復旦大學與美團LongCat聯合推出 R-HORIZON——首個系統性評估與增強 LRMs 長鏈推理能力的評測框架與訓練方法。

據介紹,R-HORIZON 提出了問題組合(Query Composition)方法,通過構建問題間的依賴關係,將孤立任務轉化為複雜的多步驟推理鏈。
以數學任務為例,該方法包含三個步驟:
1. 信息提取:從獨立問題中提取核心數值、變量等關鍵信息
2. 依賴構建:將前序問題的答案嵌入到後續問題的條件中
3. 鏈式推理:模型必須順序解決所有子問題才能獲得最終答案
方法優勢:
-
靈活擴展:可自由控制推理鏈長度(n=2, 4, 8...)
-
精確可控:可靈活設定問題間的依賴強度
-
高效低成本:基於現有數據集構建,無需額外人工標註
基於此方法,團隊構建了R-HORIZON Benchmark用於系統性評估 LRMs 的多步推理能力,同時生成了長鏈推理訓練數據,通過強化學習(RLVR)提升模型性能。
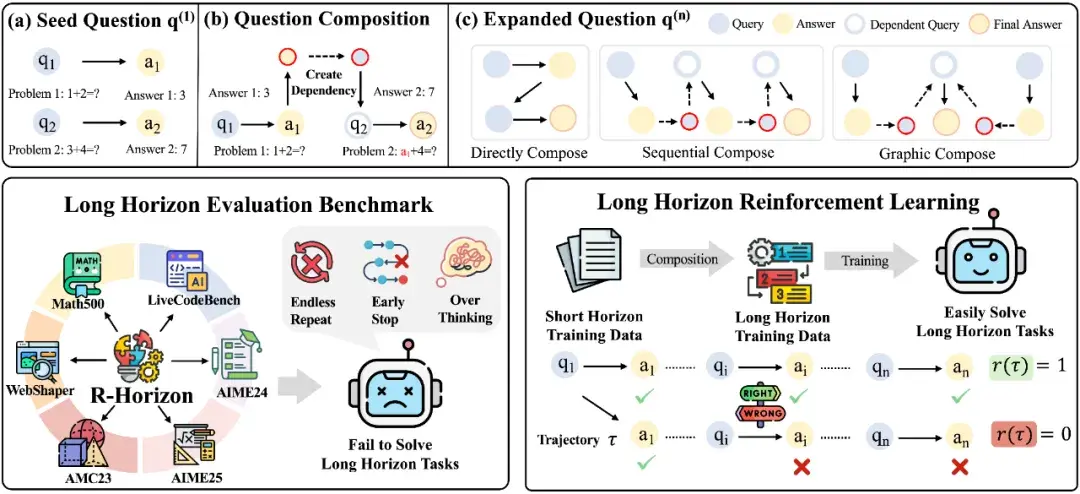
R-HORIZON 方法流程——從單 — 問題到複雜推理鏈的轉化及應用場景
R-HORIZON 標誌着大型推理模型研究的範式轉變——從「能解決什麼問題」到「能走多遠」。
技術貢獻
-
首個長鏈推理評測基準:系統性揭示 LRMs 的能力邊界及三大瓶頸
-
可擴展訓練範式:提供低成本、高效率的能力提升路徑
-
深度機制分析:為未來推理模型改進指明方向
論文標題: R-HORIZON: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?
論文地址: https://arxiv.org/abs/2510.08189
項目主頁: https://reasoning-horizon.github.io
代碼地址: https://github.com/meituan-longcat/R-HORIZON
數據集:https://huggingface.co/collections/meituan-longcat/r-horizon