









還記得第一次遇到這種情況嗎?你寫了一段比較兩個 Integer 對象的代碼,有時候==返回 true,有時候卻返回 false,明明看起來是相同的值。這並非 Java 的"陷阱",而是 Integer 緩存池在默默工作。我第一次遇到這個問題時,足足調試了半小時才恍然大悟。今天,我們就來深入瞭解這個經常被忽視卻又至關重要的 Java 性能優化機制。
什麼是 Integer 緩存池?
Integer 緩存池(Integer Cache)是 JDK 內部維護的一個靜態緩存,用於存儲一定範圍內的 Integer 對象。當我們獲取這個範圍內的 Integer 對象時,Java 會直接返回緩存池中已有的對象,而不是創建新的實例,從而提高內存使用效率和程序性能。
Integer 緩存池本質是"享元模式(Flyweight Pattern)"的應用——通過共享細粒度對象,減少內存佔用並提高性能。Java 中,所有包裝類的緩存機制(如 Boolean 的 TRUE/FALSE 常量、Character 的 ASCII 範圍緩存)均遵循這一模式。
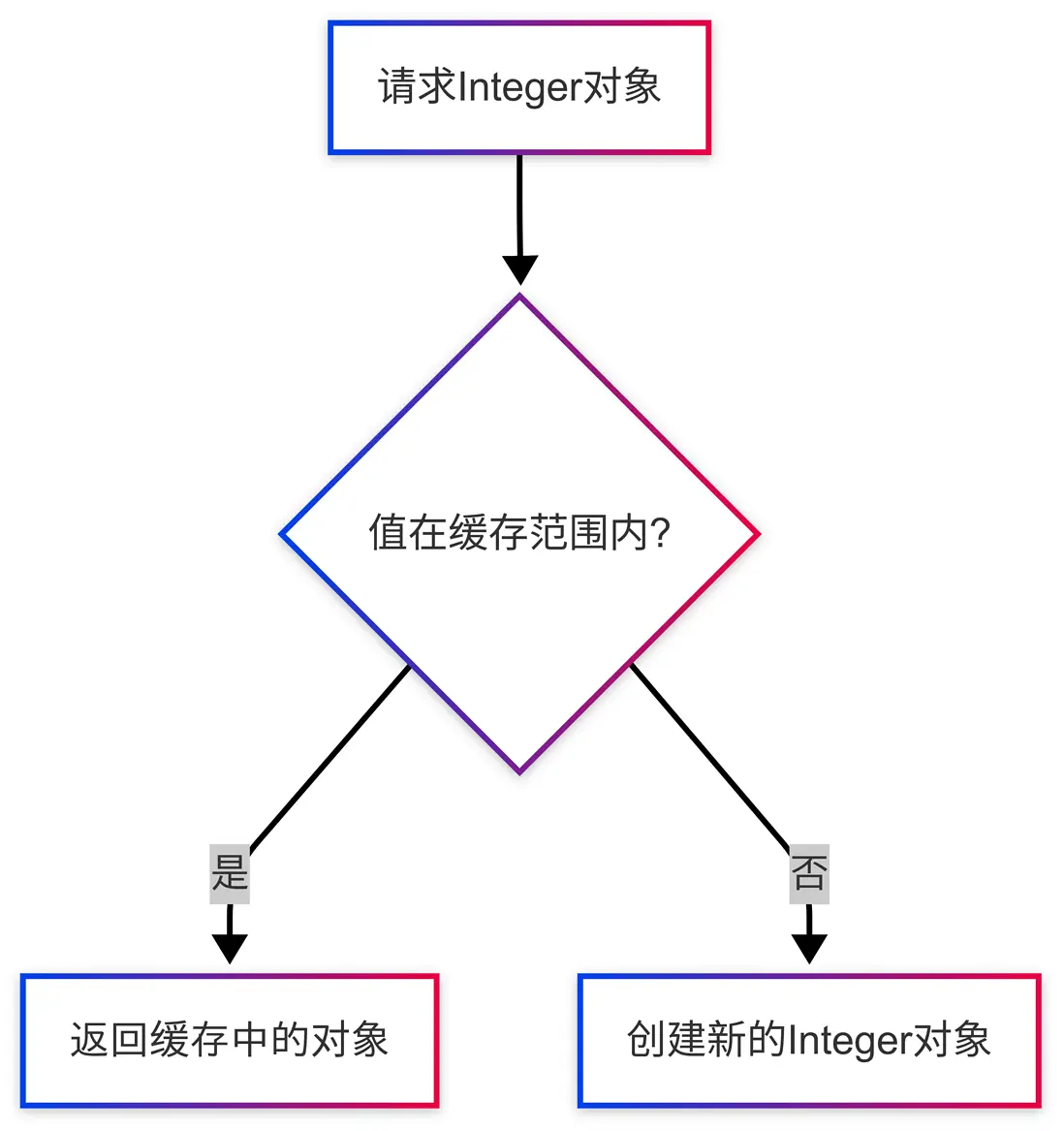
Integer 緩存池的核心案例
先看一段代碼:
Integer a = 100;
Integer b = 100;
System.out.println(a == b); // 輸出 true
Integer c = 200;
Integer d = 200;
System.out.println(c == d); // 輸出 false這段代碼的輸出結果是不是有點讓人困惑?為什麼相同值的比較結果會不同?這就是 Integer 緩存池在起作用。
緩存池的實現原理
打開 JDK 源碼,我們可以找到 Integer 類中的內部類 IntegerCache:
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer[] cache;
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
h = Integer.parseInt(integerCacheHighPropValue);
h = Math.max(h, 127); // 確保上限不低於默認值127
// Maximum array size is Integer.MAX_VALUE
h = Math.min(h, Integer.MAX_VALUE - (-low) - 1); // 避免數組越界
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
}
private IntegerCache() {}
}通過源碼我們可以看到,緩存池默認緩存的是-128 到 127 之間的 Integer 對象。IntegerCache 的緩存數組在類加載時初始化(靜態代碼塊執行),因此首次使用Integer類(如調用valueOf或自動裝箱)時,緩存已準備就緒。
IntegerCache 的設計體現了"空間換時間"的經典優化思想:通過提前創建常用小整數對象並複用,避免重複對象創建的開銷(如內存分配、垃圾回收)。這種設計在 JDK 中廣泛存在(如 String 池、Boolean 常量),是理解 Java 性能優化的重要切入點。
來看看valueOf()方法的實現:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}緩存池的工作流程如下:
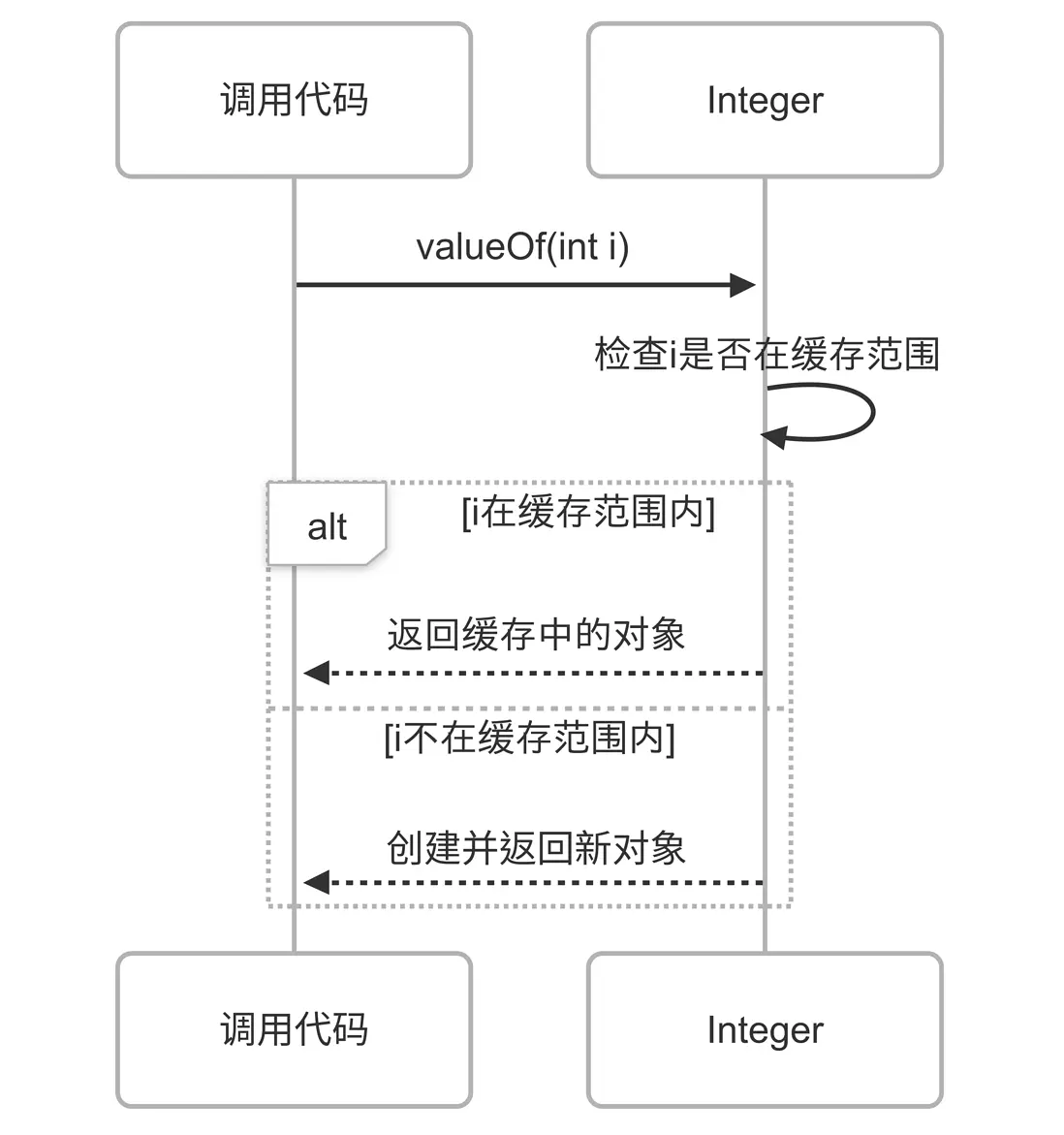
深入分析:自動裝箱與緩存池
理解了valueOf()的實現原理後,我們就能明白為什麼自動裝箱會觸發緩存機制——因為自動裝箱的本質就是調用valueOf()。
Java 5 引入了自動裝箱和拆箱機制,編譯器會自動將基本類型轉換為對應的包裝類對象,反之亦然。
// 自動裝箱
Integer num = 100; // 編譯器轉換為: Integer num = Integer.valueOf(100);
// 自動拆箱
int value = num; // 編譯器轉換為: int value = num.intValue();只要使用自動裝箱(如Integer num = 100;),編譯器必然調用valueOf()而非new Integer(),因此必然觸發緩存邏輯(除非值超出緩存範圍)。若顯式使用new Integer(int),則會繞過緩存,即使值在緩存範圍內也會創建新對象。
實際案例分析
下面通過一個更完整的例子來分析 Integer 緩存池的行為:
public class IntegerCacheDemo {
public static void main(String[] args) {
// 使用自動裝箱 - 緩存範圍內
Integer a1 = 100;
Integer a2 = 100;
System.out.println("a1 == a2: " + (a1 == a2)); // true
// 使用valueOf - 緩存範圍內
Integer b1 = Integer.valueOf(100);
Integer b2 = Integer.valueOf(100);
System.out.println("b1 == b2: " + (b1 == b2)); // true
// 使用構造器 - 不使用緩存
Integer c1 = new Integer(100);
Integer c2 = new Integer(100);
System.out.println("c1 == c2: " + (c1 == c2)); // false
// 緩存範圍外
Integer d1 = 200;
Integer d2 = 200;
System.out.println("d1 == d2: " + (d1 == d2)); // false
// new Integer與valueOf對比
Integer e1 = new Integer(100);
Integer e2 = Integer.valueOf(100);
System.out.println("e1 == e2: " + (e1 == e2)); // false(前者是新對象,後者取緩存)
System.out.println("e1.hashCode(): " + e1.hashCode()); // 100(值本身)
System.out.println("e2.hashCode(): " + e2.hashCode()); // 100(值本身)
// 總是使用equals比較值
System.out.println("d1.equals(d2): " + d1.equals(d2)); // true
}
}運行這段代碼,我們可以看到:
- 緩存範圍內的值通過自動裝箱和 valueOf 獲取的對象是同一個
- 使用 new 創建的對象永遠是新對象,即使值在緩存範圍內(如
new Integer(100)),也會創建新對象 - 超出緩存範圍的值(如 200),即使通過自動裝箱獲取,仍會創建新的 Integer 對象
- 雖然
e1和e2引用不同對象,但它們的hashCode()值相同(都是 100),這是因為 Integer 的哈希碼就是其 int 值 - 使用 equals 比較值而非引用,總是正確的做法
性能影響與內存優化
Integer 緩存池的設計初衷是優化性能和內存使用。默認緩存範圍(-128~127)的設定基於統計學:日常開發中高頻使用的小整數(如循環索引、狀態碼)多集中在此區間,緩存這些值可在內存佔用和性能提升之間取得平衡。
測試一下性能差異:
public class IntegerCachePerformance {
public static void main(String[] args) {
int iterations = 10_000_000;
// 測試使用緩存
long startTime = System.nanoTime();
for (int i = 0; i < iterations; i++) {
Integer num = 100; // 使用緩存池
}
long endTime = System.nanoTime();
System.out.println("使用緩存耗時: " + (endTime - startTime) / 1_000_000.0 + " ms");
// 測試不使用緩存
startTime = System.nanoTime();
for (int i = 0; i < iterations; i++) {
Integer num = new Integer(100); // 不使用緩存
}
endTime = System.nanoTime();
System.out.println("不使用緩存耗時: " + (endTime - startTime) / 1_000_000.0 + " ms");
}
}在筆者的測試環境中,使用緩存時每創建 1000 萬個 Integer 對象耗時約 2ms,而不使用緩存時耗時約 200ms,性能差距達 100 倍。這是因為new Integer()每次需經歷類加載、對象分配、構造函數調用等開銷,而緩存池直接返回已有對象引用。
這個簡單測試只是為了演示原理。真實項目中測試性能應該多次運行並排除首次執行(JIT 編譯影響),專業場景下可以用 JMH 等工具。
調整緩存池大小
如果你的程序中經常使用範圍超出默認緩存的整數,可以通過 JVM 參數調整緩存上限:
-Djava.lang.Integer.IntegerCache.high=1000這會將緩存上限從 127 提高到 1000,讓更多的 Integer 對象可以從緩存中獲取。需要注意的是:
- 下限
low=-128是固定值,不可通過參數修改 - 上限默認值
127可增大,但需注意內存佔用(緩存數組大小為high - low + 1,過大可能導致內存開銷)
若將上限設置為Integer.MAX_VALUE,緩存數組將包含2^31個對象(約 4GB 內存,未考慮對象頭開銷),這在實際應用中幾乎不可行。因此,調整上限時需根據業務場景權衡:僅將高頻使用的整數範圍納入緩存,避免內存溢出風險。
例如:若設置high=1000,緩存數組將存儲 1129 個 Integer 對象(1000 - (-128) + 1)。
調整緩存範圍後的行為變化:
// 假設通過-Djava.lang.Integer.IntegerCache.high=200啓動
Integer x = 200;
Integer y = 200;
System.out.println(x == y); // 輸出true(因200已被納入緩存)其他包裝類的緩存機制
不只是 Integer,Java 中的其他幾個包裝類也有類似的緩存機制:
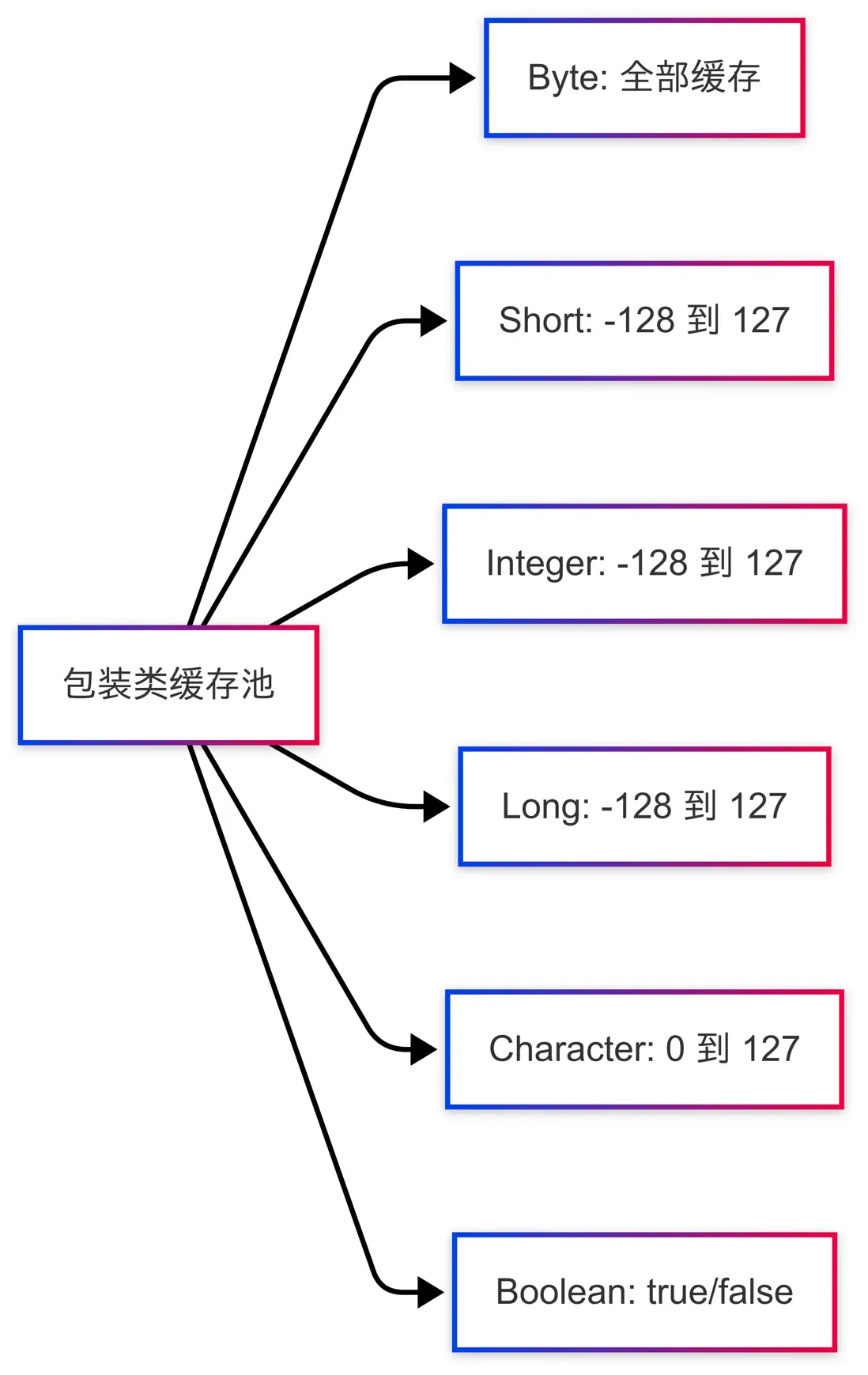
各包裝類緩存機制詳細對比:
| 包裝類 | 緩存支持 | 緩存範圍 | 備註 |
|---|---|---|---|
| Boolean | 是 | true/false(單例) | 通過Boolean.TRUE和Boolean.FALSE兩個靜態常量實現,本質是單例模式 |
| Byte | 是 | -128~127(固定) | 值域固定,全部緩存 |
| Short | 是 | -128~127(固定) | 同上 |
| Integer | 是 | -128~127(可調整上限) | 通過IntegerCache實現 |
| Long | 是 | -128~127(固定) | 同上 |
| Character | 是 | 0~127(固定) | 對應 ASCII 字符 |
| Double | 否 | 無 | 無緩存機制 |
| Float | 否 | 無 | 無緩存機制 |
常見誤區
在實際開發中,開發者常常會犯以下幾個錯誤:
- 誤以為所有小整數對象都共享引用:有些開發者認為所有的小整數都是同一個對象,但忽略了緩存範圍的限制,超出範圍(如 200)的 Integer 對象即使值相同也是不同對象。
-
認為
==可靠地比較整數值:即使瞭解緩存機制,也可能忽略對象來源(自動裝箱 vs 構造器)帶來的影響。看下面的例子:Integer x = 100; // 緩存對象 Integer y = new Integer(100); // 新對象 System.out.println(x == y); // false(引用不同) - 忽略不同 JVM 實現的差異:雖然 JDK 規範默認緩存範圍是-128~127,但不同 JVM 實現可能有微小差異,依賴確切範圍的代碼可能不具備跨平台性。
這些誤區的核心原因在於混淆了'值相等'和'引用相等',也提醒我們在開發中必須嚴格遵循'使用equals()比較值'的最佳做法(見下一節)。
開發中的注意事項
在實際開發中,由於緩存機制的存在,一定要注意以下幾點:
- 永遠不要使用
==比較兩個包裝類對象,除非你確切知道緩存機制的工作原理並清楚其後果 - 始終使用
equals()方法比較包裝類對象的值 - 如果要比較基本類型值,可以使用自動拆箱後再比較
- 注意緩存範圍,不要過分依賴緩存機制
- 當使用自動拆箱與基本類型比較時,需確保包裝類對象不為
null,否則會觸發 NPE
讓我用一個簡單的例子説明第 2 點和第 3 點:
// 正確的做法
Integer a = 1000;
Integer b = 1000;
// 1. 使用equals比較值
if(a.equals(b)) {
System.out.println("值相等");
}
// 2. 使用自動拆箱後比較基本類型
if(a.intValue() == b.intValue()) {
System.out.println("值相等");
}
// 或更簡單的形式
if(a == b.intValue()) {
System.out.println("值相等");
}關於自動拆箱的 NPE 風險,看這個例子:
Integer x = null;
int y = 100;
if (x == y) { // 運行時拋出NPE,因自動拆箱時調用x.intValue()
// ...
}這種錯誤在實際代碼中很容易發生,尤其是處理可能為 null 的 Integer 對象時。
總結
| 概念 | 描述 |
|---|---|
| Integer 緩存池 | JDK 內部維護的靜態緩存,存儲-128 到 127 範圍內的 Integer 對象 |
| 默認範圍 | 下限固定為-128,上限默認 127(可通過 JVM 參數調整上限) |
| 自動裝箱 | 編譯器自動將int轉為Integer,實際調用了valueOf()而觸發緩存機制 |
| new Integer() | 每次都創建新對象,不使用緩存池,即使值在緩存範圍內 |
| Integer.valueOf() | 優先從緩存池獲取對象,緩存範圍外才創建新對象 |
| 比較方式 | ==比較引用地址,equals()比較值;應始終使用equals()比較值 |
| 性能影響 | 使用緩存可以減少對象創建,提高性能和內存利用率 |
| 初始化時機 | 類加載時初始化(靜態代碼塊) |
| 設計模式 | 享元模式的典型應用,通過共享對象減少內存佔用 |





