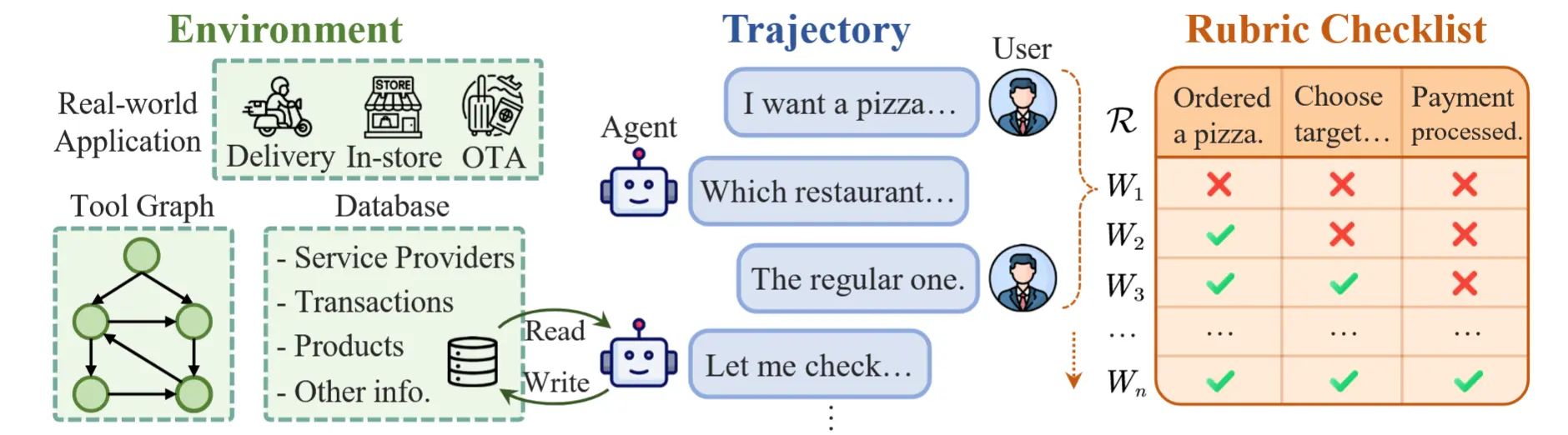
由美團 LongCat 團隊研發的 VitaBench(Versatile Interactive Tasks Benchmark)正式發佈,這是當前高度貼近真實生活場景所面臨複雜問題的大模型智能體評測基準。

VitaBench 以外賣點餐、餐廳就餐、旅遊出行三大高頻真實生活場景為典型載體,構建了包含 66 個工具的交互式評測環境,並進行了跨場景的綜合任務設計,例如要求 agent 在一個旅行規劃任務中通過思考、調用工具和用户交互,完整執行到買好票、訂好餐廳的終端狀態。
我們首次基於深度推理、工具使用與用户交互三大維度對智能體任務進行了量化拆解,以可控地構建複雜問題。我們發現,即便是當前領先的推理模型,在主榜(複雜跨場景任務)中的成功率也僅有 30%,揭示了現有智能體與複雜真實生活場景應用需求之間的顯著差距。VitaBench 現已全面開源,旨在為推進智能體在真實生活場景中的研發與應用提供重要基礎設施。
一、研究背景:智能體評測與現實應用間存在巨大鴻溝
隨着大語言模型在複雜推理與工具調用能力上的快速進步,基於 LLM 的智能體在真實生活場景中的應用日益廣泛。然而,現有的智能體評測基準與現真實生活場景的應用需求之間依然存在顯著差距,主要體現在以下幾個方面:
- 工具生態簡單化:早期的工具調用基準主要評估單次 API 調用的準確率(如:函數選擇、參數填充),忽視了真實工具間的複雜依賴關係與組合調用需求;
- 信息密度不足:大多數相關基準僅關注單一類型信息,未能反映真實應用場景中多源信息(時空信息、常識信息、多場景服務數據、用户畫像、用户歷史交易數據等)的綜合處理需求;
- 模型探索性受限:現有基準為了模擬真實生活場景,通常會將領域知識組裝成冗長的 Policy 文檔要求模型遵循,但是這種做法會限制模型在複雜環境中探索解空間的自主性。同時,這種模式下,除了進行深度思考、有效環境交互的能力外,模型的長文本指令遵循能力也對執行結果有很大影響;
- 交互動態性缺失:用户作為環境的重要組成部分,大多數交互式 Agent 基準當前沒有充分考慮到用户交互行為的多樣性、用户需求的模糊性、多輪對話中的意圖轉移等真實複雜度;
通過對美團生活服務場景的深入分析,LongCat 團隊指出:真實世界的任務複雜性,源於三大維度的交織:
- 推理複雜性:需整合多源信息、自主推理規劃任務完成路徑;
- 工具複雜性:需在高度互聯的工具圖中理解領域特徵,精確調用目標工具;
- 交互複雜性:需在多輪對話中主動澄清、追蹤意圖、適應多樣化的用户行為並給予反饋。
為系統衡量這三重挑戰下的模型表現,團隊構建了 VitaBench,一個依託"生活服務"場景、高度仿真的綜合性 Agent 評測基準。

VitaBench 的評測榜單未來將長期維護更新,歡迎持續關注:
-
🌐 項目主頁:https://vitabench.github.io
-
📃 論文鏈接:https://arxiv.org/abs/2509.26490
-
💻 代碼倉庫:https://github.com/meituan-longcat/vitabench
-
🤗 數據集:https://huggingface.co/datasets/meituan-longcat/VitaBench
-
🏆 排行榜:https://vitabench.github.io/#Leaderboard
二、理論基礎:三維複雜度框架
通過將 Agent 在環境中與 User、Tool 的交互建模為部分可觀測馬爾可夫決策過程(POMDP),VitaBench 進一步將智能體任務複雜度拆解到各個方面進行量化並提升:
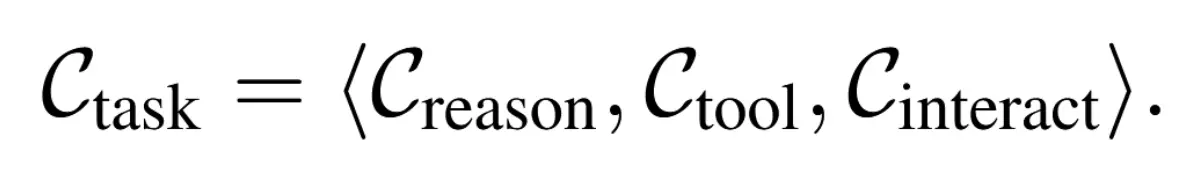
2.1 推理複雜度(𝒞_reason)
量化智能體需要在部分可觀測環境中的整合的信息量,具體通過以下指標衡量:
- 觀測空間大小:環境整體信息量,信息越多,任務越難;
- 部分可觀測度:智能體需要通過交互才能觀測到的信息佔整體信息的比例,比例越大,任務越難;
- 推理點數量:任務中需要處理的顯性與隱性推理點數量,推理點越多,任務越難。
基於此,VitaBench 構建了大規模真實環境數據庫,其中單個任務可涉及 5-20 個服務提供商、最多超過 100 個候選產品,每個任務聚合多個真實用户需求,形成複雜的搜索與推理空間。
2.2 工具複雜度(𝒞_tool)
如果將現實中的工具集建模為圖,圖中頂點代表工具,邊代表工具間的依賴關係,那麼工具複雜度可以通過以下指標衡量:
- 圖大小與密度:反映解決領域問題需要涉及的工具數量與工具間依賴緊密程度,數值越高,模型掌握工具集的難度越大;
- 工具調用鏈路長度與子圖覆蓋率:解決任務需要完成的工具調用鏈路越長,所形成的子圖佔整張圖的比例越大,任務的需求覆蓋就越廣,任務越就越難。
基於此,VitaBench 從三個場景中提煉出 66 個真實工具並構建有向圖,將領域規則編碼到圖結構中。其中工具通過 Python 函數實現,確保工具調用結果的穩定性和一致性。
2.3 交互複雜度(𝒞_interact)
反映智能體在用户的動態多輪對話中的掌控能力,通過以下機制實現:
- 用户畫像系統:基於真實平台數據脱敏構建的多樣化用户畫像,包含人口屬性、飲食偏好、消費歷史等信息;
- 行為屬性建模:涵蓋情緒表達(急躁、焦慮、冷漠等)、交互模式(細節導向、依賴型、邏輯型等)維度;
- 動態狀態演化:用户狀態、意圖可能在交互過程中持續變化,要求智能體實時調整對話策略。
基於此,VitaBench 為每個任務都配備了一個獨特的用户角色,並通過 User Simulator 扮演,逐步向 Agent 提出需求。
三、VitaBench 基準構建
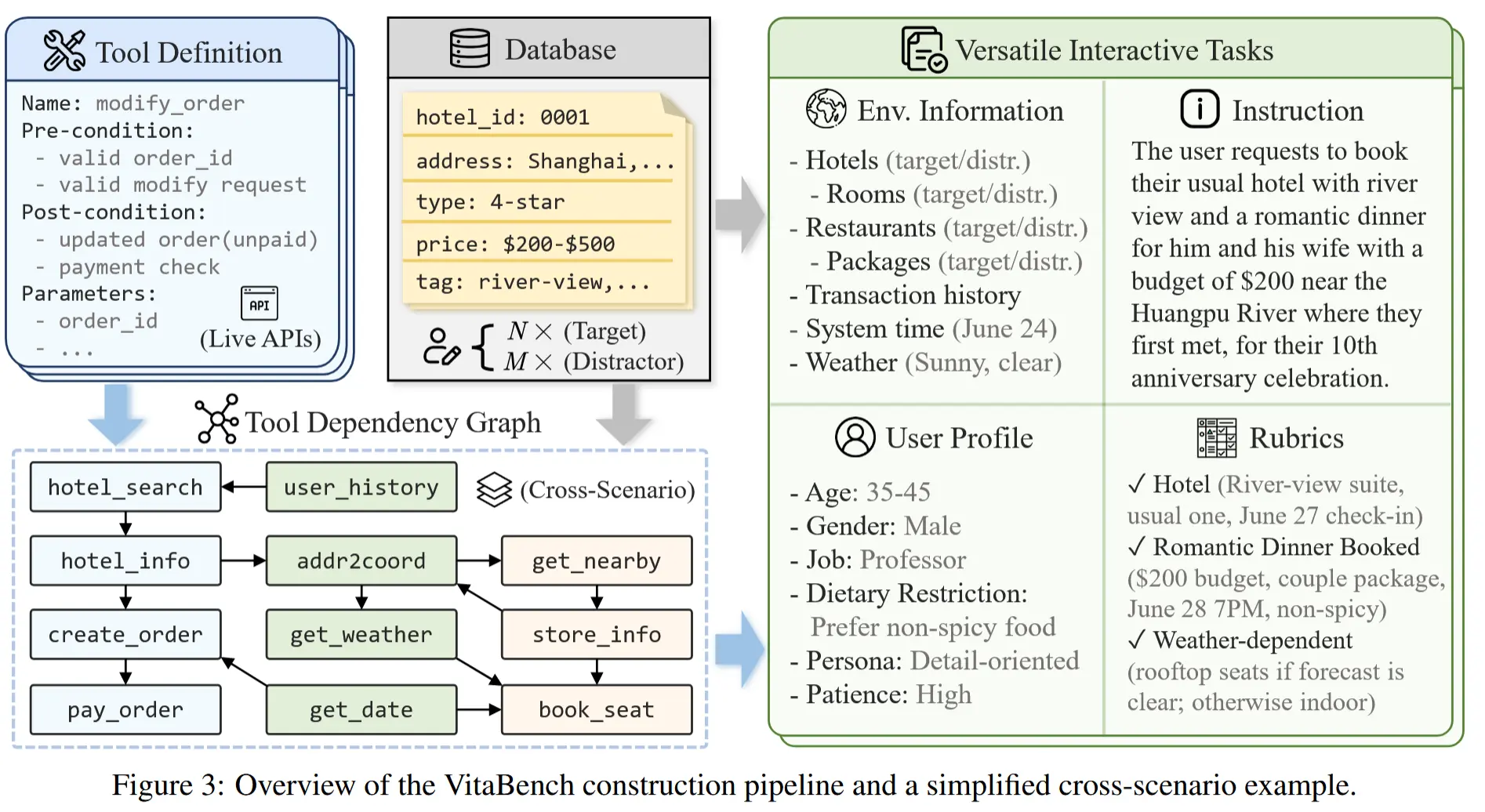
VitaBench 通過兩階段流程構建:
階段一:框架設計
- 工具定義:從三個領域中抽象核心功能,定義 66 個簡化但功能完整的 API 工具;
- 依賴構建:基於工具間的依賴關係構建有向圖,將領域規則編碼到圖結構中;
- 用户模擬:實現基於語言模型的用户模擬器,支持模糊化需求生成與個性化響應。
階段二:任務創建
- 用户畫像:基於真實平台數據合成差異化用户特徵;
- 任務指令:融合多個真實用户請求,改寫得到複合目標任務;
- 環境數據:結合真實數據合成擴展,再由人工核驗以確保任務可完成;
- 評估標準:為每個任務制定獨立且細粒度的評測標準。
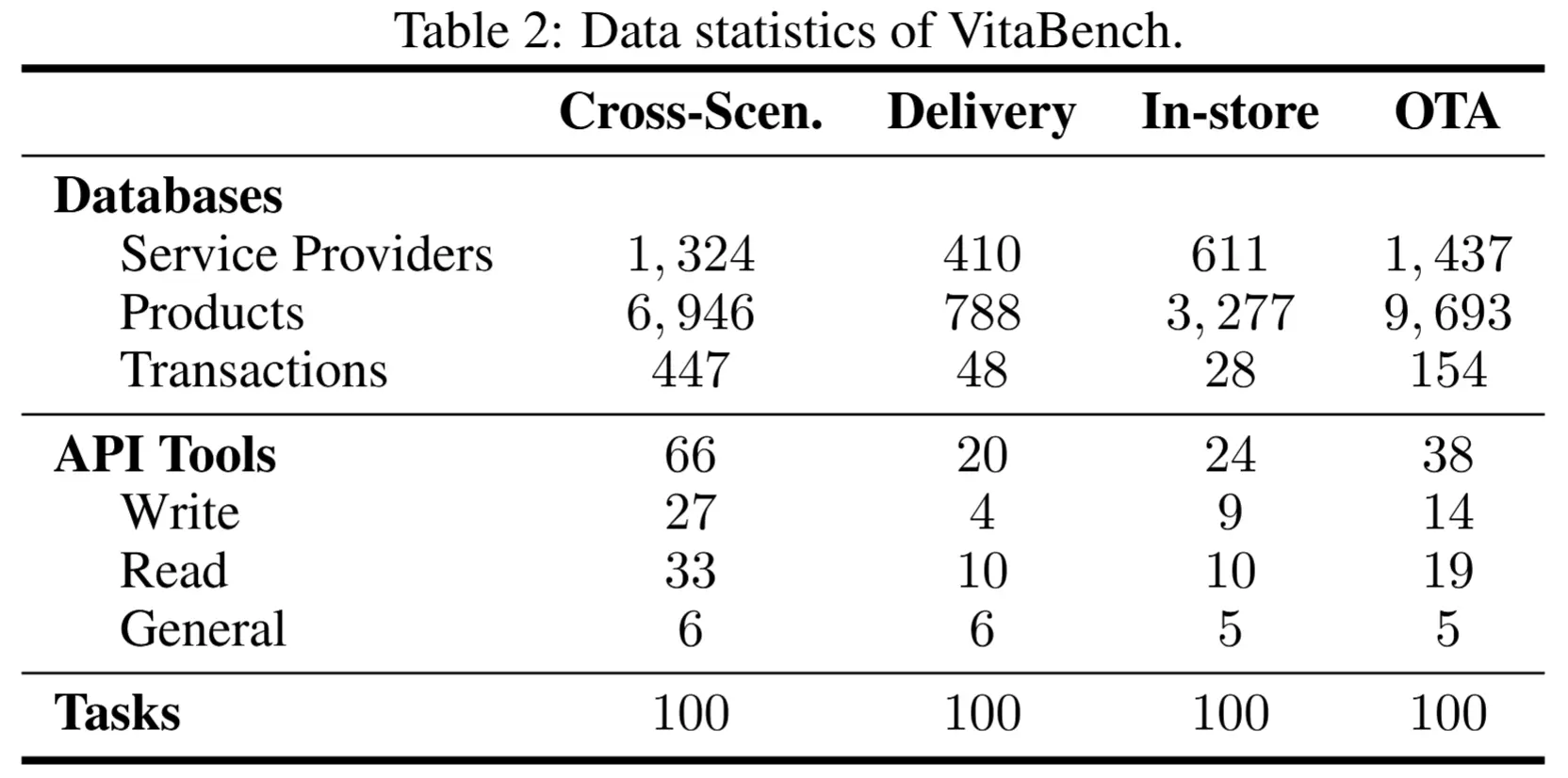
VitaBench 將各領域的規則統一編碼到工具圖結構中,避免了冗餘的領域策略文檔(Domain Policy Document)。智能體無需依賴預設規則,而是通過工具描述自行推理領域邏輯。這種設計使 VitaBench 能夠靈活支持各種場景與工具集的自由組合。團隊基於三個領域共構建了 400 項評測任務,其中包括:
- 單場景任務(300 項):聚焦於單一場景下的複雜需求;
- 跨場景任務(100 項):考察智能體在多場景間的切換執行與信息整合能力。
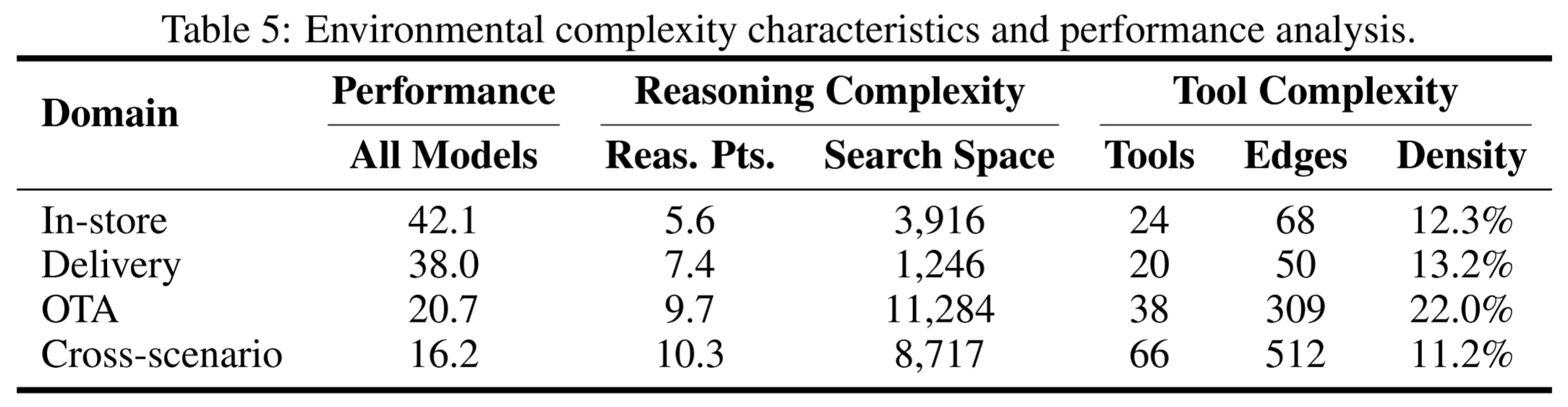
每個任務均由多名專業標註人員和領域專家進行多次校驗與複核,既確保任務具備足夠的複雜度,又保證其可以順利完成。數據統計結果如下表所示:
針對長軌跡評估的複雜性,VitaBench 團隊還提出了基於 Rubric 的滑動窗口評估器。
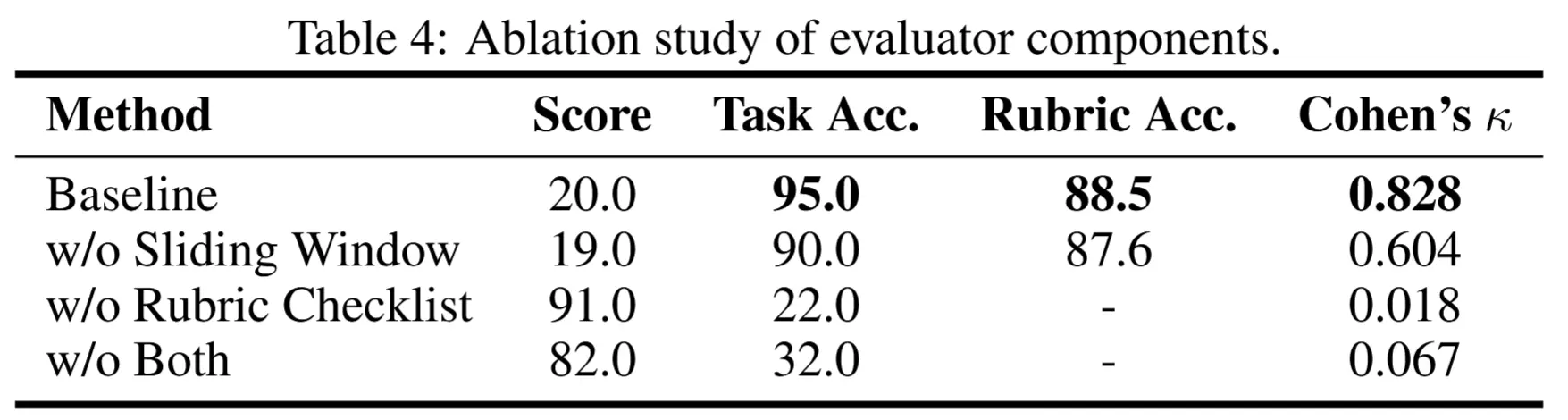
傳統的基於數據庫狀態比對的評估方法難以捕捉商品推薦、行程規劃等不改變最終狀態的行為,無法對 Agent 完成任務的過程進行有效監督。VitaBench 借鑑最新研究,將任務目標拆解為一組原子化評估準則(Rubric),實現了更全面、細粒度的行為覆蓋。
評估器通過帶重疊的滑動窗口掃描完整對話軌跡,在保持上下文連貫性的同時持續跟蹤每個 rubric 的狀態,確保跨窗口一致。最終以嚴格的「全有或全無」標準判斷任務完成與否。這種細粒度的設計不僅顯著提升了評估的可解釋性,也為未來的強化學習工作提供了更密集、更可靠的反饋信號。
四、實驗結果與分析
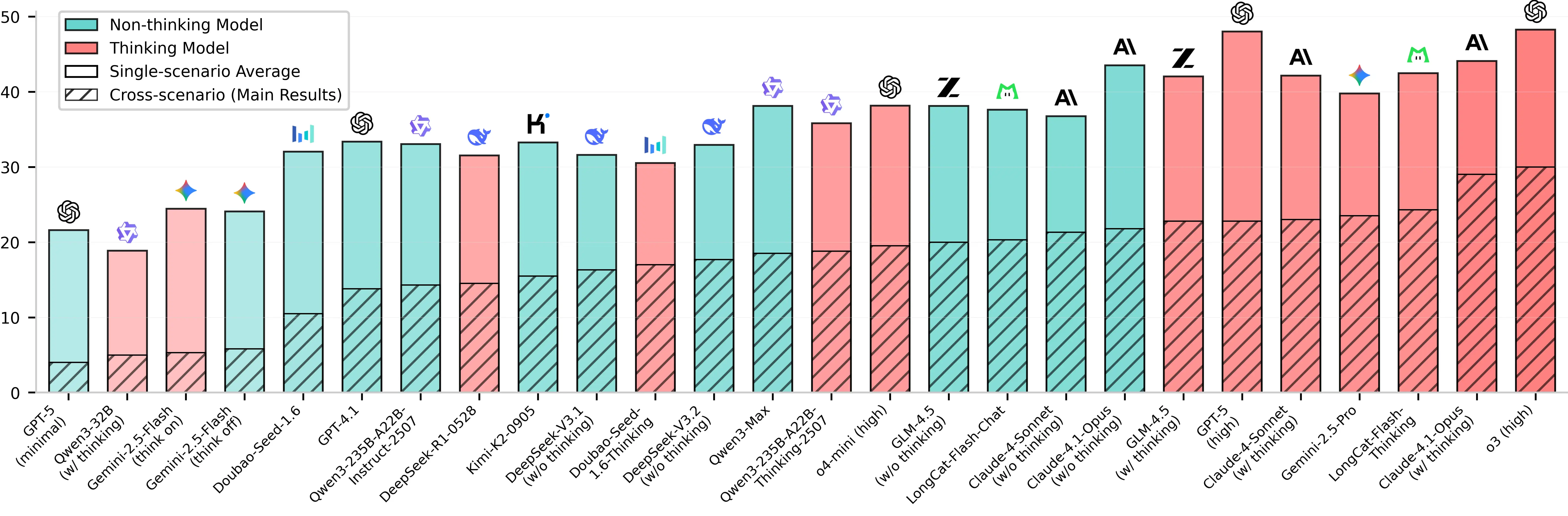
團隊在 VitaBench 上評測了包括 GPT-5、Claude-4.1-Opus、Gemini-2.5-Pro、Kimi-K2、GLM-4.5、LongCat-Flash 等在內的 20 餘款主流大模型。
實驗設置:
- 實現基於 Function Call 的智能體架構,所有模型使用官方工具調用格式;
- 用户模擬器基於 GPT-4.1 實現,評估器基於 Claude-3.7-Sonnet 實現;
- 每個任務運行 4 次,温度均設置為 0.0 以促進穩定輸出,計算 Avg@4、Pass@4、Pass^4 指標;
- 排行榜分為推理和非推理模型兩類,對於支持在兩種模式之間切換的混合思考模型,我們在兩類中分別評估其開啓思考和關閉思考的配置。
4.1 主實驗結果
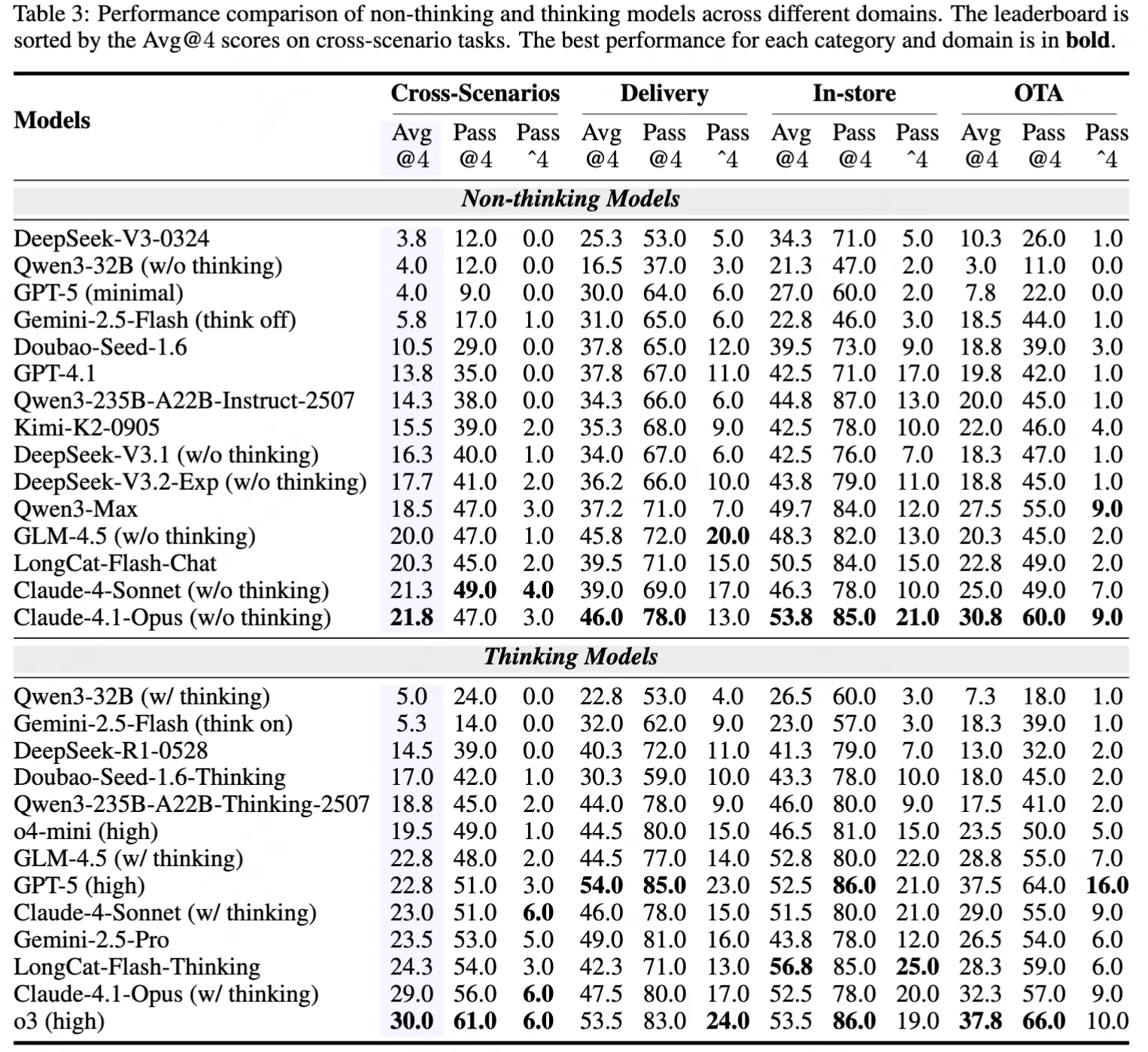
主要結論如下:
- 跨場景任務帶來極大挑戰:即使是測試中表現最佳的 o3(high)模型,跨場景 Avg@4 成功率也僅為 30.0%,遠低於單場景任務的 48.3%,表明當前模型在跨域工具協調與意圖整合方面存在根本性短板。
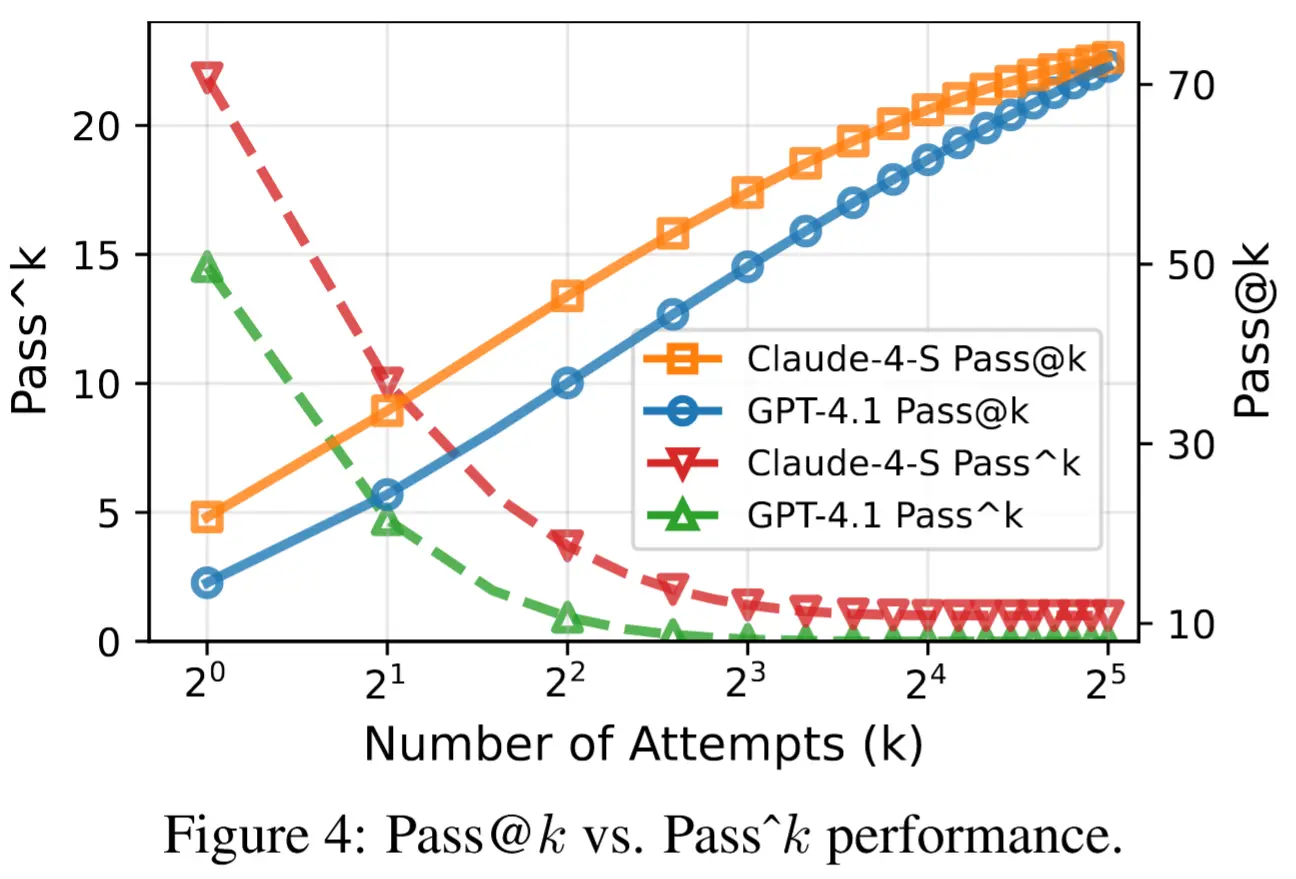
- 多次嘗試(探索)可以提升性能,但同樣穩定性堪憂:儘管 Pass@4(至少一次成功)可達 60%,但 Pass^4(四次全成功)接近 0%,説明模型行為高度不穩定,難以滿足生產環境可靠性要求。
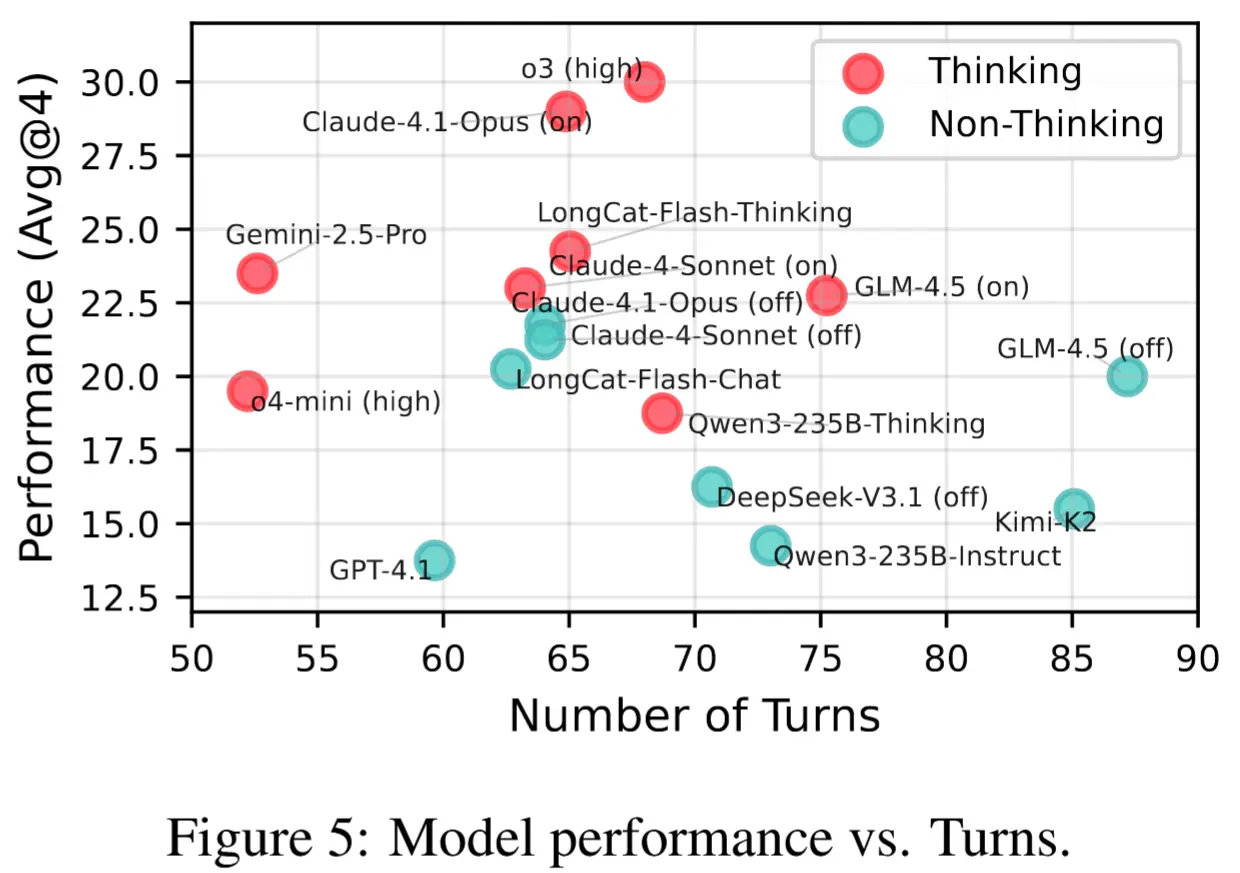
- "思考型"模型顯著優於"非思考型":啓用鏈式推理(thinking)的模型普遍提升 5--8 個百分點,且交互輪次更少,説明深度規劃對複雜任務至關重要。
4.2 複雜性消融實驗
團隊進一步通過消融實驗,驗證了 VitaBench 所提出的三大複雜性維度的有效性:
- 推理複雜性:任務所需推理點數量與成功率呈強負相關。在線旅行與跨場景任務平均包含 9.7--10.3 個推理點,搜索空間相比其他兩個領域高出一個量級,成功率也更低。
- 工具複雜性:工具圖的節點與邊數量越多,任務越難。跨場景任務涉及 66 個工具、512 條依賴邊,是所有任務中最複雜的,成功率也最低。
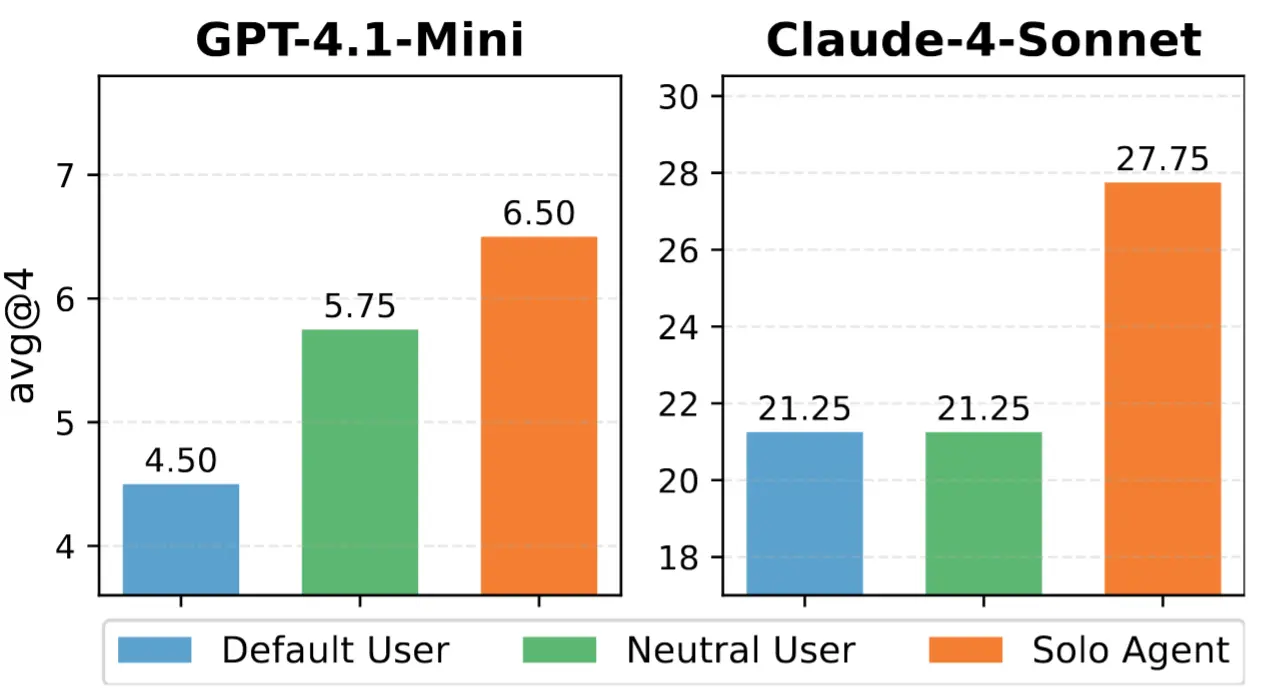
- 交互複雜性:在「直接告訴 Agent 完整指令(無用户交互)」條件下,模型成功率顯著提升;而引入真實用户模擬器(包含完整人物特徵和行為屬性)後,性能下降 15--25 個百分點,尤其對弱模型影響更大。
4.3 用户模擬器與評估器可靠性驗證
為確保評測結果可信,團隊對兩個核心組件進行了嚴格驗證:
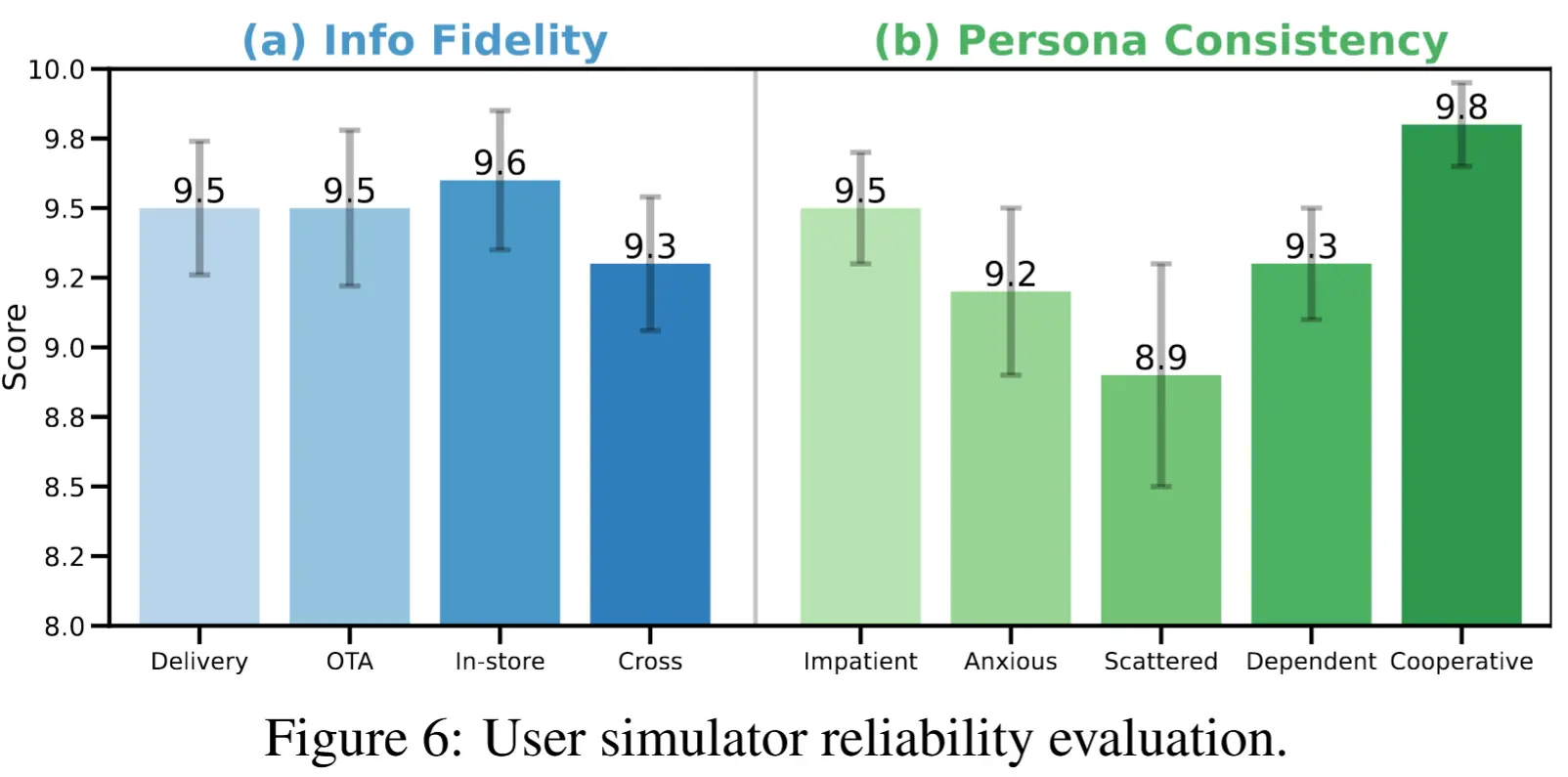
- 用户模擬器:在信息保真度(9.48/10)與人格一致性(9.34/10)兩項指標上均表現優異,能準確模擬不同用户行為和偏好,且不違背任務要求。
- 滑動窗口評估器:與人工標註相比,Cohen's κ 達 0.828,顯著優於無 Rubric 或無滑動窗口的基線方法。
4.4 典型失敗案例分析
在對模型錯誤案例的系統分析中,團隊歸納出三大錯誤類別:推理相關錯誤(61.8%)、工具相關錯誤(21.1%)、交互相關錯誤(7.9%)。
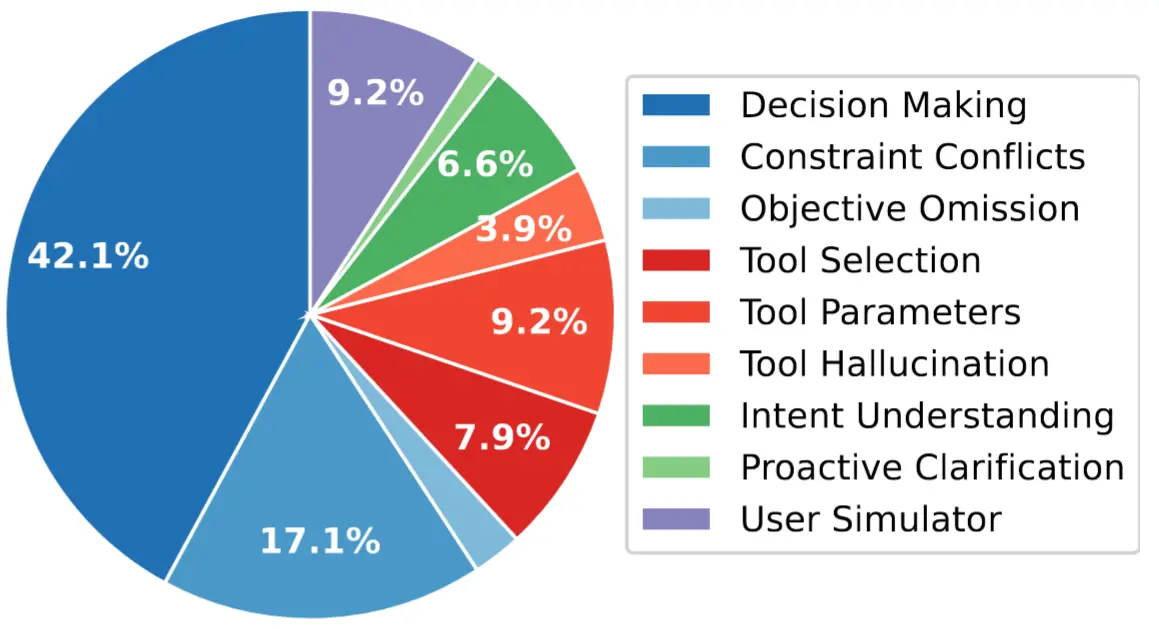
分析發現,當前模型普遍存在以下具有代表性的失誤模式:
- 模型在涉及時空推理與常識推理的任務中常常忽略細節,反映出其在多維信息整合上的侷限。
- 即便具備正確的工具與條件,模型仍常因對自身能力、工具能力的不確定而提前放棄任務。
- 當工具調用失敗或用户需求模糊時,模型往往重複無效操作,而非主動調整策略進行修復。
這些問題表明,當前通用型智能體在推理、策略調度與自我反思等方面仍存在顯著提升空間,為後續研究提供了明確方向。
五、總結與展望
VitaBench 不僅是一個評測基準,更是一套關於「Agentic Task Complexity」的理論框架。它首次系統量化了推理、工具與交互三大維度對智能體性能的影響,並揭示了當前模型在真實生活場景中的能力邊界。
我們的目標不僅僅是測量現有模型的智能,更是開啓「AI 下半場」,實現通往實用智能體的最後一公里。正如其名 "Vita"(拉丁語 "生命,生活")所寓意的:智能的終極考場,不在實驗室,而在生活本身。
VitaBench 現已全面開源,歡迎訪問項目官網 https://vitabench.github.io 獲取最新信息。
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明"內容轉載自美團技術團隊"。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。