

作者:曾慶國(悦達)
Prometheus 大家應該非常熟悉,正文開始前,讓我們一起來回顧開源 Prometheus 項目的發展史。Prometheus 最初由 SoundCloud 的工程師 Björn Rabehl 和 Julius Volz 於 2012 年開發。當時,SoundCloud 需要一個更高效、靈活的監控系統來替代傳統工具(如 Nagios 和 Graphite),以應對快速增長的分佈式系統複雜性。2015 年,Prometheus 在 GitHub 上開源,併發布 v0.1.0。緊接着 2016 年隨着雲原生時代的到來,繼 Kubernetes 之後,Prometheus 成為 CNCF 的第二個正式項目,隨後在 2018 年成為第二個正式畢業項目。2024 到 2025 年 Prometheus 開源社區發佈了 3.X 版本,活力不減當年。Prometheus 項目以靈活簡單的數據協議,豐富的生態工具鏈和雲原生項目廣泛地默認支持,成為雲原生時代監控領域的事實規範。
作為國內最早提供 Prometheus SaaS 化服務的廠商,阿里雲 Prometheus 團隊一直在跟進開源 Prometheus 的開發進展。目前阿里雲 Prometheus 上已經有數萬客户在使用,每天寫入幾十 PB 的流量,廣泛應用在雲產品監控、Kubernetes 監控、業務監控、AI Infra 監控和 AI 推理監控等場景。形成了阿里雲上最大規模的觀測指標數據生態。
2024 年開始,整個開源技術社區展現出 ALL IN AI 的趨勢,推動着 AI 時代的到來。那麼 Prometheus 是否會成為上個時代的產物無法適配 AI 時代的業務訴求呢?我們的答案是否定的。恰恰相反我們看到隨着人工智能技術的快速發展,AI 技術棧正經歷從單點模型到複雜系統、從單模態到多模態、從靜態推理到動態服務化的演進。在這一過程中,AI 系統的複雜性呈指數級增長:
- 模型規模:參數量從百萬級躍升至萬億級,訓練和推理的資源需求激增,然而算力緊缺是國內短期內難以解決的難題;
- 系統架構:從單機部署轉向分佈式集羣,大模型服務通過 SGLang,VLLM,Ray 等引擎分佈式部署。涉及 GPU/TPU 集羣、分佈式存儲、流水線調度等多組件協同;
- 數據流複雜性:基礎訓練需要訓練數據、推理請求、特徵工程、模型版本等形成多維度數據流。推理服務結合 MCP 工具鍊形成了遠超過往的複雜分佈式系統。
大規模 AI 可觀測的挑戰
大規模 AI Infra
AI Infra 核心關注 AI 模型訓練和推理所依賴的基礎算力供給。通常我們談 AI Infra 主要會包括以下幾方面:
(1)硬件設備統一監控
AI Infra 管理一些特有的設備以支撐 AI 計算,當然常規 CPU 算力同樣需要,統一監控需要覆蓋下述場景。
- 異構硬件管理:GPU、TPU、CPU、FPGA 的混合部署增加了資源分配的複雜性,需要有效的全局監控來提供可靠的基礎設施。
- GPU 健康狀態監控:GPU 內存泄漏、温度異常、顯存不足等問題可能導致訓練中斷。
- 網絡與存儲 IO:模型訓練過程通常涉及大量的網絡交換和存儲數據交換,繼而產生了配套的高性能網絡、大規模存儲等設施,網絡與存儲 IO 的波動直接影響訓練效率。
- 能耗與成本控制:AI 訓練的高能耗需實時監控以優化資源利用率。
(2)大規模容器集羣
我們觀察到,大模型訓練集羣目前基本採用 Kubernetes 架構。OpenAI 在去年底發生大規模故障,核心就是因為 Kubernetes 集羣 API Server 發生雪崩問題。據公開信息,早在 2021 年,OpenAI 訓練 GPT-3 的集羣規模在 7500+ 個節點(遠超社區 5000 節點最大規模限制),使用 Prometheus 收集大量指標數據。 本次故障的誘因就是因為節點上安裝的遙測組件導致 API Server 故障繼而導致雪崩。在阿里雲內部,大規模集羣節點超過 1w 節點,數十萬的 Pod 數量。對於觀測組件的挑戰非常大,然而全方面的觀測能力是必需。針對大規模容器集羣的觀測數據(指標、元數據、日誌等)採集、計算和存儲,特別是針對訓練集羣,離線任務集羣等 Pod 變更非常頻繁的情況,常規開源的組件都是無法支撐的。
(3)雲上異構產品
雲上的用户搭建用於訓練或推理服務,通常使用到多種雲產品。以阿里云為例,靈駿計算或 ECS 等產品提供算力,網絡、存儲相關產品提供高性能存儲和網絡,PAI 提供 AI PaaS 平台產品,百鍊等提供模型服務。還有正在快速發展的 AI 網關、FC 計算等。目前阿里雲已基本實現核心產品的監控數據以 Prometheus 規範統一供給,以實現異構雲產品的統一監控。這種統一大大降低了用户獲取和使用異構產品監控數據的門檻。
推理 App 架構快速發展
隨着 2025 年 DeepSeek 的火爆,大模型推理服務持續火爆,幾乎所有的互聯網企業、數字化轉型企業都已開始搭建企業自己的推理服務。目前我們觀察到,常見的 AI 應用架構大概如下:
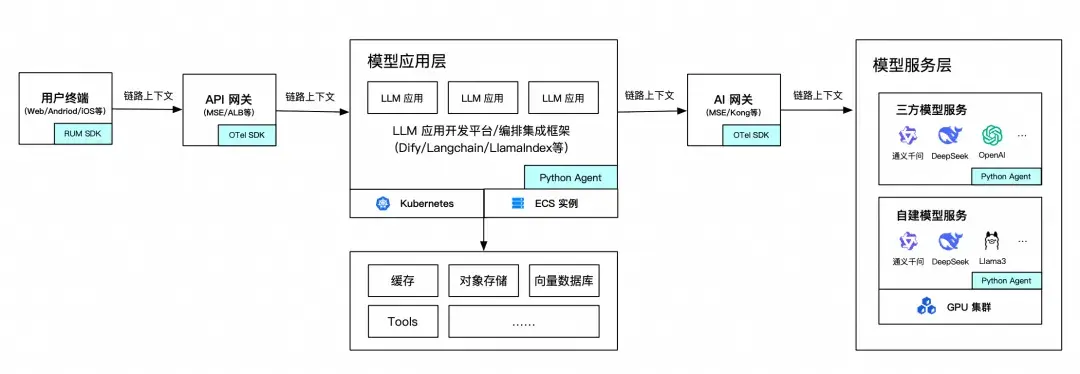
對於這種新型技術架構,監控指標設計非常重要。通過模型服務服務於模型應用的推理性能、成功率、準確率和成本都是需要重點關注的。對於一次推理的端到端全過程以及每個階段的關鍵指標我們認為如下:
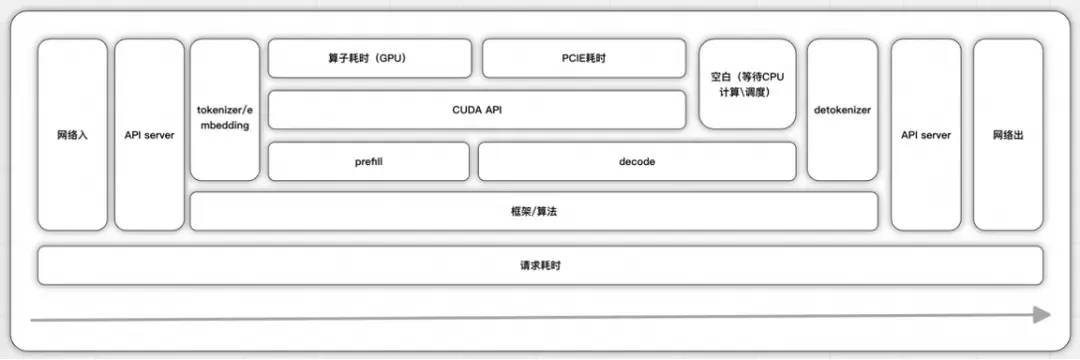
- Time To First Token (TTFT): 首 Token 延遲,即從接收請求到生成第一個 token 的時間,通常要求控制在 2-3 秒內。該指標直接反映 Prefill 階段的計算效率
- Prefill 是計算密集型,GPU 的利用率較高,所以也需要觀測 GPU 的使用率和 KV Cache 的利用率
- Time Per Output Token (TPOT):每個輸出 token 的延遲(不含首個 Token),一般需低於 50 毫秒以保證生成流暢性(約每秒 20 個 token)
- MBU:內存帶寬利用率,decode 是 IO 密集型,需要把參數和 KV cache 從顯存加載到計算單元,這個過程計算能力一般不是瓶頸,顯存帶寬才是瓶頸,而在多卡集羣的情況下,PCIe 卡帶寬或者速度更快的 NVlink 帶寬有可能成為瓶頸
- throughout:吞吐量,即每秒針對所有請求生成的 token 數。這個和 batchsize 有關,與 ttot 和 tpot 都是有制衡作用,推理性能目標是,最快的首個 token 響應時間、最高的吞吐量和最快的每個輸出 token 時間。
- Token 黑洞問題,輸入 Token 或輸出 Token 循環重複輸出,基於 AI 網關識別 Token 黑洞。
推理服務的全面監控對於 AI 應用的穩定運行至關重要。目前,黃金指標體系基本已經形成,新的穩定性問題也在持續出現,通過多模態指標、Trace 和日誌數據實現對 AI 應用的觀測,我們認為比歷史任何時候的需求都更為重要。
MCP Tools 模式的分佈式
MCP 定義了模型與工具服務之間的交互協議,這使得模型服務與海量的數字化服務產生了鏈接。這意味着通用模型服務將託舉起一個架構負責的大規模分佈式系統。通常對於用户的一個對話需求,背後需要幾個甚至幾十個 Tools 來完成。其中如果出現性能瓶頸或 Token 黑洞,都會導致整個推理過程不符合預期。因此對於 MCP Tools 本身和上下游的統一監控尤為重要。對於分佈式系統的統一監控是 Prometheus 監控體系的核心優勢。
多模態可觀測數據
Prometheus 社區目前也在與 OpenTelemetry 的融合,推動指標(Metrics)、日誌(Logs)、追蹤(Tracing)的統一收集與處理。在 AI 可觀測場景,完整的洞察方案都是需要結合指標、調用鏈和日誌。以實現快速的故障定位。指標通常用來統計數據、告警、發現問題,調用鏈負責追逐分佈式系統調用,例如 MCP Server 或 Agent2Agent 以定位故障點位或代碼行數,日誌用以明確具體的故障原因。良好的觀測系統依賴業務開發者做好指標定義、和 Trace 埋點。通常需要通過數據計算技術實現多種數據之間的轉換,或通過外掛探針技術實現數據精確採集,這些都是可觀測方案的核心。
阿里雲 Prometheus 2.0 方案
為了應對大規模 AI 可觀測的挑戰,阿里雲 Prometheus 團隊總結 1.0 的產品技術在雲原生時代大規模落地的經驗,重新整合離散的技術,推出了全新的阿里雲 Prometheus 2.0 方案。本方案同樣全面兼容 Prometheus 社區的協議規範,提供用户全方位的使用體驗提升。接下來我從數據採集、存儲、計算、查詢、數據生態和分析語言、業務系統集成等維度做簡要介紹。
數據採集 LoongCollector
團隊堅持自研指標採集服務,本次升級進行了全面的重構。將指標採集和服務發現能力全面移植到阿里雲開源 LoongCollector,以實現一個支持多模態數據大規模採集的統一組件。目前 LoongCollector 已支持日誌、指標、元數據、Profiling 等數據形態。從指標數據看,LoongCollector 架構上區分服務發現模塊 LoongOperator 和數據採集 Pipeline Collector。以容器集羣數據採集為例,LoongOperator 實現了超 10w+ 的 Target 發現規模和分佈式調度,Collector 副本數根據 Target 數量和數據量自動擴容。全面兼容社區 CRD 規範,支持 ServiceMonitor, PodMonitor,Prometheus Rule,PrometheusConfig 等。Collector 部分採用 C++ 實現,在內部使用的場景中,跑出了單核 70 M/s 的性能。同時全面兼容社區 Prometheus Agent,VM Agent 對於指標採集的規範和約定。同等數據規模下,性能較 VM Agent(目前開源實現中性能較好的)內存下降 50%,CPU 下降 20%。在隨後的版本計劃中,LoongCollector 將發行標準 Kubernetes 集羣版、SideCar 版和主機版本,以實現無處不在的數據採集。
大規模時序存儲
阿里雲 Prometheus 1.0 的時序存儲獨立建設,與日誌、Trace 等數據形態互通性不佳。隨着 AI 時代到來以及全棧可觀測需求的發展。我們越發認為可觀測數據的採集和存儲需要統一,生態數據處理能力應該互通。因此在 2.0 版本中,我們將時序存儲底層與阿里雲日誌、Trace 等數據存儲形態實現統一。這種統一體現在網關統一,存儲層統一,計算和查詢技術棧一致。在此基礎上,自研全新的時序數據引擎,在內存實時壓縮、文件壓縮、自適應 Block、多數據類型、支持數據更新等技術上實現突破。在查詢計算引擎上,為了充分發揮 CPU 多核、指令加速能力,以及對計算、內存資源的精細化控制。相對於社區目前主流的 Go 語言實現的 Prometheus 計算引擎,我們使用 C++ 來開發新的 Prometheus 計算引擎。新的引擎對於計算流程上及實現上進行了全面改造,實現了更高的性能、穩定性和 QoS 控制。此外在 PromQL 的兼容性測試中,Prometheus C++ 計算引擎與開源的兼容度為 100%。
在線上一些典型的查詢場景,目前 Prometheus 2.0 和 VictoriaMetrics 的查詢延遲如下:
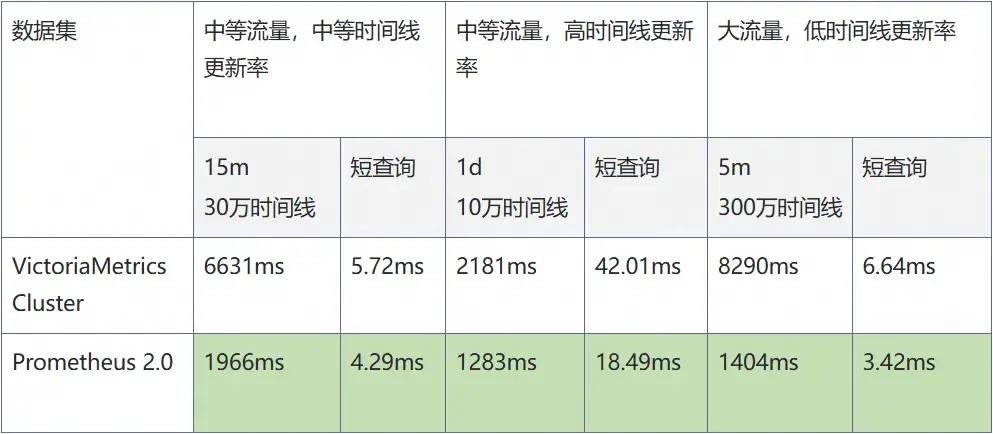
從測試結果可以看出,阿里雲 Prometheus 2.0 的查詢性能對比 VictoriaMetrics 在各個場景下全面領先。
預聚合計算(RecordingRule 與 ScheduleSQL)
對於指標相關的預聚合計算的考慮,我們認為除了 Metric2Metric 以外,Log2Metric,Metric2Others 在 AI 全棧觀測中應用廣泛。Prometheus 社區在 2018 年就引入 RecordingRule 規範和實現。提供以 PromQL 語法框架下的 Metric2Metric 計算。這種能力在阿里雲 Prometheus 1.0 版本中同樣提供,服務了數千的用户,運行了數萬的計算任務。但我們認為該功能沒有達到 Stable 狀態。1.0 主要繼承了社區的實現,從任務調度上出現較多的調度不均、失效等問題,運維成本較高。
在 2.0 版本中,我們基於在日誌服務中廣泛使用的調度和計算引擎,重寫了 RecordingRule 實現。從調度上解決了調度不均、調度失效、調度性能不足的問題,實現更大規模的指標數據預聚合計算。計算上基於全新的時序引擎,以實現高性能的數據加載和計算。這種計算能力將廣泛用於雲產品監控,容器監控等場景。通過預計算來解決 PromQL 複雜,容器指標理解門檻高,查詢計算成本高等問題。
只有 RecordingRule,我們認為是不夠的。我們經常收到用户需求,能不能用類似 SQL 的語法來進行指標計算,因為業務開發者對於 PromQL 的掌握是有門檻的。另外,由於 Prometheus PromQL 的限制,對於涉及多值或更多算子的需求是難以滿足的。由於我們將指標存儲與阿里雲日誌存儲實現統一,天然集成了日誌領域的 ScheduleSQL 計算能力。這是一種類 SQL 的語法,可以實現對指標數據多樣化的分析。同樣 ScheduleSQL 作用於常規日誌數據時,可以直接從日誌計算出統計指標存入 Prometheus。全面打通了數據格式間的孤島。
查詢聚合 View
聊完採集、存儲和計算,來到數據查詢階段。阿里雲 Prometheus 2.0 除了提供標準的單實例 Query、RemoteRead 接口以外,針對統一監控的查詢場景提供查詢時聚合 View 的產品能力。在 1.0 版本中該功能已經推出並得到廣泛使用,它支持跨區域、跨賬號的統一查詢多個 Prometheus 實例。 這裏利用到算子下推、數據自動路由等技術實現數據查詢加速。
在 2.0 版本中,得益於底層存儲的融合,聚合計算進一步加強。查詢引擎升級為通用聚合引擎,底層支持聚合指標存儲、日誌存儲和事件存儲,結合 SPL 可以實現異構數據的統一分析。另外在跨區域數據查詢上優化了網絡鏈路,性能得到顯著提升。
雲上指標數據生態
除了技術全面升級以外,阿里雲 Prometheus 的核心競爭力是提供了全面的雲產品監控數據生態。截止目前,已經超過 80% 的核心雲產品底層採用 Prometheus 技術棧採集、存儲和計算監控數據。我們通過 Prometheus 標準協議向用户提供最為及時、完善的雲產品監控指標,一舉從過去分鐘級的指標數據提升到秒級。這非常有利於全面上雲的用户建立全棧監控。
目前,阿里雲 Prometheus 為用户提供靈駿計算、PAI、百鍊、AI 網關、 FC 等 AI 全技術棧產品的完整監控數據。
智能分析語言 PromQL 與 SPL
PromQL 是 Prometheus 開源項目帶來的指標查詢語言。PromQL 通過標籤驅動、直觀語法、強大運算能力和生態集成,成為現代可觀測性指標工具鏈的核心。它不僅簡化了時間序列數據的查詢與分析,還通過與 Prometheus 生態的深度整合,為系統監控、性能調優和故障排查提供了高效、靈活的解決方案。無論是開發人員調試微服務,還是運維團隊管理雲原生環境,PromQL 都是不可或缺的利器。
阿里雲 Prometheus 2.0 查詢引擎實現了 PromQL 的 100% 社區兼容性,並提供了額外的擴展算子。這使得用户可以無縫轉移社區成果到阿里雲 Prometheus 服務,沒有遷移成本。
對於更高級的數據計算,例如數據富化(增加標籤),多模數據聯合計算等需求,數據關聯查詢等需求,我們即將提供一種新的計算形式 SPL。它是一種 Pipeline 模式的數據計算編排,SPL 提供了大量的算子和多路數據提取能力,可以直接作用於數據流處理。用户可以基於 SPL 實現指標數據的實時加工處理。也可以用於與 AI 系統的集成來實現標準的數據提取。指標數據不是可觀測的唯一,與日誌、Trace、Entity 等數據實現關聯分析是故障洞察最為有效的手段。 SPL 為實現該能力提供支撐。
業務分析-大數據生態集成
指標數據除了用於穩定性監控,服務運維人員以外,已經有大量的用户將 Prometheus 技術棧用於業務分析服務於業務和運營。用户通過在業務代碼中植入 SDK 來埋點業務指標,通過阿里雲 Prometheus 服務提供的可靠採集、存儲服務管理數據,最後通過 Grafana 來可視化分析。除此之外,我們還有其他手段來與業務數據打通嗎?通常業務系統的離線業務分析會採用大數據技術棧,例如 Flink、Kafka 等。對此,阿里雲 Prometheus 服務藉助底層統一能力,支持用户通過 Kafka 或 Flink RemoteWrite Sink 等模式,將時序數據從其他數據分析平台寫入阿里雲 Prometheus。也可以通過數據訂閲消費、數據投遞等渠道將數據寫入大數據分析體系,實現了良好的數據互通性。
新版本的實現從去年開始在阿里雲內部投產,截止目前 Prometheus 2.0 已在內部 AI 系統的可觀測中全面落地:
- 單集羣規模:常規模式下支持 5K+ 集羣節點(10w+ Targets)的採集規模、提供 1 GB/s 的數據採集能力;針對部分超大規模集羣,僅需禁用部分通用功能後實現可靠的數據採集。
- 成本優勢:某超大規模推薦系統客户將監控成本降低 40%,同時查詢性能提升 2 倍;
- AI 專用場景:為百鍊、通義千問等大模型提供從訓練資源利用率到推理 SLA 的全鏈路監控。
阿里雲 Prometheus 2.0 服務正在整合到阿里云云監控平台,通過阿里云云監控控制枱對客提供服務。存量 v1 Prometheus 實例我們會逐步後台遷移到新版本。
為了為你提供更為標準的雲上服務, 阿里雲 Prometheus 2.0 服務的 OpenAPI 體系進行了升級遷移,後續你可以從雲監控 2.0 的 API 體系(cms-20240330)中獲取到。需要基於 OpenAPI 進行集成的用户需要做出對應的 API 變更,我們在此表達歉意。如果您對本文介紹到的某些特性有興趣,歡迎通過用户羣、工單等形式與我們交流。
結語: AI 觀測的未來已來
阿里雲 Prometheus 2.0 通過存儲、計算、智能分析、生態的全面升級,重新定義了面對超大規模 AI 系統的商業化 Prometheus 方案。其核心價值不僅在於技術指標的突破,更在於實現了可觀測數據生態從雲上“基礎設施層”延伸到“業務模型層”的全覆蓋,為 AI 工程化落地提供了不可或缺的觀測工具。隨着 AI 技術向實時性、大規模化演進,阿里雲 Prometheus 2.0 或將成為企業構建下一代 AI 系統的基礎設施基石。阿里雲 Prometheus 2.0 是阿里雲可觀測產品族的一員,在不久的將來我們將全面發佈雲監控 2.0 產品,以提供更為全面的智能觀測技術和產品棧。
在此,謹代表阿里雲 Prometheus 團隊全體開發者,感謝多年以來數萬用户的支持和需求反饋,是你們推動了阿里雲 Prometheus 服務的持續成長。我們繼續努力,為您提供最為可靠的可觀測基礎數據服務。