美團LongCat團隊推出了UNO-Bench,用於評估多模態大語言模型統一能力的基準測試。
該基準旨在系統性地評估模型的單模態與全模態理解能力,涵蓋了44種任務類型和5種模態組合,並通過實驗揭示了全模態與單模態性能之間的組合定律。
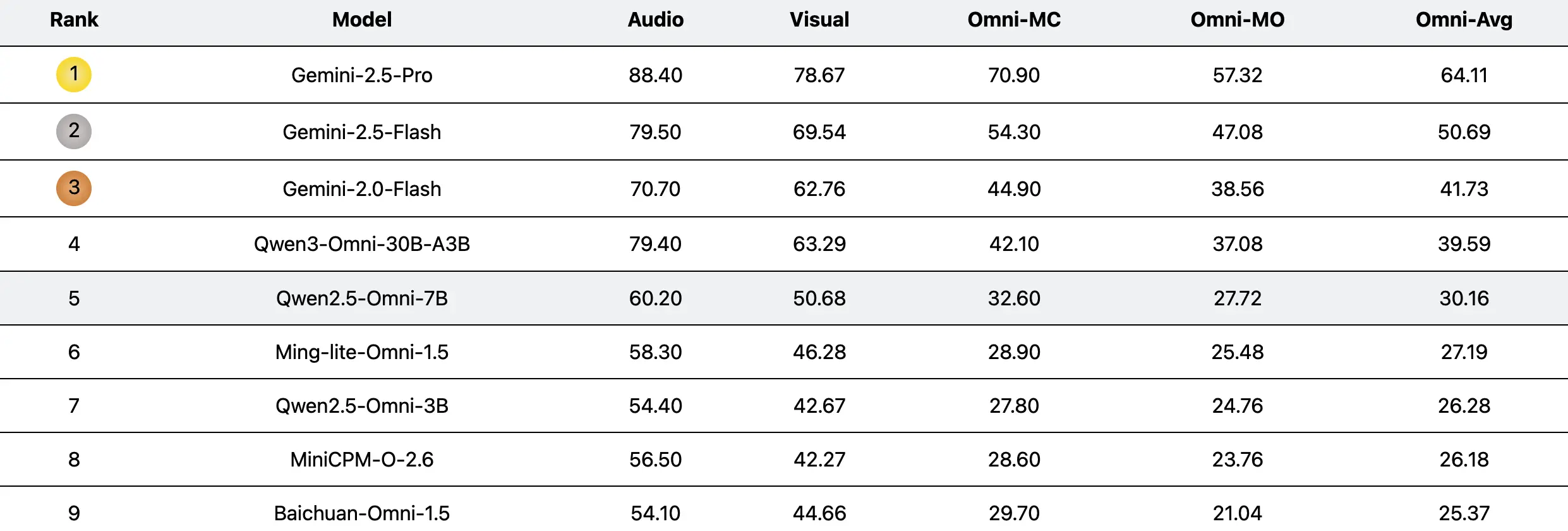
據介紹,UNO-Bench包含1250個人工精選的全模態樣本(跨模態可解性達98%)和2480個增強的單模態樣本。人工生成的數據集非常適合真實場景,尤其適用於中文語境;而自動壓縮的數據集則提高了90%的運行速度,並在18個公開基準測試中保持了98%的一致性。除了傳統的多項選擇題外,團隊提出了一種創新的多步驟開放式問題形式來評估複雜的推理能力。該形式整合了一個通用的評分模型,支持6種題型的自動評估,準確率達到95%。
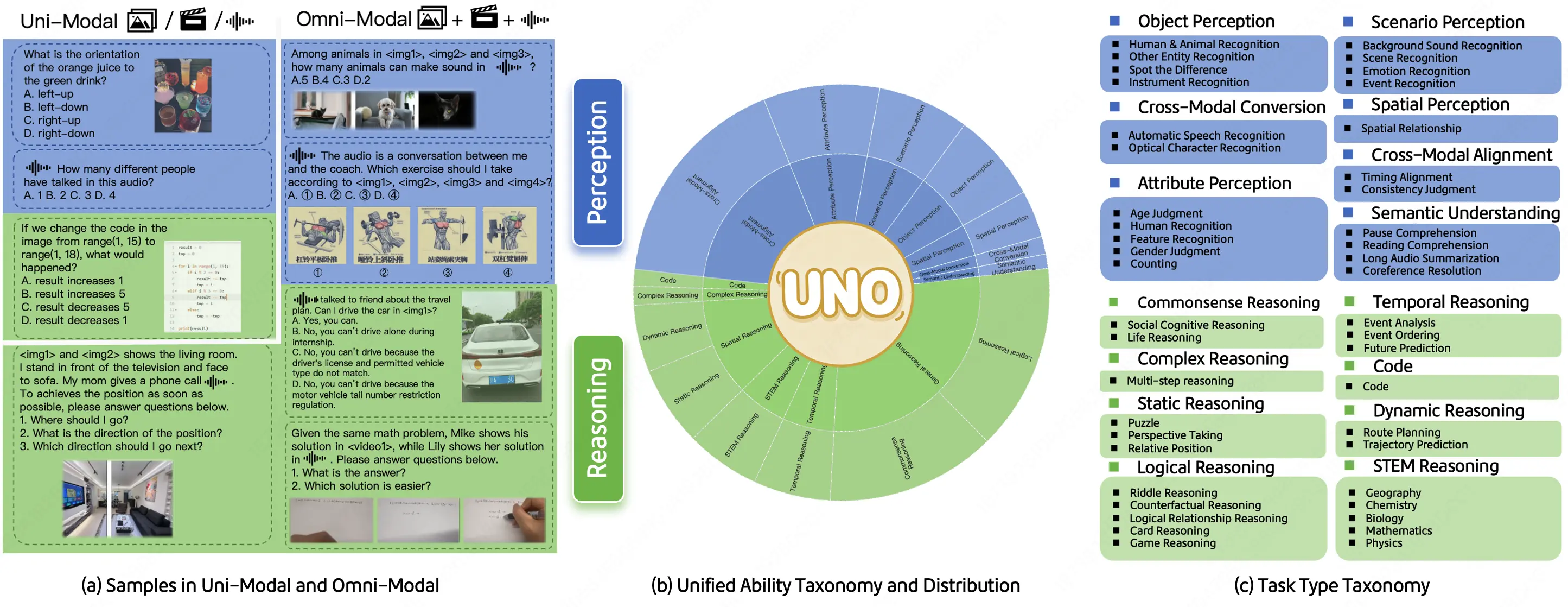
UNO-Bench目前專注於中文場景,並正在積極尋求合作伙伴共同構建英語及多語言版本。UNO-Bench數據集可在Hugging Face上下載,相關代碼、論文和項目頁面也已公開。
https://meituan-longcat.github.io/UNO-Bench/
https://github.com/meituan-longcat/UNO-Bench
https://huggingface.co/datasets/meituan-longcat/UNO-Bench