

本文介紹了 Zendesk 構建數據遷移器進行長時間大規模賬户數據遷移的實踐,以及選擇這種作業執行方式的權衡和取捨。原文:Less is More: Improving job execution by ditching the job executor
本文概述了我們所做的架構調整,這些調整極大簡化了長時間運行任務的執行模式。
通過利用客户端行為,系統不僅提升了整體功能,還消除了分佈式任務執行中的諸多複雜問題。

背景:Zendesk 的賬户遷移
在 Zendesk 的後台系統,每個客户賬户的相關數據都存放在全球各地的某個數據中心。我們不想讓賬户永遠停留在其創建時所在的原始數據中心,因此通過完善的賬户遷移工具,能夠以幾乎零停機時間的方式將賬户遷移到新的數據中心。
該工具非常有用,既對客户有益,也對我們自身有益。最初是為將單一 Rackspace 部署擴展到多個數據中心而設計,多年後,它再次在將數據中心遷移至 AWS 時發揮了關鍵作用。目前仍被用於在各個數據中心之間平衡容量和其他指標,而且最近在將收購公司的服務遷移到我們的共享基礎設施方面也發揮了重要作用。
賬户遷移工具包含中央協調器以及若干數據遷移器。協調器負責管理整個賬户遷移生命週期,隨着遷移進程的推進,會協調各個系統。而實際進行數據傳輸工作的通常是數據遷移器,我們支持的每個數據存儲類型都配備有一個數據遷移器。
歡迎加入!請將物品放置在 Zendesk 基礎設施內
所以,當我們收購了一家使用不同數據庫系統的公司時,就會面臨難題。
最簡單且直接的解決辦法是“我們能不能不這麼做?”如果有已被認可且同樣適用的數據存儲方案,我們將轉而使用該方案。
如果這種方式不可行,且需要遷移數據的話,那麼通常就需要新的數據遷移工具。這是一項繁重工作,所以我們很不情願去進行這項工作,但讓數據永遠滯留在核心 Zendesk 基礎設施之外會使得情況變得複雜,並且還會使所收購的產品失去許多組織層面的益處。
因此,在將收購項目整合到共享基礎設施中時,構建數據傳輸系統的複雜性會產生重大影響。
數據遷移器是作業執行服務器
數據傳輸的具體細節既重要又有趣,但今天我們要關注的是任務管理,因為數據傳輸工具就是通過執行任務來工作的。那麼,什麼樣的事情可以被稱為“任務”呢?在我看來,任務的核心特徵是:
- 長期運行(如果運行時間較短,那可能只是一個請求而已),並且
- 會進行完成情況監控(如果無需等待其完成,那麼只需觸發事件或通知,然後離開即可)
除了這些常見特性之外,數據遷移任務通常都是持續進行的,會將數據從源系統複製到目標系統,隨着新變化的出現而保持同步。因此,我們會讓它們一直運行,直到整個賬户遷移完成。
典型作業系統 API
如果有作業,可能需要運行作業系統。對於作業,編排器是請求作業運行的客户端,而數據移動器是實現作業的服務器。
大多數用於長時間運行作業的系統(包括我們的初始實現)都有類似於這樣的 API:
StartJob(config) -> jobIdGetStatus(jobId) -> statusStopJob(jobId)
API 構造簡單,但要成為適合執行數據遷移任務的工具,必須滿足一系列要求。
持久性
所有任務絕不遺失!如果客户創建了任務,那麼服務器在發生崩潰或重啓時也必須不會忘記這個任務。
容錯性
作業可以運行很長時間,而 Kubernetes 容器並非永遠存在。如果某個容器崩潰或被替換,作業就需要通過讓另一個容器接替來繼續進行。
恢復
中斷不應導致工作重新開始,工作應從(接近)上次停止的地方繼續進行。
唯一性
我們不希望兩個實例在同一時間執行相同的任務。
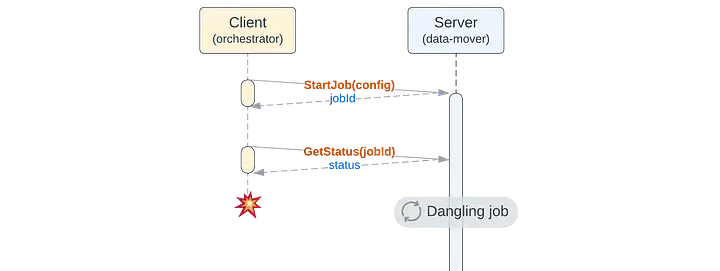
懸置任務
如果客户出於任何原因忘記了某個任務,我們不希望一直執行這個任務,因為這既浪費資源,還可能在客户意料之外的情況下引發問題,因此需要檢測到這些懸置任務並停止執行。
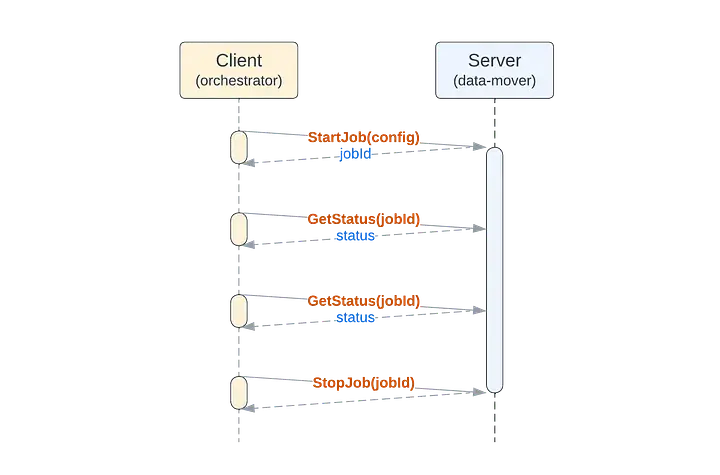
任務執行架構
基於上述 API 和需求,顯而易見的架構包含數據庫和一個鎖 API。該鎖 API 可能會複用相同底層數據存儲,也可能是獨立系統,如 Consul 或 etcd。
當作業被創建時,會將其保存在數據庫中(以確保持久性),並且其當前狀態會定期進行保存(以便於恢復)。當進程正在執行某個作業時,首先會獲取該作業的鎖(以確保唯一性)。如果數據存儲中存在未完成的作業但沒有活躍鎖,那麼這些作業就可以由工作進程來接管(以實現容錯)。
我們用 3 個服務器實例、1 個作業數據庫以及 1 個鎖服務將這一切整合起來。以下是執行一個示例作業的步驟序列,其中包括在另一個服務器實例上的恢復操作:
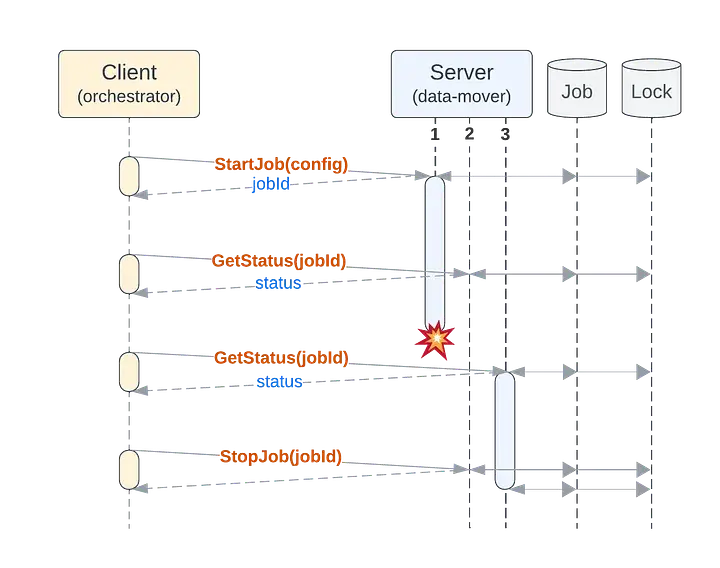
工作完成了嗎?
嗯,我們正在接近目標,不過仍有一些問題需要解決。
懸置任務:如果不介意在客户端離開後讓任務繼續運行一段時間的話,這個問題其實並不難解決。我們決定只有在客户端要求查看任務狀態時才執行非活躍任務。如果客户端不再調用 GetStatus 函數,當前容器仍會繼續運行該任務,直到容器終止,但此後該任務將不再執行。
重複任務:如果客户端創建了一個任務,但由於出現錯誤導致無法處理響應,那麼就會產生一個立即失效的任務。我們不會永遠在它上面浪費資源,但可能會持續執行該任務數小時之久。在處理數據方面,如果有兩個任務在處理相同的數據,還可能會導致寫入衝突和傳輸失敗。
要點:冪等性密鑰
有一種常見且非常有效的防止重複任務的方法,稱為冪等性密鑰(idempotency key)。這種技術在諸如 Stripe 和 Square 這樣的支付 API 中非常常見,因為人們傾向於每次購買只支付一次。
將此概念應用於工作流程中時,其含義是:客户端為要創建的每個工作生成一個唯一的密鑰,並將其作為 StartJob 的一部分發送。如果服務器收到兩個具有相同“冪等性密鑰”的請求,就知道客户端所指的正是同一個工作。因此,客户端可以多次調用 StartJob 操作(最多 10 次),而服務器則知道只需啓動一次即可。
這種責任分配方式十分巧妙,因為服務器和客户端各自只需實現自己的部分即可,而兩者結合在一起就能形成有效防止重複任務的可靠解決方案。
但客户端能做的遠不止這些 —— 事實證明,還可以通過利用客户端能夠輕鬆提供的特性來解決許多問題。

極其簡潔的界面
之前,我説如果任務時間很短,可能就只是一個請求而已。那麼,如果任務本身就是請求呢?這種情況存在兩個明顯問題:
- 客户端希望在任務運行期間能夠了解其狀態。
- 請求是脆弱的 —— 你不能指望單個請求能夠持續足夠長的時間來完成一項任務。
第一個問題(瞭解任務狀態)可以通過流式響應來解決。我們用 GRPC,但流式 HTTP 也能很好發揮作用。服務器可以隨時發出新的狀態信息,客户端會立即接收到。這比讓客户端定期查詢任務狀態要簡單且響應更快。
至於連接的脆弱性問題,我們的任務原本就需要具備可恢復性。因此,如果連接中斷,客户端可以發出一個新的長期有效的 RunJob 請求(使用相同的重複性密鑰和配置),而服務器則可以根據其最新狀態繼續執行該任務。
按照這種設置,以下是任務執行的流程示例(包括在不同服務器實例上重新啓動任務的情況):
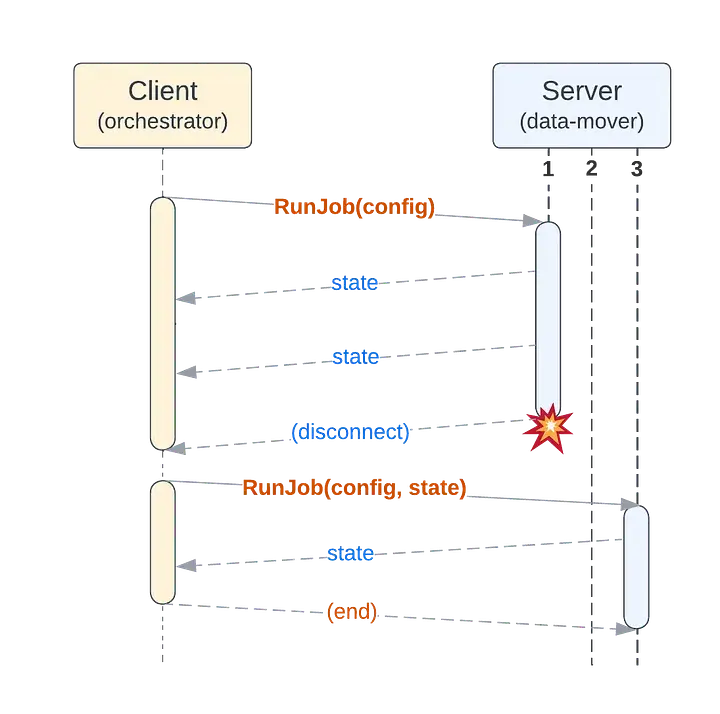
沒錯,我們移除了服務器的鎖 API 和任務存儲功能。
細心的讀者可能會懷疑我是在故意隱瞞一些情況,將這些責任轉嫁給了客户端(而客户端基礎設施並未在圖中展示)。繼續閲讀,就會明白這其實是一種有意為之的好處,而非不正當的賬目操作。
太完美了 🌅
我通常不會對序列圖產生過多的感情反應,但令人驚訝的是,這個簡單的 API 重構竟然如此完美滿足了需求。我來列舉一下其中的優點:
不存在“懸置任務”這種説法
在這種模式中,工作僅在客户主動等待時才會進行,通過保持連接處於開啓狀態來體現這一點,一旦連接斷開,工作就會停止。
這與結構化併發有着很好的相似之處,我對這種結構化併發方式非常讚賞。結構化併發通過防止異步子任務的生命週期超過其父任務來避免出現失控線程。通過保持請求處於打開狀態,迫使客户端主動等待,從而實現了與防止失控任務類似的安全保護機制。
任務分配
客户端每次僅執行一個請求。我們原本依靠分佈式鎖來確保只有一個進程執行某個特定任務。但如果工作僅在客户端有活躍請求時進行,並且客户端只有一個活躍請求,就不需要明確的分配,而只需在接收請求的實例上執行工作即可。
錯誤與重試
賬户遷移任務是耗時的,並且可能既昂貴又重要。之前的系統默認情況下較為脆弱:任何錯誤都會導致任務失敗,直到數據移動器實現可靠的錯誤重試機制(包括關於如何延長等待時間以及何時放棄的邏輯)。
通過這個接口,任何錯誤都會默認導致請求失敗。但客户端已經能夠處理失敗的請求了,可以讓客户端在何時重試以及何時放棄方面儘可能靈活自主,同時保持服務器的實現簡單。
實際上,如果一項操作被判定為重要的話,客户端會轉而向人工尋求幫助。與在出現太多錯誤後就放棄不同,客户端會停止重試,並等待人工操作員來終止或恢復該操作。同樣,這並不需要服務器提供任何特定支持。
負載均衡
這算是一個比較遙遠的目標,因為很難實現。理想情況下,如果有 10 個實例和 100 個任務,我們希望每個實例能同時處理 10 個任務。有一些簡單技巧可以實現一定程度的平衡,比如在接取未被佔用的任務之前先短暫休息一下。如果休息時間與已經運行的任務數量成正比,那麼空閒實例會比忙碌實例更頻繁的接取任務。
但當連接數量成為工作數量的可靠指標時,平衡問題就變得簡單多了,因為這就是負載均衡器所做的事情 —— Istio 的默認設置是將流量發送到請求活躍度最低的實例。這在工作完成時不會主動重新平衡工作,但除此之外,我們還能實現最優平衡,而且是免費的。
存儲狀態
這或許是我們過度依賴客户端的地方 —— 我們把狀態交給客户端,讓其自行進行存儲。
作為流式傳輸響應的一部分,我們有一個不可讀的字節字段 persist_state。收到該字段後,客户端會將其存儲在某個位置。在每次發起請求時,客户端會在 RunJob 請求中將最近存儲的狀態作為 persist_state 字段的值。
這意味着服務器可以完全實現無狀態化,這對於需要處理持久化數據的服務來説是一種奇特的特性。但這些數據屬於正在遷移的服務,不適合用作我們自己的作業存儲庫。
對我們而言,這樣做是值得的,因為我們擁有的服務器數量遠遠多於客户端數量(在未來可預見的時期內,只有一個客户端),而且一個完全無狀態的服務器所帶來的好處足以彌補讓客户端保存狀態所帶來的額外工作量。
你完全可以採納本文其餘觀點,而無需讓客户端掌控狀態。而且,除非完全信任客户端,否則切勿這樣做。我們選擇充分信任客户端,以至於會故意破壞其自身數據(例如,向我們發送虛假狀態,可能會導致跳過傳輸過程中的某些部分)。但我們不會在狀態中暴露任何與授權相關的敏感數據,以免讓客户端能夠通過其不擁有的數據存儲系統施加影響。
令人驚訝的是,對無狀態數據傳輸器的需求正是整個設計的最初動機,因為無狀態系統是降低複雜性時自然而然的想法。回過頭來看,刪除狀態存儲可能是最不重要的好處 —— 如果不必擔心所有的分佈式協調難題,寫入數據庫其實也不是那麼困難。
為什麼(以及何時)這種方法能奏效呢?
當然,這一切只有在客户端具備諸如“不會忘記處理任務”以及“每次處理一個任務時只提出一個請求”這樣的良好習慣時才會有效。這……聽起來像是作業執行器的工作嗎?
嗯,賬户管理協調器實際上就是一種被賦予了更高職責的作業執行器,其大部分工作內容包括運行各種內部作業並記錄其狀態。這裏所描述的方法並沒有消除對作業執行器的需要,但意味着可以將單一作業執行器應用於系統最外層。我們並非直接與作業系統進行集成,而是通過構建接口來利用它所提供的有用特性。
這顯然有利於簡化現有數據傳輸系統,使它們無需再負責管理任務(以及由此帶來的任何複雜性或故障)。但更重要的是那些尚未編寫的數據傳輸程序。現在,當我們需要為一家被收購公司的數據存儲系統編寫數據傳輸程序時,大部分工作僅僅是進行數據傳輸,而無需構建可靠的任務執行系統。
歡呼“耦合”吧? 🔗
人們往往會傾向於構建模塊化、解耦、獨立且具備所有那些讓人感覺良好的特質(但其實沒人應該討厭這些特質)的系統。
事實上,康威定律表明,如果將“數據傳輸器”作為獨立系統和團隊來設立,人們自然會傾向於將其構建為一個獨立系統,就像我們所做的那樣。但通過採用輕量級耦合方式,可以實現巨大的效率提升。而這種耦合方式確實是非常輕量級的,只是在客户端和服務器之間確定了一套特定的協議,從而構建出了整體上最穩固、複雜度最低的系統。
結語:“為什麼不直接使用[我最喜歡的作業系統]呢?”
由於不瞭解具體細節,或許本可以這麼做!鑑於我們的需求涉及多種不同編程語言,沒有一種系統能完全滿足需求,也沒有現成系統具備我們所需要的所有功能。我確信可以通過各種方法來實現,只需添加額外代碼來整合或增強缺失的功能即可。但有什麼比編寫一堆代碼更好的呢?那就是不做這些!
感謝閲讀!
我希望你會覺得這種針對作業系統 API 的替代方法頗具吸引力。它未必適用於每一個類似工作的系統,關鍵在於,如果從給定系統的整體環境以及其使用方式的角度去思考,有時能夠找到一種複雜程度低得多的解決方案,這確實很美妙。
你好,我是俞凡,在Motorola做過研發,現在在Mavenir做技術工作,對通信、網絡、後端架構、雲原生、DevOps、CICD、區塊鏈、AI等技術始終保持着濃厚的興趣,平時喜歡閲讀、思考,相信持續學習、終身成長,歡迎一起交流學習。為了方便大家以後能第一時間看到文章,請朋友們關注公眾號"DeepNoMind",並設個星標吧,如果能一鍵三連(轉發、點贊、在看),則能給我帶來更多的支持和動力,激勵我持續寫下去,和大家共同成長進步!
本文由mdnice多平台發佈









