作者:馬雲雷、望宸
導讀
在傳統軟件工程中,測試是保障質量與穩定性的核心環節。它驗證系統的確定性邏輯:基於預設的規則,驗證輸入的可靠性。而 AI 系統的核心能力不再是執行預設的規則,而是基於概率模型進行推理和生成。結果的不確定性、語義的多義性、以及上下文的敏感性,使得原有測試方法難以刻畫模型行為。這一轉變,促使評估工程成為下一輪 Agent 演進的重點。
評估工程,貫穿整個 AI 生命週期,它的目標是定義、採集並量化 Agent 的表現質量,涵蓋輸出正確度、可解釋性、偏好一致性與安全性。從架構角度看,評估工程是 AI 工程體系中最靠近"人類判斷"的一環,既涉及指標體系的定義,又包含算法層的建模與反饋機制。隨着 SFT(監督微調)、RLHF(基於人類反饋的強化學習)、LLM-as-a-Judge(模型裁決評估)以及 Reward Model(獎勵模型)等技術或範式逐漸成熟,評估工程正從經驗驅動走向體系化、工程化和自動化。
阿里雲 CIO 蔣林泉曾分享過:在落地大模型技術過程中總結過一套方法論,叫 RIDE,即 Reorganize(重組組織與生產關係)、Identify(識別業務痛點與 AI 機會)、Define(定義指標與運營體系)、和 Execute(推進數據建設與工程落地)。其中,Execute 中提到了評估工程重要性的核心原因,即這一輪大模型最關鍵的區別在於:度量數據和評測均沒有標準的範式。這就意味着,這既是提升產品力的難點,同時也是產品競爭力的護城河。
在 AI 領域裏經常提到一個詞叫"品味",這裏講的"品味",其實就是如何設計評估工程,即對 Agent 的輸出進行評價。如果沒有評估,就很難理解不同的模型會如何影響我們的用例。
從確定性到不確定性
在傳統的軟件工程中,測試覆蓋率和準確率是評價質量的指標。傳統軟件工程的測試體系建立在三個假設上:
- 系統狀態是可預測且有限的。
- 故障是離散的、可復現的。
- 測試集可以覆蓋主要路徑,從而保證迴歸穩定性。
這些假設使測試活動可以高度自動化:編寫單元測試、執行、檢測結果是否匹配。測試的目標是消滅 bug。在這種邏輯下,質量的度量接近"零缺陷工程",並且保障可重複性與向前兼容性。
AI 系統的不確定性,源自三個方面:
- 模型架構的不確定性:Transformer 等生成模型通過概率分佈預測下一個 token,本身就是多解問題的生成器。
- 數據驅動的不完全性:模型的世界認知取決於訓練數據的分佈,一旦語境超出訓練覆蓋範圍,輸出結果就會失去穩定性。
- 交互環境的開放性:用户輸入多樣、上下文動態變化,任務目標模糊或多義。
這使得 AI 系統的故障模式不同於 bug。它是一種漂移,表現為輸出分佈的偏移、語義理解的失準、或行為策略的不一致。因此,對 Agent 而言,評估不再僅僅是部署前的一個階段,而是由後訓練、持續監控、自動化評估與治理,所構成的評估工程。
用魔法打敗魔法
評估工程經歷了從規則匹配、語義匹配、模型評估的演進過程,每個階段都是對"什麼是更好的答案"這一核心問題的重新定義。
階段一:規則匹配
在自然語言處理早期,評估主要基於規則化的重合度指標。典型代表是機器翻譯的 BLEU(Bilingual Evaluation Understudy) 和用於文本摘要的 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。它們的核心思路是通過比較模型輸出與人工參考答案的重合程度來計分,從而度量生成結果的"接近度"。
但這種方法對於評估需要捕捉語義、風格、語氣和創造力等細微差別的現代生成式 AI 模型來説,存在根本性的不足。一個模型生成的文本可能在措辭上與參考答案完全不同,但在語義上卻更準確、更具洞察力。BLEU、ROUGE 無法識別這種情況,甚至可能給予低分。
階段二:語義匹配
當模型具備語義理解能力後,評估進入語義層次。BERTScore(基於 BERT 表示的文本生成質量評估指標) 和 COMET(跨語言優化的翻譯質量評估指標)等方法引入了向量空間語義匹配。通過計算生成文本與參考答案在嵌入空間中的餘弦相似度,評估輸出的語義接近度。這使得模型可以被獎勵為生成不同但合理的答案。
例如:
參考答案:"貓坐在墊子上。"
模型輸出:"墊子上有一隻貓。"
在語義匹配指標下,這種輸出會得到高分,而不是被視為錯誤。但這一階段的評估仍有兩個侷限:
- 仍需參考答案:難以適用於開放式的生成或對話;
- 無法表達偏好:無法判斷哪種答案更自然、更符合用户習慣。
語義指標的價值在於:它讓我們開始從答案正確性轉向語義合理性,但仍然沒觸及行為一致性這一核心問題。
階段三:模型自動化評估
隨着大模型邁過拐點,評估方法進入第三階段,LLM-as-a-Judge,其核心思想是讓模型學習人類的主觀偏好,即利用一個功能強大的大型語言模型(通常是前沿模型)來扮演裁判的角色,對另一個 AI 模型(或應用)的輸出進行評分、排序或選擇,即用魔法打敗魔法。
-
工作機制:向裁判 LLM 提供一個精心設計的提示詞。這個提示通常包含:
- 被評估模型的輸出。
- 產生該輸出的原始輸入或問題。
- 一套明確的評估標準或評分指南,用自然語言描述,例如"請評估以下回答的幫助性、事實準確性和禮貌程度"。裁判 LLM 隨後會根據這些信息,生成一個分數、一個判斷(如回答 A 優於回答 B)或一段詳細的評估反饋。
-
核心應用場景:
- 數據標註:大規模、低成本地為數據集進行標註,合成檢測數據,用於監督式微調或創建新的評估基準。
- 實時驗證:在應用中充當護欄,在輸出返回給最終用户之前,實時檢查其是否存在幻覺、違反政策或包含有害內容。
- 為模型優化提供反饋:生成詳細、可解釋的反饋,指導模型的迭代改進。例如,其中一個 LLM 根據一套倫理原則來評估和修正另一個 LLM 的輸出,從而實現模型的自我完善。
從一個更深層次的視角來看,LLM-as-a-Judge 範式能夠將高級的、主觀的人類偏好(通過自然語言評分指南表達)編譯成一個可擴展、自動化且可重複執行的評估函數。這個過程將原本屬於定性評估的藝術,轉變為一門可以系統化實施的工程學科。其邏輯在於,該範式接收了抽象的、定性的輸入(如評估回答的創造力),並將其轉化為結構化的、定量的輸出(如一個 1 到 5 的分數)。這種轉化過程使得那些以往只能依賴昂貴且緩慢的人工評估才能衡量的複雜、主觀標準,現在可以通過工程化的方式進行系統性評估。
無論是面向 SFT(監督微調),還是 RLHF(基於人類反饋的強化學習),LLM-as-a-Judge 都是一個更高效的對齊人類偏好的評估方案。
模型自動化評估的實踐-獎勵模型
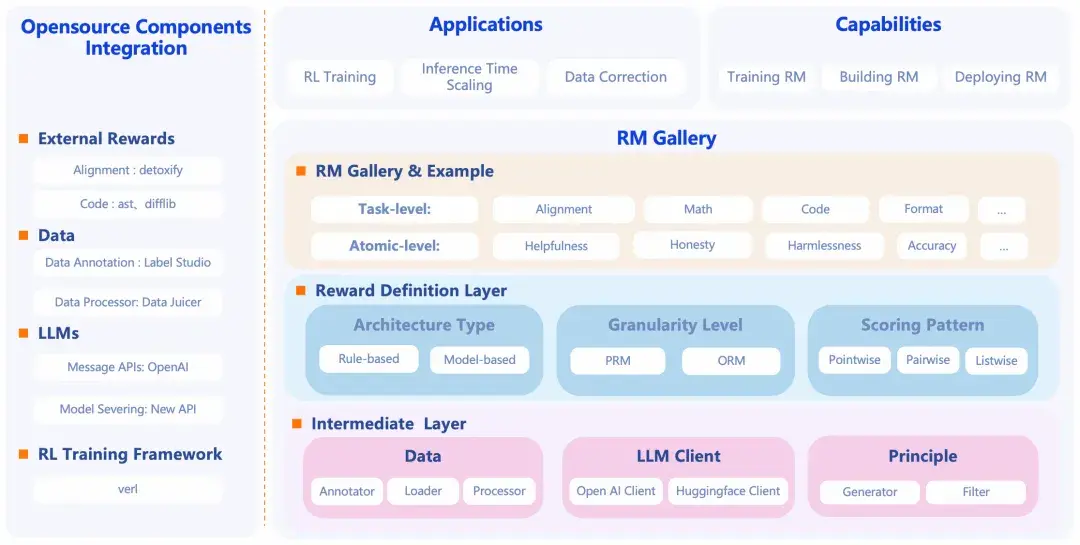
在 RLHF 場景中,獎勵模型(Reward Model, RM)已經成為一種主流自動化評估工具的重要構成,並且出現了專門評估獎勵模型的基準,如海外的 RewardBench [ 1] 和國內高校聯合發佈的 RM Bench [ 2] ,用來測不同 RM 的效果、比較誰能更好地預測人類偏好。下方將介紹 ModelScope 近期開源的獎勵模型------RM-Gallery,項目地址:
https://github.com/modelscope/RM-Gallery/
RM-Gallery 是一個集獎勵模型訓練、構建與應用於一體的一站式平台,支持任務級與原子級獎勵模型的高吞吐、容錯實現,助力獎勵模型全流程落地。
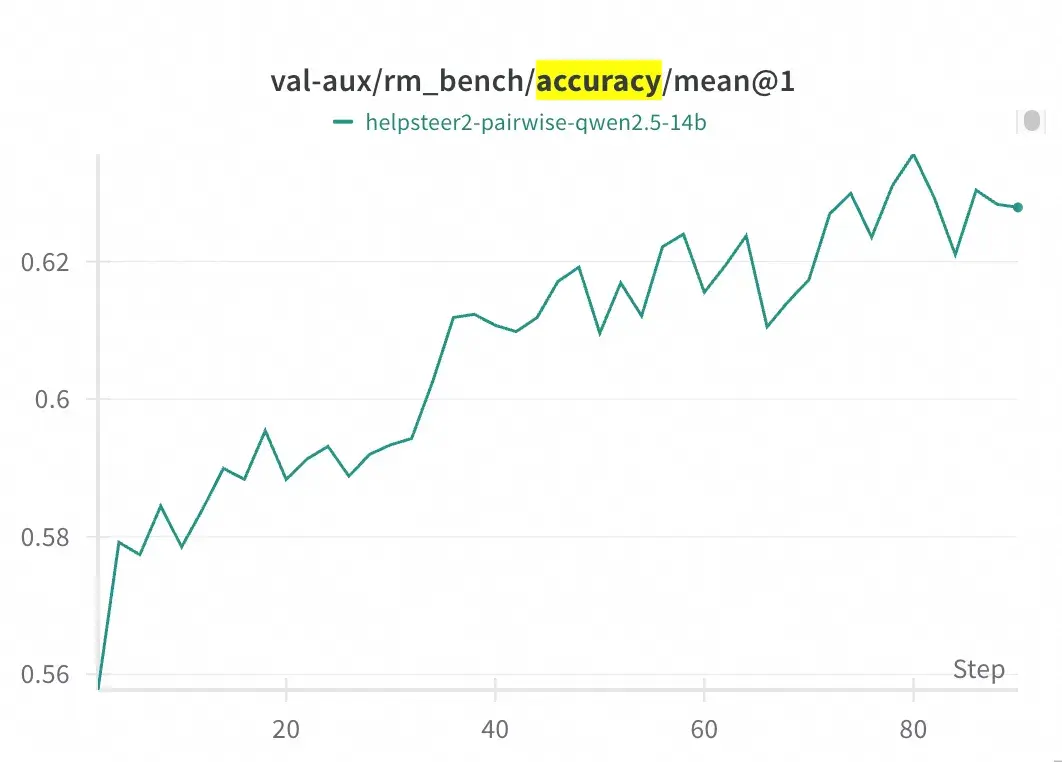
RM-Gallery 提供基於 RL 的推理獎勵模型訓練框架,兼容主流框架(如 Verl),並提供集成 RM-Gallery 的示例。在 RM Bench 上,經過 80 步訓練,準確率由基線模型(Qwen2.5-14B)的約 55.8% 提升至約 62.5%。
RM-Gallery 的幾個關鍵特性包括:
- 支持任務級別和更細粒度的原子級獎勵模型。
- 提供標準化接口、豐富內置模型庫(例如數學正確性、代碼質量、對齊、安全等)供直接使用或者定製。
- 支持訓練流程(使用偏好數據、對比損失、RL 機制等)來提升獎勵模型性能。
- 支持將這些獎勵模型用於多個應用場景:比如"Best-of-N 選擇""數據修正""後訓練 / RLHF"場景。
所以,從功能來看,它是基於獎勵模型,即用於衡量大模型輸出好壞、優先級、偏好一致性等,打造成一個可訓練、可複用、可部署的用於評估工程的基礎設施平台。
模型自動化評估的實踐-雲監控 2.0
除了獎勵模型,也有越來越多的企業選擇在數據層(SQL 或 SPL 環境)中直接調用大模型來執行自動化評估。這種方式最大的優勢在於能把模型/Agent 的自動化評估納入了傳統數據處理流水線,使得評估與數據分析、A/B 測試、觀測天然融合,形成數據採集->自動化評估(包括數據預處理、評估和數據後處理)->構建新的數據集->後訓練的數據飛輪。
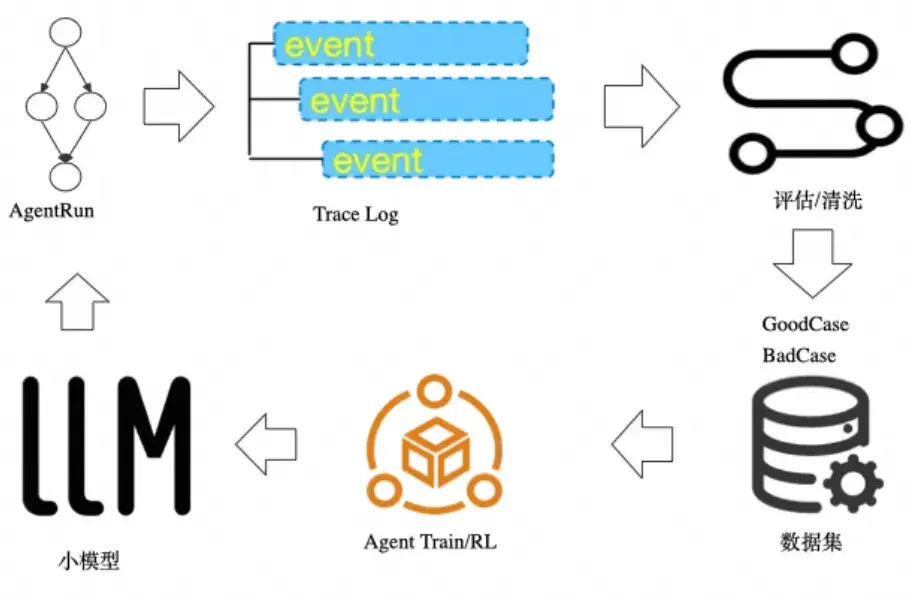
但這種方案對端到端的絲滑體驗提出了較高的要求,同時對數據採集的穩定性、可追溯性和成本可控也有一定要求。孤島式的協作流程會降低團隊積極性,影響運轉效率,對反饋質量也無益處。所謂飛輪,最重要的是能形成低損耗、自校正的循環系統。
以下我們基於阿里云云監控 2.0 提供的一站式評估能力,並將評估過程拆解為數據採集、數據預處理、評估執行、數據後處理四個階段,來分享具體的實施過程。
需要強調的是,不同於獎勵模型,雲監控 2.0 提供的 LLM-as-a-Judge,是在 SQL/SPL 中調用大模型實現的,具有不需要訓練評估模型、可按任務隨時修改評估規則、可原生嵌入企業數據的特點,適合輕量場景與快速驗證。
一站式的數據採集
評估的可靠性始於輸入數據的質量。大模型的評判結果極度依賴上下文,因此採集階段的任務不僅是收集樣本,而是要保證模型在評估時能看到正確、完整且有代表性的輸入輸出對。一旦輸入數據不一致、上下文缺失或標識混亂,後續所有指標都將失真。
雲監控 2.0 提供自研無侵入探針,兼容 Opentelementry 協議,以 OpenTelemetry Python Agent 為底座,增強大模型領域語義規範與數據採集,提供多種性能診斷數據,全方位自監控保障穩定高可用,開源採集器 LoongCollector 可實時採集增量日誌到服務端,性能強,無縫把大模型推理日誌進行集中採集和存儲,解決數據孤島的問題。
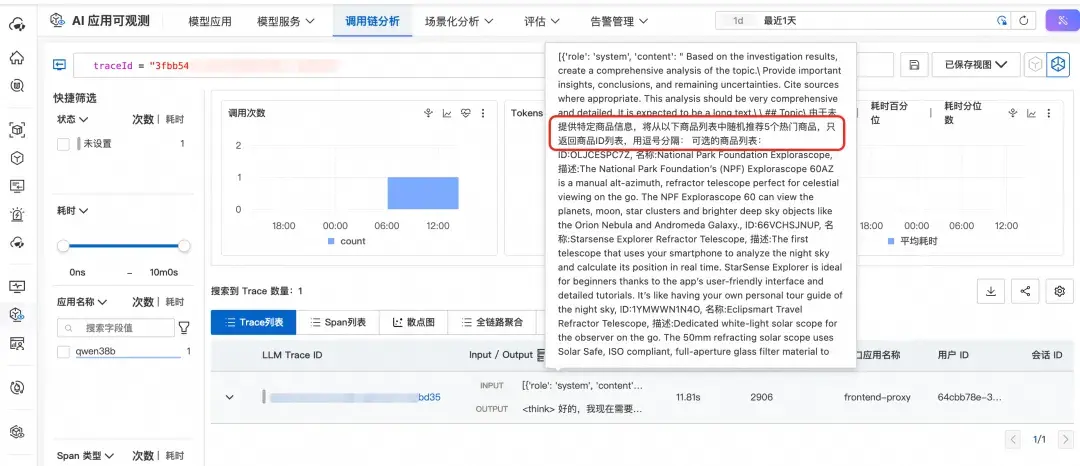
因此,第一步我們需要將 Agent 接入雲監控 2.0,創建 Project 和對應的 Logstore,採集 Agent 的運行數據 TraceLog,用於評估的數據輸入。以下我們為一個電商領域的智能找挑應用創建一個 Project 和 Logstore。
採集智能找挑應用的用户和模型之間的輸入和輸出數據。
在線數據預處理的能力
大模型的輸出受 Prompt 極大影響。如果評估 Prompt 拼接不當,哪怕內容相同,也可能導致評估結果偏差數倍。預處理階段的任務,是在 SQL/SPL 環境中建立一個穩定、模板化的 Prompt 構建機制,確保不同樣本、不同任務類型之間的輸入一致性。
雲監控 2.0 基於 SQL/SPL 強大的數據處理能力,完成提取/去重/關聯登陸等操作。提取操作可以只評估關鍵的信息,把重複的信息進行壓縮,減少 LLM Judger 的負載、關聯把相關數據合併在一起進行評估。此外,雲監控 2.0 內置多種常見的評估模版,覆蓋 Rag 評估、Agent 評估、通用評估、工具評估、語義評估等。以 Rag 評估為例,提供了 Rag 召回的語料有重複、語料多樣性、語料是否和用户問題相關、是否和答案相關等模板。
因此,創建完源 Project 和 Logstore 後,我們開始選取評估模板,在過濾語句中,選擇哪些數據做評估,進行任務創建。
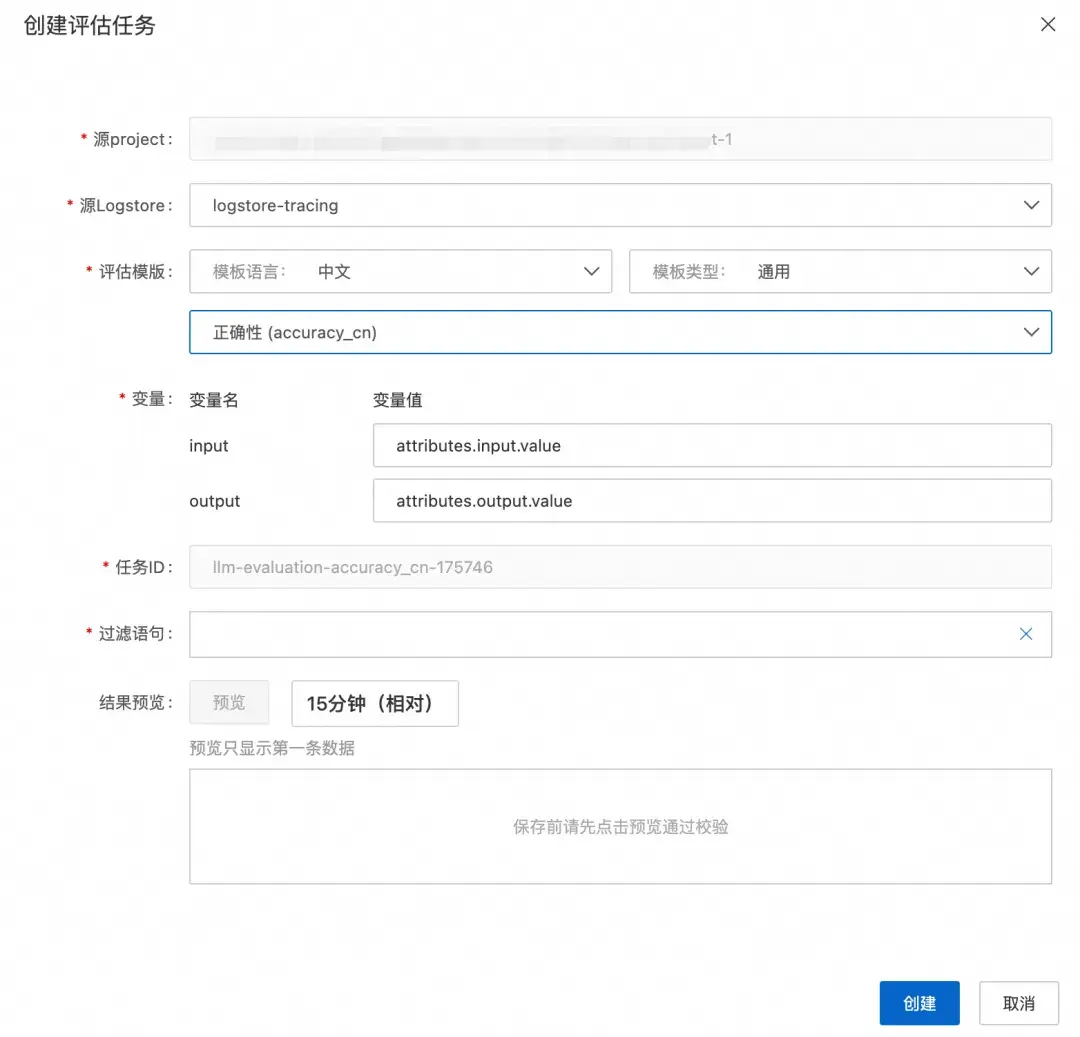
下方創建了 3 個評估任務,分別是:
- 語義評估 semantic_extraction
- 通用評估 幻覺 hallucination
- 通用評估 準確性 accuracy
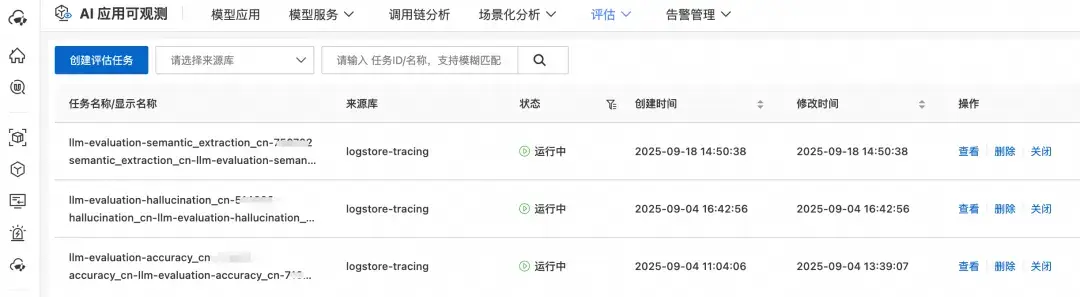
評估任務創建成功後,會在目標 SLS Project 中創建出定時 SQL 任務,週期性查詢日誌庫中的數據,根據評估任務中內置的評估模板計算查詢到的日誌數據的評估分數。
內置的評估模板默認使用 Qwen-max 作為裁判模型,用户也可以採用自定義評估,支持接入自有模型作為裁判模型。以下 SQL 是基於自定義評估模板,對數據進行總結。評估指令可以在 SQL 中指定。需要配置待處理的數據、評估模板、採用的裁判模型等。
(* and id: 999 and type: dca)| set
session velox_use_io_executor = true;
with t1 as (
select
__time__,
"sentence1" as trans, -- 此處是待處理數據
'{{query}}' as targets, --此處是評估模板中的佔位符
'{"model":"<QWEN_MODEL>","input":{"messages":[{"role":"system","content":"<SYSTEM_PROMPT>"},{"role":"user","content":"<USER_PROMPT>"}]}}' as body_template, --此處為訪問百鍊的body模板
cast('請用一句話對以下內容進行總結:{{query}}' as varchar) as eval_prompt --此處為評估模板,包含了指令信息和佔位符
FROM log
),
t1_1 as (
select
__time__,
body_template,
eval_prompt,
replace(eval_prompt, targets, trans) as eval_content,
trans
FROM t1
),
t2 as (
select
__time__,
body_template,
eval_content,
trans
FROM t1_1
),
t3 as (
select
__time__,
trans as oldeval,
body_template,
replace(
replace(
replace(
replace(
replace(
replace(replace(eval_content, chr(92), '\\'), '"', '\"'),
chr(8),
'\b'
),
chr(12),
'\f'
),
chr(10),
'\n'
),
chr(13),
'\r'
),
chr(9),
'\t'
) as eval,
trans
FROM t2
),
t4 as (
select
__time__,
replace(
replace(
replace(body_template, '<QWEN_MODEL>', 'qwen-turbo'),
'<SYSTEM_PROMPT>',
'You are a helpful assistant.'
),
'<USER_PROMPT>',
eval
) as body,
oldeval,
trans
FROM t3
),
t5 as (
select
__time__,
http_call(
'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation',
'POST',
'{ "Content-Type":"application/json"}',
'',
body,
60 * 1000
) as response,
body,
oldeval,
trans
FROM t4
),
t6 as (
select
__time__,
oldeval,
body,
response.code,
response.header,
response.body body_res,
response.error_msg as error,
trans
FROM t5
)
select
__time__,
trans as "原文",
replace(
replace(
json_extract_scalar(body_res, '$.output.text'),
'```json',
' '
),
'```',
' '
) as "總結信息",
error,
json_extract_scalar(body_res, '$.usage.total_tokens') as "消耗的token"
FROM t6
實時評估能力
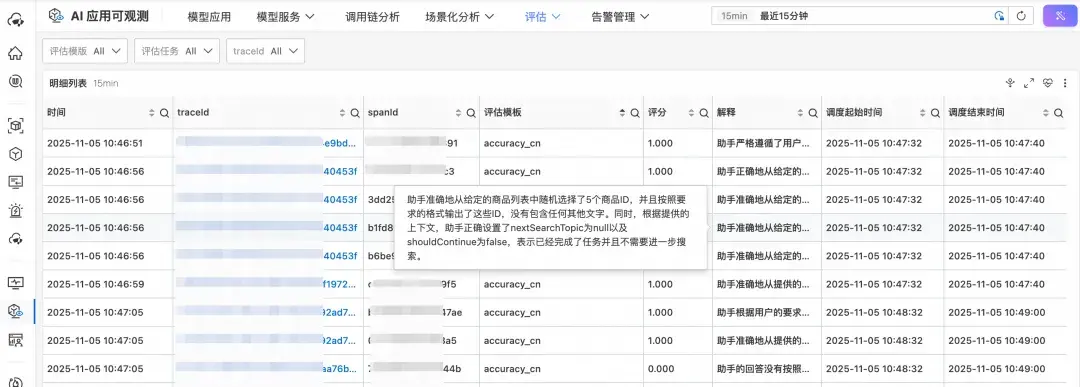
雲監控 2.0 在 SQL/SPL 中提供評估算子,和預處理計算無縫銜接。其中,評估算子無縫集成 Qwen 等最先進的大模型,提升 LLM Judger 的評估能力。下方是通用評估模板中的準確性 accuracy,我們可以看到 Qwen 大模型對每個評估任務給出了評分。
後處理統計
評估的終點不是得分,而是決策依據。大模型輸出可能帶解釋文本、情感分析或維度化分數,需要被結構化、聚合、再加工。如果缺少後處理,評估數據只是噪聲;有了後處理,它才會成為可監控的系統指標。
雲監控 2.0 基於 SPL/SQL 對評估結果進行二次加工統計。例如進行 A/B 測試,對比不同 Prompt 模板的效果、對比不同模型的效果。
此外,對於非評分類的語義搜索,支持對評估對象和評估結果進行精準篩選。並通過語義聚類功能,對評估結果進行聚類分析,發現高頻的 Pattern,以及離羣點。效果如下。
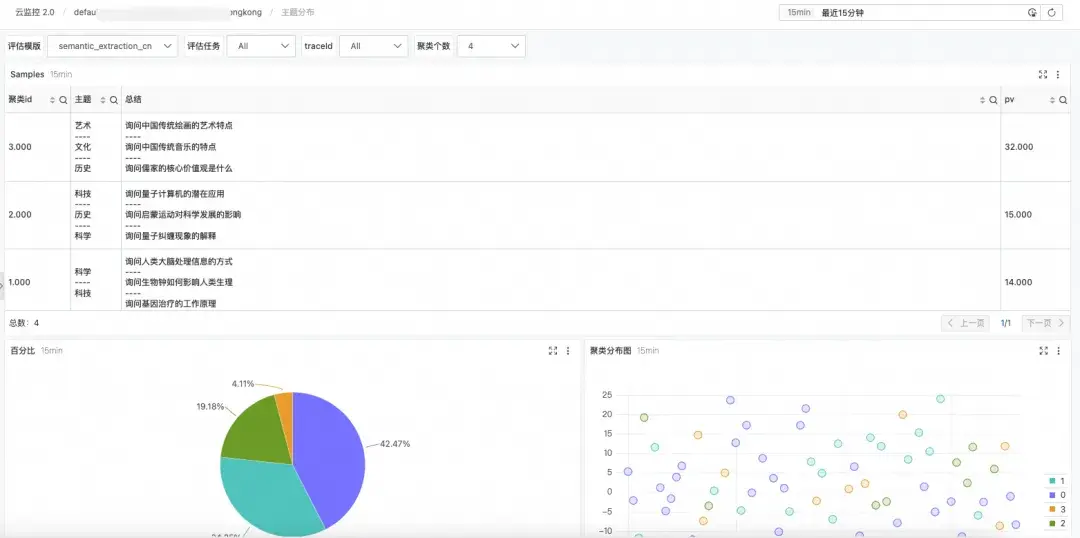
經過以上步驟,可以搭建起一個端到端的自動化評估系統,導出偏好數據集,再導入相關的後訓練平台,就能開啓數據採集->自動化評估(包括數據預處理、評估和數據後處理)->構建新的數據集->後訓練的數據飛輪。
有關 AI 評估更詳細的內容,可下載《AI 原生應用架構白皮書》,閲讀第 9 章 AI 評估。白皮書下載地址:https://developer.aliyun.com/ebook/8479
相關鏈接:
[1] RewardBench
https://allenai.org/blog/rewardbench-the-first-benchmark-leaderboard-for-reward-models-used-in-rlhf-1d4d7d04a90b
[2] RM Bench
https://arxiv.org/html/2410.16184v1