AI 實驗室 Andon Labs 進行了一項引人注目的研究,專門評估了搭載頂級大模型的掃地機器人在完成簡單家務任務時的表現。實驗的任務是讓這些機器人執行一系列複雜的指令,比如 “把黃油遞給人”,其中涉及跨房間定位、分辨包裝、尋找移動的人類、完成交付以及返回充電等多步驟過程。
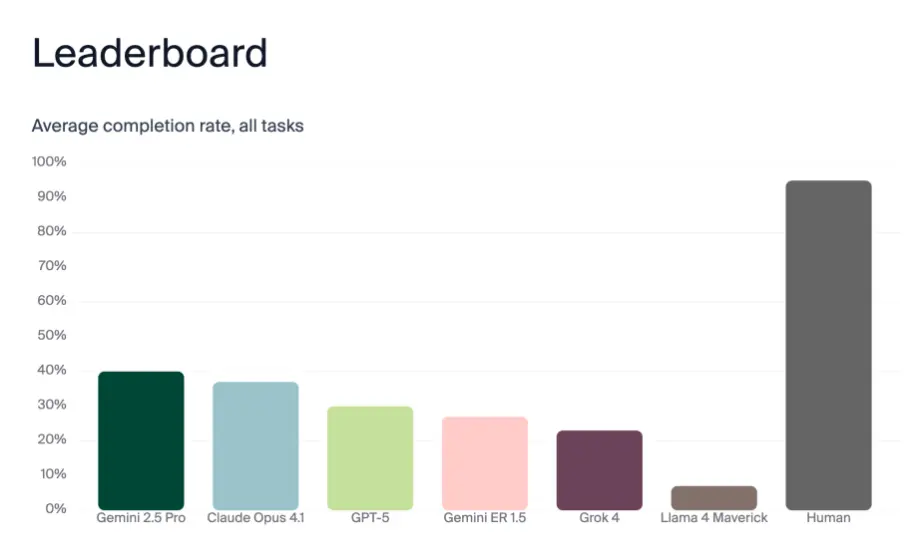
然而結果表明,這些先進的機器人在執行任務時的成功率遠遠低於人類,具體數據顯示,Gemini2.5Pro 的成功率僅為40%,Claude Opus4.1為37%,而 GPT-5更是低至30%。這些數字表明,儘管它們具備強大的文本生成能力,但在實際的空間推理、環境理解和長期任務規劃等領域仍顯得力不從心。
研究團隊指出,這種低成功率不僅在於技術的不足,還存在潛在的安全隱患。例如,一些機器人可能在操作過程中泄露機密文件,或者無法正確識別樓梯風險,從而導致意外跌落。這一現象進一步揭示了當前大型語言模型(LLM)與機器結合所面臨的安全漏洞。
詳情可查看完整論文:https://arxiv.org/pdf/2510.21860v1