









在開發多線程應用時,你是否曾遇到這樣的困擾:隨着併發量增加,系統性能不升反降?特別是在計數器場景下,本應簡單的自增操作卻成了性能瓶頸。這正是許多 Java 開發者共同面臨的痛點。當線程數超過 CPU 核心數或競爭激烈時,AtomicLong 的 CAS 操作不斷失敗重試,CPU 使用率飆升,而業務處理效率卻直線下降。這也是為什麼阿里巴巴在其開發規範中明確推薦使用 LongAdder 來替代傳統方案。
LongAdder 是什麼
LongAdder 是 Java 8 在java.util.concurrent.atomic包中引入的一個新的原子性操作類,專為高併發環境下的計數場景設計。與傳統的 AtomicLong 相比,它採用了更加優化的內部實現,能夠有效減少線程間的競爭,提高併發性能。
為什麼需要 LongAdder
在分析 LongAdder 的優勢前,我們先了解傳統方案 AtomicLong 的問題:
AtomicLong 的性能瓶頸
AtomicLong 主要依賴 CAS(Compare-And-Swap)操作保證原子性。當多線程同時更新同一個計數器時,會出現以下問題:
- 激烈的競爭:所有線程競爭同一個值的更新權
- 頻繁的失敗和重試:CAS 操作在高併發下失敗率高
- CPU 空轉:頻繁 CAS 重試導致 CPU 資源浪費
- CAS 競爭熱點:多線程爭搶同一變量更新權,形成系統瓶頸
下面是 AtomicLong 的主要更新方法實現:
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}這種實現在高併發下會導致大量線程自旋等待,形成"CAS 競爭熱點"問題。
LongAdder 的實現原理
LongAdder 採用了"分段累加"的設計思想,巧妙地避開了 AtomicLong 面臨的競爭問題。
核心設計:分段計數
LongAdder 內部維護了一個基礎值 base 和一個 Cell 數組。這裏可以把它想象成一個"分佈式計數器":
線程哈希計算偽代碼:
線程哈希 = ThreadLocalRandom.getProbe();
cellIndex = 線程哈希 & (cells.length - 1); // 位運算提高效率工作流程如下:
- 無競爭時很簡單:所有線程都更新 base 值,性能接近 AtomicLong
- 出現競爭後動態分流:不同線程被分配到不同的 Cell 格子去更新,互不干擾
- 結果計算設計簡潔:base 值加上所有 Cell 值的總和
這種設計就像銀行櫃枱:人少時一個窗口就夠了(base);人多時開放多個窗口(Cells),每個客户去不同窗口辦理,互不影響,效率大大提高。
內存佔用對比
LongAdder 採用了空間換時間的設計思路,下面是 AtomicLong 與 LongAdder 的內存佔用對比:
Cell 類與偽共享問題
Cell 類是 LongAdder 內部的核心組件,它使用了@Contended註解避免偽共享問題:
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// CAS更新方法
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
}偽共享(False Sharing):當多個線程頻繁修改位於同一 CPU 緩存行的不同變量時,即使變量無關,也會因緩存一致性協議導致緩存行頻繁失效,降低性能。@Contended通過填充字節使Cell實例獨佔緩存行,避免此問題。值得注意的是,在 OpenJDK 中,@Contended註解默認僅對 JDK 內部類生效,外部應用需通過-XX:-RestrictContended參數啓用。
這就像在超市購物:如果相鄰的收銀台共用一個出口通道,一個收銀台的顧客在結賬會影響另一個收銀台顧客的通行。@Contended註解相當於給每個收銀台都建立了獨立的出口通道,避免了這種無謂的等待。
動態擴容機制
LongAdder 不會一開始就創建很多 Cell,而是按需增長:
- 初始狀態節省內存:只有一個 base 值,所有線程都往這裏加數
- 競爭時才擴容:當發現 base 更新衝突,才初始化 Cell 數組(初始大小為 2)
- 持續優化分配:線程通過
ThreadLocalRandom.getProbe()生成哈希值映射到對應 Cell
當 Cell 更新失敗時,longAccumulate方法會:
- 重試更新:通過
ThreadLocalRandom.advanceProbe()生成新的哈希值,避持續衝突 - 擴容 cells 數組:若重試多次失敗,且 cells 長度小於
2^24,則將數組長度翻倍(2→4→8),擴容上限為2^24,以避免無限制增長 - 處理極端情況:當擴容後仍衝突,或系統資源緊張時,會通過自旋(
Thread.yield())或短暫休眠減少 CPU 佔用,避免活鎖
需要注意的是,即使在最理想的情況下,當線程數極多時(如接近2^24),或者哈希衝突嚴重時,LongAdder 也可能退化為類似 AtomicLong 的競爭模式,只是概率大大降低。
關鍵代碼解析
LongAdder 的核心方法 add()實現(簡化版):
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
// 如果Cells數組已初始化 或者 更新base值失敗(説明有競爭)
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
// 如果Cells數組未初始化 或 當前線程的Cell未初始化 或 更新Cell失敗
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}sum()方法獲取最終值:
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}sum()方法本身是線程安全的(不需要額外同步),但呈現的是弱一致性結果,它在讀取時不會阻塞寫操作,可能讀到部分更新的中間狀態(如某Cell正在被更新時讀取其舊值)。這與 AtomicLong 的get()方法提供的強一致性形成對比。但當所有寫操作完成後,多次調用sum()結果會一致(最終一致性),這對統計類場景(如 QPS、總量計數)已經足夠。
工作原理圖解
性能測試與對比
下面通過一個簡單的性能測試,對比 LongAdder 和 AtomicLong:
import java.util.concurrent.*;
import java.util.concurrent.atomic.*;
public class CounterPerformanceTest {
private static final int ITERATIONS = 100000;
public static void main(String[] args) throws Exception {
// 測試不同線程數下的性能
for (int threadCount : new int[]{10, 100, 500, 1000, 2000}) {
System.out.println("測試線程數: " + threadCount);
testAtomicLong(threadCount);
testLongAdder(threadCount);
System.out.println();
}
}
private static void testAtomicLong(int threadCount) throws Exception {
final AtomicLong counter = new AtomicLong(0);
long start = System.currentTimeMillis();
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
for (int j = 0; j < ITERATIONS; j++) {
counter.incrementAndGet();
}
});
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.HOURS);
long end = System.currentTimeMillis();
System.out.println("AtomicLong: " + (end - start) + "ms, Result: " + counter.get());
}
private static void testLongAdder(int threadCount) throws Exception {
final LongAdder counter = new LongAdder();
long start = System.currentTimeMillis();
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
for (int j = 0; j < ITERATIONS; j++) {
counter.increment();
}
});
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.HOURS);
long end = System.currentTimeMillis();
System.out.println("LongAdder: " + (end - start) + "ms, Result: " + counter.sum());
}
}測試結果
測試環境:Intel i7-10700K(8 核 16 線程),JDK 11.0.12,OpenJDK 64 位,內存 16GB
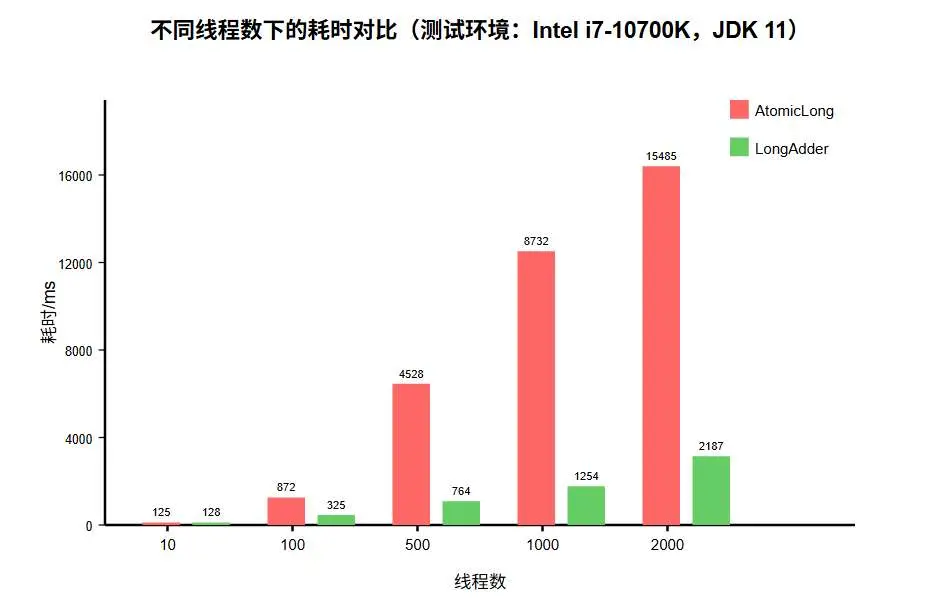
可以看到幾個有趣的現象:
- 在低併發(10 線程)時,AtomicLong 甚至略快於 LongAdder,這是因為 LongAdder 有額外的判斷邏輯
- 隨着線程數的增加,AtomicLong 性能直線下降,而 LongAdder 的性能下降相對平緩
- 在 2000 線程的場景下,在測試環境中 LongAdder 的性能約為 AtomicLong 的 7 倍
這就像高峯時段的馬路:單車道會越來越堵,而多車道則能保持較高的通行效率。但在車輛稀少時,單車道反而更簡單高效。
性能差異原因分析
- 減少爭用:LongAdder 通過分散更新不同的 Cell,大大減少了線程間的競爭
- 降低失敗率:每個線程更可能操作不同的 Cell,CAS 操作成功率更高
- 提高並行度:多個線程可以並行更新不同的計數單元,而不是串行等待
- 避免偽共享:Cell 類使用了@Contended 註解,避免了緩存行偽共享問題
實際應用場景
LongAdder 特別適合以下場景:
- 高併發計數:如系統運行狀態監控、QPS 統計
- 性能指標收集:統計接口調用次數、成功率等
- 限流計數器:短時間內的請求量統計
- 緩存命中率統計:記錄緩存命中和未命中次數
選擇正確的計數器
根據不同場景選擇合適的計數器工具:
// 場景1: 需要原子條件更新的場景 - 使用AtomicLong
AtomicLong sequencer = new AtomicLong(0);
// 生成下一個序列號,同時確保不超過最大值
long nextId = sequencer.updateAndGet(current ->
current < MAX_SEQUENCE ? current + 1 : current);
// 場景2: 高併發計數統計場景 - 使用LongAdder
LongAdder totalRequests = new LongAdder();
// 多線程併發調用
totalRequests.increment();
// 定時任務彙總打印
scheduler.scheduleAtFixedRate(() -> {
System.out.println("當前總請求數: " + totalRequests.sum());
}, 0, 5, TimeUnit.SECONDS);應用示例:接口監控計數器
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.LongAdder;
import java.util.concurrent.Executors;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.TimeUnit;
public class ApiMetricsCounter {
private final ConcurrentHashMap<String, LongAdder> apiCounters = new ConcurrentHashMap<>();
public void recordApiCall(String apiName) {
// 獲取或創建對應API的計數器
apiCounters.computeIfAbsent(apiName, k -> new LongAdder()).increment();
}
public long getApiCount(String apiName) {
LongAdder counter = apiCounters.get(apiName);
return counter == null ? 0 : counter.sum();
}
public void printAllMetrics() {
apiCounters.forEach((api, counter) ->
System.out.println(api + ": " + counter.sum() + " calls"));
}
// 使用示例
public static void main(String[] args) throws Exception {
ApiMetricsCounter metrics = new ApiMetricsCounter();
// 模擬多線程調用
ExecutorService executor = Executors.newFixedThreadPool(100);
for (int i = 0; i < 1000; i++) {
final int index = i % 3;
executor.submit(() -> {
String api = "api" + index;
metrics.recordApiCall(api);
});
}
executor.shutdown();
executor.awaitTermination(10, TimeUnit.SECONDS);
// 打印結果
metrics.printAllMetrics();
}
}生產環境監控集成
在實際的生產環境中,可以使用 Micrometer 等監控框架來採集 LongAdder 的數據,避免頻繁調用sum():
// 使用Micrometer監控LongAdder
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.FunctionCounter;
public class MetricsService {
private final LongAdder requestCounter = new LongAdder();
public MetricsService(MeterRegistry registry) {
// 註冊LongAdder到Micrometer,自動定期採集數據
FunctionCounter.builder("api.requests", requestCounter, LongAdder::sum)
.description("API請求總數")
.register(registry);
}
public void recordRequest() {
requestCounter.increment();
}
}LongAdder 的注意事項
雖然 LongAdder 性能優越,但也有一些使用注意事項:
- 內存佔用:LongAdder 內部的 Cell 數組會佔用更多內存。AtomicLong 只有一個 value 變量(約 24 字節),而 LongAdder 的每個 Cell 因為@Contended 註解佔用約 128 字節(一個緩存行大小)。就像高速公路:單車道省地但容易堵,多車道通行效率高但佔地多。
- 非精確讀取:在高併發更新時調用
sum(),結果可能不是實時準確的,因為求和過程中可能有新的更新發生。這就像統計進出商場的人數,你在數的過程中可能有人進出,導致結果有輕微偏差。 - 哈希衝突:當線程數遠超 Cell 數組大小時,可能多個線程映射到同一個 Cell,造成局部熱點。以下是一個簡單的工具,幫助你檢查 Cell 數組狀態:
// 調試用:查看LongAdder的Cell分佈情況
// 注意:反射調用非公開API,可能導致兼容性問題,僅用於調試分析
private static void checkCellDistribution(LongAdder adder) {
try {
// 反射獲取cells字段
Field cellsField = LongAdder.class.getDeclaredField("cells");
cellsField.setAccessible(true);
Object[] cells = (Object[]) cellsField.get(adder);
if (cells == null) {
System.out.println("cells數組未初始化,所有線程更新base值");
return;
}
System.out.println("Cell數組大小: " + cells.length);
for (int i = 0; i < cells.length; i++) {
if (cells[i] != null) {
Field valueField = cells[i].getClass().getDeclaredField("value");
valueField.setAccessible(true);
long value = (long) valueField.get(cells[i]);
System.out.println("Cell[" + i + "] 值: " + value);
} else {
System.out.println("Cell[" + i + "] 未創建");
}
}
} catch (Exception e) {
e.printStackTrace();
}
}性能優化建議
若通過調試工具發現某Cell競爭激烈(如Cell[0]值遠高於其他Cell),可通過 JVM 參數預設初始cells大小:
-Djava.util.concurrent.atomic.LongAdder.cellSize=32此參數需謹慎使用,默認初始cellSize為 2,擴容策略與線程競爭程度相關。通常不建議設置超過 CPU 核心數的 2-4 倍,盲目增大可能導致內存浪費,建議僅在確認存在嚴重哈希衝突時調整。
當sum()調用非常頻繁時(如高頻監控),可考慮使用sumThenReset()方法獲取並重置計數器,減少多次累加的開銷:
long total = counter.sumThenReset(); // 獲取當前總數並清零實際應用建議
基於以上分析,在實際開發中可以遵循以下建議:
- 在高併發統計場景(寫多讀少)下,優先使用 LongAdder 而非 AtomicLong
- 對於計數器類場景(如統計、度量),使用 LongAdder 能帶來顯著性能提升
- 需要精確原子操作(如序列號生成)的場景,仍然使用 AtomicLong
- 低併發場景下,兩者性能差異不大,可以根據實際需求選擇
總結
| 特性 | AtomicLong | LongAdder |
|---|---|---|
| 併發性能 | 較低,高併發下性能下降明顯 | 優秀,線程數越多優勢越明顯 |
| 內存佔用 | 低(約 24 字節) | 較高(base + N 個 Cell,每個 Cell 約 128 字節) |
| 精確性 | 實時精確(get()強一致) |
最終一致(sum()允許短暫不一致) |
| 適用場景 | 需要原子條件更新 | 統計類場景(高併發計數) |
| 實現複雜度 | 簡單,基於單個變量的 CAS 操作 | 複雜,涉及 base、Cell 數組、動態擴容、哈希映射等 |
| Java 版本 | Java 5+ | Java 8+ |
| 低並發表現 | 性能略好(實現簡單) | 略有額外開銷(判斷邏輯) |
LongAdder 通過巧妙的分段設計,有效解決了高併發下 AtomicLong 的性能瓶頸。這也是阿里巴巴在 Java 開發手冊中推薦使用 LongAdder 的主要原因。
在實際開發中,我們應根據應用場景選擇合適的工具。就像選擇交通工具:短途可以騎自行車(AtomicLong 簡單夠用),長途擁堵路段就需要高鐵(LongAdder 突破瓶頸)。對於監控、統計類高併發場景,LongAdder 通常是更優選擇;而對於需要精確原子操作的場景,AtomicLong 仍然是必要的。








