

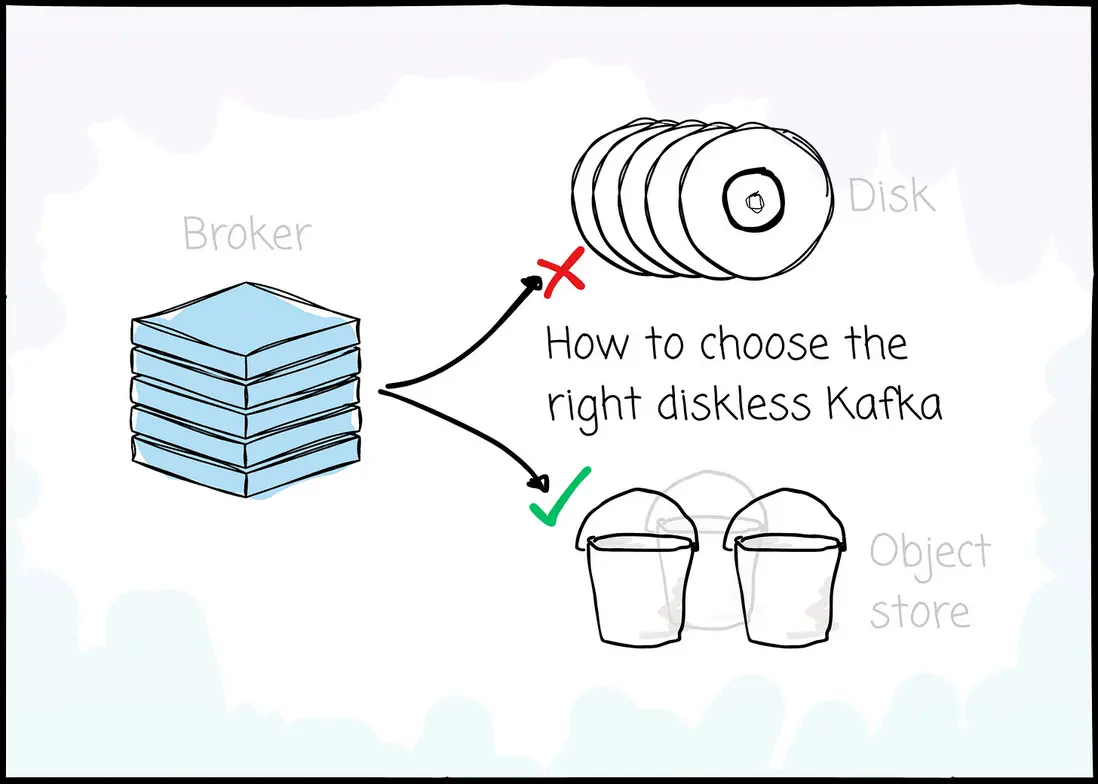
文章導讀
隨着越來越多企業將 Kafka 遷移至雲原生架構,AutoMQ 正逐漸成為 Kafka 用户的雲端優選。作為兼容 Apache Kafka 協議、專為雲設計的新一代發行版,AutoMQ 憑藉高性能、彈性擴展和極致成本等優勢,在全球範圍內的熱度持續攀升,GitHub Star 數也順勢突破 8k 大關。在海外社區涌現的眾多討論與推文中,我們發現了這樣一篇來自開發者的深度好文,將其內容翻譯並呈現給大家,概述如下。
Apache Kafka 雖已成為流數據領域的事實標準,但其誕生於 IDC 時代的“存算一體”架構在雲原生環境下正顯露疲態:高昂的跨可用區(Cross-AZ)流量成本與難以解耦的存算資源,成為企業數字化基礎設施中不可忽視的隱形債務。伴隨着雲存儲技術的成熟,Diskless Kafka 逐漸成為下一代消息中間件演進的必然趨勢。
在這場架構變革中,我們不僅將深入剖析Diskless Kafka興起的根本原因,更將目光投向目前唯一的開源、成熟的Diskless Kafka方案——AutoMQ。以此為切入點,重點探討 Kafka 向基於共享存儲架構演進的技術路徑,並將從各個維度深度剖析 Diskless Kafka 設計背後的核心權衡,助您充分理解不同架構的優劣,從而選擇出真正適合自己的 Kafka 方案。
引言
自問世以來,Apache Kafka 已確立了其作為分佈式消息領域“事實標準”的地位,支撐着全球無數企業的關鍵業務——從微服務通信到實時分析,應用場景無處不在。
然而,它的架構誕生於本地數據中心(On-Premise)主導的時代。在那時,服務器硬件通常需要預先採購,且網絡帶寬遠不及今日。當這種設計理念被移植到現代雲環境時,弊端便顯露無疑:跨可用區(Cross-AZ)的網絡流量成本飆升,且難以實現計算與存儲的獨立擴展。
這一現狀正推動着整個行業向一種全新的範式演進:Diskless Kafka。在本文中,我們將首先Diskless Kafka趨勢,並盤點市場上現有的解決方案。隨後,我們將重點剖析 AutoMQ——作為業內最早嘗試實現 Diskless Kafka 的先行者之一。
Diskless Kafka vs Apache Kafka
Kafka 誕生於十多年前的 LinkedIn,旨在為生產者(Producer)與消費者(Consumer)提供一種高效的解耦手段;雙方均通過 Broker 進行交互以傳遞消息。正如前文所述,Kafka 誕生的時代背景具有以下特徵:
- 主要依賴本地數據中心(IDC),而非雲服務。

- 那時的網絡帶寬相當有限;因此,構建系統的標準做法是將計算與存儲緊密綁定在一起(即存算一體)。
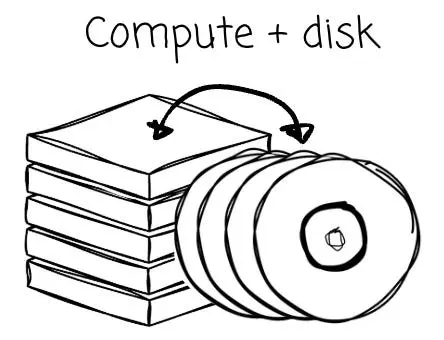
基於上述背景,Kafka 的 Broker 被設計為將消息直接持久化存儲在本地磁盤上,並通過 Broker 間的消息複製機制來實現數據冗餘與高可用性。
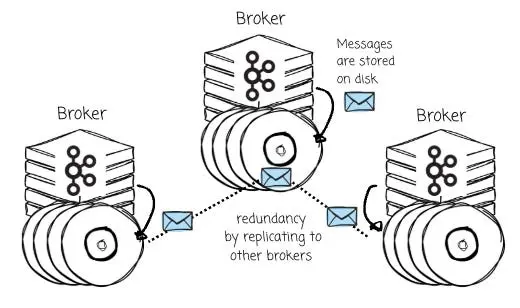
這意味着,擴容存儲就必須增加機器節點。這種機制迫使用户即便在現有計算資源利用率並不高的情況下,也不得不配置額外的 CPU 和內存。
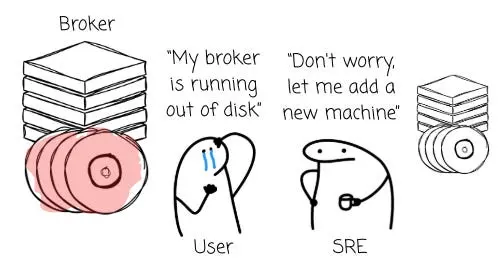
除了資源效率低下的問題,Broker 級別的數據複製在雲端多可用區(AZ)部署中還會帶來巨大的、往往被忽視的財務黑洞。這種成本主要體現在以下兩個方面:
- 生產者流量成本:在一個典型的跨三個可用區部署的高可用架構中,生產者必須將消息發送給指定分區的 Leader Broker。如果 Kafka 集羣將 Leader 分區均勻分佈在三個可用區,那麼大約有三分之二的情況下,生產者會將消息發送到位於不同可用區的 Broker 上(從而產生跨區流量費用)。
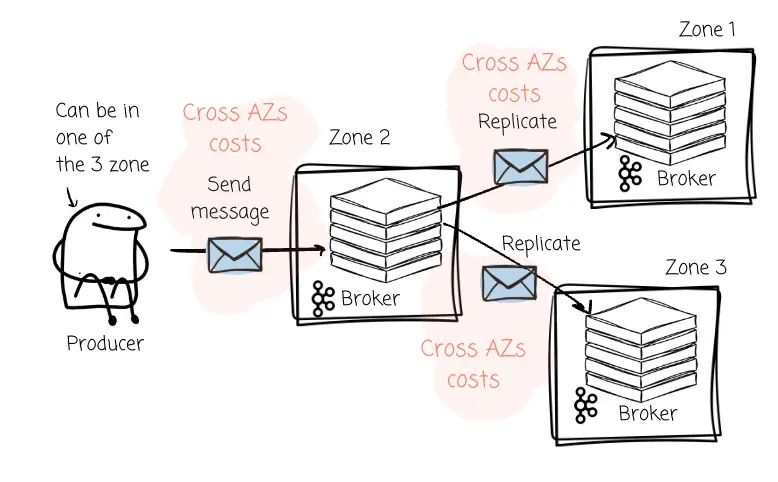
- 複製流量成本:當 Leader 節點接收到數據後,為了保證數據的持久性,必須將其複製到位於另外兩個可用區的 Follower 節點。這一過程會引發規模更為龐大的跨可用區數據傳輸,導致同一份消息數據產生“二次”網絡費用。
鑑於上述痛點,各類採用全新架構設計的系統正應運而生。
Diskless Kafka
儘管 Kafka 存在上述不足,但其 API 無疑已大獲全勝。它不僅是數據流領域的行業標準,更衍生出了一個極為龐大且成熟的生態系統。
因此,任何廠商若想提供更優的替代方案,其首要前提必須是兼容 Kafka。推倒重來去構建一套全新的系統並非良策,重構 Kafka 的存儲層才是更為高效的路徑。

所謂Diskless Kafka架構(Diskless Architecture),指的是一種將所有消息徹底從 Broker 中剝離,並轉而全量存儲於對象存儲(Object Storage)的架構模式。
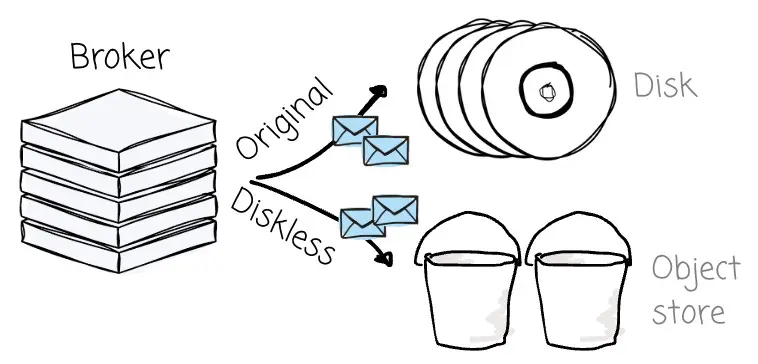
這種新模式徹底重塑了 Kafka 兼容系統在雲端的運作機制,其帶來的收益不僅立竿見影,更具顛覆性:
- 成本優勢:相比傳統 Kafka Broker 所必需的高性能塊存儲,對象存儲的單位容量(Per GB)成本要低整整一個數量級。

- 彈性伸縮:Broker 節點轉變為無狀態的計算單元,可根據處理需求靈活進行擴縮容;與此同時,存儲容量則完全依託於對象存儲,能夠獨立、自動地進行擴展。
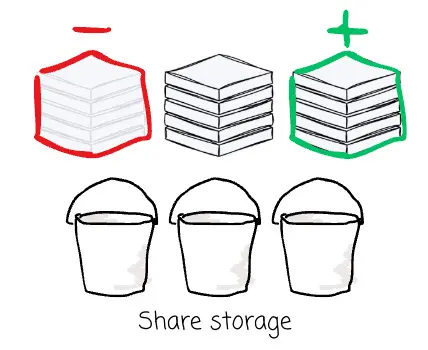
- 持久性與可用性:雲對象存儲服務天生具備極高的持久性,並能自動在多個可用區之間複製數據。這種高可靠性主要得益於糾刪碼(EC)技術與自動數據複製機制的結合,且這些機制通常天然具備跨多可用區的能力。由於數據保護的重任已完全下沉由存儲層接管,系統不再需要維護昂貴且複雜的 Broker 級數據複製,從而徹底根除了與之伴生的跨可用區流量難題。

值得特別指出的是,Diskless Kafka架構與 Kafka 分層存儲(KIP-405)所提出的分層架構有着本質區別。KIP-405 引入的是一套雙層存儲體系:
- 本地存儲(Broker 本地磁盤):用於存儲最新的數據。
- 遠程存儲(S3/GCS/HDFS):用於存儲歷史數據。
然而,在這種架構下,Broker 無法實現徹底的無狀態化,我們前文討論過的種種痛點依然存在。
從 WarpStream、BufStream 到 Aiven,各路廠商紛紛基於這一理念推出了 Kafka 的替代方案。這類平台的集中爆發,恰恰印證了其所解決的痛點是何等關鍵。雖然它們殊途同歸,都致力於通過對象存儲來實現降本與彈性增強,但各家的技術成色與實現路徑卻不盡相同。
在本文中,我將重點剖析 AutoMQ——相較於其他競品,它提供了一種獨樹一幟的 Diskless Kafka 解法。
AutoMQ
100% Kafka 兼容與開放性
正如我們之前所探討的,新一代系統必須嚴格遵循 Kafka 協議。
Kafka 協議是圍繞本地磁盤構建的。從向物理日誌追加消息,到通過定位分段文件(Segment Files)中的偏移量(Offset)來服務消費者,所有的操作邏輯都緊緊圍繞着這一設計核心。
即便如此,基於對象存儲構建 Kafka 兼容方案仍面臨巨大挑戰。暫且不論性能,對象存儲的寫入機制與磁盤迥異。我們無法像操作文件系統那樣,打開一個不可變對象並直接在末尾追加數據。
對此,部分廠商(如 WarpStream、Bufstream)選擇另起爐灶,開發一套新協議來兼顧:
- 適配對象存儲
- 提供 Kafka 兼容性
他們認為,相較於基於開源 Kafka 協議進行改造,這種方式更為直接。然而,此舉也帶來了嚴峻挑戰:難以緊跟社區演進的步伐,往往導致某些 Kafka API 特性的支持滯後甚至缺失。例如,WarpStream 就耗費了相當時日才補齊了對事務(Transactions)的支持。
AutoMQ 並不認可這種路徑。

AutoMQ 選擇了一條不同的路:完整複用了除存儲層以外的所有 Kafka 上層邏輯。團隊投入了大量精力,為 Kafka 量身打造了一款全新的存儲引擎,它既能與對象存儲無縫對接,又能向上提供 Kafka 協議運行所必需的底層抽象。
得益於此,AutoMQ 有底氣為其Diskless Kafka方案承諾 100% 的 Kafka 兼容性;即便 Kafka 社區後續推出了諸如隊列(queues)等前沿新特性,AutoMQ 也能通過合併上游代碼,實現無縫集成與同步支持。
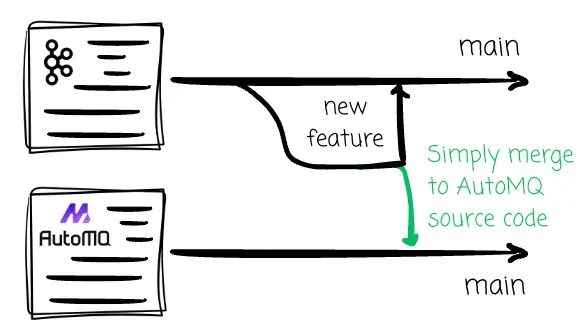
AutoMQ 的另一大亮點在於其開源屬性。這賦予了用户極大的自由度——既可以嚐鮮試用,也能在自家環境中獨立部署。
放眼當下的市場,它是唯一一款兼具開源與生產級可用性的 Diskless Kafka 解決方案。反觀其他開箱即用的競品,無一例外均採用了閉源策略,而 Kafka 社區官方關於Diskless Kafka Topic 的提案(KIP: Diskless Topic)尚處於討論之中,遠未落地。
絕不以犧牲低延遲為代價
向對象存儲寫入數據的速度,無疑要慢於本地磁盤。一些 Diskless Kafka 方案選擇了犧牲低延遲性能:它們必須等到消息在對象存儲中完成持久化後,才會向生產者返回確認(ACK)。
然而,這種方案伴隨着嚴重的代價。當延遲出現數量級級別的惡化時,客户端往往需要投入額外的時間重新打磨配置,涵蓋從併發度到緩存大小的方方面面(關於緩存,後文會有更多討論)。在金融等對延遲極度敏感的關鍵業務場景中,這種程度的性能退化往往是不可接受的。
AutoMQ 拒絕這種妥協。
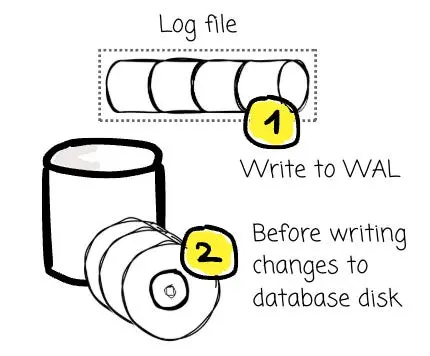
為此,他們借鑑了數據庫領域的一個經典理念:預寫日誌(Write Ahead Log, WAL)。這是一種專用於崩潰恢復與事務恢復的“僅追加”(Append-only)日誌結構。其原理十分簡單:所有的數據變更,必須先被完整記錄在日誌中,隨後才能被應用到數據庫的實際數據文件中。
遵循這一原則,即便系統在事務提交之後、變更尚未刷入數據文件之前發生崩潰,系統依然可以通過讀取 WAL 來重放(Replay)這些變更。這對於數據庫管理系統(DBMS)確保數據的持久性至關重要。
回到 AutoMQ 的架構設計上來,每個 Broker 都配備了一個 WAL,其底層依託於 AWS FSx 或其他雲廠商提供的同類高性能存儲服務。正是憑藉這些通常具備跨可用區複製能力的強健共享服務,AutoMQ 能夠確保從容應對可用區(AZ)級別的故障。
當 Broker 接收到消息時,會先將其寫入內存緩衝區,待數據成功持久化至 WAL 後,便立即向生產者返回確認響應(ACK)。通過這種機制,客户端無需等待消息寫入對象存儲(這一相對緩慢的過程),從而顯著降低了延遲。
隨後,這些消息會被打包,通過異步方式批量刷寫(Flush)至對象存儲中。
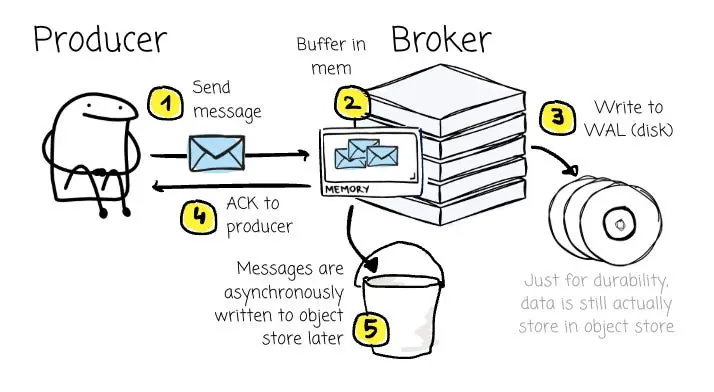
相較於等待一批消息被完整寫入對象存儲,在消息持久化至 WAL(磁盤)後立即發送 ACK 響應,無疑要快得多。
需要補充説明的一點是,由於磁盤設備主要承擔 WAL 的職能以確保消息的持久性,系統對磁盤空間的需求極小。AutoMQ 默認將 WAL 的大小設定為 10GB 即可滿足需求。
基於 Leader 與無 Leader 架構之爭
究其核心,Apache Kafka 是一個基於 Leader(Leader-Based)的系統。對於 Topic 的每一個分區,通常都配備了一個 Leader 以及零個或多個 Follower。所有的寫入操作都必須流向該分區的 Leader,而讀取請求則可以由 Leader 或該分區的 Follower 來承接。AutoMQ 依然沿用了這一架構路線。

在Diskless Kafka架構下,鑑於所有 Broker 均共享底層的對象存儲,Bufstream 和 WarpStream 等廠商認為,傳統的“基於 Leader(Leader-Based)”架構已非必需。
相反,他們將所有 Broker 視為一個同構的、無狀態的計算資源池;也就是説,任意 Broker 均可接收針對任意分區的寫入請求。業界通常將這種模式稱為“無 Leader(Leaderless)架構”。
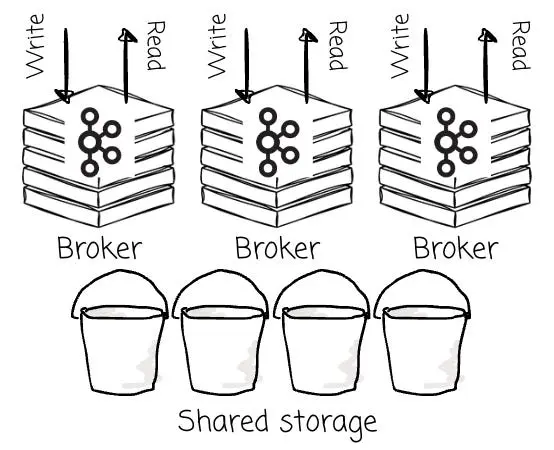
接下來,我們將從多個維度深入探討,為您剖析這兩種架構設計背後的權衡與取捨。
額外的組件
為了實現無 Leader 架構,相較於原生 Kafka 方案,系統在部署時必須引入一個額外的組件。由於每個 Broker 都能處理讀寫請求,因此必須依靠協調器(Coordinator)來為客户端指派具體的 Broker、管理元數據,並重新實現那些原本由分區 Leader 掌控的所有 Kafka 高級特性。
然而,這種對外部協調器的依賴也帶來了一些副作用。它引入了 Broker 自身之外的外部依賴,從而使數據寫入鏈路變得更加複雜。同時,這也推高了維護 Kafka API 兼容性的成本,因為諸如事務或冪等生產者等 Kafka 核心特性,都必須在協調器的深度參與下進行徹底的重新實現。
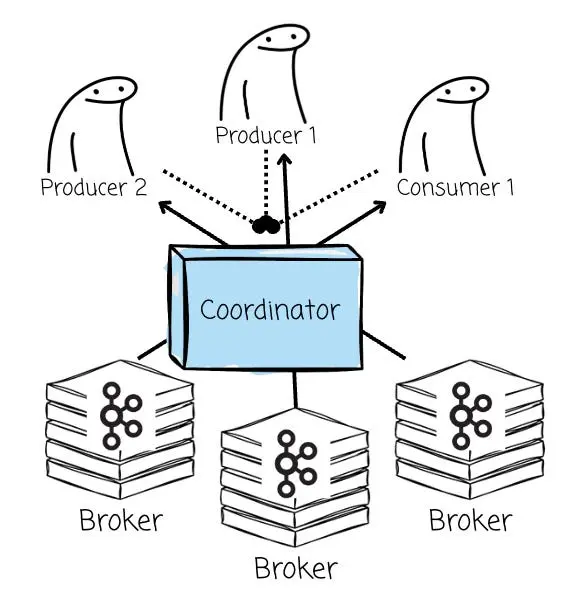
AutoMQ 堅持採用基於 Leader 的架構,因此無需引入額外的“協調器”組件,其消息生產與消費機制依然完美沿襲了 Kafka 的原生邏輯。客户端會向 Bootstrap Broker 發起元數據請求,以獲知 Broker 列表、所在的可用區(AZ)以及各 Topic 分區的 Leader 信息。在生產數據時,客户端會始終嘗試與指定 Topic 分區的 Leader 進行交互;而在消費端,客户端既可以連接 Leader,也可以連接任意副本節點。
由於 AutoMQ 完整保留了 Leader 這一核心概念,因此係統架構中無需任何額外的組件介入。
寫入靈活性
無 Leader 架構賦予了寫入端極大的靈活性。
其顯著優勢之一在於大幅削減了跨可用區(Cross-AZ)傳輸的成本。系統能夠無縫地將流量從生產者路由至與其位於同一可用區的 Broker,從而避免了跨區流量費用的產生。

AutoMQ 基於 Leader 的架構憑藉共享對象存儲的能力,同樣能夠輕鬆規避寫入側的跨可用區流量。這主要涵蓋兩種場景:
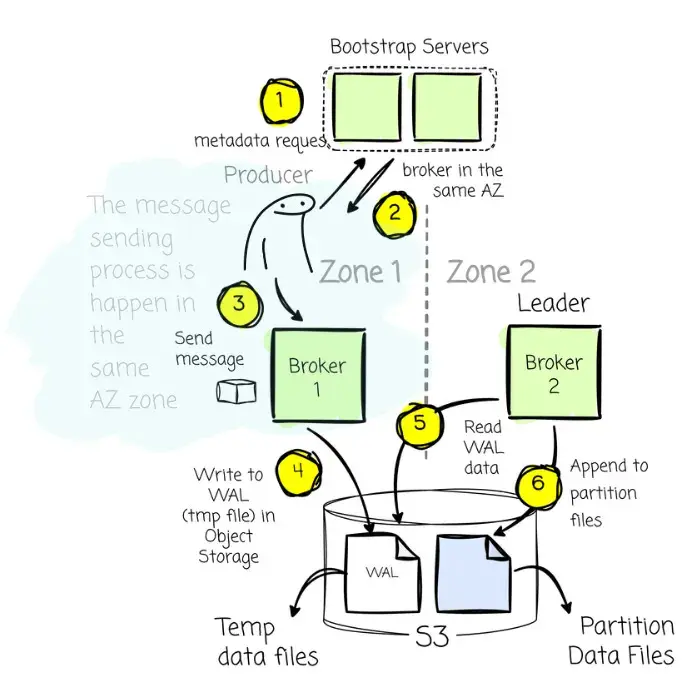
- 如果 Leader 與生產者處於同一可用區:太棒了,這是最理想的情況,生產者只需照常向該 Broker 發送消息即可。
- 如果 Leader 位於不同的可用區:當生產者請求目標 Broker 信息以發送消息時,服務發現機制不會返回位於異地的 Leader 地址,而是會返回一個與生產者處於同一可用區的 Broker 地址。
該同區 Broker 會先將接收到的消息寫入對象存儲的臨時文件中。隨後,Leader 會“認領”這些臨時文件,並將數據正式寫入實際的分區位置。之所以採取這種機制,是因為在基於 Leader 的架構中,所有針對分區的最終寫入操作,必須由 Leader 親自經手。
憑藉這一設計,AutoMQ 在徹底消除跨可用區流量費用的同時,並未犧牲 Kafka 的兼容性(因為 Leader 依然把控着分區數據的寫入權)。
讀取側的數據局部性
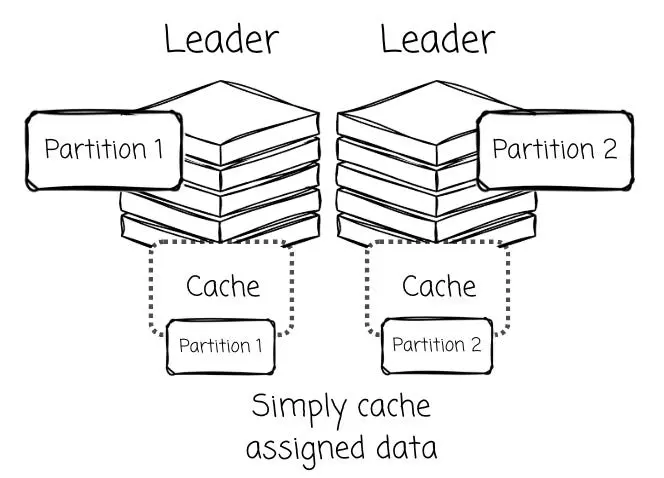
在 AutoMQ 這類基於 Leader 的系統中,分區 Leader 擁有得天獨厚的優勢:極高的數據局部性(Data Locality)。
由於 Leader 統管其名下分區的所有寫入操作,那些最新生成且被頻繁訪問的“熱數據(Hot Data)”可以被直接駐留在其本地內存緩存中。
談及緩存,它堪稱Diskless Kafka架構中的“生命線”。畢竟,直接從對象存儲讀取數據的性能表現,終究無法與本地磁盤相提並論。
除去性能層面的考量,過於頻繁的讀取請求還會導致成本激增,畢竟雲服務商通常是依據對象存儲的 GET 請求次數來進行計費的。而在這一語境下,緩存機制不僅是提升性能的關鍵,更是兼顧成本效益(降本增效)的利器。
這不僅有助於提升讀取性能,還能最大化數據在上傳至對象存儲前的批處理效率。
正是基於這一架構優勢,AutoMQ 順理成章地設計出了雙層緩存機制:利用專用的日誌緩存(Log Cache)來應對寫入與熱點讀取,同時配備塊緩存(Block Cache)來服務於歷史數據。
反之,無 Leader 架構則可能受制於數據局部性(Data Locality)較低的困境。
當任意 Broker 隨時都能向同一分區寫入數據時,該分區的數據就會被打散,以碎片化的形式分佈在 S3 的大量小對象中,而這些對象又是由不同的 Broker 各自生成的。
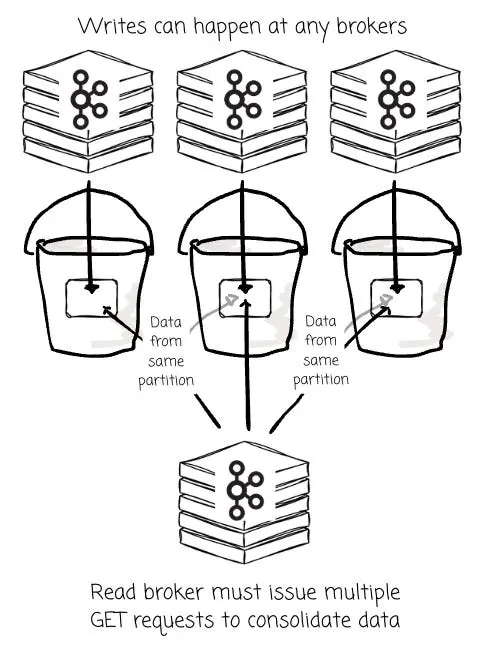
儘管這些對象最終會被合併,但在初始階段,Broker 仍不得不發起大量的 GET 請求,去拉取那些零散分佈的對象以響應消費者。
緩存固然能緩解這一壓力。但核心難題在於:在無 Leader 架構下,既然所有 Broker 都能承接讀取請求,該如何制定高效的數據緩存策略?
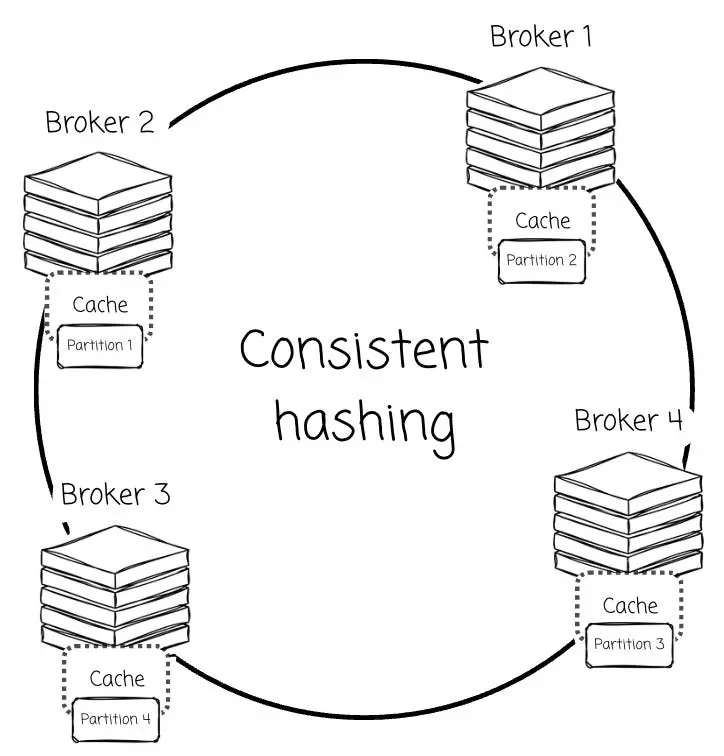
據我瞭解,為了解決這一問題,廠商們試圖將分區“綁定”給特定的 Broker。例如,WarpStream 利用一致性哈希算法將分區分配給特定的 Broker,由該節點全權負責指定分區的緩存與數據服務。
這種做法實際上是變相迴歸了“基於 Leader”的架構理念,但同時也為此引入了額外的複雜性。由於缺乏本地數據支持,為了填補由此產生的性能與成本缺口,工程團隊不得不設計各種變通方案,以規避對象存儲的高延遲與昂貴的 API 調用成本(如 S3 GET 請求)。
例如,WarpStream blog 中曾詳細闡述了他們如何利用 mmap 技術來最小化 S3 API 的開銷。而這,恰恰是為了緩解因無法實現真正的數據局部性而不得不付出的設計代價。
元數據管理
基於 Leader 與無 Leader 架構之間的分歧,不僅停留在表面,更深入到了元數據管理的底層邏輯。在 AutoMQ 的基於 Leader 模型中,元數據管理顯得大道至簡,因為它直接複用了 Kafka 成熟的分區邏輯。
當 AutoMQ 寫入數據時,它會像原生 Kafka 那樣,直接將數據寫入一個已經開啓的分區。這種設計使得元數據的存儲與組織變得異常直觀清晰。其元數據佔用的空間相對較小,主要僅需追蹤兩類信息:分區與 Leader Broker 的映射關係,以及數據對象在 S3 中的存儲位置。
這一元數據管理重任,由 Kafka 原生的 KRaft 協議高效承接,該協議已直接集成於 Broker 核心之中。元數據的體量與消息批次的數量並不掛鈎,從而有效杜絕了數據膨脹的風險。
反觀無 Leader 系統,則面臨着頗為棘手的挑戰。由於其在架構層面剝離了消息分區的概念,團隊不得不投入巨大的工程精力,編寫海量代碼,只為從零開始復刻 Kafka 的核心功能。
由於缺乏對分區日誌擁有絕對控制權的“單一權威節點”,它們被迫對每一批次(Batch)的消息都保存詳盡的元數據,包括其偏移量(Offset)、時間戳以及所包含的分區數量。
這種複雜性體現在兩個維度。
首先,海量的元數據通常需要引入一個獨立的事務型數據庫來進行管理。這不僅大幅增加了運維的負擔,還為系統埋下了另一個潛在的單點故障隱患。
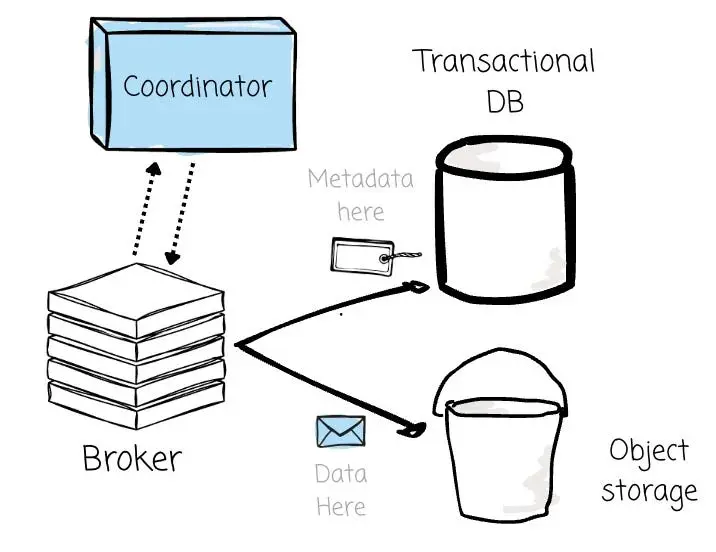
其次,它極大地複雜化了數據訪問鏈路。存儲在 S3 中的數據本身不再具備“自包含性”;消費者若要讀取數據,必須將對象存儲中的原始數據與數據庫中對應的元數據進行動態拼接。
相比 AutoMQ 或傳統 Kafka,這種合併過程要繁瑣得多。究其根本,這是因為無 Leader 架構拋棄了作為 Kafka 協議基石的那套簡單而高效的分區邏輯,從而不得不去承受的直接後果。
結語
在本文中,我們首先審視了雲原生時代 Kafka 所面臨的種種挑戰,剖析了Diskless Kafka架構興起的背後動因及其核心內涵。隨後,我們將目光投向了 AutoMQ 一一它是目前市場上唯一一款提供開源Diskless Kafka選項的解決方案。
最後,我們從額外組件需求、寫入靈活性、讀取側的數據局部性以及元數據管理這四個維度出發,深度對比了Diskless Kafka系統中的兩條主流技術路線:基於 Leader(Leader-based)與無 Leader(Leaderless)架構的異同。