到 id=12345 的完整記錄並返回
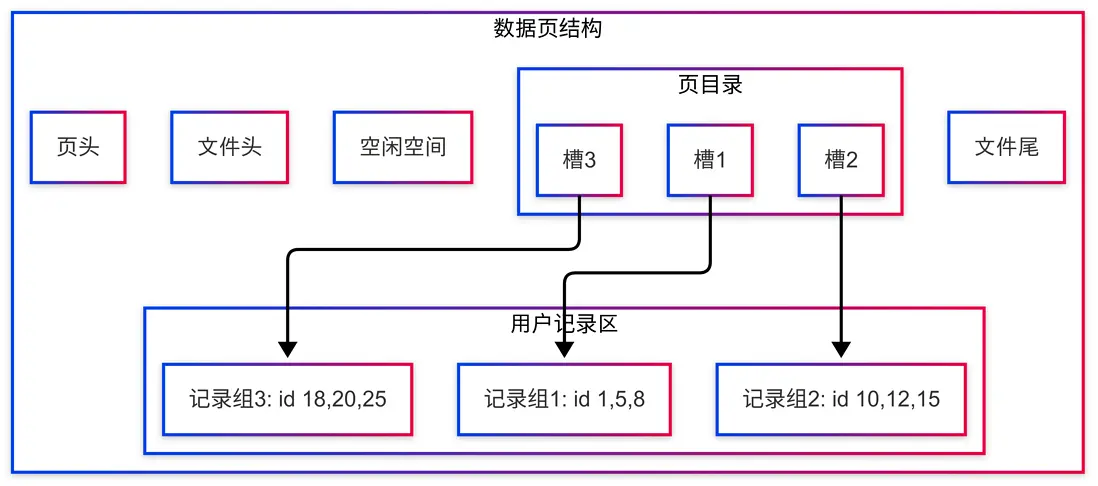
5. 數據頁內的查找
當定位到葉子節點的數據頁後,MySQL 不是線性遍歷頁內的所有記錄,而是使用頁目錄(Page Directory)進行查找:
- 頁目錄由多個"槽"(slot)組成,每個槽指向一個記錄組的最後一條記錄
- 系統先對頁目錄進行二分查找,找到記錄可能所在的記錄組
- 然後在該記錄組內從前往後順序查找目標記錄
InnoDB 的聚簇索引與回表操作
在 InnoDB 存儲引擎中,表數據文件本身就是按 B+樹組織的一個索引結構,這個索引的 key 是數據表的主鍵,被稱為"聚簇索引"(也叫主鍵索引)。聚簇索引的葉子節點存放的就是整張表的行記錄數據。
也就是説:數據文件本身就是主鍵索引的一部分!這與其他索引不同,其他索引(稱為二級索引或輔助索引)的葉子節點只存儲索引列和主鍵值,不包含行的全部數據。
如果使用SELECT * FROM employees WHERE age = 28;這樣的查詢,過程會有所不同:
- 首先沿着 age 索引的 B+樹查找,定位到 age=28 的記錄
- 但二級索引的葉子節點只存儲了索引列(age)和主鍵值(id)
- 系統獲取到主鍵值後,需進行"回表"操作:再次查詢主鍵索引(聚簇索引)獲取完整記錄
- 實際發生兩次 B+樹查詢:一次在二級索引樹上,一次在聚簇索引樹上
這就是為什麼通過主鍵查詢比二級索引查詢更快—前者只需一次樹的遍歷,後者需要遍歷兩棵樹。
範圍查詢是怎麼工作的?
如果我們執行範圍查詢:
SELECT * FROM employees WHERE age BETWEEN 25 AND 30;B+樹的優勢就體現出來了:
- 系統先定位到第一個滿足條件的記錄(age=25)
- 然後利用葉子節點間的鏈表指針,順序掃描直到超出條件(age>30)
- 無需回到上層節點重新查找,非常高效
對比下全表掃描與索引範圍掃描的 I/O 差異:
- 全表掃描:需要讀取整個表的所有頁,假設有 1000 個頁,就需要 1000 次 I/O
- 索引範圍掃描:假設 age=25 到 age=30 的記錄只分布在 5 個頁上,只需要 5 次 I/O 就能完成查詢
此外,範圍查詢通過葉節點鏈表能實現順序 I/O(連續讀取),而全表掃描可能導致大量隨機 I/O,性能差距更大。
常見問題及解決方案
問題 1:為什麼有時候創建了索引查詢還是很慢?
原因分析: 可能是出現了回表查詢。當查詢的字段不全在索引中時,MySQL 需要先通過索引找到主鍵值,再通過主鍵索引查找完整記錄。
解決方案: 可以考慮創建覆蓋索引,即索引包含查詢需要的所有字段。例如:
-- 如果經常查詢age和department,可以創建聯合索引
CREATE INDEX idx_age_dept ON employees(age, department);
-- 使用這個查詢就能直接從索引獲取數據,不需回表
SELECT age, department FROM employees WHERE age = 28;問題 2:如何判斷查詢是否用了索引?
解決方案: 使用 EXPLAIN 命令分析 SQL 執行計劃
EXPLAIN SELECT * FROM employees WHERE age = 28;EXPLAIN 結果中的關鍵字段:
- "key"列:顯示使用的索引名稱,如果為 NULL 則表示未使用索引
- "rows"列:估計需要掃描的行數,越少越好
-
"type"列:顯示連接類型,從好到差依次是:
- system/const:通過主鍵或唯一索引定位單條記錄
- ref:使用非唯一索引查找
- range:範圍查詢
- index:全索引掃描
- ALL:全表掃描,意味着沒有使用索引
例如,如果看到 type=ALL,即使有創建索引也説明沒有被使用。
問題 3:為什麼有時候明明有索引,MySQL 卻不使用?
原因分析:
- 如果表很小,全表掃描可能更快
- 如果查詢的數據量超過表的大約 20-30%,MySQL 認為全表掃描更高效
- 如果索引字段使用了函數或運算
- 如果索引列使用了
LIKE '%關鍵詞%'(前綴通配符) - 如果使用
OR條件且部分列無索引 - 如果索引列的數據分佈極度傾斜(如 90%是同一個值)
解決方案:
確保 SQL 語句不對索引字段做函數運算:
-- 不會使用索引
SELECT * FROM employees WHERE YEAR(birth_date) = 1990;
-- 改寫後會使用索引
SELECT * FROM employees WHERE birth_date BETWEEN '1990-01-01' AND '1990-12-31';B+樹在實際場景中的表現
讓我們看一個真實場景:假設我們的 employees 表有 100 萬條記錄,使用 InnoDB 引擎,默認頁大小 16KB。
對於主鍵 id 索引:
- 考慮到 InnoDB 的頁結構開銷,實際每個索引頁能存儲的索引項通常少於理論值
- 假設中間節點每個索引項約 20 字節(整數 id + 子頁指針)
- 考慮頁結構開銷後,一個頁實際可能存儲約 700 個索引項
- 若是 3 層 B+樹,大致可索引約 3.43 億條記錄(700³)
但需注意,實際存儲容量會受到多種因素影響:
- 不同數據類型大小不同
- 可變長度字段會影響每頁存儲的記錄數
- 中間節點和葉子節點的結構不完全相同
知識總結
| 知識點 | 描述 | 重要性 |
|---|---|---|
| B+樹結構 | 多路平衡樹,所有數據在葉子節點,中間節點存儲分隔鍵和指針,葉節點通過鏈表相連 | ⭐⭐⭐⭐⭐ |
| 聚簇索引 | InnoDB 中,數據文件本身就是主鍵索引的一部分,葉子節點包含完整行數據 | ⭐⭐⭐⭐⭐ |
| 頁 | MySQL 的基本 I/O 單位,默認 16KB,包含多條記錄 | ⭐⭐⭐⭐ |
| 緩衝池 | 內存中的數據緩存,使用改進的 LRU 算法管理,減少磁盤 I/O | ⭐⭐⭐⭐ |
| 查詢過程 | 從根節點開始,根據鍵值比較逐層向下,最後在頁內使用頁目錄快速定位 | ⭐⭐⭐⭐⭐ |
| 回表查詢 | 通過二級索引找到主鍵值,再經由聚簇索引獲取完整記錄 | ⭐⭐⭐⭐ |
| 覆蓋索引 | 索引包含查詢所需的所有字段,避免回表 | ⭐⭐⭐⭐ |
| 範圍查詢 | 利用葉節點鏈表高效進行範圍掃描,減少 I/O 次數並實現順序讀取 | ⭐⭐⭐⭐ |
| 頁目錄 | 加速頁內記錄查找的數據結構,通過"槽"指向不同記錄組 | ⭐⭐⭐ |
| 執行計劃 | 通過 EXPLAIN 分析查詢執行情況,特別關注 type、key、rows 等字段 | ⭐⭐⭐⭐ |
通過理解 MySQL B+樹索引的工作原理,我們能更好地設計數據庫結構和優化查詢語句。下次當你執行一條 SELECT 語句時,你就能清楚地知道 MySQL 在背後做了哪些工作!
感謝您耐心閲讀到這裏!如果覺得本文對您有幫助,歡迎點贊 👍、收藏 ⭐、分享給需要的朋友,您的支持是我持續輸出技術乾貨的最大動力!
如果想獲取更多 Java 技術深度解析,歡迎點擊頭像關注我,後續會每日更新高質量技術文章,陪您一起進階成長~











