一、背景介紹
為什麼得物需要自建大數據研發與管理平台?
得物作為一家數據驅動型互聯網企業,數據使用的效率、質量、成本,極大影響了公司的商業競爭力。而數據鏈路上最關鍵的系統是計算存儲引擎和數據研發平台。其中計算存儲引擎決定了數據的使用成本,數據研發平台則決定了數據的交付效率、數據質量以及數據架構合理性。
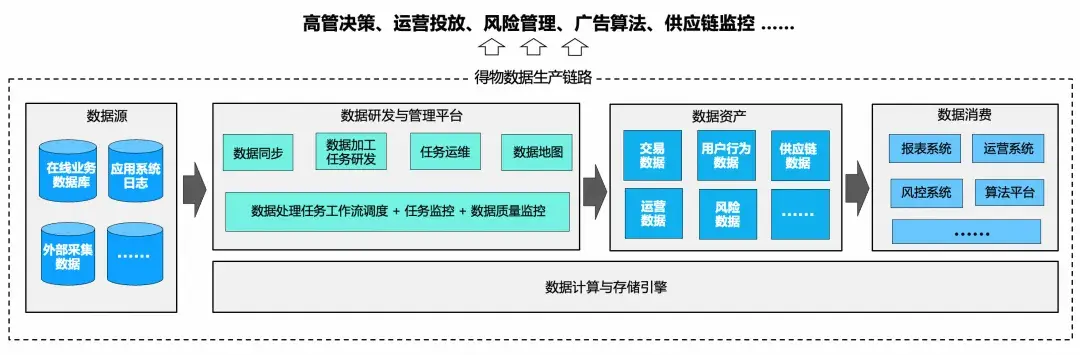
得物數據生產鏈路
過去整套大數據基礎設施我們都使用雲上商業化產品(下文簡稱“雲平台”),但在各方面已遠無法匹配上得物長期的業務發展。目前得物大數據面臨着如下挑戰:
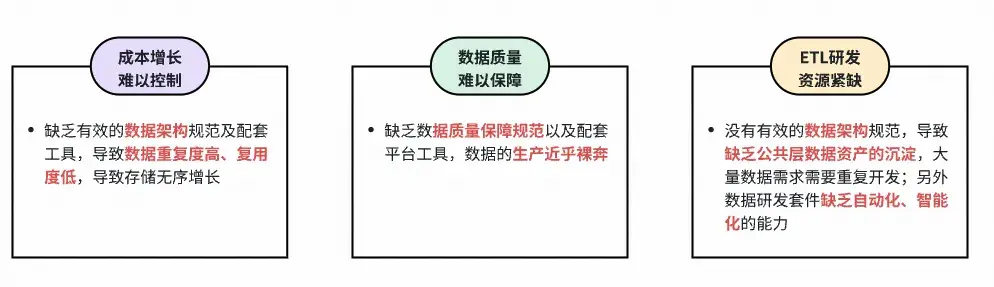
因此24年技術部正式啓動大數據系統自建,Galaxy數據研發與管理平台為其中一個重要項目,負責面向參與數據生產的用户,提供離線和實時數據的採集同步、研發運維、加工生產、數據資產管理以及安全合規的能力,滿足業務長期發展對於數據架構、數據質量、數據交付效率的訴求。
二、產品功能架構
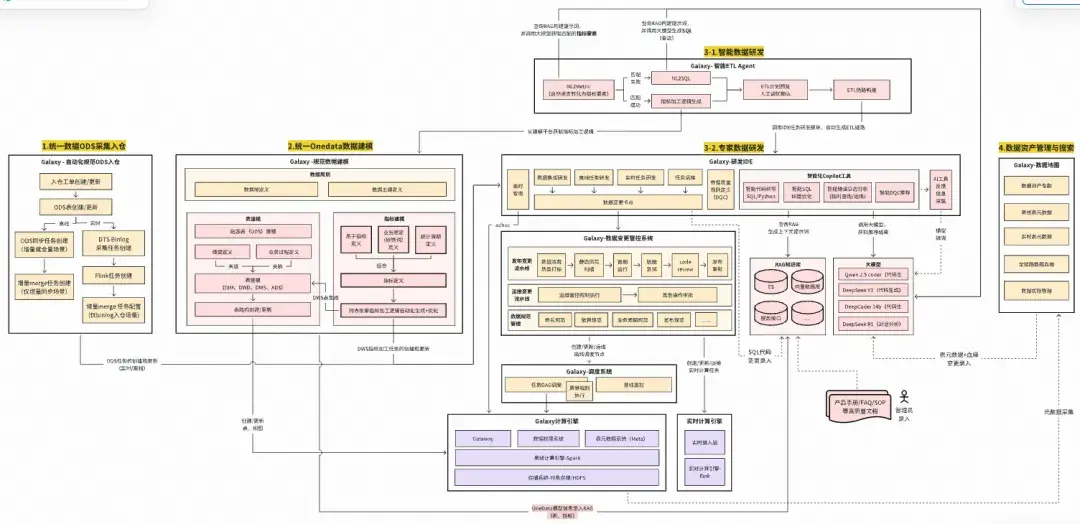
下圖為整體產品功能架構,其中藍色部分為當前已落地功能,灰色部分為規劃中的功能。
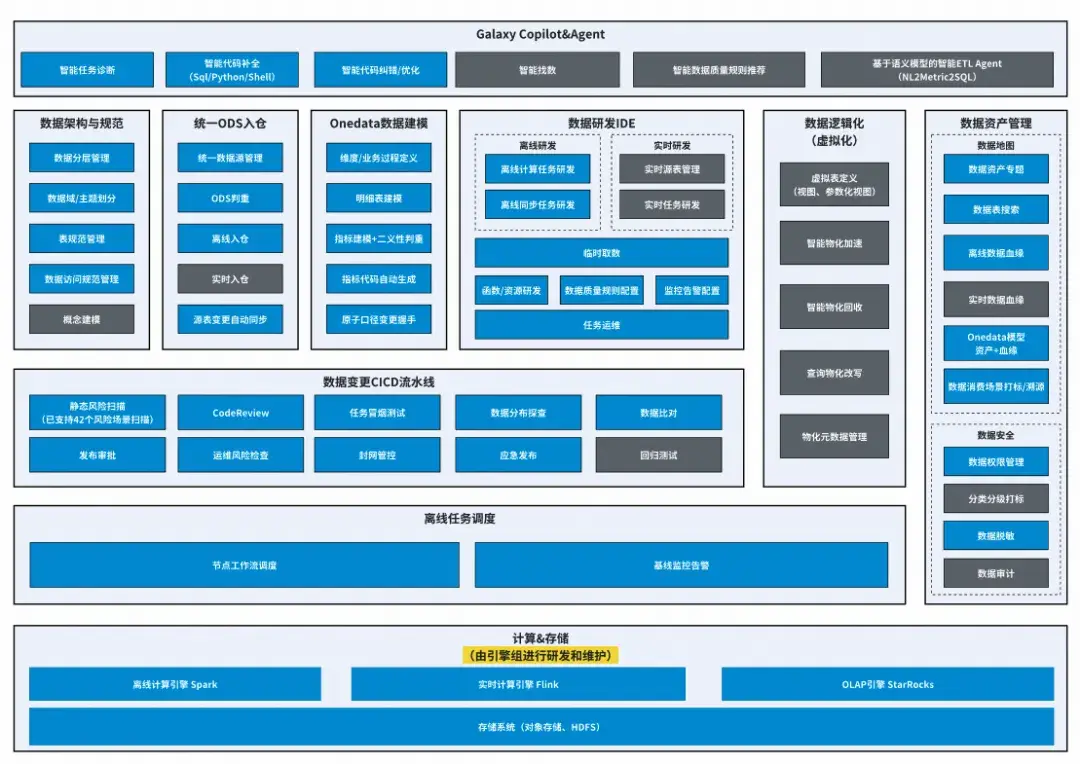
Galaxy數據研發與管理平台產品功能架構
24年立項開始至今,我們主要專注在4個最核心能力的建設,分別為:數據研發套件、數據架構技術、數據質量技術、智能化數據研發。如果把數據研發平台比喻成一輛汽車,那麼這四部分的定位如下圖所示:
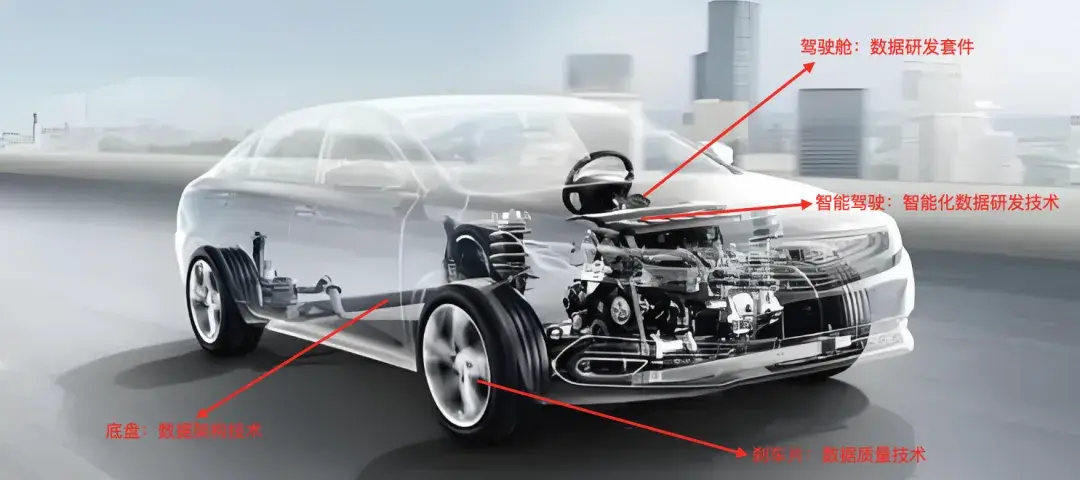
下文會對這些關鍵技術實現、落地進展以及Galaxy數據研發平台的架構演進,進行解析。
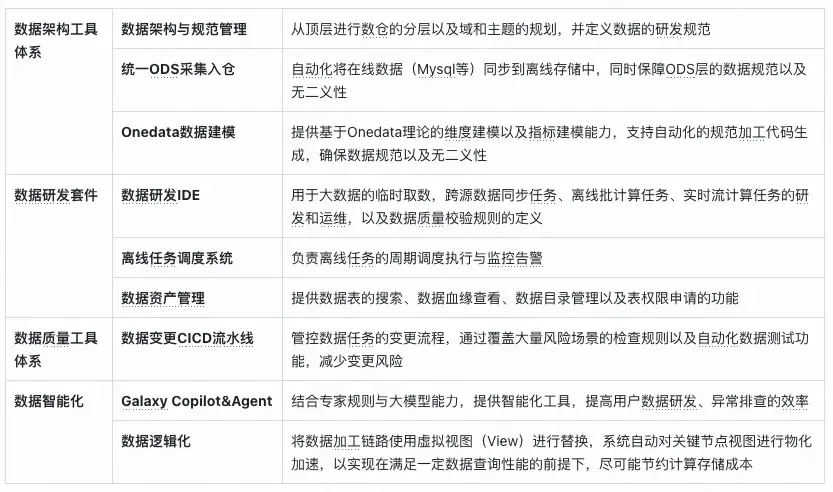
三、數據建設的“駕駛艙” - 數據研發套件
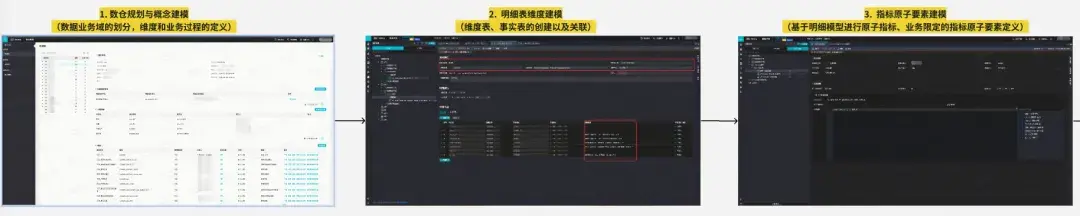
3.1 系統架構解析
數據研發套件包含數據研發IDE、數據資產系統、離線任務調度系統三部分,在平台中的定位類似於“汽車的駕駛艙”,為數據工程師提供豐富的工具集,控制全公司的數據流動與計算。整體系統架構如下圖所示:
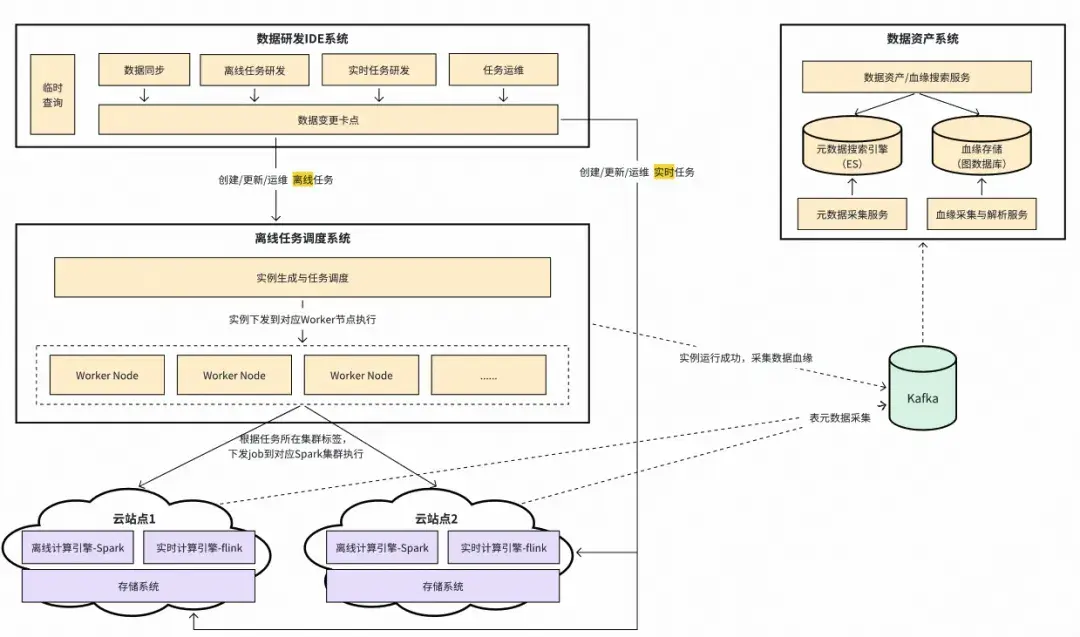
3.2 數據同步技術解析
數據同步也叫數據集成,它是Galaxy數據研發平台的核心組件之一,主要用於公司各種異構數據源與數據倉庫進行數據傳輸,打通數據孤島。它作為大數據鏈路加工的起點和終點,不僅用於數倉ODS層(Operational Data Store,保存原始數據)的入倉構建,也負責將數倉數據迴流(出倉)到消費側的各種數據源中。
離線數據同步
離線數據同步是最為主流的一種數據同步模式,以批量讀寫的形式將源表以全量或增量的形式週期性的寫入目標表。目前Galaxy數據研發套件支持了多種類型數據源的離線同步,包括:
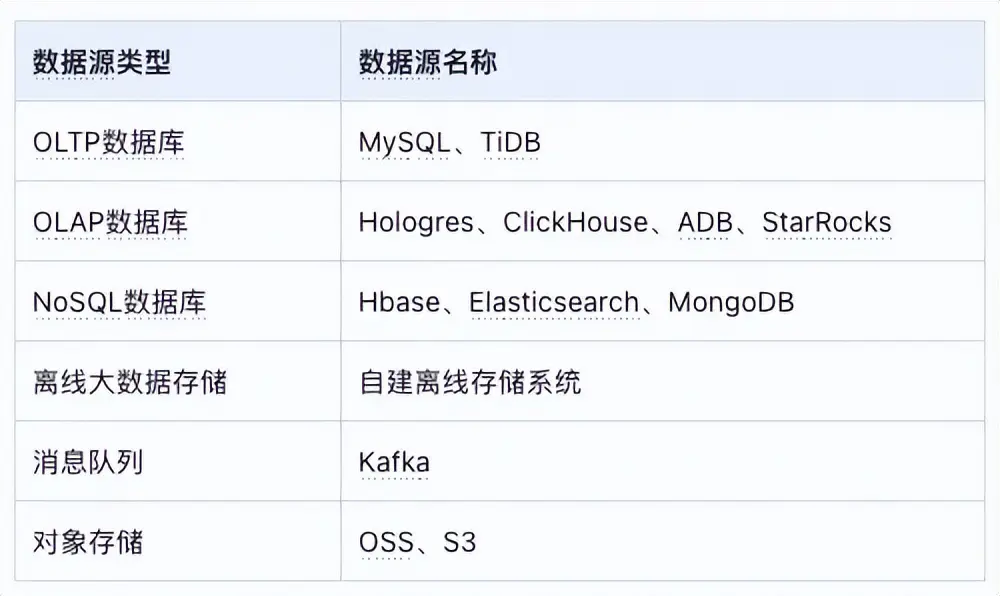
目前Galaxy數據研發套件的離線同步內核基於Spark Jar進行實現,下圖為離線數據同步架構:
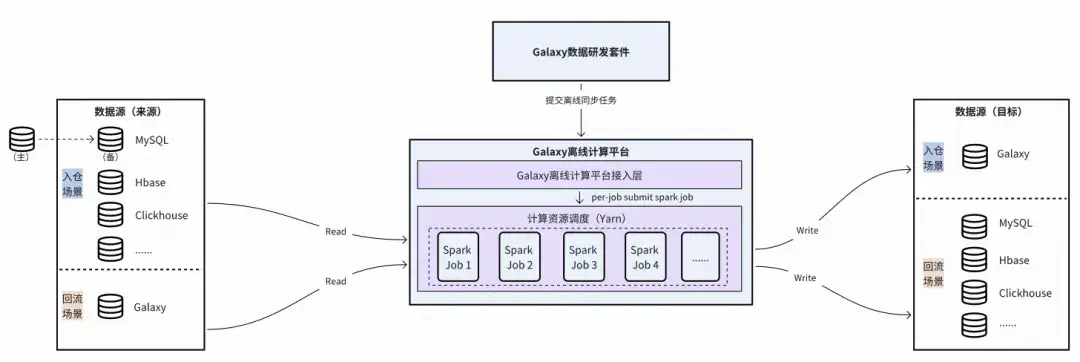
Galaxy數據研發套件離線數據同步架構
離線數據同步的具體實現執行流程(以MySQL同步至得物自建離線存儲系統為例):
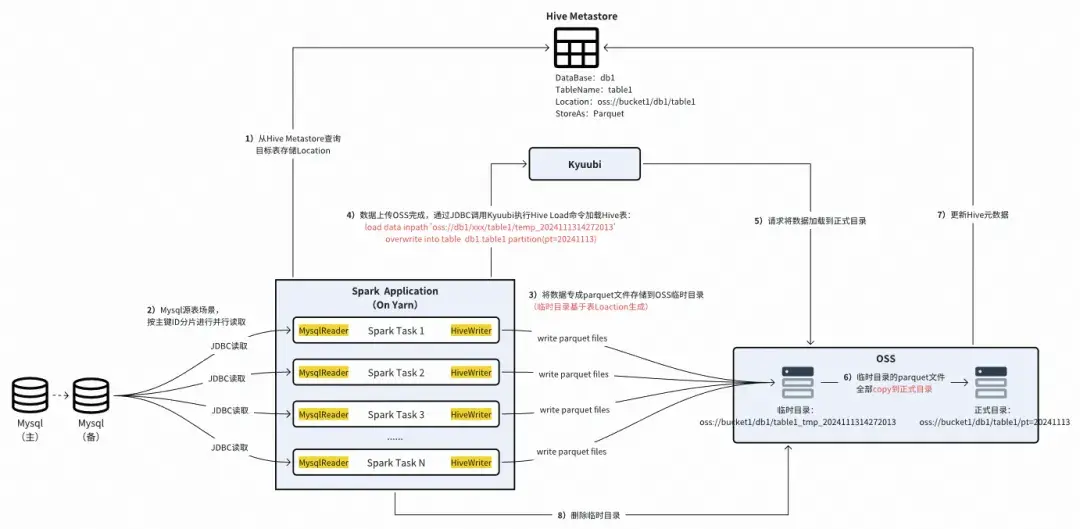
MySQL離線同步至得物自建離線存儲系統的執行流程
實時數據同步
離線數據同步存在着一些侷限性,主要有:
- 對在線數據庫壓力大,即使是讀庫也可能影響線上部分業務的穩定性。而如果單獨為數據入倉申請一個備庫,又會帶來較大的額外成本;
- 大表同步時間長(可達7小時)此類任務基本無法保障下游重要數據產出的SLA;
- 需要在短時間傳輸大量數據,對網絡帶寬依賴高;
- 數據時效差,最快也是T+H的延遲,無法滿足實時報表等對時效性敏感場景的需求。
因此需要實時數據同步的能力對此類場景進行補充。我們主要支持兩種實時同步方案:
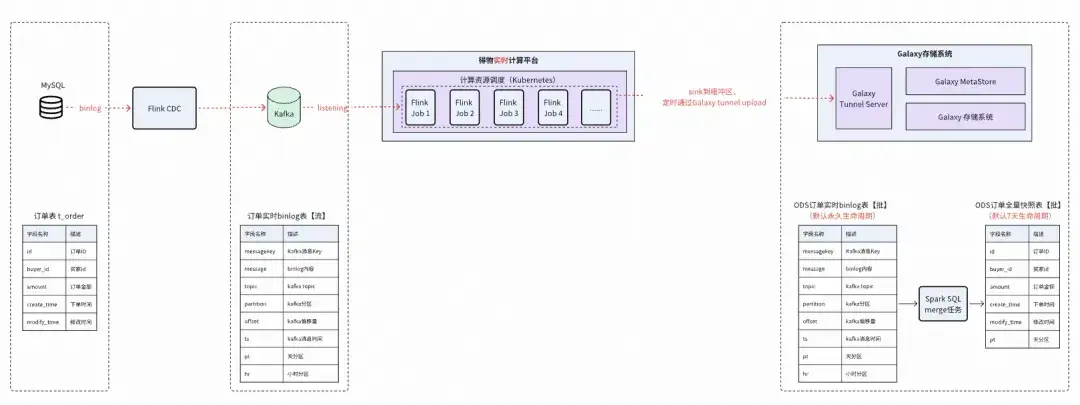
1)基於業務庫binlog的的實時入倉
對比離線數據入倉,基於binlog的實時入倉可以避免對數據庫造成壓力,減少了對網絡帶寬的依賴,同時對於超大規模的表可以大幅縮短基線加工時長。但此方案依然需要(小時/天)將增量數據和全量數據做Merge處理和存儲,這會產生冗餘的計算和存儲成本,且時效性也較差,因此本質上只能為離線數倉場景服務。
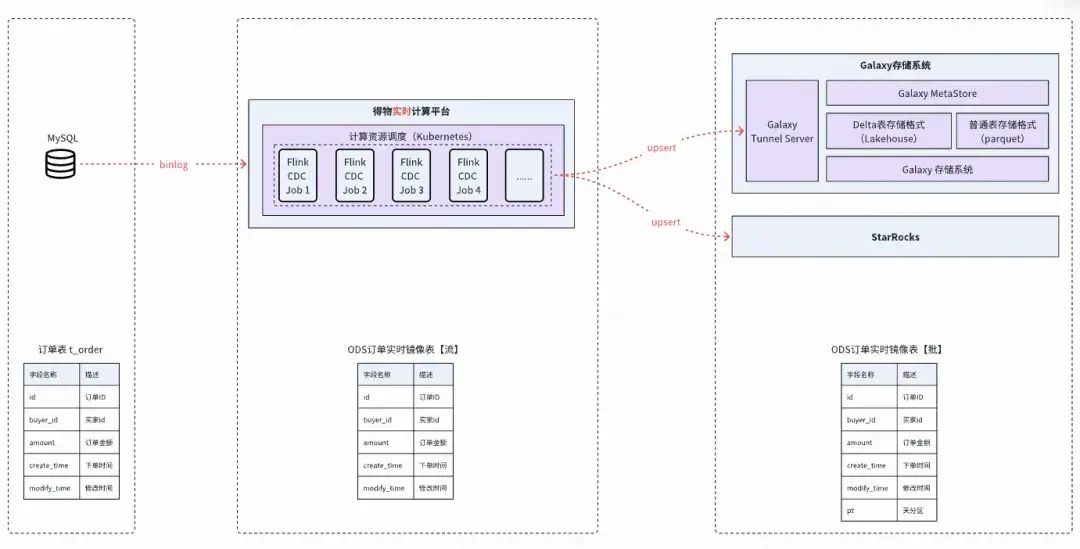
2)實時鏡像同步
通過實時計算引擎Flink CDC將變更數據實時更新到存儲系統中,保持數倉ODS表和來源數據庫表的增全量同步,整體架構更加簡單,並減少ODS層的批計算和冗餘存儲成本。目前規劃通過Paimon、Iceberg等開放Lakehouse能力來實現離線存儲系統的實時事務性更新。根據實際業務場景,也可以直接將數據實時寫入StarRocks等支持更新的OLAP數據庫中。
3.3 數據研發套件任務遷移方案解析
在過去得物的全部數據加工任務全部運行在雲上數據平台,因此除了對齊產品能力外,我們還需要將數據加工任務從雲平台“平滑”的遷移到Galaxy研發平台。
由於調度系統的故障風險極大,一旦異常很可能由於依賴錯亂導致數據異常或停止調度導致的數據產出延遲。因此我們將Galaxy研發套件的平台層遷移和調度層遷移進行解耦,以便將調度系統的遷移節奏放緩。
首先進行風險較低的研發平台層遷移,讓業務可以儘快上線,便於優化數據研發流程和數據資產管理能力。此階段任務的調度依然運行在雲平台。之後再進行調度層的遷移,這個階段用户基本無感,完成後則徹底不再依賴雲平台。
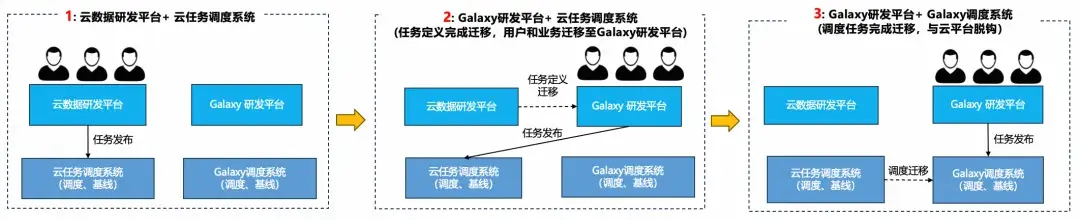
因此架構上一套研發平台需要同時適配兩套調度系統(雲任務調度+Galaxy自研調度系統 ),並支持逐步往自研Galaxy調度的平滑演進。
為了讓調度遷移的過程需要如同“數據庫主備切換”一樣,儘量讓用户無感,我們使用了影子節點的方案,以實現遷移流程的業務無感、可灰度、可回滾。影子節點本質是一個Shell任務,當調度系統啓動它後,它會通過Rest API檢測對方調度系統中實體節點的狀態,並與它保持狀態同步。通過影子節點,我們可以實現按照任意調度任務id進行灰度遷移,調度遷移本質就是將雲平台的實體節點替換為影子節點。如下所示:
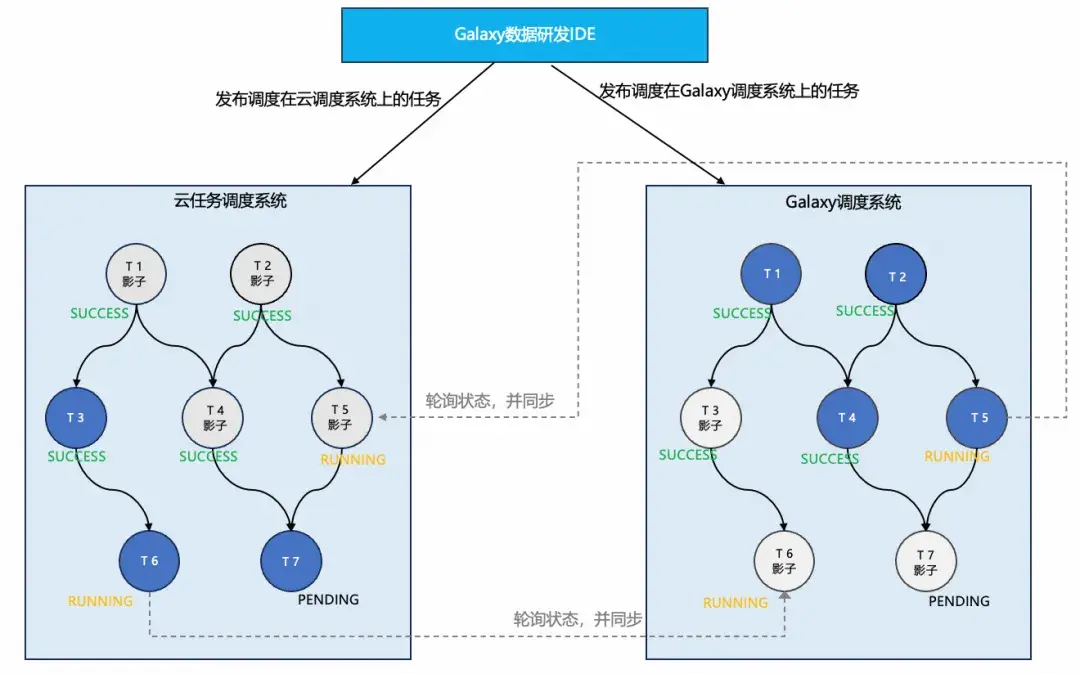
基於“影子節點”的雙調度互通方案
3.4 功能建設與遷移進展
1)功能對齊與優化
目前Galaxy研發套件已完成與原雲數據研發平台的主鏈路功能對齊,具備數據研發與資產管理的全套流程,同時還針自建Spark引擎查詢和運維、在線數據入倉等方面進行定向優化。提效成果:
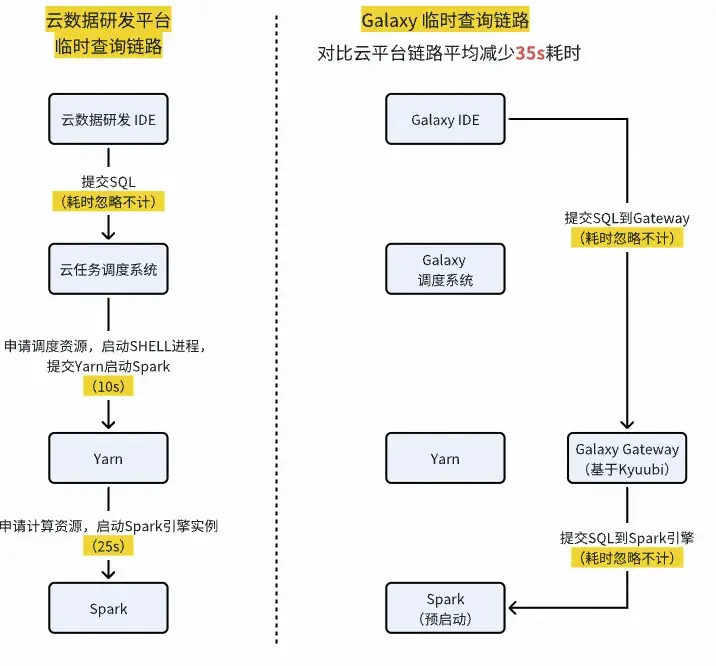
臨時SQL查詢性能優化
通過簡化調用鏈路+Spark Driver預啓動等查詢加速技術,平均每個Query可以比原雲數據研發平台固定節約35s+。
減少查詢等待時間:290+人日/月
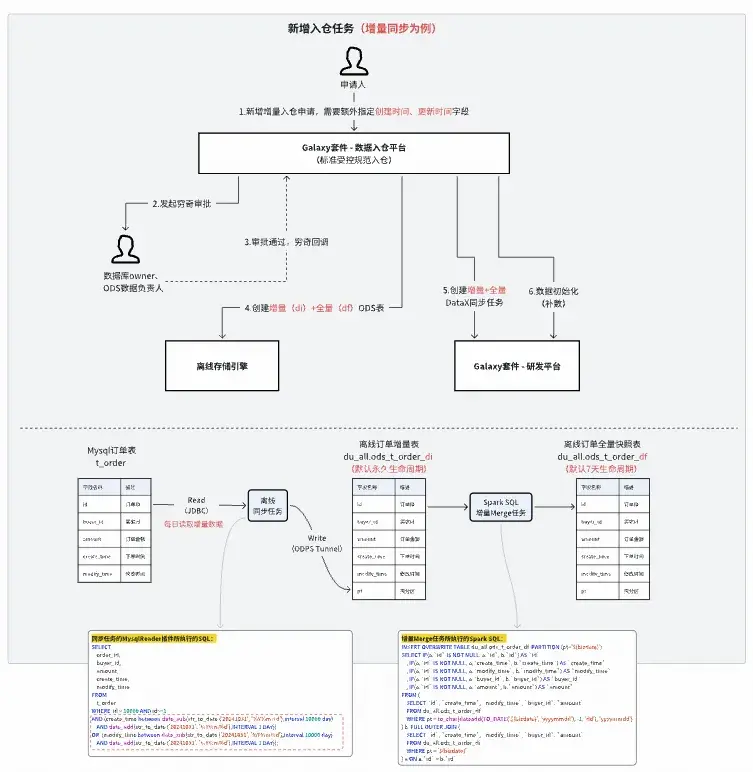
在線數據入倉自動化提效
通過工單申請即可實現MySQL數據入倉。自動幫用户創建同步數據源、增/全量ODS表、同步任務、增量Merge任務,並自動賦權以及數據初始化。根據用户調研和埋點分析,每個數據入倉需求可提效30min+。
提效效果:20+人日/月
2)業務遷移進展
目前我們已完成數據平台、數據挖掘、數據分析團隊的全部任務遷移(佔得物全域的44%),並完成了算法團隊的POC。同時還將上述團隊的臨時取數業務遷移到了自建Spark引擎,從而實現雲上商業版計算引擎的DEV資源縮容400+cu,總計可節省臨時取數計算成本約2萬+/月。
四、公司數據資產的“底盤”-數據架構技術
目前,公司業務用數越來越敏捷和頻繁,而數據資產卻沒有做到“好找敢用”,大量的重複數據和數據煙囱也隨之出現。這不僅導致大量數據二義性問題,同時也使計算存儲成本難以控制。以離線數倉社區&交易的試點域為例,重複冗餘表達到了54%,重複指標達到了35%。這本質上是缺乏數據架構體系的建設,數據架構是公司數據管理的“骨架”和“路線圖”,它如同“汽車的底盤”,忽視數據架構可能導致數據的無序增長以及業務的決策錯誤。
4.1 Onedata數據架構方法論
及工具體系
Galaxy數據研發平台基於“Onedata”的數據架構方法論,建立了統一的數據採集和生產規範,使數據的新增更加合理、易用,提高數據的複用度、研發效率、交付質量,降低使用成本。這是一種“內啡肽”式的數據建設,前期需要花費一定時間進行數據模型的設計並遵守數據研發規範,但從業務的長遠發展來看,這是必須要走的一步。
目前我們已在數據採集入倉和數據研發兩個環節完成了數據架構能力建設,確保數據的入口(ODS)以及數據倉庫的規範性,並再後續通過旁路數據治理的手段進行存量數據的規範化。如下圖所示:
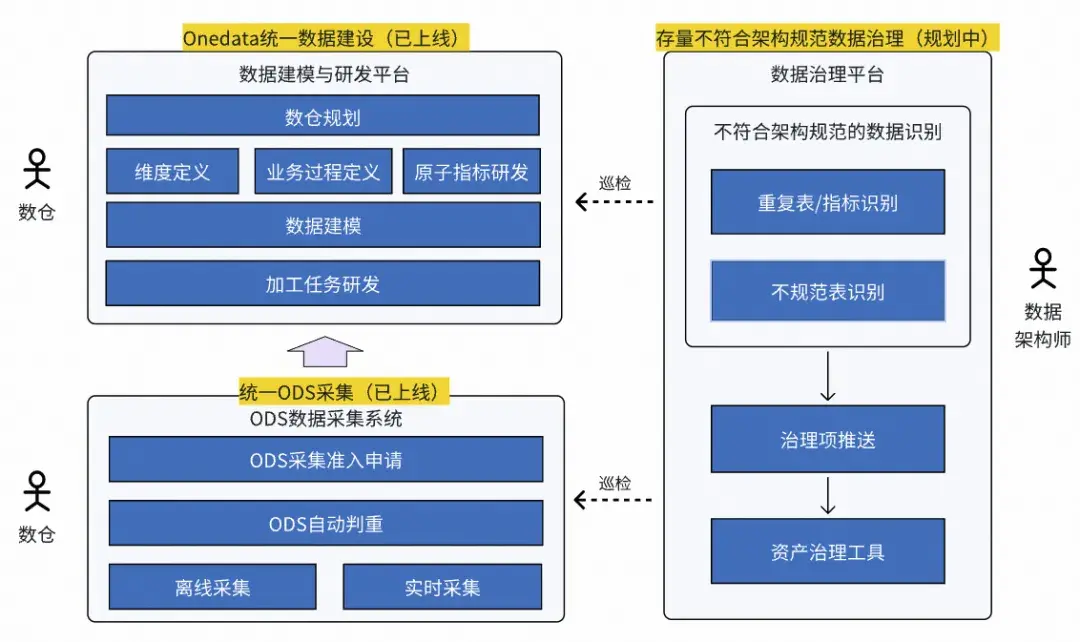
Onedata數據架構工具體系
融入了Onedata數據架構技術體系(紅色部分)後的Galaxy數據研發平台架構如下圖所示:
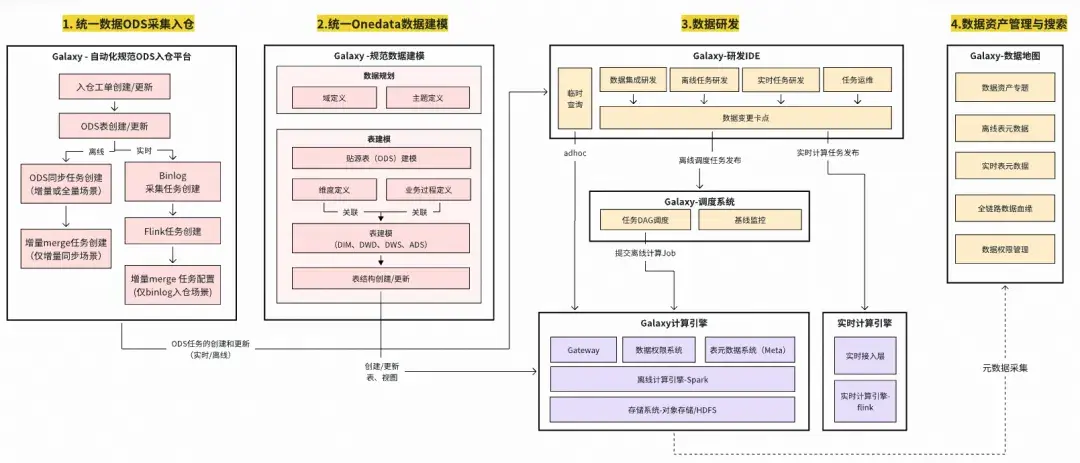
融入Onedata規範數據生產能力(紅色部分)的
Galaxy研發平台技術架構
下文主要對兩個關鍵模塊,統一ODS自動化入倉平台、Onedata數據建模的實現方案進行解析。
4.2 統一ODS自動化採集入倉方案解析
ODS(Operational Data Store),為操作數據層,是整個數倉最基礎的一層,是原始數據採集入倉的第一個環節。Onedata的核心理念之一是所有的數據採集有統一的規範和入口。因為隨意的從在線庫進行採集同步會導致大量重複的數據存儲,以及過長浪費的表存儲生命週期。
由於數據的採集入倉本身沒有過度複雜的業務邏輯,因此Galaxy數據研發平台實現了自動化數據採集入倉能力,提供在線數據源到數倉ODS層的標準化採集和管理能力。無需研發代碼的同時,產生的數據都是嚴格滿足架構規範的。具體價值有:
- 避免重複ODS數據存儲
- 通過庫owner+數倉owner雙重審批,避免不合理的數據入倉
- 控制ODS表生命週期,避免存儲成本浪費
- 全流程自動化,提高ODS層數據研發效能
目前支持MySQL和TiDB的全量採集同步和增量採集同步。同時,開啓自動更新模式的入倉任務,還會訂閲來源MySQL表的變更消息,並自動更新同步任務。關鍵流程如下:
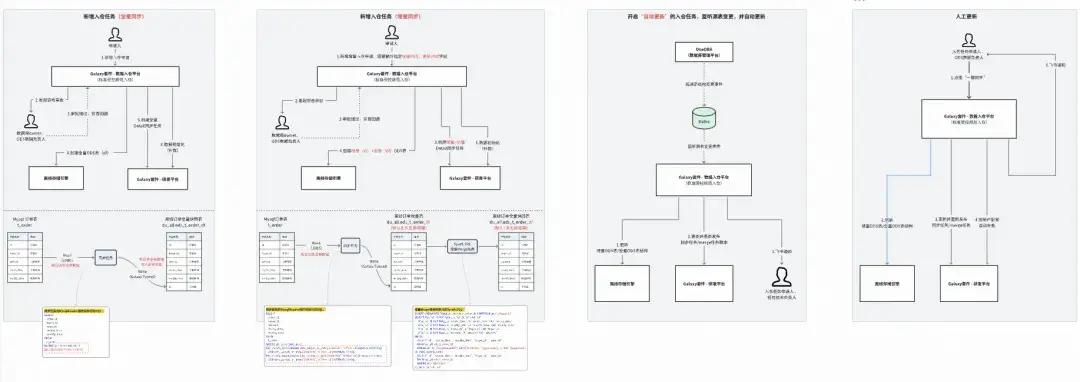
自動化數據入倉流程
4.3 規範數據建模與自動化指標研發方案解析
Onedata在數據研發環節,核心採用維度建模的理論。它構建了公司級的一致性維度、標準化的事實表以及可靈活分析的彙總表和無二義性的指標。並將數據進行清晰的分層,將公司內部分散、異構的數據整合成一套可信、可複用、可分析的數據資產。其主要價值有:
- 保證維度和指標一致性:通過維度和業務過程的概念建模,確保維度表和事實表的全局唯一性;同時通過原子要素的指標建模,確保指標口徑的全局無二義性。
- 提升開發效率:數據工程師無需重複構建維度表和基礎事實表,直接複用數倉公共層的成果;同時指標原子要素定義完成後,指標和彙總表的代碼全部可以系統自動化生成和優化,大幅提高效率,也減少出錯的可能性。
- 增強數據可解釋性:明確的表業務描述以及字段關聯的指標和維度,以及清晰的星型/雪花模型關係,使數據的消費側更方便的使用數據。
- 事前治理:嚴格根據架構規範進行數據研發,禁止重複表的新增,約束數據表的生命週期、數據依賴等,避免事後運動式治理。
Onedata核心概念、建模流程以及配合工具如下圖所示:
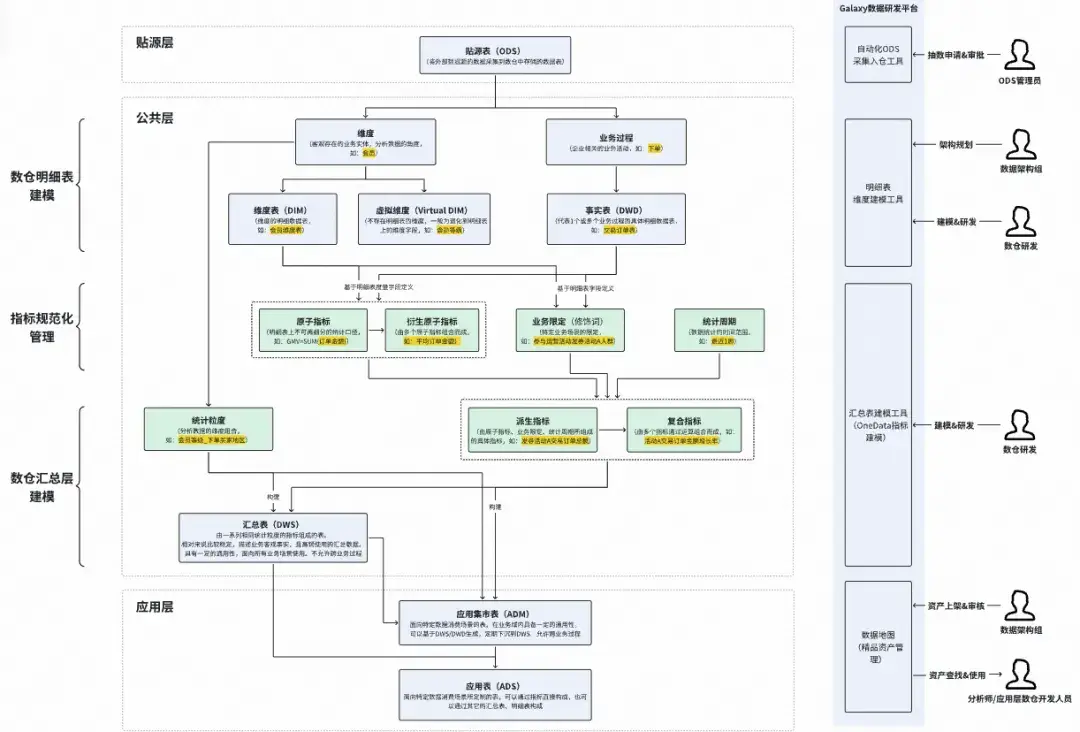
Onedata的數據建模流程
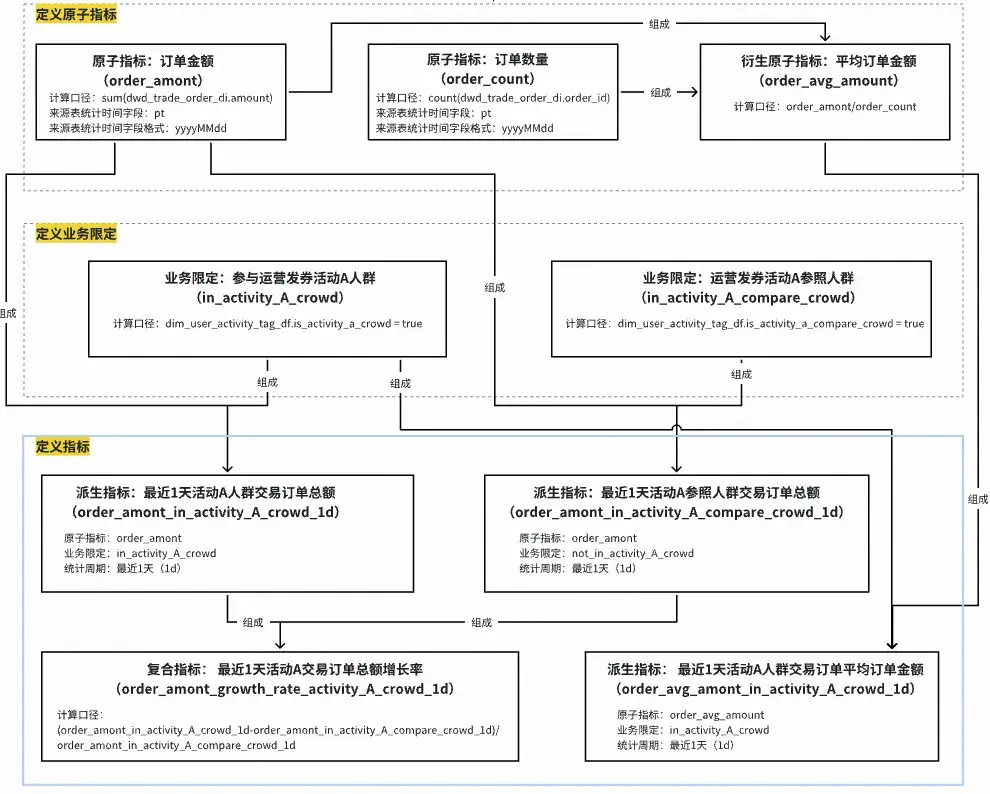
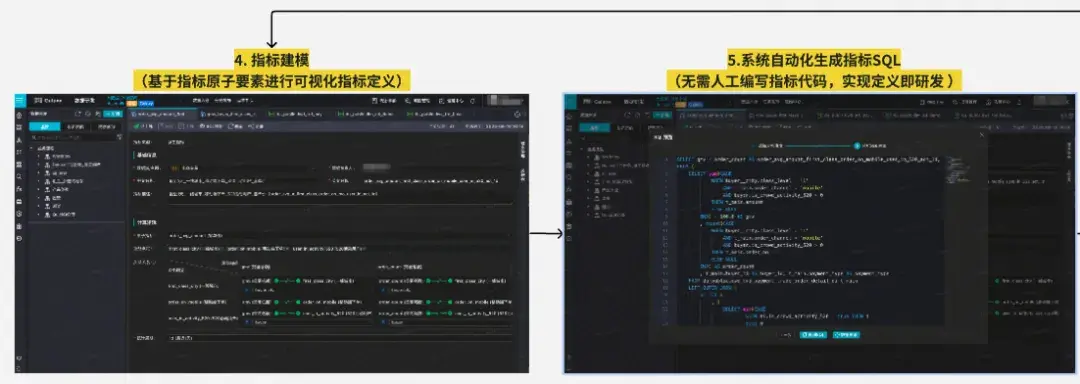
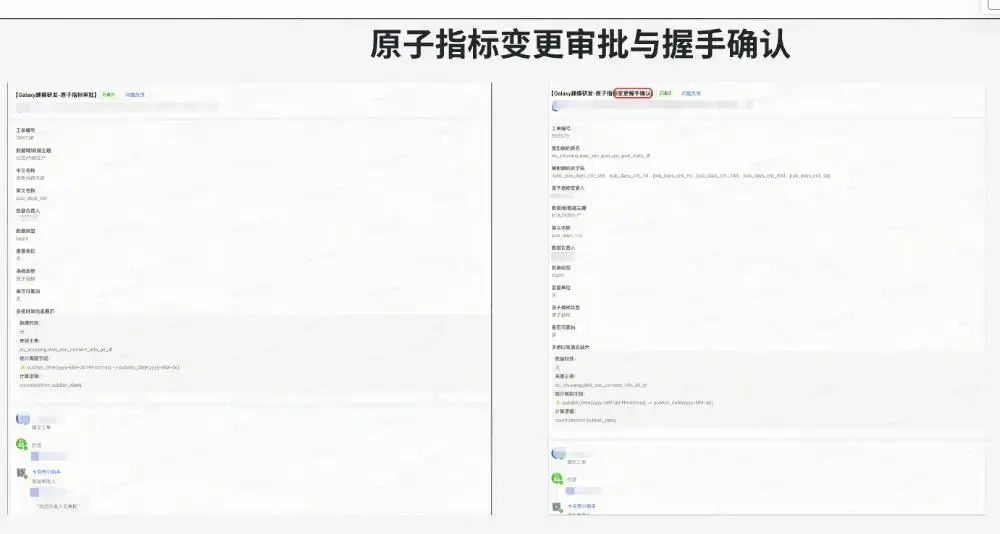
其中最為關鍵部分為“指標建模”。我們將指標的口徑組成拆成了三部分組成:原子指標、業務限定、統計週期,同時在其物化到表上的時候再確定統計粒度。通過原子要素的組合定義指標可以確保同樣的指標在公司全局只會有一個,以及標識出不同的彙總表、應用表中的指標是否為同一個。另外當原子口徑發生了變化,系統也可以根據血緣關係找到受影響的指標和表,讓owner進行握手確認,確保口徑變更一致性。例如下圖所示:
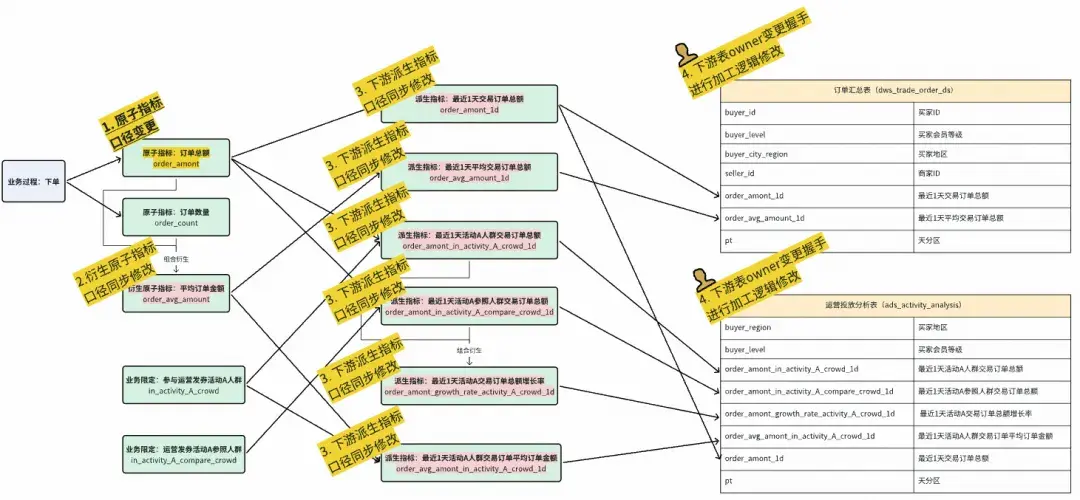
1個原子指標口徑變更,影響了7個關聯指標、
2張表的同步變更
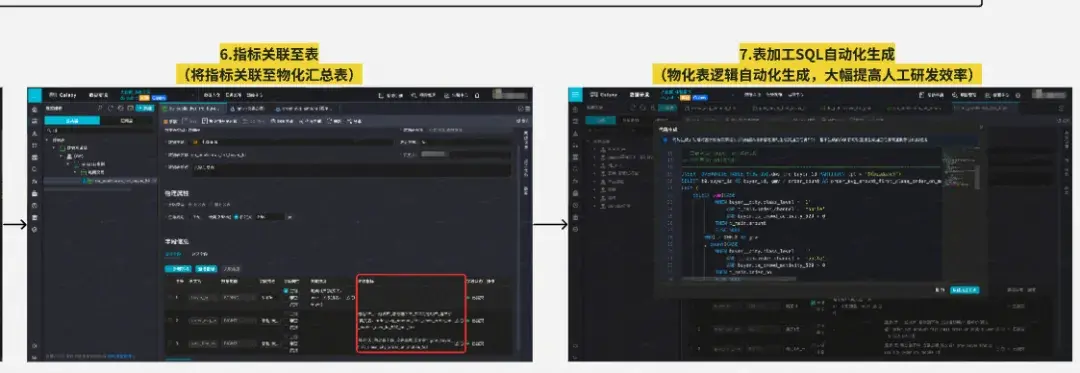
從上圖我們也可以看到,原子口徑的變更影響非常大,即使可以基於血緣進行變更握手管控,人工修改邏輯也容易改錯或遺留。因此我們實現了自動化指標代碼生成的能力,基於原子口徑自動化生成指標及其物化表的加工邏輯。
指標代碼自動化生成方案:
將指標按來源表分組,並將其的組成原子要素(原子指標+業務限定+統計週期+統計粒度)進行SQL邏輯的組裝、優化、方言翻譯,具體流程為:

數據建模與指標SQL生成案例:
1.數據建模
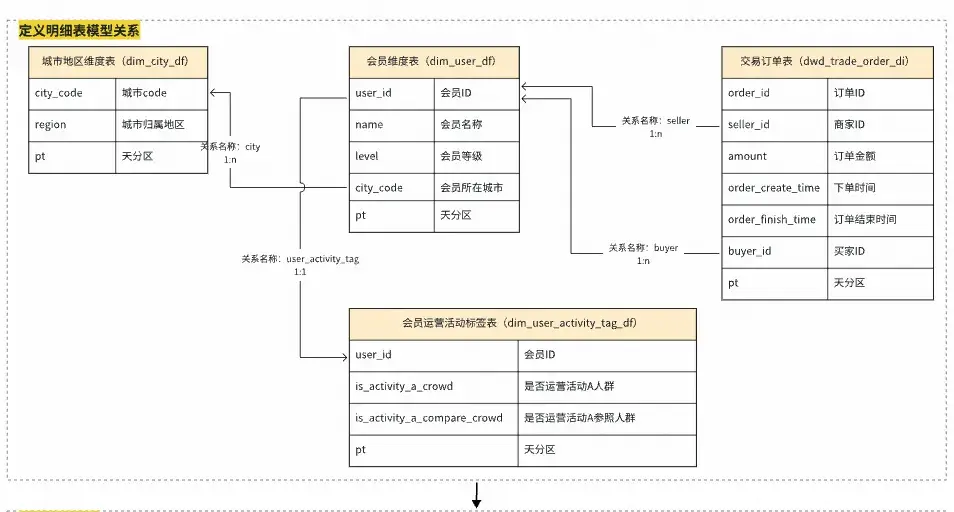
2.代碼生成



3.代碼優化 - 指標SQL優化規則






4.4 當前落地進展與效果
1)統一自動化ODS採集入倉
目前已實現通過工單申請的方式一鍵完成MySQL和TiDB的數據進行增/全量自動化採集入倉能力,無需人工編寫代碼即可實現規範的數據入倉。產品效果如下:
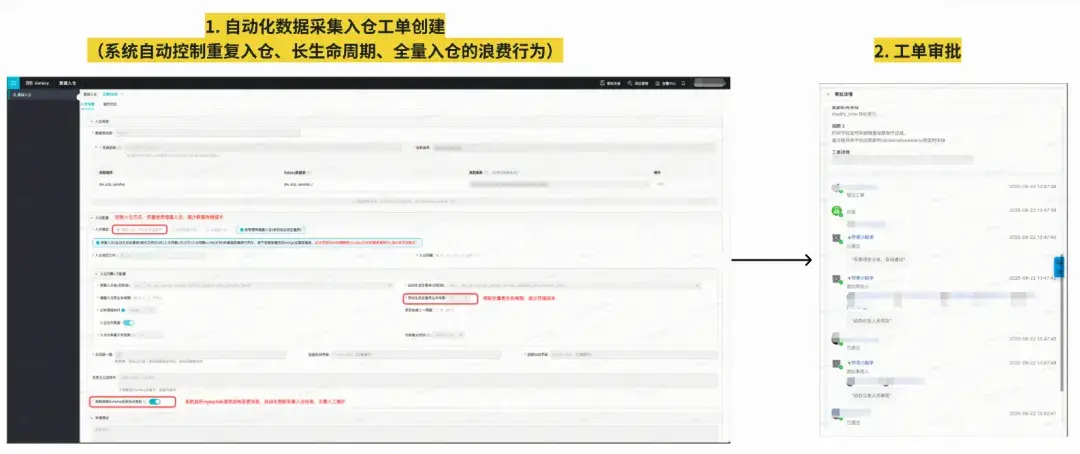
業務成果:
- 業務域落地:目前已在得物內部各域全面落地統一ODS入倉能力。2025年Q3,得物全域新增的入倉任務93.6%是通過Galaxy自動化採集入倉平台自動化生成的;
- 表生命週期規範:25年新增ODS表生命週期定義率較24年Q4提升7.4倍,節約了大量離線存儲;
- ODS存儲增量控制:通過源頭規範數據入倉,配合數據治理團隊使數倉ODS層存儲季度增幅降低:32%->8%
2)規範建模與自動化指標代碼生成
目前已完成數倉規劃->概念建模->明細表維度建模->指標建模->指標代碼自動化生成->彙總表代碼自動化生成的Onedata規範建模研發全流程,產品效果如下:
業務成果:
- 商家域數倉Onedata一期落地效果:完成了40+數據資產沉澱與規範化汰換改造,以及190+應用指標定義與上架,同時沉澱了100+公共派生指標。通過數據規範化重構、二義性問題的解決以及自動化代碼生成的能力,可實現商家數據需求數倉開發效率提升40+%,每迭代線上需求吞吐量提升75%->90%。
- 社區域數倉Onedata一期落地效果:完成1200+應用指標的定義與上架,實現100%無二義性。通過精品資產的規範建設與切換,通過複用公共層數據,實現5+萬/月的成本下降。由於數據二義性的解決以及資產規範度的提高,實現數倉和分析師用於口徑oncall和業務取數的人力成本減少約10+人日/月。
五、數據生產的“剎車片” - 數據質量技術
得物數倉發展至今,不僅用於高管決策以及數據報表的場景,同時和得物線上業務做了非常強的耦合,各域均存在P0級資損風險場景,例如:社區數倉的運營投放、算法數倉的新品商業化、交易數倉的費率折扣、營銷域、用户域等等。這些數據直接應用於線上業務,任何的數據質量問題都可能導致公司、商家、用户的利益受損,以及業務對數倉的信心丟失。
然而過往數倉的數據交付只是停留在快速提供數據以發揮業務價值這一步,業務和研發對數據質量和穩定性保障重視度嚴重不夠,並且沒有明確生產變更和數據質量校驗的SOP,同時也沒有健全的工具體系支撐,全靠數據工程師的自我修養,導致歷史上很多核心數據加工任務沒有保障或者保障不全面,不斷引發P級故障。
5.1 Galaxy的數據質量工具體系
數據質量的相關工具就如同“汽車的剎車片”,可以想象沒有剎車在路上行駛是如何的危險。因此我們在Galaxy數據研發平台建設之初就同步進行了數據質量工具的開發。目前所建立起來的離線數倉質量加固SOP及配合的工具如下:
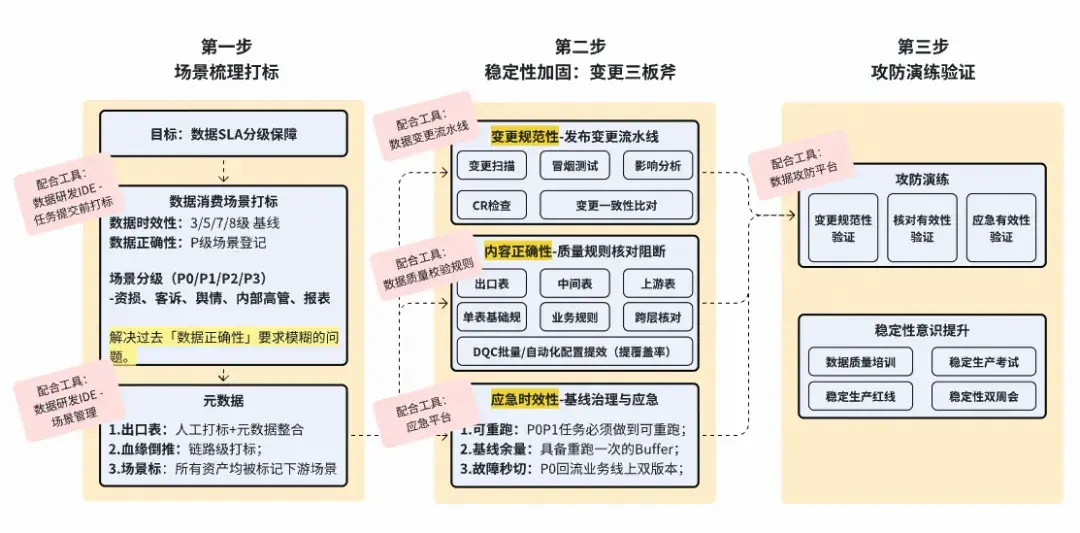
離線數倉質量加固SOP
目前重點建設的2個核心功能,分別為:數據質量校驗規則,用於監控生產數據質量並進行及時阻斷止血,避免下游數據污染;以及數據變更管控流水線,在數據生產變更的環節嵌入消費場景打標、自動化風險掃描、code review、自動化數據測試、發佈審批等功能,以全面保障數據質量。融入了數據質量技術體系(紅色部分)後的Galaxy數據研發平台架構如下圖所示:
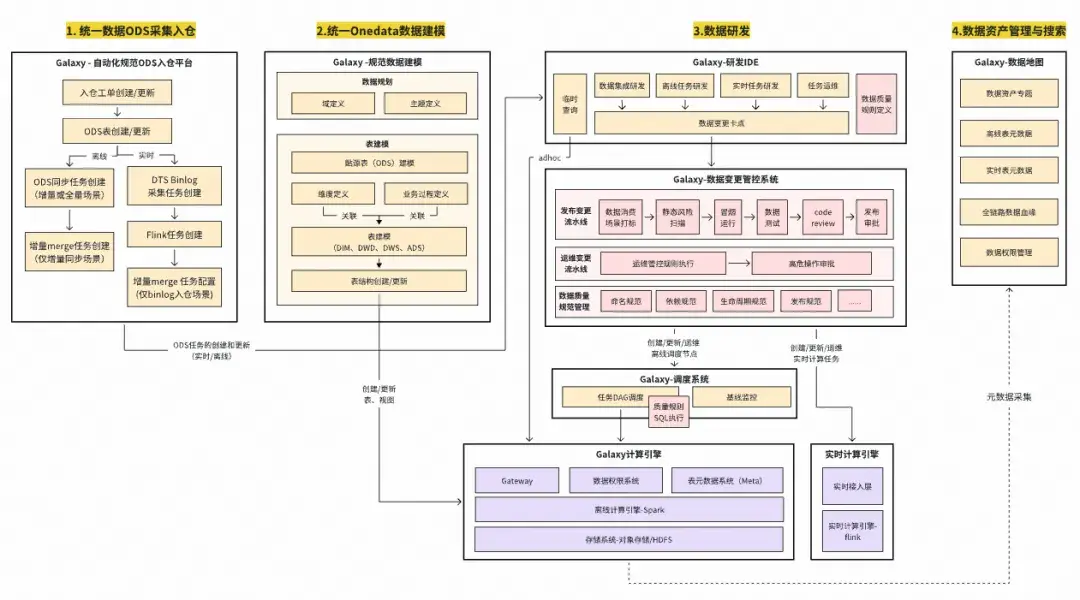
融入數據質量能力(紅色部分)後的Galaxy數據研發平台架構
5.2 當前落地進展與效果
數據質量校驗規則
Galaxy數據研發平台已經實現了完善的數據質量規則校驗能力,用户在Galaxy數據研發IDE上面向數據標準進行高效的質量規則定義,系統會自動生成校驗SQL隨着任務的發佈一起下發到調度系統中執行。同時支持了強規則(主路執行,數據異常阻斷任務執行)和弱規則(旁路執行,數據異常進行告警)兩種規則運行場景,應對不同的場景訴求。產品效果如下所示:
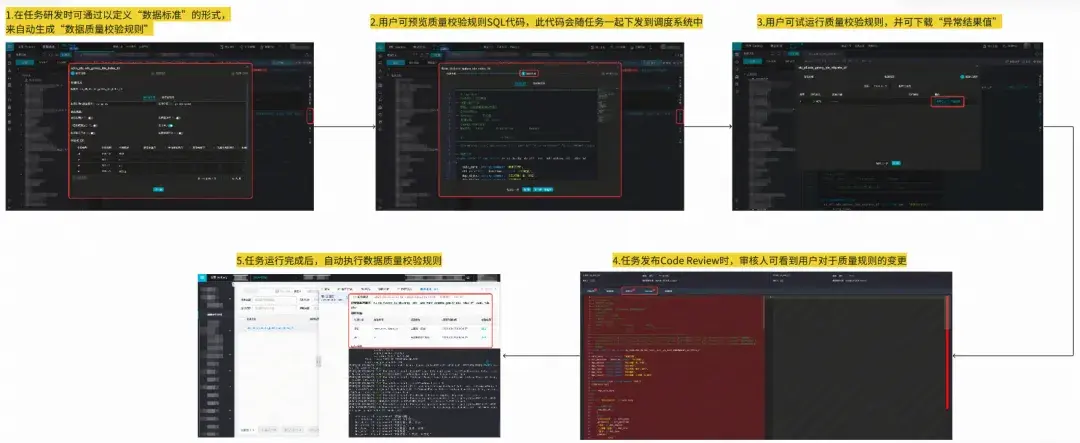
場景覆蓋方面已經實現了表非空校驗、表波動校驗、字段主鍵校驗、字段非空校驗、字段波動校驗、字段枚舉校驗、自定義SQL校驗等15種規則,覆蓋了離線數倉100%的校驗場景。
同時通過批量導入、弱轉強等提效工具幫助離線數倉團隊在25年Q3新增了1200+質量規則,全量P0任務質量規則覆蓋率達到96%,非P0任務86%。並結合發佈管控流水線能力,實現了P0場景任務100%變更覆蓋表級規則,且金額等高風險字段100%變更覆蓋字段級規則。
數據變更流水線
目前已經完成了完整的變更管控流水線的能力,主要功能包括:消費場景打標、靜態風險掃描、Code Review、冒煙測試、數據探查、數據比對、發佈審核。產品效果如下所示:
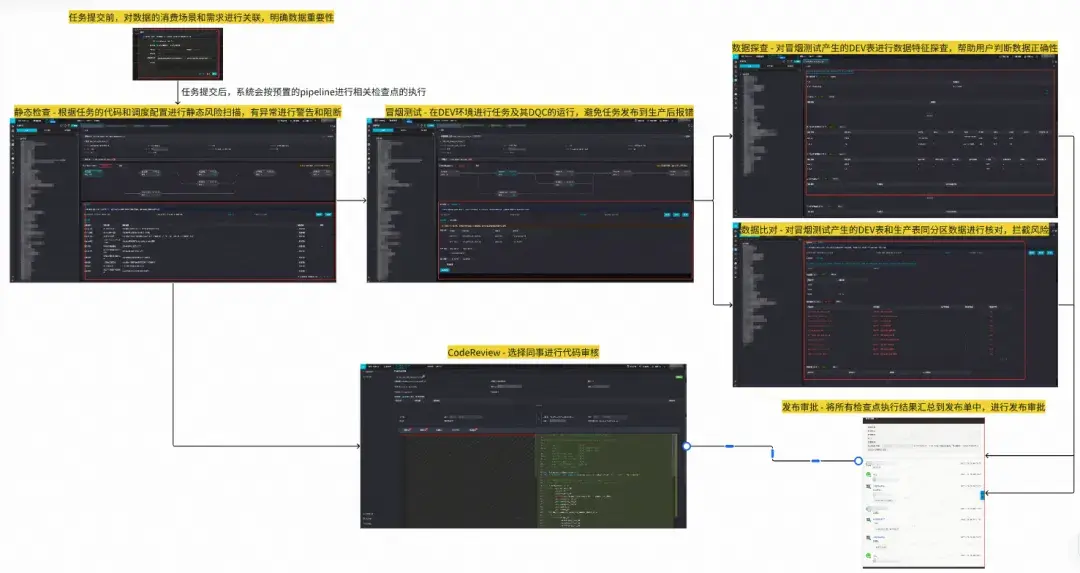
其中,場景打標方面,離線數倉末端任務(ADS和迴流)98.3%打標了數據消費場景,對於全鏈路分析數據重要性和消費場景起到了巨大的作用;變更管控方面,靜態掃描節點已實現了48個風險掃描規則,覆蓋了94%的已知風險場景,當前系統自動化風險識別率98%(剩餘為人工CR發現的問題),平均每雙週可事前攔截600+起風險事件。
六、數據研發之路的“輔助駕駛”-智能化數據研發
過去10年,通過開源大數據組件的興起,大幅度降低了企業構建大數據Infra的難度,在一定程度上實現了企業間的“數據平權”。而在企業內部,由於數據同步、ETL研發調度、資產管理、數據治理等複雜的技術導致找數和用數門檻非常高,因此大部分場景都是提需求給數倉團隊進行數據加工,那麼數據團隊的交付效率就變成了公司各業務線數據化經營決策的瓶頸。
6.1 Galaxy的智能化演進路線
我們計劃分3個階段(L1~L3)建設Galaxy數據研發平台的智能化能力,來提升數據研發效率,降低業務自主進行數據研發的門檻,實現公司內部不同部門和崗位間的“數據平權”。如下所示:

Galaxy數據研發智能化演進路徑
當前我們處於L1的Copilot階段,通過在數據研發流程中,旁路嵌入基於專家經驗規則和大模型的智能SQL代碼續寫、智能任務診斷、智能SQL代碼糾錯與優化、 智能質量規則推薦等應用,輔助用户進行高效數據研發。嵌入Copilot後的Galaxy研發平台整體架構如下,主要關注紅色部分:
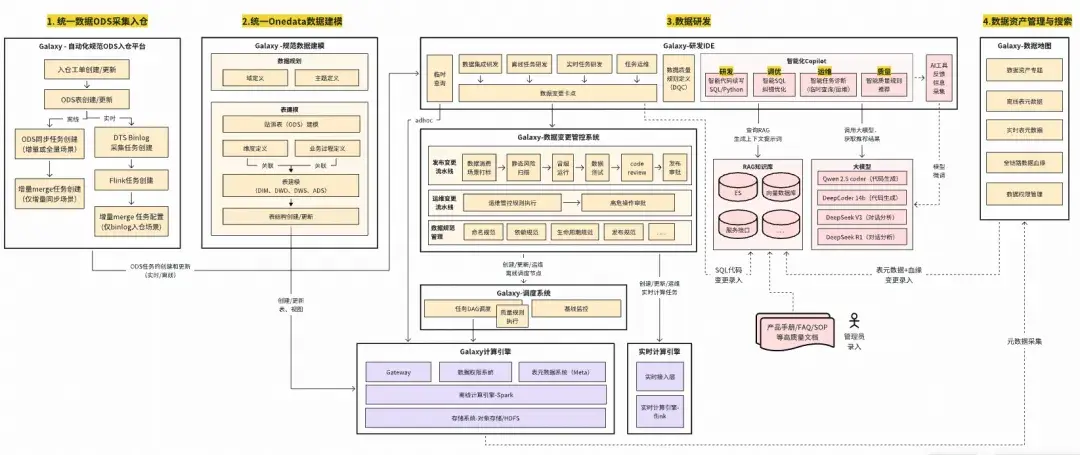
數據智能化L1階段的Galaxy研發平台技術架構
下文主要對當前較為成熟的功能,智能SQL代碼續寫的實現方案進行解析。
6.2 智能SQL代碼續寫方案解析
SQL代碼續寫的重點在於工程鏈路,大模型上我們選擇適合代碼生成的小參數模型,當前使用了Qwen-2.5-coder,後續會進行其他模型的實驗。系統流程如下:
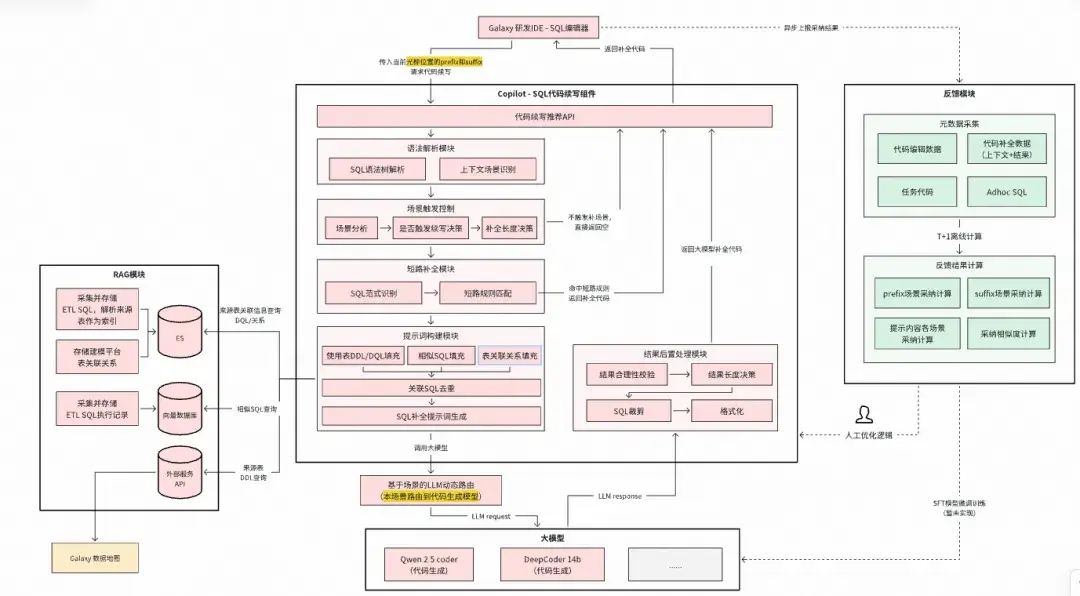
智能SQL代碼續寫系統流程
關鍵模塊功能描述:

6.3 當前落地進展與效果
目前Galaxy研發平台已經落地了智能代碼續寫、智能任務診斷、智能SQL糾錯與優化3個Copilot應用,具體業務效果如下:
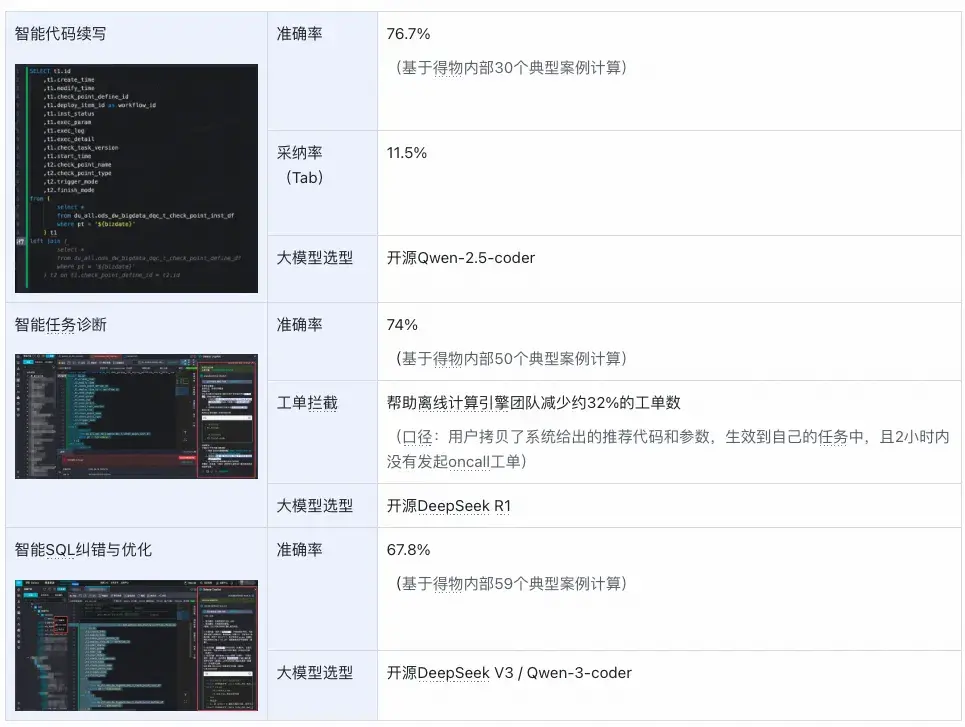
其中高活用户的智能代碼續寫功能開啓率為98.5%,整體採納率趨勢和我們做的優化動作如下:
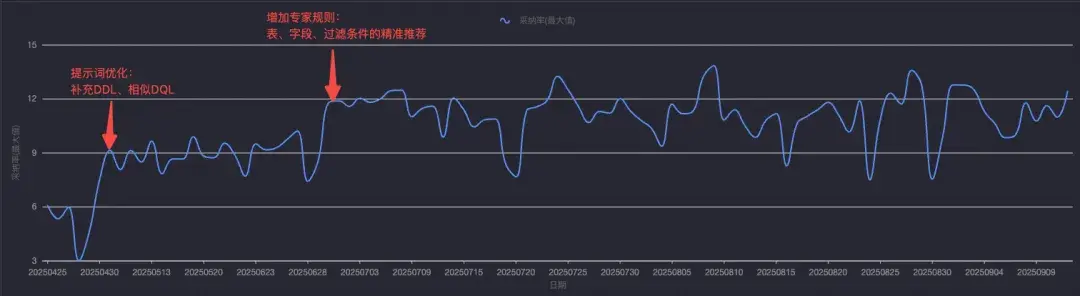
智能SQL續寫採納率趨勢
(2025年04月25日~2025年09月09日)
七、後續規劃
後續Galaxy數據研發平台會持續完善現有功能提升產品體驗,同時在智能ETL Agent、Data Fabric、數據邏輯化三個前沿方向進行探索,通過技術先進性為公司數據業務帶來更多的價值。
7.1 長期規劃一:智能ETL Agent
核心目標:數據研發提效,並降低數據研發門檻
ETL Agent核心能力是需要將用户的自然語言業務需求翻譯成數據表的SQL加工邏輯,其本質上就是“NL2SQL”的傳統命題。然而,如果讓大模型直接分析用户的問題,那麼它需要嘗試從底層混亂的物理表結構中生成目標SQL,這會將業務語義的複雜性完全壓給大模型,導致同一指標因表結構理解偏差或字段映射錯誤而產生不同結果。
Galaxy的ETL Agent會採用“NL2Metric2SQL”的方案。通過大模型進行自然語言的解析,結合向量數據庫的相似度匹配實現NL2Metric的能力,然後基於Onedata數據模型和指標語義層,將自然語言的用數需求準確翻譯為指標原子要素(原子口徑、業務限定、統計週期、統計維度),並自動構建ETL加工鏈路。如下圖案例:
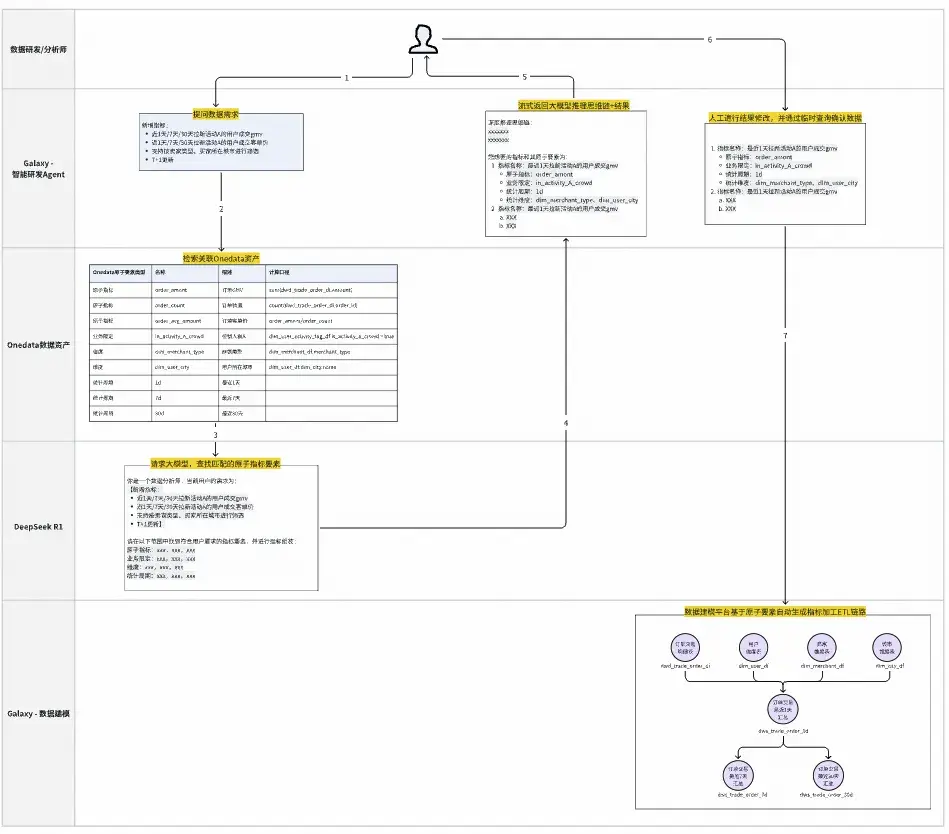
智能ETL Agent用户流程案例
這也是Galaxy智能化的L2階段,這個階段將數據研發分成了專家數據研發以及智能數據研發。專家模式依然按傳統SQL任務進行數據研發。而智能研發則以自然語言形式的數據需求作為輸入,通過提前將Onedata數據模型存儲在RAG的向量數據庫中,然後根據數據需求內容進行分詞,按相似度從RAG中匹配出相關的指標要素構建出提示詞,並請求大模型獲得正確的指標要素。
實現智能ETL Agent後的智能化L2階段Galaxy研發平台架構(紅色部分為Agent相關模塊)
7.2 長期規劃二:Data Fabric
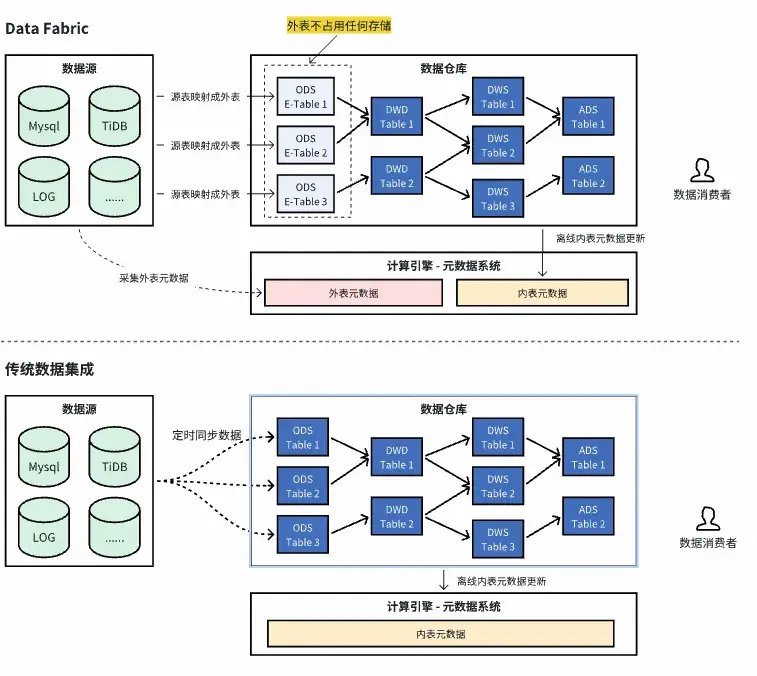
核心目標:減少非必要的離線數據存儲成本
傳統的數據集成(數據入倉)方案是通過離線或實時數據同步工具將公司內部各數據源的數據全量或增量地抽取、清洗、加載到一箇中心化的數據倉庫中。但這種方案在技術上存在三個問題:
- 離線存儲成本大:傳統的數據集成方式,離線數倉的ODS層會拷貝全部所需在線數據的副本。然而其中很大一部分的數據僅用於短期分析,或用於對RT不敏感的查詢場景,這些數據在離線數倉中物化存儲的ROI極低,造成了大量存儲成本浪費。
- 數據搬遷成本大:隨着業務的發展,公司的數據源可能分佈在不同地域、不同雲環境。週期性的將海量數據同步至中心化數倉,將產生巨大的網絡帶寬成本和入倉等待時間。同時入倉需要與數倉工程師進行需求溝通,也存在大量協作成本。
- 數據一致性問題:數據同步有顯著延遲,在離線同步的場景下,分析的數據會有天級延遲。
Data Fabric(數據編織)是一種全新的數據集成架構方案,核心理念是 “不移動數據,移動計算”。 技術實現方案上以外表的形式來封裝源端表,通過統一的元數據系統,將源端表(外表)和離線表(內表)統一管理起來,使用起來對用户無感。在執行計算時,通過Spark引擎的跨源聯邦查詢能力,直接從各源端數據庫(一般為備庫或抽數庫)將數據查詢回來後進行分佈式計算。下圖展示了Data Fabric與傳統數據集成的區別:
7.3 長期規劃三:數據邏輯化
核心目標:計算存儲成本降低,數據研發與運維提效
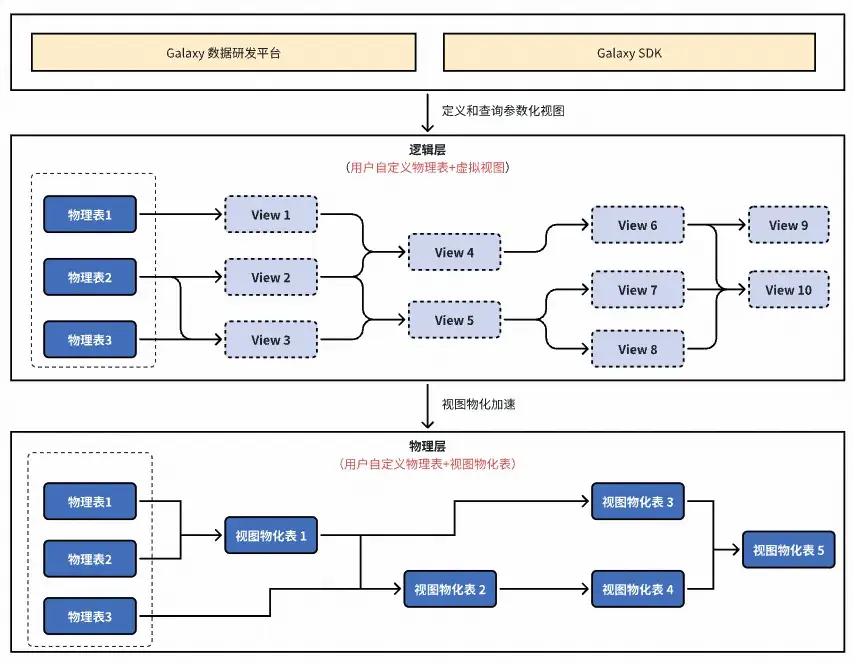
通過視圖或參數化視圖進行整條數據鏈路的構建,那麼整條鏈路就完全不需要任何存儲成本,計算成本也僅在視圖查詢時才發生。但這樣會導致一個問題,當視圖邏輯複雜,嵌套層級多時,查詢效率非常低,且對相同視圖的查詢都需要重新計算。因此我們需要對一些關鍵的視圖進行物化,物化後的視圖,在查詢時可以直接訪問其物化表,實現查詢性能的大幅提升。
數據邏輯化架構,會存在兩層,上層為由用户定義的物理表以及虛擬視圖組成的邏輯層,對用户感知;下層為物理表和系統自動生成的視圖物化表組成的物理層,對用户不感知,具體如下圖所示:
數據邏輯化的架構分層
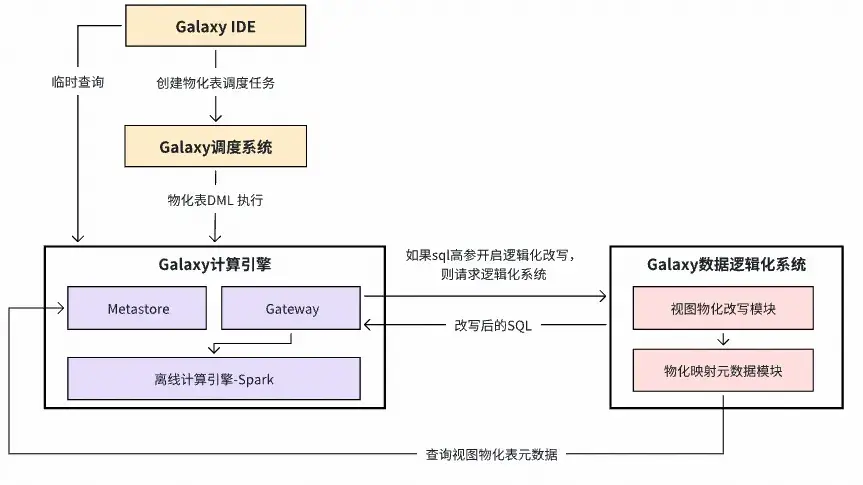
數據邏輯化的關鍵技術之一為視圖物化表的命中。當某個視圖存在物化表時,需要將對應查詢範圍的數據直接翻譯成物化表的查詢,而不去展開視圖查詢,以提升查詢性能。技術鏈路如下圖所示:
數據邏輯化的視圖物化命中改寫鏈路
另一項關鍵技術為視圖的物化策略與回收策略。系統需要定期通過算法識別出在滿足產出時效的前提下,整體計算和存儲成本最低的物化方案。例如下方案例:

數據邏輯化的視圖物化與回收策略
目前全域優化場景簡單且有效的算法有遺傳算法、模擬退火算法等。通過評估在一定存儲成本限制下,哪些視圖的物化組合,可以使用整體計算cost最低。
將數據虛擬化技術和ETL Agent能力結合,我們可以實現系統自託管的智能數據研發,即Galaxy智能化的L3階段。
往期回顧
1. 從一次啓動失敗深入剖析:Spring循環依賴的真相|得物技術
2. Apex AI輔助編碼助手的設計和實踐|得物技術
3. 從 JSON 字符串到 Java 對象:Fastjson 1.2.83 全程解析|得物技術
4. 用好 TTL Agent 不踩雷:避開內存泄露與CPU 100%兩大核心坑|得物技術
5. 線程池ThreadPoolExecutor源碼深度解析|得物技術
文 /宇賢
關注得物技術,每週更新技術乾貨
要是覺得文章對你有幫助的話,歡迎評論轉發點贊~
未經得物技術許可嚴禁轉載,否則依法追究法律責任。