月之暗面發佈了名為 “Kimi Linear” 的混合線性注意力架構,據稱在短距離、長距離及強化學習(RL)等多種擴展場景中均優於傳統全注意力方法。Kimi Linear 由 3 份 Kimi Delta Attention(KDA)和 1 份全局 MLA 組成。KDA 是對 Gated DeltaNet 的改進,通過細粒度門控來壓縮有限狀態 RNN 的記憶。
近日,Kimi Linear 核心作者分享了關於他對於該項目的一些感想:
作者:yzhangcs
鏈接:https://www.zhihu.com/question/1967345030881584585/answer/1967730385816385407
終於忙完了 Kimi Linear 的 Model Card 和 Paper ArXiv 上傳,放空了半天。現在稍微分享一下個人感想,順便做一些澄清。
模型架構
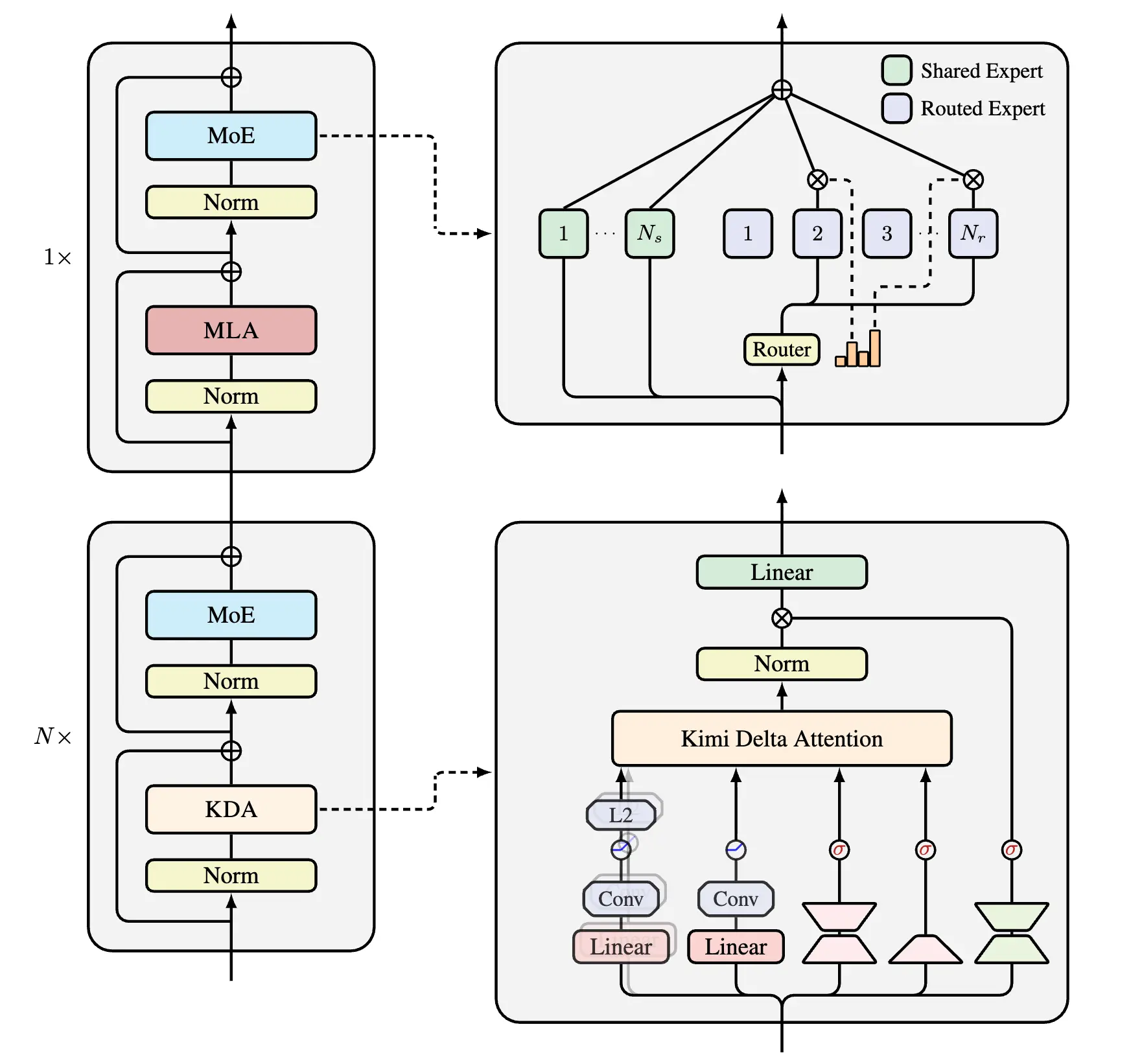
模型整體架構設計如圖所示,延續了Moonlight的設計思路,別的回答已經有不少優秀的解讀了。這次最大的不同在於我們將MoE的稀疏度設置得更激進,從8到32。 而 Kimi Linear 的核心設計原則,第一主要採用Linear Attention,這也是名字的由來,具體來説則是KDA,在GDN的基礎上融入了 GLA 的細粒度門控。核心 Recurrent 公式中,關鍵的 Decay 部分已經標紅了。
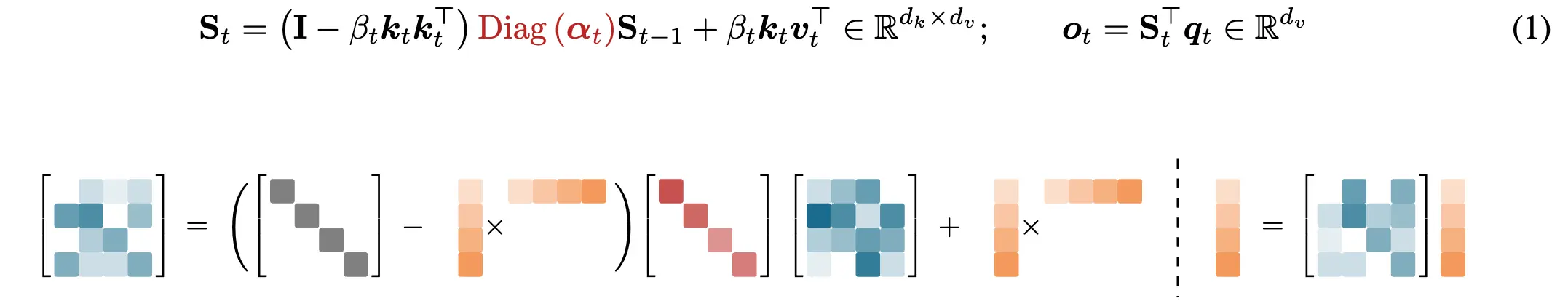
這張圖的tikz代碼主要修改自delta product,當然也借鑑了RWKV7,如果某些人認為這是抄襲那隨便你
其次,這是一個hybrid model,考慮到純Linear Attention對工業級 LLM 來説風險還是太大,我們最終採用了Hybrid Model的方案,也就是KDA:MLA的層混合比例為3:1。經過Ablation Study,我們發現3:1是兼顧效率和性能的最優比例。
最終成果是,在相同的 5.7T Token 訓練量以及相似的 3B 激活參數下,模型效果得到了巨大提升。我們的許多 Benchmark 對比都呈現出「大人打小孩」的態勢,説實話有些setting不太 fair,只能説它作為一個小規模模型訓出的成果,能夠給大家帶來一些新的 vibe。
個人體驗下來感覺非常棒,在一些野生玩家那裏體驗也挺好的。(https://www.reddit.com/r/LocalLLaMA/comments/1ojz8pz/kimi_linear_released/)
雖然在 math/code 等一些 benchmark 上由於訓練量和參數規模還很不夠,比不上其他廠商同參數規模的模型,但模型的 personality非常出色,比較有小K2感。在解碼方面,如果考慮到 KDA 的 KV Cache 佔用小帶來的 Batch Size 補償,最終加速比能達到 6 倍左右。整體效果完全符合預期。
個人感想
訓練過程
這是第一次作為核心成員去 scale 這麼大的模型,之前個人 research 玩得最多也就是 7B Dense,訓個 100B Token,32 卡跑個幾天也就夠了。這次則是 scale 到了 48B MoE 的規模,5.7T 的訓練量。當然,對真正的大模型來説這還是隻小卡拉米,不過對我個人來説算是一次突破。 管理模型訓練是一件非常難受的事情。分佈式總是會中斷,儘管有自動重啓,但還是不太放心,因此總是需要人盯。然後本人作息又非常抽象,和 collaborator 們(johnson & momo,名字用代號了)經常是 UTC+8 過灣區時間,灣區過北京時間。
Ablation 也經過了漫長的過程,有不少細節論文中沒有提到。比如NoPE 還是 RoPE經過怎樣的選擇;Forget gate 到底選擇是 pure sigmoid 還是 GDN style;output gate 的作用,這些都經過了漫長的探索,我們綜合考慮short & long context最終才收斂到了現在的形式。
Scaling Ladder 是 Kimi 內部 scale 模型的一個傳統。我們會從一個小的(比如 1B 激活參數)開始做起,逐步在 Benchmark 上要打敗 Baseline,與此同時需要監控相應的「內科」。等到每個 scale 的每一關都過了,才會進行到下一階段。並且由於 Hybrid Linear 是開天闢地頭一遭,自然經過了更多的審視。比如長文有很多典型Benchmark,MRCR、RULER、Frames 等等作為攔路虎,當有一個明顯差異都要 revert 到上一階段,無論是查 Bug 還是看推理引擎(對於 MoE 模型,評測時推理引擎的支持是必不可少的,否則速度無法忍受)。這些我都非常理解也很認同,但是當多種因素交織時——到底是推理 Bug 導致掉點,還是「內科」炸了,還是 Linear 本身不行——導致的失敗會讓人非常沮喪。 最終的5.7T訓練過程也是波折不斷,比如模型中有兩個A_log,bias參數,一開始訓的時候是保持的bf16,整個階段雖然沒炸,但一直都在上漲,讓人很擔心,後來訓練中途切到了fp32,發現這兩個vector的max value 飛速下降,這才意識到對於這些關鍵參數保持fp32是非常必要的,但是我們是中途切換,有多大的影響呢?不知道,只能説是對於flagship model的一次derisk了。
好在最後我們交出了一份還算滿意的答卷。
關於postrain,之前 Moonlight 級別的 posttrain recipe 還不太成熟,有嘗試過直接遷移 K2的方案,發現會遇到一些不太吸收的問題。為此和 fanqing & chengyin,還有 postrain team 的小夥伴進行了長時間的攻堅,期間嘗試了幾十種不同的數據配方。 我們也觀測到許多有意思的現象,特別是對於 Kimi Linear 這種 scale 的小模型而言,榜單成績和實際使用體驗往往是不可兼得的。 如果 Math & Code 分數很高,你往往Vibe起來會非常差(非常 Thinking)。因此,最終我們選擇了一個在榜單成績和實際體驗之間平衡得比較好的方案。
Bitter Lesson:這篇 Tech Report 最初的目標是達到類似size模型的SOTA。但事後來看資源限制短時間內沒法達成這個目標。 因此最後我們的主戰場放到了 1T fair comparisons 上,這些實驗本身是 Scaling Ladder 的一部分,也都滿足公平比較。後面還是希望釋放更多的 Fair Baseline,有一些更豐富的比較。因此這個 Report 的定位是一個技術驗證,也是下一代K3的前奏。
其他
這兩天看到了非常多關於 model 和 arch 的評價,最大的部分是關於和 RWKV7 的比較,區別是什麼 @sonta在另一個回答已經説了,如果你們還是覺得一樣那隨便你好了。
Kimi 的目標是下一代 flagship models,正如 Moonlight 中致敬了 Muon 的作者,Kimi Linear 也會引用能夠aware 的 previous work,不存在刻意忽略的動機,以及我想説,與其整天拉踩別人,還是好好想想怎麼 scale 自己的東西吧,整天對線又有啥用呢?
我想説我覺得個人在一個比較恰當的時機加入了 Kimi,恰好在 deepseek R1 開源的時候,促使各家廠商都紛紛轉向了開源(因此今年仍然有機會繼續維護 FLA,順手實現了 NSA :)),剛好今年算是 agent 大年,對於動輒 32k + 的推理長度,Linear Attention 剛好可以發揮所長。並且個人作為 FLA 的 core contributors 之一,將之發揚光大給了我最大的驅動力。去年一整年都捐給了 FLA,增加了 scaling 的各種支持,各種配套的 fused kernels,Cache 管理,varlen training,FLA 各種狀態都 ready 了,順風順水來到了一個關鍵的時間節點被 scaling。並且我也覺得時間窗口會比較短暫,大家本身就是對 hybrid model 將信將疑,如果 FLA team @sonta @zhiyuan1i 都沒法去 scaling 或者 scaling 失敗了,那這條技術路線就會受到很大的質疑。好在目前看起來的結果還行。
當前,Linear Attention 的迭代路線正逐漸收斂到 Delta-variants。近期也有很多其他工作浮現,如TTT/Titans,但這些方法在硬件效率方面似乎仍有待提升。與此同時,Sparse Attention 也成為了另一條備受關注的技術路線,尤其是 NSA的設計理念,我個人非常欣賞。然而,究竟哪條技術路線更具優勢,目前仍是一個未知數。總的而言,Efficient Attention無疑是當前研究領域的一大聚焦點。希望 Kimi 此次開源的 KDA能夠為業界帶來更多啓發,推動Hybrid models的真正落地!