

1. 引言:數據庫的“至暗時刻”
在互聯網高併發場景下,經常會出現流量突發的狀況。例如短視頻 App 遭遇熱點事件,幾百萬用户瞬間涌入,產生海量的點贊與評論互動。
此時,後端監控系統往往會發出警報:
- 數據庫 CPU 飆升至 100%。
- 磁盤 I/O 被打滿,寫入延遲從幾毫秒惡化至數秒。
- 連接池耗盡,新的請求因無法獲取連接而報錯。
這種現象的根本原因在於:在傳統架構中,每一次前端的“點贊”操作,都直接對應數據庫中的一次 UPDATE 操作。在高併發下,成千上萬個線程爭搶數據庫的行鎖(Row Lock),導致數據庫瞬間成為整個系統的瓶頸。
面對這種洪峯流量,直接由數據庫承擔所有寫入壓力並不現實。此時,需要在應用層與數據庫層之間增加一層“緩衝保護”,即 Redis Write-Behind(異步回寫)模式。
2. 什麼是 Write-Behind 模式?
在緩存設計模式中,業界常見的有 Cache-Aside(旁路緩存)或 Write-Through(直寫),這些模式通常要求數據在寫入時必須同步落庫,以保證數據的強一致性。
而 Write-Behind(回寫),也稱為 Write-Back,其核心思想是:“先內存,後持久化”。
在這種模式下,Redis 不僅僅充當緩存的角色,更是一個“擋板”或“緩衝區”。
- 寫請求:應用層只將數據更新到 Redis,並立即返回“成功”響應。
- 同步:由獨立的後台異步線程(或定時任務),負責週期性地將 Redis 中的數據批量寫入數據庫。
核心機制圖解:
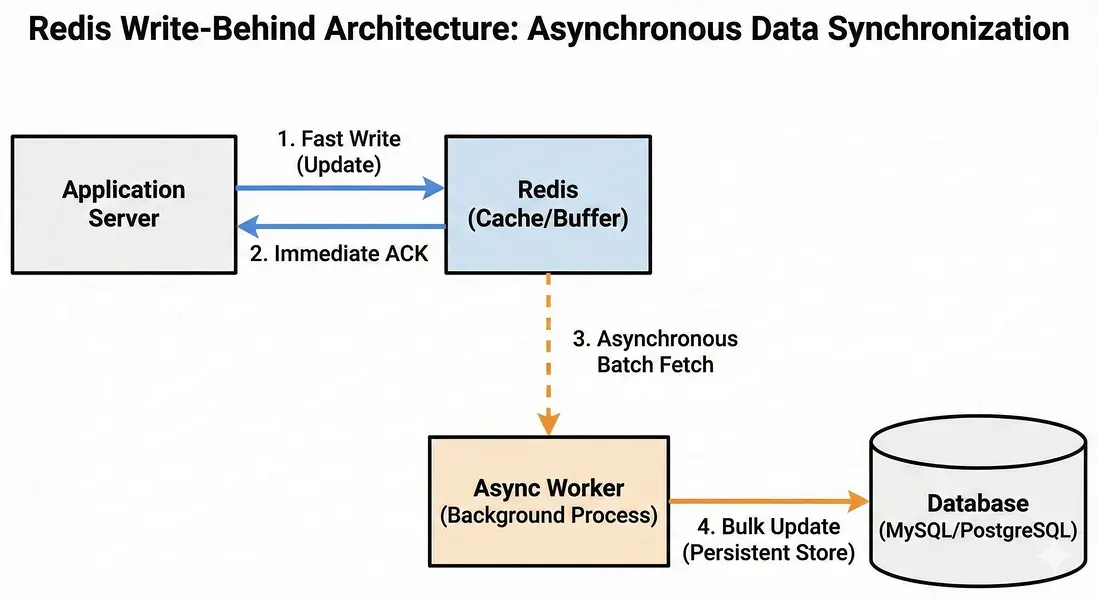
圖注:Write-Behind 模式核心流程:用户請求在 Redis 層快速完成,後台通過異步 Worker 進行批量落庫。
3. 為什麼它是“性能救星”?
Write-Behind 模式的本質,是利用“數據的即時一致性”來換取“極致的寫入性能”。
3.1 極高的寫入吞吐量
在 Write-Behind 模式下,客户端的等待時間僅包含 Redis 的網絡耗時與內存操作耗時,通常在毫秒級。這使得前端用户體驗極其流暢,感知不到數據庫的壓力。
3.2 削峯填谷(Load Leveling)
這是該模式最顯著的收益。
- 合併寫請求:假設 1 秒內產生了 10,000 次點贊請求。
- 傳統模式:數據庫需執行 10,000 次
UPDATE。 - Write-Behind:Redis 中的計數器累加 10,000 次,後台線程只需向數據庫執行 1 次
UPDATE count = count + 10000。 - 效果:數據庫的寫壓力可降低數個數量級。
3.3 系統的彈性
即使數據庫因意外短暫宕機(如重啓、網絡抖動),只要 Redis 保持運行,前端業務的寫操作仍可正常進行。該模式為系統提供了一個寶貴的“緩衝窗口”,為數據庫恢復爭取了時間。
4. 黃金應用場景
並非所有業務都適合該模式,以下是 Write-Behind 模式最適用的場景:
場景一:高頻計數器(Counter)
典型案例:視頻播放量、文章點贊數、直播間熱度。
此類數據的特點是高頻且非核心敏感。對於業務而言,實時數據是 10,005 還是 10,100 並不影響核心流程,只要最終數量一致即可。
- 實現策略:使用 Redis 的
INCR原子操作,每隔 N 秒將增量同步回 DB。
場景二:高頻軌跡/位置上報
典型案例:外賣騎手位置更新、車輛 GPS 軌跡。
若騎手每秒上報一次座標,直接寫庫會產生海量數據且造成巨大的 I/O 壓力。
- 實現策略:將座標推入 Redis List,積累一定數量(如 50 個點)或一定時間(如 1 分鐘)後,批量打包
INSERT到數據庫。
場景三:狀態防抖(Debounce)
典型案例:在線文檔的“自動保存”、用户的“正在輸入”狀態、最後在線時間。
用户在編輯文檔時,短時間內可能產生多次輸入。系統無需保存每一次中間狀態,只需保存最後停頓時的狀態。
- 實現策略:Redis 中只存最新狀態(Last Value),延遲 N 秒後落地,丟棄中間過程數據。
5. 硬幣的另一面:風險與代價
在引入 Write-Behind 提升性能的同時,必須關注其帶來的風險。
5.1 數據丟失風險(關鍵風險)
問題:由於數據是異步落庫的,如果在數據同步到數據庫之前 Redis 發生宕機,且 Redis 的持久化(RDB/AOF)未及時跟上,則內存中的這部分數據將徹底丟失。
對策:
- 嚴禁將此模式用於金融交易、訂單支付狀態等核心鏈路。
- 配置合理的 Redis AOF 策略(如
appendfsync everysec)以降低丟失概率。
5.2 數據一致性延遲
問題:數據庫中的數據存在滯後性。如果後台管理系統直接查詢數據庫導出報表,所見數據可能少於前端展示的數據。
對策:
- 業務層需接受“最終一致性”。
- 或者強制所有的讀取操作優先查詢 Redis。
6. Java (Spring Boot) 實現思路簡述
以下是一個基於 Spring Scheduled 的實現偽代碼示例,用於演示“點贊異步回寫”的邏輯:
@Service
public class LikeService {
@Autowired
private StringRedisTemplate redisTemplate;
// 1. 業務請求:極速響應,僅操作 Redis
public void likePost(Long postId) {
String key = "post:likes:" + postId;
// Redis 原子增,內存操作,無需等待 DB
redisTemplate.opsForValue().increment(key);
}
// 2. 異步回寫:定時任務 (例如每5秒執行一次)
@Scheduled(fixedRate = 5000)
public void syncToDatabase() {
// 掃描相關的 key (生產環境建議使用 Scan 命令或維護一個髒數據 Set)
Set<String> keys = redisTemplate.keys("post:likes:*");
if (keys == null || keys.isEmpty()) return;
for (String key : keys) {
String countStr = redisTemplate.opsForValue().get(key);
if (countStr != null) {
Long count = Long.parseLong(countStr);
Long postId = parseIdFromKey(key);
// 3. 批量更新數據庫
// SQL: UPDATE posts SET like_count = like_count + :count WHERE id = :postId
dbRepository.incrementLikes(postId, count);
// 4. 更新後處理 Redis 中的數據
// 簡單處理可直接刪除 Key,更嚴謹的做法是扣減已同步的數值 (DECR)
redisTemplate.delete(key);
}
}
}
}
7. 總結
Redis Write-Behind 模式是處理高併發寫場景的有效手段。它通過引入異步邊界,將數據庫從繁重的隨機寫操作中解放出來,轉而處理其更擅長的批量順序寫。
結論:
Write-Behind 模式是一種架構上的權衡,即用“即時一致性”和“少量數據丟失的風險”,換取“極致的寫入性能”。
在進行系統設計時,決策的關鍵在於:業務是否允許少量數據的丟失以換取高性能? 如果是點贊數等非敏感數據,該模式是絕佳選擇;如果是資金交易等核心數據,則應堅持使用強一致性的傳統寫庫模式。
本文由mdnice多平台發佈