

本系列介紹增強現代智能體系統可靠性的設計模式,以直觀方式逐一介紹每個概念,拆解其目的,然後實現簡單可行的版本,演示其如何融入現實世界的智能體系統。本系列一共 14 篇文章,這是第 1 篇。原文:Building the 14 Key Pillars of Agentic AI
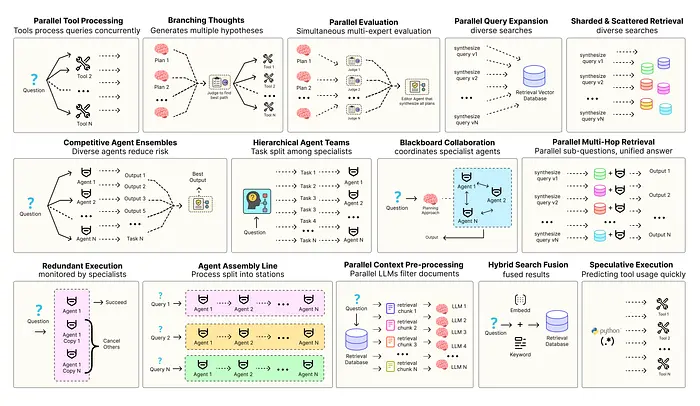
優化智能體解決方案需要軟件工程確保組件協調、並行運行並與系統高效交互。例如預測執行,會嘗試處理可預測查詢以降低時延,或者進行冗餘執行,即對同一智能體重複執行多次以防單點故障。其他增強現代智能體系統可靠性的模式包括:
- 並行工具:智能體同時執行獨立 API 調用以隱藏 I/O 時延。
- 層級智能體:管理者將任務拆分為由執行智能體處理的小步驟。
- 競爭性智能體組合:多個智能體提出答案,系統選出最佳。
- 冗餘執行:即兩個或多個智能體解決同一任務以檢測錯誤並提高可靠性。
- 並行檢索和混合檢索:多種檢索策略協同運行以提升上下文質量。
- 多跳檢索:智能體通過迭代檢索步驟收集更深入、更相關的信息。
還有很多其他模式。
本系列將實現最常用智能體模式背後的基礎概念,以直觀方式逐一介紹每個概念,拆解其目的,然後實現簡單可行的版本,演示其如何融入現實世界的智能體系統。
所有理論和代碼都在 GitHub 倉庫裏:🤖 Agentic Parallelism: A Practical Guide 🚀
代碼庫組織如下:
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb並行工具隱藏 I/O 時延
智能體系統中最主要且最常見的瓶頸(許多開發者已經知道,但我認為對初學者來説很重要)不是 LLM 思考時間,而是 I/O 時延……即等待網絡、數據庫和外部 API 響應的時間。

當代理需要從多個來源收集信息時,例如查詢股價和搜索最新新聞,天真、順序的方法會依次執行調用,效率低下。如果都是獨立調用,沒有理由不同時執行。
我們現在構建一個智能體系統,學習該模式在哪種情況下以及如何使用最有效。該系統會接收用户查詢,識別需要調用兩個不同的實時 API,並並行執行。
首先需要創造一些真實的工具,利用 yfinance 庫獲取實時股票價格數據。
from langchain_core.tools import tool
import yfinance as yf
@tool
def get_stock_price(symbol: str) -> float:
"""Get the current stock price for a given stock symbol using Yahoo Finance."""
# 添加一條 print 語句,以清楚指示何時執行此工具
print(f"--- [Tool Call] Executing get_stock_price for symbol: {symbol} ---")
# 實例化 yfinance Ticker 對象
ticker = yf.Ticker(symbol)
# 獲取股票信息,用 'regularMarketPrice' 增強可靠性,並帶有回退
price = ticker.info.get('regularMarketPrice', ticker.info.get('currentPrice'))
# 處理股票代碼無效或數據不可用的情況
if price is None:
return f"Could not find price for symbol {symbol}"
return priceLangChain 的 @tool 將標準 Python 函數裝飾為工具提供給代理,從而獲取給定股票代碼的市價。
快速測試一下,確保正確連接到了實時 API。
get_stock_price.invoke({"symbol": "NVDA"})
#### 輸出 ####
--- [Tool Call] Executing get_stock_price for symbol: NVDA ---
121.79 ...可以看到輸出確認工具連接正確,可以訪問外部 yfinance API。如果失敗,就需要檢查網絡連接或 yfinance 安裝情況。
接下來將創建第二個用於獲取最新公司新聞的工具,使用針對基於 LLM 的代理優化的 Tavily 搜索 API。
from langchain_community.tools.tavily_search import TavilySearchResults
# 首先,初始化基本 Tavily 搜索工具
# 'max_results=5' 將限制搜索前 5 個最相關文章
tavily_search = TavilySearchResults(max_results=5)
@tool
def get_recent_company_news(company_name: str) -> list:
"""Get recent news articles and summaries for a given company name using the Tavily search engine."""
# 添加 print 語句,以便清楚記錄工具的執行情況
print(f"--- [Tool Call] Executing get_recent_company_news for: {company_name} ---")
# 為搜索引擎構造更具體的查詢
query = f"latest news about {company_name}"
# 調用底層 Tavily 工具
return tavily_search.invoke(query)這裏把基礎工具 TavilySearchResults 封裝在自定義 @tool 函數裏,目的是獲取用户查詢的最新新聞。
測試一下這個工具……
get_recent_company_news.invoke({"company_name": "NVIDIA"})
#### 輸出 ####
--- [Tool Call] Executing get_recent_company_news for: NVIDIA ---
[{'url': 'https://www.reuters.com/technology/nvidia-briefly-surpasses-microsoft-most-valuable-company-2024-06-18/', 'content': 'Nvidia briefly overtakes Microsoft as most valuable company...'}, ...]輸出是一份近期新聞列表,證實第二個工具也正常工作,我們的代理現在具備兩種不同的真實世界數據收集能力。
為了正確衡量效率提升,需要整理工作流,更新圖狀態,加入用於記錄性能指標的字段。
from typing import TypedDict, Annotated, List
from langchain_core.messages import BaseMessage
import operator
class AgentState(TypedDict):
# 'messages' 將保存對話歷史
messages: Annotated[List[BaseMessage], operator.add]
# 'performance_log' 將累積詳細説明每個步驟執行時間的字符串
# 'operator.add' 歸約函數告訴 LangGraph 追加列表而非替換
performance_log: Annotated[List[str], operator.add]AgentState 是智能體運行的黑匣子錄音機,通過添加帶有 Annotated operator.add 歸約函數的 performance_log 字段創建持久化日誌,圖中的每個節點都會更新該日誌,為我們提供分析總執行時間和各階段耗時所需的原始數據。
現在創建第一個儀表化節點,調用 LLM 的代理大腦。
import time
def call_model(state: AgentState):
"""The agent node: calls the LLM, measures its own execution time, and logs the result to the state."""
print("--- AGENT: Invoking LLM --- ")
start_time = time.time()
# 從狀態中獲取當前消息歷史
messages = state['messages']
# 調用工具感知 LLM,LLM 將決定是否可以直接回答或需要調用工具
response = llm_with_tools.invoke(messages)
end_time = time.time()
execution_time = end_time - start_time
# 用性能數據創建日誌條目
log_entry = f"[AGENT] LLM call took {execution_time:.2f} seconds."
print(log_entry)
# 返回 LLM 響應和要添加到狀態的新日誌條目
return {
"messages": [response],
"performance_log": [log_entry]
}call_model 函數是我們第一個儀表化圖節點,用帶 time.time() 的 llm_with_tools.invoke() 封裝調用,精確測量 LLM 的思考時間,並將測量數據格式化為人類可讀的字符串,作為狀態更新的一部分返回。
接下來創建用於執行工具的儀表化節點。
from langchain_core.messages import ToolMessage
from langgraph.prebuilt import ToolExecutor
# ToolExecutor 是一個 LangGraph 工具,可以獲取一組工具列表並執行
tool_executor = ToolExecutor(tools)
def call_tool(state: AgentState):
"""The tool node: executes the tool calls planned by the LLM, measures performance, and logs the results."""
print("--- TOOLS: Executing tool calls --- ")
start_time = time.time()
# 來自代理的最後一條消息將包含工具調用
last_message = state['messages'][-1]
tool_invocations = last_message.tool_calls
# ToolExecutor 可以批量執行工具調用,對於同步工具,底層仍然是順序的,
# 但這是一種管理執行的乾淨方式
responses = tool_executor.batch(tool_invocations)
end_time = time.time()
execution_time = end_time - start_time
# 為工具執行階段創建日誌條目
log_entry = f"[TOOLS] Executed {len(tool_invocations)} tools in {execution_time:.2f} seconds."
print(log_entry)
# 將工具響應格式化為 ToolMessages,這是 LangGraph 期望的標準格式
tool_messages = [
ToolMessage(content=str(response), tool_call_id=call['id'])
for call, response in zip(tool_invocations, responses)
]
# 返回工具消息和性能日誌
return {
"messages": tool_messages,
"performance_log": [log_entry]
}類似於 call_model 節點,將核心邏輯 tool_executor.batch(tool_invocations) 封裝在計時儀表中,通過記錄執行 batch 的總時間,可以稍後和模擬順序執行比較,以量化並行的好處。
定義好儀表節點後,可以將它們接線成 StateGraph。
from langgraph.graph import END, StateGraph
# 此函數作為條件邊,根據代理的最後一條消息路由工作流
def should_continue(state: AgentState) -> str:
last_message = state['messages'][-1]
# 如果最後一條消息包含工具調用,路由到 'tools' 節點
if last_message.tool_calls:
return "tools"
# 否則,智能體已經完成推理,結束執行圖
return END
# 定義圖工作流
workflow = StateGraph(AgentState)
# 添加儀表節點
workflow.add_node("agent", call_model)
workflow.add_node("tools", call_tool)
# 入口點是 'agent' 節點
workflow.set_entry_point("agent")
# 為路由添加條件邊
workflow.add_conditional_edges("agent", should_continue, {"tools": "tools", END: END})
# 添加從工具回到代理的邊
workflow.add_edge("tools", "agent")
# 編譯成可執行應用程序
app = workflow.compile()
我們定義了一個簡單的循環:
agent思考should_continue邊檢查是否需要行動,如果需要,tools節點會行動,然後流返回agent節點處理其動作的結果。compile()方法將該抽象定義轉化為具體、可執行的對象。
接下來給代理一個查詢,要求它同時使用兩個工具並進行流式執行,並在每一步檢查狀態。
from langchain_core.messages import HumanMessage
import json
# 圖的初始輸入,包括用户查詢
inputs = {
"messages": [HumanMessage(content="What is the current stock price of NVIDIA (NVDA) and what is the latest news about the company?")],
"performance_log": []
}
step_counter = 1
final_state = None
# 用 .Stream() 使用 stream_mode='values' 獲取每個節點運行後的完整狀態字典
for output in app.stream(inputs, stream_mode="values"):
# 輸出字典的鍵是剛剛運行的節點名稱
node_name = list(output.keys())[0]
print(f"\n{'*' * 100}")
print(f"**Step {step_counter}: {node_name.capitalize()} Node Execution**")
print(f"{'*' * 100}")
# 打印狀態,以便詳細檢查
state_for_printing = output[node_name].copy()
if 'messages' in state_for_printing:
# 將消息對象轉換為更可讀的字符串表示形式
state_for_pr...tty_repr() for msg in state_for_printing['messages']]
print("\nCurrent State:")
print(json.dumps(state_for_printing, indent=4))
# 為每一步添加分析
print(f"\n{'-' * 100}")
print("State Analysis:")
if node_name == "agent":
# 檢查代理響應是否包含工具調用
if "tool_calls" in state_for_printing['messages'][-1]:
print("The agent has processed the input. The LLM correctly planned parallel tool calls. The execution time of the LLM call has been logged.")
else:
print("The agent has received the tool results and synthesized them into a coherent, final answer. The performance log now contains the full history.")
elif node_name == "tools":
print("The tool executor received the tool calls and executed them. The results are now in the state as ToolMessages. The performance log is accumulating.")
print(f"{'-' * 100}")
step_counter += 1
final_state = output[node_name]執行查詢,看看並行模擬是如何工作的……
#### 輸出 ####
****************************************************************************************************
**Step 1: Agent Node Execution**
****************************************************************************************************
--- AGENT: Invoking LLM ---
[AGENT] LLM call took 4.12 seconds.
Current State:
{
"messages": [
"HumanMessage(content='What is the current stock price of NVIDIA (NVDA) and what is the latest news about the company?')",
"AIMessage(content='', tool_calls=[{'name': 'get_stock_price', 'args': {'symbol': 'NVDA'}, 'id': '...'}, {'name': 'get_recent_company_news', 'args': {'company_name': 'NVIDIA'}, 'id': '...'}])"
],
"performance_log": [ "[AGENT] LLM call took 4.12 seconds." ]
}
----------------------------------------------------------------------------------------------------
State Analysis:
The agent has processed the input. The LLM correctly planned parallel tool calls. The execution time of the LLM call has be...------------------------------
****************************************************************************************************
**Step 2: Tools Node Execution**
****************************************************************************************************
--- TOOLS: Executing tool calls ---
--- [Tool Call] Executing get_stock_price for symbol: NVDA ---
--- [Tool Call] Executing get_recent_company_news for: NVIDIA ---
[TOOLS] Executed 2 tools in 2.31 seconds.
Current State:
{
"messages": [ ... ],
"performance_log": [ "[AGENT] LLM call took 4.12 seconds.", "[TOOLS] Executed 2 tools in 2.31 seconds." ]
}
----------------------------------------------------------------------------------------------------
State Analysis:
The tool executor received the tool calls and executed them. The results are now in the state as ToolMessages. The performance log is accumulating.
----------------------------------------------------------------------------------------------------
...流輸出提供了代理週期的逐步視圖。
- 步驟 1(代理):在
agent節點初始運行中,通過AIMessage可以看到 Llama 3 模型正確識別需要調用兩個獨立工具,get_stock_price和get_recent_company_news,並且在一次回合內完成了規劃,從而實現了並行優化計劃。 - 步驟 2(工具):
tools節點接收兩條計劃調用,日誌顯示兩條[Tool Call]打印語句,確認被ToolExecutor同時執行。性能日誌條目[TOOLS] Executed 2 tools in 2.31 seconds是關鍵數據。 - 步驟 3(代理):最後一步,代理收到
ToolMessage結果並綜合生成最終答案。
現在進行最終定量證明,分析完整性能日誌,計算節省的時間。
print("Run Log:")
total_time = 0
tool_time = 0
for log in final_state['performance_log']:
print(f" - {log}")
# 從日誌字符串中提取時間值
time_val = float(log.split(' ')[-2])
total_time += time_val
if "[TOOLS]" in log:
tool_time = time_val
print("\n" + "-"*60 + "\n")
print(f"Total Execution Time: {total_time:.2f} seconds\n")
print("Analysis:")可以看到並行處理解決了時延問題……
#### 輸出 ####
============================================================
FINAL PERFORMANCE REPORT
============================================================
Run Log:
- [AGENT] LLM call took 4.12 seconds.
- [TOOLS] Executed 2 tools in 2.31 seconds.
- [AGENT] LLM call took 5.23 seconds.
------------------------------------------------------------
Total Execution Time: 11.66 seconds工具執行總時間為 2.31s,假設每個網絡調用耗時約 1.5s,順序執行需時約 3.0s(1.5s + 1.5s)。
併發執行節省了約 0.7s,增益看起來很小,但在一個有 5-10 個獨立工具調用、每次需要 2-3s 的複雜系統中,差別會更大。順序過程需 10-30s,而並行過程仍只需 2-3s,這就是可用系統和不可用系統的區別。
Hi,我是俞凡,一名兼具技術深度與管理視野的技術管理者。曾就職於 Motorola,現任職於 Mavenir,多年帶領技術團隊,聚焦後端架構與雲原生,持續關注 AI 等前沿方向,也關注人的成長,篤信持續學習的力量。在這裏,我會分享技術實踐與思考。歡迎關注公眾號「DeepNoMind」,星標不迷路。也歡迎訪問獨立站 www.DeepNoMind.com,一起交流成長。
本文由mdnice多平台發佈