

在 Rust 後端開發領域,Workspace Modular Monolith(基於工作空間的模塊化單體) 架構正日益流行。這種架構模式巧妙地平衡了開發效率與部署成本:在開發階段,它提供了類似微服務的物理隔離(crates 分離);而在部署階段,它保留了單體應用的簡單性(單一二進制文件)。
然而,在模塊化的高牆之下,往往隱藏着一個難以忽視的架構短板——數據庫遷移(Database Migrations)。
第一部分:背景與痛點 —— 代碼模塊化,數據耦合化的偽裝
在一個標準的 Rust Workspace 中,項目通常包含 user、order、payment 等多個獨立的 crates。從 Rust 代碼的層面看,它們是解耦的;但在數據庫層面,傳統的實踐往往依然維持着“中央集權”的模式。
1.1 “物理代碼分離,邏輯數據耦合”的現狀
在大多數項目中,無論開發者正在構建哪個業務模塊,所有的 SQL 遷移文件都被迫擠在項目根目錄的 migrations/ 文件夾下。更糟糕的是,它們共享着同一張 seaql_migrations 表來記錄版本歷史。這種物理上的混雜,直接導致了邏輯上的強耦合。

(User Access (ua) 和 Core Callback (cc) 的遷移記錄混雜在同一張全局表中,難以區分邊界)
1.2 這種架構帶來的五大弊端
雖然代碼解耦了,但這種“單體”的數據庫遷移策略導致了顯著的架構壞味道:
- 破壞封裝性 (Broken Encapsulation)
業務代碼位於crates/user,但創建表的 SQL 卻位於根目錄。當需要刪除或重構一個模塊時,開發者不僅要處理代碼,還必須在根目錄的數百個 migration 文件中進行“考古”,極易導致垃圾 Schema 殘留。 - 模塊複用性差 (Poor Reusability)
若想將現有的auth模塊複用到另一個 Rust 項目中,無法直接通過複製crates/auth文件夾實現,因為其數據庫定義遺留在老項目的根目錄下。這直接違背了模塊化“即插即用”的設計初衷。 - 協作衝突 (Merge Conflicts)
當團隊成員 A 開發訂單模塊,成員 B 開發用户模塊時,他們不得不在同一個migrations目錄下競爭文件命名。在代碼合併時,經常出現時間戳衝突或依賴順序混亂的問題。 - 測試隔離困難 (Hard to Isolate Tests)
進行單元測試時(例如僅測試user模塊),測試腳本往往被迫運行所有的 Migrations,包括不相關的支付表、日誌表等。這導致測試速度變慢,且增加了測試環境的脆弱性。 - 認知負擔 (Cognitive Load)
開發過程中,思維需要在“業務邏輯”(子模塊目錄)和“數據結構”(根目錄)之間頻繁切換,打破了上下文的連貫性。
1.3 破局思路:去中心化
面對上述問題,一個行之有效的解法是將數據庫變更權真正下沉到各個業務模塊中。本文將介紹如何利用 SeaORM 結合 inventory 庫,設計一套“去中心化”的遷移系統,實現從“中央集權”到“聯邦自治”的轉變。
第二部分:設計思路 —— 從集權到聯邦
要實現真正的模塊自治,需要在架構設計上進行根本性的調整。這不僅僅是移動文件位置,更是對數據管理權限的重新分配。
2.1 核心原則:模塊自治
理想的 Modular Monolith 應該遵循 “聯邦制(Federation)” 原則。每個模塊(Crate)應當被視為一個獨立的“邦國”,擁有自己的法律(代碼)和領土(數據庫表結構)。主程序(App Server)僅僅是一個“聯邦政府”,負責在啓動時協調各邦國的運作,而不干涉其內部事務。
2.2 策略對比
通過下表可以清晰地看到新舊架構的區別:
| 特性 | 傳統單體模式 (Centralized) | 模塊化自治模式 (Decentralized) |
|---|---|---|
| 文件位置 | 根目錄 migrations/ |
各模塊內 crates/xxx/migrations/ |
| 歷史記錄表 | 全局唯一 seaql_migrations |
模塊獨立 seaql_migrations_{module} |
| 版本控制 | 全局時間戳,需嚴格排序 | 模塊內時間戳,模塊間無干擾 |
| 啓動邏輯 | 硬編碼加載全局遷移 | 動態發現,自動註冊 |
| 刪除模塊影響 | 高風險 (需手動清理 SQL) | 零風險 (刪除文件夾即可,自動隔離) |
2.3 關鍵實施路徑
為了落地這一設計,需要解決兩個關鍵技術問題:
- 物理隔離:不再使用一張大表記錄所有變更。User 模塊的變更記錄在
seaql_migrations_ua,Callback 模塊的變更記錄在seaql_migrations_cc。這確保了模塊 A 的回滾或重置絕不會影響到模塊 B。 - 服務發現:由於模塊是解耦的,主程序不應該硬編碼引用各個模塊的 Migrator。我們需要一種機制,讓各個模塊在編譯或鏈接階段,能夠自動將自己的 Migrator “註冊”到全局列表中。
第三部分:核心實現 —— Inventory + Macro
基於上述設計思路,技術落地將依賴 SeaORM 作為 ORM 框架,並配合 inventory crate 實現分佈式註冊。
3.1 核心機制:Inventory (點名 vs 舉手)
inventory 庫通過 Rust 的編譯期魔法,在鏈接階段將散落在各 crate 中的註冊項收集到一個全局“登記表”。可以做一個形象的類比:
- 傳統方式 (點名):主程序必須明確知道每個人的名字(
use user::Migrator; use order::Migrator;),並手動調用它們。耦合度極高。 - Inventory 方式 (舉手):各模塊在自己內部“舉手報到”,主程序只需在啓動時問一句:“有哪些人到了?”(
inventory::iter())。
這種方式不僅避免了主程序與各模塊的硬編碼依賴,實現了真正的“即插即用”,且由於收集動作發生在鏈接階段,運行時開銷為零。
3.2 定義標準:ModuleMigration
首先,定義一個標準的結構體用於模塊上報信息,並聲明 inventory 收集該類型:
use sea_orm_migration::sea_orm::DatabaseConnection;
use sea_orm_migration::DbErr;
// 1. 模塊遷移執行器 trait,抹平不同 Migrator 的類型差異
#[async_trait::async_trait]
pub trait MigrationExecutor: Send + Sync {
async fn execute_up(&self, db: &DatabaseConnection, steps: Option<u32>) -> Result<(), DbErr>;
async fn execute_down(&self, db: &DatabaseConnection, steps: Option<u32>) -> Result<(), DbErr>;
}
// 2. 模塊註冊項結構體
pub struct ModuleMigration {
pub module_name: &'static str,
pub get_migration_table_name: fn() -> String, // 關鍵:獲取該模塊獨立的表名
pub executor: &'static dyn MigrationExecutor,
}
// 3. 告訴 inventory 開始收集這種對象
inventory::collect!(ModuleMigration);3.3 魔法膠水:module_migrator! 宏
這是整個方案的樞紐。通過定義一個過程宏,自動完成“生成樣板代碼”和“註冊”兩項繁瑣工作,對開發者屏蔽底層複雜度。
宏的核心實現如下:
#[macro_export]
macro_rules! module_migrator {
// 接收模塊名和一系列 migration 模塊標識符
($module_name:expr, $($migration:ident),+ $(,)?) => {
use $crate::*;
// 1. 自動生成所有遷移模塊的 pub mod 聲明
$(
pub mod $migration;
)+
/// 模塊的獨立 Migrator
#[derive(Clone, Debug, Default)]
pub struct ModuleMigrator;
#[async_trait::async_trait]
impl MigratorTrait for ModuleMigrator {
/// 2. 關鍵:重寫遷移表名,使用模塊特定的遷移歷史表
/// 例如:seaql_migrations_ua
fn migration_table_name() -> DynIden {
SeaRc::new(Alias::new(concat!("seaql_migrations_", $module_name)))
}
/// 3. 返回該模塊的所有遷移文件
fn migrations() -> Vec<Box<dyn MigrationTrait>> {
sort_migrations(vec![
$(
Box::new($migration::Migration),
)+
])
}
}
// 4. 最後,利用 inventory 自動註冊該模塊
$crate::register_migrator!($module_name, ModuleMigrator);
};
}3.4 總指揮:MultiModuleMigrator
最後,系統需要一個全局的 Migrator 來調度執行。
⚠️ 關鍵設計細節:MultiModuleMigrator的migrations()方法故意返回空列表。因為它不直接管理遷移文件,而是通過重寫up()和down()方法,充當“調度者”的角色,動態遍歷 inventory 註冊表來調用各模塊的 executor。
pub struct MultiModuleMigrator;
#[async_trait::async_trait]
impl MigratorTrait for MultiModuleMigrator {
// 關鍵:這裏返回空,因為具體的 migration 文件歸各模塊管理
fn migrations() -> Vec<Box<dyn MigrationTrait>> {
Vec::new()
}
// 重寫 up 方法,接管遷移流程
async fn up<'c, C>(db: C, steps: Option<u32>) -> Result<(), DbErr>
where C: IntoSchemaManagerConnection<'c> {
// 1. 收集所有註冊模塊
let modules: Vec<_> = inventory::iter::<ModuleMigration>().collect();
// 2. 依次觸發每個模塊的 executor
for module in modules {
tracing::info!("執行模塊遷移: {}", module.module_name);
match &db_conn {
SchemaManagerConnection::Connection(conn) => {
// 每個模塊維護自己的 version history
module.executor.execute_up(conn, steps).await?;
}
_ => panic!("不支持事務嵌套")
}
}
Ok(())
}
}3.5 當前限制與注意事項
在實施此方案時,需注意以下幾點:
- 事務限制:由於 SeaORM 遷移內部可能包含事務操作,
MultiModuleMigrator暫不支持在外部事務上下文中執行(如代碼所示,遇到 Transaction 會報錯)。所有遷移將在數據庫連接上直接執行。 - 執行順序:模塊間的遷移順序默認由
inventory的收集順序決定(通常依賴於鏈接順序)。如果存在模塊間的嚴格依賴(如外鍵),建議通過 Cargo 的依賴關係控制,或在代碼層面增加優先級排序邏輯。 - Fail-fast 策略:遷移執行是同步順序的,若某個模塊遷移失敗,後續模塊將不會執行,確保數據庫狀態不會進一步惡化。
第四部分:開發體驗與成果
經過底層的改造,頂層的開發體驗得到了質的飛躍,代碼變得極致簡潔且具備高度的內聚性。
4.1 聲明式的模塊定義與命名規範
現在,在各個模塊內部,開發者只需編寫幾行聲明式代碼即可完成遷移配置。
命名規範建議:
- 模塊前綴:與 crate 名稱或業務縮寫對應(如
user_access-\>ua,core_callback-\>cc)。- 表名格式:自動生成為
seaql_migrations_{prefix}。- 文件命名:建議遷移文件包含前綴,避免混淆(如
m20250903_000001_ua_user.rs)。
下面是兩個不同模塊的配置示例:
User Access (ua) 模塊
// crates/user_access/src/migrations/mod.rs
core_common::core_migration::module_migrator!(
"ua", // 生成表名 seaql_migrations_ua
m20250903_000001_ua_user,
m20250903_000003_ua_oauth_user,
m20250909_000001_ua_oauth2_sessions,
m20250910_000001_ua_saas,
// ... 更多文件
);Core Callback (cc) 模塊
// crates/core_callback/src/migrations/mod.rs
core_common::core_migration::module_migrator!(
"cc", // 生成表名 seaql_migrations_cc
m20250918_000001_cc_callback,
m20250923_000001_cc_id_alloc,
);4.2 最終效果:物理隔離
運行遷移後,數據庫中呈現出清晰的隔離視圖。每個模塊擁有獨立的遷移歷史表,互不干擾。
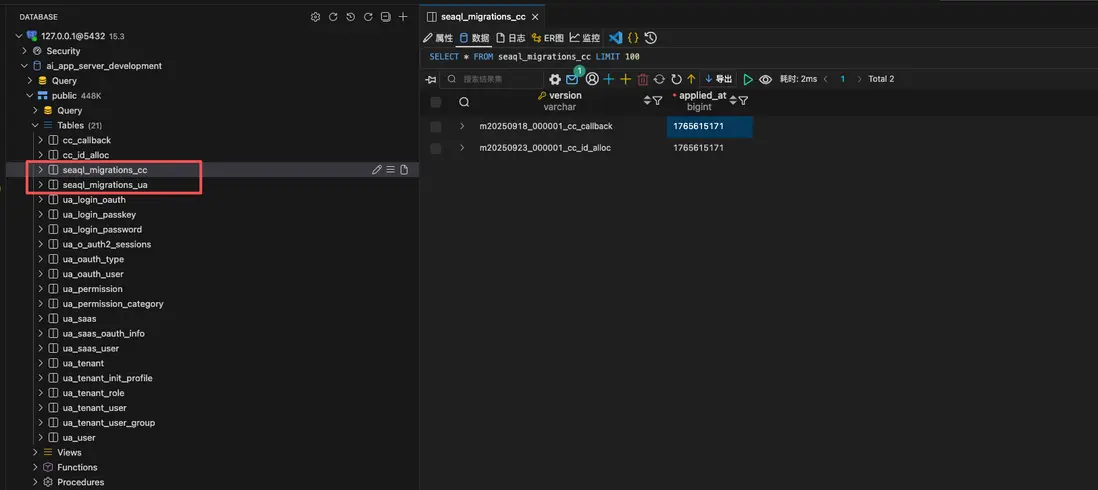
(改革後。User Access 和 Core Callback 擁有了各自獨立的 seaql_migrations_xx 表)
4.3 收益總結
通過實施這套方案,項目成功實現了:
- 真正的物理隔離:若需刪除
ua模塊,只需刪除crates/user_access文件夾。相關的 Migration 代碼和定義將隨之消失,乾淨利落。 - 獨立的歷史記錄:如上圖所示,
cc模塊只記錄了兩條變更,而ua模塊記錄了幾十條。它們的時間戳無需全局協調,徹底消除了版本衝突。
4.4 主程序集成
最後,在應用入口(App Server)集成這套系統非常簡單,實現了真正的“零配置啓動”。只需聲明使用 MultiModuleMigrator 作為全局遷移器:
// src/app.rs - 主程序中的類型聲明
use core_common::core_migration::MultiModuleMigrator;
// 將 MultiModuleMigrator 泛型注入到 App 配置中
pub type App = BaseApp<AiAppServerConfig, MultiModuleMigrator>;當框架啓動時,會自動調用 MultiModuleMigrator::up()。此時,inventory 機制已在後台靜默地完成了所有模塊的收集工作,整個過程無需任何手動註冊代碼。
第五部分:總結
通過引入 SeaORM 的靈活性與 inventory 的分佈式註冊能力,成功填補了 Modular Monolith 架構中關於數據治理的最後一塊拼圖。
這套去中心化的遷移機制,不僅解決了代碼管理上的物理耦合,更在邏輯層面賦予了每個模塊完整的生命週期自主權。現在,開發團隊可以自信地添加、移除或重構業務模塊,而無需擔心觸碰那張曾經令人頭疼的全局遷移網。這正是 Rust 項目從“能跑”邁向“好維護”的關鍵一步。
本文由mdnice多平台發佈