銀河通用聯合北京大學、阿德萊德大學、浙江大學等團隊,推出了全球首個跨本體全域環視的導航基座大模型——NavFoM(Navigation Foundation Model)。把Vision-and-Language Navigation、Object-goal Navigation、Visual Tracking 和Autonomous Driving 等不同機器人的導航任務統一到相同的範式。
- 全場景:同時支持室內和室外場景,未見過的場景 Zero-Shot 運行,無需建圖和額外採集訓練數據;
- 多任務:支持自然語言指令驅動的目標跟隨和自主導航等不同細分導航任務;
- 跨本體:可快速低成本適配機器狗、輪式人形、腿式人形、無人機、甚至汽車等不同尺寸的異構本體。
除此之外,該模型允許開發人員以之為基座,通過後訓練,進一步進化成滿足特定導航要求的應用模型。
根據介紹,NavFoM 建立了一個全新的通用範式:“視頻流 + 文本指令 → 動作軌跡”。無論是“跟着那個人走”,還是“找到門口的紅車”,在 NavFoM 裏都是同一種輸入輸出形式。模型不再依賴模塊化拼接,而是端到端地完成“看到—理解—行動”的全過程。

這意味着,曾經割裂的任務經過統一的數據對齊和任務建模可以互相遷移;不同形態的機器人能共享學習經驗和運動知識。
NavFoM 有兩項關鍵技術創新:第一,TVI Tokens(Temporal-Viewpoint-Indexed Tokens)——讓模型理解時間與方向。第二,BATS 策略(Budget-Aware Token Sampling)——讓模型在算力受限下依然聰明。
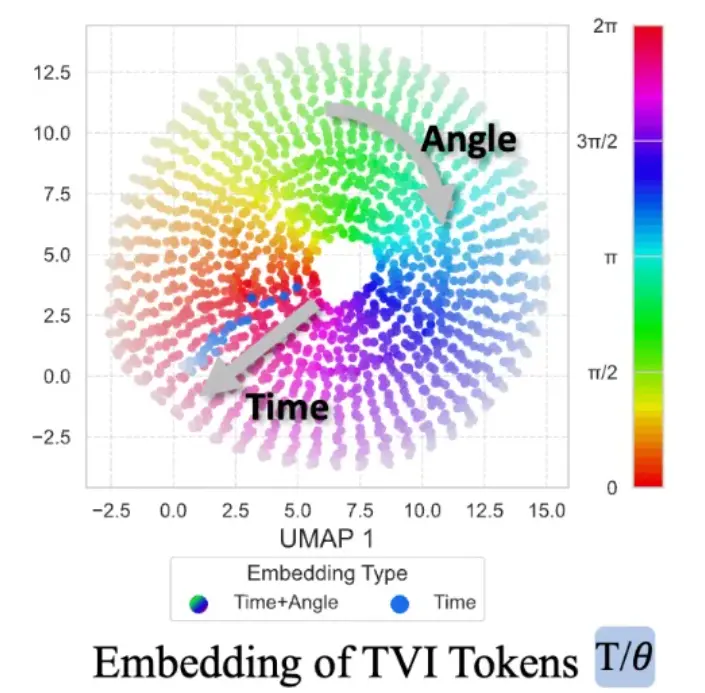
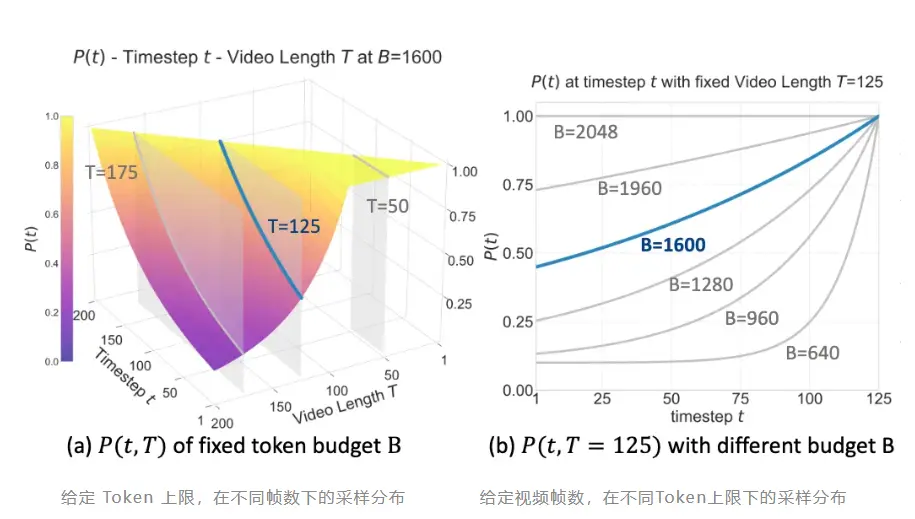
此外,銀河通用構建了的跨任務數據集包含八百萬條跨任務、跨本體導航數據,覆蓋視覺語言導航,目標導航,目標跟蹤,自動駕駛,網絡導航數據等多種任務;以及四百萬條開放問答數據,讓模型具備語言與空間之間的語義理解能力,這一訓練量約為以往工作的兩倍左右。