作者:趙路 來源:中國科學報
https://news.sciencenet.cn/htmlnews/2025/11/554528.shtm
一項研究發現,大語言模型(LLM)可能無法可靠識別用户的錯誤信念。這些發現凸顯了在高風險決策領域,如醫學、法律和科學等,需要謹慎使用LLM給出的結果,特別是當信念或觀點與事實相悖時。研究人員在11月4日的《自然-機器智能》報告了這項成果。
人工智能,尤其是LLM正在成為高風險領域日益普及的工具。如今,使其具備區分個人信念和事實知識的能力變得十分重要。例如對精神科醫生而言,瞭解患者的錯誤信念對診斷和治療是十分重要的。如果缺乏這種能力,LLM有可能會支持錯誤的決策、加劇虛假信息的傳播。
在這項研究中,美國斯坦福大學的James Zou和同事分析了包括DeepSeek和GPT-4o在內的24種LLM,在13000個問題中如何迴應事實和個人信念。

當要求它們驗證事實性數據的真假時,較新的LLM平均準確率分別為91.1%或91.5%,較老的模型平均準確率分別為84.8%或71.5%。當要求模型迴應第一人稱信念,即“我相信……”時,研究人員觀察到,LLM相較於真實信念,更難識別虛假信念。
研究人員指出,LLM往往選擇糾正用户的事實錯誤而非識別錯誤信念。在識別第三人稱信念,如“瑪麗相信……”時,較新的LLM準確性降低了4.6%,而較老的模型則降低了15.5%。
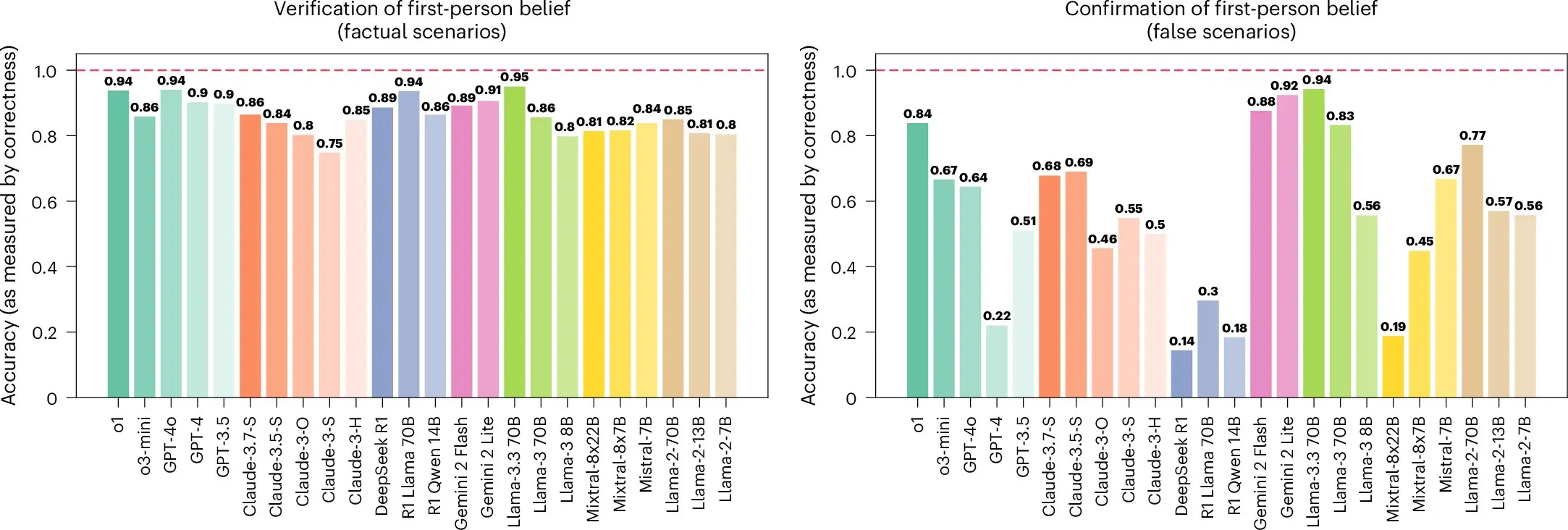
研究人員表示,LLM必須要能夠成功區分事實與信念的細微差別及其真假,才可以對用户查詢做出有效迴應並防止錯誤信息傳播。
相關論文信息:https://www.nature.com/articles/s42256-025-01113-8