

[TOC]
正則表達式與文本搜索
元字符
.匹配任意單個字符(單行模式下不匹配換行符)*匹配前一個字符任意次[]匹配範圍內任意一個字符^匹配開頭$匹配結尾\轉義後面的特殊字符
擴展元字符
+先前的項可以匹配一次或多次。?先前的項是可選的,最多匹配一次。|匹配前面或後面的正則表達式, "或"()分組
重複
一個正則表達式後面可以跟隨多種重複操作符之一。
{n} 先前的項將匹配恰好 n 次。
{n,} 先前的項可以匹配 n 或更多次。
{n,m} 先前的項將匹配至少 n 詞,但是不會超過 m 次
find 命令
遞歸地在目錄中查找文件
find [路徑...] 表達式
表達式
查找範圍
-maxdepth <level> # 目錄遞歸最大層數
-mindepth <level> # ?
按文件名查找
-name "模式" # 完整匹配基本的文件名, 使用"通配符"匹配基本的文件名
-regex "模式" # 完整匹配整個路徑(並非單單匹配文件名), 使用"正則"匹配基本的文件名
-iregex "模式" # 完整匹配整個路徑(並非單單匹配文件名) , 使用"正則"匹配基本的文件名, 但不區分大小寫
-regextype <reg_type> # 改變正則表達式語法, 可選: emacs (this is the default), posix-awk, posix-basic, posix-egrep and posix-extended
按文件類型查找
-type 類型 # b 塊設備, c 字符設備, d 目錄, p 命名管道, f 普通文件, l 符號鏈接, s 套接字
按時間查找
# 數字參數
# +n 在這之前的
# -n 在這之後的
# n 正好處於該時刻
-daystart # 從當日0點為基準, 而不是當前時刻, 影響下述幾種時間類型.
-atime <n> # Access, 最後訪問時間, 單位為天(但實際是以當前時間為基準)
-ctime <n> # Change, 文件i節點修改時間, 單位為天
-mtime <n> # Modify, 文件內容修改時間, 單位為天
-amin <n> # 類似 atime, 但單位是分鐘
-ctim <n> # 類似 ctime, 但單位是分鐘
-mmin <n> # 類似 mtime, 但單位是分鐘
按大小
-size <n> # 默認單位是塊(512字節), 支持 k(KB), M(MB), G(GB), 可以用 + - 或無符號, 意義同上面的按時間查找.
按歸屬
-user <user> # 按屬主
-uid <uid> # 按屬主的id
動作
-exec 操作 \; # 執行時無需確認, {} 作為轉義字符會被替換成查找的文件
-ok 操作 \; # 類似 -exec, 但是每次操作都會提示確認
運算符(按優先級從高到低排序)
() # 強制優先
! <表達式> # 邏輯非, 對<表達式>結果取反, 即不匹配後面條件, 比如 ! -name 表示不匹配指定文件名
-not <表達式> # 邏輯非, 同 ! <表達式>
<表達式1> <表達式2> # 邏輯與(默認), 如果前一個<表達式>執行結果為false, 則不會執行後續<表達式>
<表達式1> -a <表達式2> # 邏輯與, 同上
<表達式1> -and <表達式2> # 邏輯與, 同上
<表達式1> -o <表達式2> # 邏輯或
<表達式1> -or <表達式2> # 邏輯或
<表達式1> , <表達式2> # 前一個表達式的結果不影響後一個表達式的執行
cat僅會修改 access 時間
touch會同時修改 access, modify, change
chmod僅會修改 change 時間
注意:
- 不同參數的前後順序很重要, 比如
-daystart需要寫在-atime等之前, 否則對其不生效.
示例
# 僅刪除昨天的日誌
find /path/to/log -daystart -mtime 1 -exec rm -v {} \;grep 命令
文本內容過濾(查找)
查找文本中具有關鍵字的一行
説明
若未提供查找的文件名或是 - 則默認是標準輸入
語法
grep [選項] 模式 文件...
grep [選項] (-e 模式 | -f 包含模式的文件) 文件...
選項
模式
-G, --basic-regexp # 使用基本正則(默認)
-E, --extended-regexp # 使用擴展正則
-e 模式, --regexp=模式 # 當模式以 - 開頭時, 應使用這種方式
-v, --invert-match # 反向匹配, 只選擇不匹配的行
-i, --ignore-case # 忽略大小寫
-R, -r, --recursive # 遞歸地讀每一目錄下的所有文件。這樣做和 -d recurse 選項等價。
顯示內容
-A <n>, --after-context=<n> # 打印匹配行的後續 n 行
-B <n>, --before-context=<n> # 打印匹配行的前面 n 行
-o, --only-matching # 只顯示匹配的部分(默認是顯示匹配行的所有內容)
-n, --line-number # 同時顯示行號
修改顯示類型, 不進行通常輸出
-c # 打印匹配到多少行
-l, --files-with-matches # 打印匹配的文件名
-L, --files-without-match # 打印不匹配的文件名
注意:
- 在輸入選項時儘量使用引號包圍, 避免Shell去解釋, 比如
grep \.實際上模式是.也就是匹配任意字符. 而grep "\."或grep '\.'才是匹配模式\.在基本正則表達式中,元字符 ?, +, {, |, (, 和 ) 喪失了它們的特殊意義;作為替代,使用加反斜槓的 (backslash) 版本 ?, +, {, |, (, 和 ) 。
cut 行切割
在文件的每一行提取片段
cut 選項 [FILE]...
選項
-d, --delimiter <分隔> # 以指定分隔符來切割, 分隔符必須是單個字符
-f, --fields <list> # 輸出指定位置的字段, 用逗號分隔多個位置, 位置從1開始uniq 連續重複行處理
刪除排序文件中的"連續"重複行
默認從標準輸入讀取, 輸出到標準輸出
uniq 選項 [INPUT [OUTPUT]]
選項
-c, --count # 在首列顯示重複數量
-d, --repeated # 僅顯示重複的行sort 排序
對文本文件的行排序
sort 選項 [FILE]...
選項
字段類型
-n # 按照數值排序, 默認包含 -b
-k #
-r # 逆向排序
-b # 忽略開頭的空格seq 產生數字序列
產生數字序列
語法
seq [OPTION]... LAST
seq [OPTION]... FIRST LAST
seq [OPTION]... FIRST INCREMENT LASTtac 倒序顯示
tac [選項] <文件=STDIN>行編輯器
非交互式, 基於行操作的模式編輯.
sed 行編輯器
sed 是單行文本編輯器, 非交互式.
sed 的模式空間, 其基本工作方式
- 將文件以行為單位讀取到內存(稱作模式空間)
- 使用sed的每個腳本依次對該行進行操作
- 打印模式空間的內容並清空
- 讀取下一行, 重複執行上述步驟
sed 的空間示意圖:

- 模式空間的內容默認會輸出, 並清空
- 保持空間的默認內容是
\n
Tip
- 使用
;可以替換多個-e
模式空間 pattern space
s 替換命令
替換
sed [選項] '[<尋址>]s<分隔符><old><分隔符><new><分隔符>[<標誌位>]' [文件...] # 簡單示例: sed 's/old/new/'
參數
old # 支持正則表達式
分隔符 # 可以採用 / 也可以採用其他來避免與正則匹配內容衝突, 比如 ~ @ 等
尋址(默認是所有行)
! # 對尋址取反, eg. "2,4!d" 表示不刪除2~4行
<n> # 只替換第<n>行
<n1>,<n2> # 區間: 從<n1>到<n2>這幾行 eg. /12\/Apr\/2020/,/13\/Apr\/2020/ 正則同樣可以使用這種區間尋址
1,<n> # 替換從開始到第<n>行
<n>,$ # 替換從第<n>到結束的這些行
/正則/ # 僅替換符合此正則匹配到的行
# eg. sed '/正則/s/old/new/'
# eg. sed '/正則/,$s/old/new/' (正則可以和行號混用)表示從匹配到的正則那行開始到結束都替換
# 尋址可以匹配多條命令, 注意大括號. eg. /regular/{s/old/new/;s/old/new/}
# 比如nginx日誌需要篩選出 14號這天的: sed -n '/14\/Apr\/2020/,/15\/Apr\/2020/ p' xx.log
標誌位(默認是隻替換第1個匹配項)
/g # 替換所有匹配項(默認只替換第1個匹配項)
/<n> # <n>是一個數字, 表示每行只替換第<n>個匹配項
/p # 打印模式空間的內容(即匹配的行), 通常會和 -n 一起使用, 如果不和 -n 一起使用, 會導致匹配的行多輸出依次.
# eg. sed -n 's/old/new/p' # 此時僅打印匹配的行
/w <file> # 將模式空間的內容(即匹配到的行)寫入到指定文件
選項
-r, --regexp-extended # 使用擴展正則表達式, 包括圓括號分組及回調.
-e script, --expression=script # 指定多個執行腳本時, 每個腳本前用一個 -e. 可以使用 "分號" 簡寫
# Eg. -e 's/old1/new1/' -e 's/old2/new2/'
-f script-file, --file=script-file # 加載腳本文件
-i[<後綴>], --in-place[=<後綴>] # 修改原始文件, 當指定後綴時則會生成對應的備份文件. 也可以直接輸出重定向輸出到其他文件
-n, --quiet, --silent # 默認不自動打印
示例
# 使用擴展正則表達式
sed -r 's/old/new/' [文件]...
# 執行多個腳本
sed -e 's/old/new/' -e 's/old/new/' [文件]...
sed 's/old/new/;s/old/new/' # 使用分號隔開不同腳本
# 將結果寫回文件保存
sed -i 's/'
sed -i,.bak 's/'
# 圓括號分組及回調
echo "a213123t" | sed -r 's/a(\d*)/b\1/g' # b213123td 刪除命令
刪除當前"模式空間的內容", 並放棄後面的命令, 讀取新的內容並重新執行sed
改變腳本的控制流, 讀取新的輸入行
(由於模式空間的內容被刪除了, 因此d後面的腳本沒法執行, 會略過)
(使用 s 替換成空內容, 但本質上這一行內容還在, 依舊會執行後續腳本, 會輸出)
sed '[<尋址>]d' [文件...]
尋址
同 s 命令
示例
sed '1d' # 刪除第一行
sed '/^\s*#/d' # 刪除 # 開頭的行a 追加命令
在匹配行的下一行插入內容
sed '[<尋址>]a <插入內容>'
示例
sed '1i haha' # 在原先第1行前面插入 hahai 插入命令
在匹配行在上一行插入內容
sed '[<尋址>]i <插入內容>'
示例
sed '2i haha' # 在原先第二行前面插入 hahac 改寫命令
將匹配行替換成指定內容
指定匹配連續幾行時, 只會替換1次 # sed '2,5c <替換內容>'
sed '[<尋址>]c <替換內容>'
示例
sed '2c hehe' # 將第2行替換成 "hehe"r 讀文件並插入 (從文件讀取改寫內容)
在匹配行下面分別插入指定文件中的內容
sed '[<尋址>]r <文件名>'
示例
sed '$r afile' bfile > cfile # 將 afile 內容追加到 bfile 結尾併合併成新的文件 cfile常用於合併多個文件
w 寫文件 ?
?
sed '[<尋址>]w <文件名>'p 打印
與 替換命令 s 的標誌位 /p 不一樣.
輸出匹配的行(不禁止原始的輸出)
sed [選項] '[<尋址>]p'
示例
sed -n '<尋址>p' # 只打印匹配的行n 提前讀入下一行, 並指向下一行
sed 'n'
示例
cat <<EOF | sed 'n'
1
2
3
4
5
EOF
# 輸出(由於未作任何操作, 因此原樣輸出)
1
2
3
4
5
# ----------------------
cat <<EOF | sed -n 'n;p'
1
2
3
4
5
EOF
# 輸出
2
4正常模式

使用n命令後

圖來源: https://blog.51cto.com/studyi...
q 退出命令
遇到匹配項, 在處理完該項後退出
sed '[<尋址>]q'
示例
sed '2q' # 在打印完第二行後退出
sed '/root/q' # 在匹配到某一行有 root 後退出打印前N行的一個比較
sed 10q filename讀取前10行就退出sed -n '1,10p' filename逐行讀入全部, 只顯示1-10行, 更耗時.
= 打印行號
打印出當前行號(單行顯示)
不影響正常的打印
sed '='
示例
echo 'a' | sed '=' # 打印結果, 第一行 "1", 第二行 "a"多行模式空間 pattern space
多行模式空間改變了 sed 的基本流程, 通過使用 N, P, D 讀入並處理多行.
主要應對配置文件是多行的情況, 比如 json 或 xml.
綜合示例
a.txt 內容如下
1
2
3
4
5
6
7
8
9
# ------------------- 示例1 ---------------------#
sed 'N;N;s/\n/\t/g;' a.txt
1 2 3
4 5 6
7 8 9
# ---------------------示例2 打印梯形結構 -------------------#
# 關鍵在於利用 D 改變控制流
sed -n 'P;N;s/\n/\t/;s/^/\n/;D' a.txt
1
1 2
1 2 3
1 2 3 4
1 2 3 4 5
1 2 3 4 5 6
1 2 3 4 5 6 7
1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8 9b.txt 內容如下
hell
o bash hel
lo bash
# -------------------- 示例 hello bash 替換成 hello sed --------------#
sed 's/^\s*//;N;s/\n//;s/hello bash/hello sed\n/;P;D;' b.txt
hello sed
hello sedN 將下一行加入到模式空間
讀取時, 將下一行加入到模式空間
兩行視為同一行, 但中間有個換行符 \n
此時多行模式 . 可以匹配到除了末尾的其他換行符
sed 'N'
示例
sed = <文件> | sed 'N;s/\n/\t/' # 在每行前面加入行號使用N命令後

圖來源: https://blog.51cto.com/studyi...
D 刪除模式空間中的第一個字符到第一個換行符
注意
會改變控制流, 不再執行緊隨的後續命令, 會再次回到腳本的初始處(但不清空模式空間)
sed 'D'P 打印模式空間中的第一個字符到第一個換行符
注意
僅僅是打印, 並不會刪除打印的部分.
sed 'P'保持空間 hold space
注意:
-
保持空間在不存儲東西時, 它裏面的默認內容是
\n因此第一次一般是用
h覆蓋掉保持空間的\n - 保持空間的內容只能臨時存儲和取出, 無法直接修改
綜合示例
# 下述多個都實現了 tac 倒序顯示的效果
# 思路: 每次將本輪正確的結果保存在保持空間
cat -n /etc/passwd | head -n 6 | sed -n '1!G;$!x;$p'
cat -n /etc/passwd | head -n 6 | sed -n '1!G;h;$p'
cat -n /etc/passwd | head -n 6 | sed '1!G;h;$!d'
cat -n /etc/passwd | head -n 6 | sed '1!G;$!x;$!d'
cat -n /etc/passwd | head -n 6 | sed -n '1h;1d;G;h;$p';
cat -n /etc/passwd | head -n 6 | sed -n '1h;1!G;h;$p';
sed '=;6q' /etc/passwd | sed 'N;s/\n/\t/;1!G;h;$!d'
# --------------------- 顯示結果 --------------------#
6 sync:x:5:0:sync:/sbin:/bin/sync
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
2 bin:x:1:1:bin:/bin:/sbin/nologin
1 root:x:0:0:root:/root:/bin/bashh 和 H 將模式空間內容存放到保持空間
- h 是覆蓋
- H 是追加
注意: 該操作不會清空模式空間(需要清空模式空間可以用 d)
g 和 G 將保持空間內容取出到模式空間
- g 是覆蓋
- G 是追加
注意: 該操作不會清空保持空間
x 交換模式空間和保持空間內容
awk 行編輯器
awk 是一種解釋型編碼語言, 常用於處理文本數據.
awk 主要是對 sed 的一個補充, 常用於在sed處理完後對相應結果進行調整並輸出.
awk 版本
- awk: 初始版本
- nawk: new awk, 是 awk 的改進增強版
-
gawk: GNU awk, 所有 GNU/Linux 發行版都包含 gawk, 且完全兼容 awk 與 nawk
實際 centos 用的就是 gawk
參考文檔:
- The GNU Awk User's Guide
網上很多教程瞎JB寫, 建議以官方文檔👆 為準
- 精通awk系列
非常不錯的系列教程! :+1:
- https://awk.readthedocs.io/en...
不完整.
awk 和 sed 的區別
- awk 更像是腳本語言
- awk 用於"比較規範"的文本處理, 用於統計數量並調整順序, 輸出指定字段.
- 使用 sed 將不規範的文本處理為"比較規範"的文本
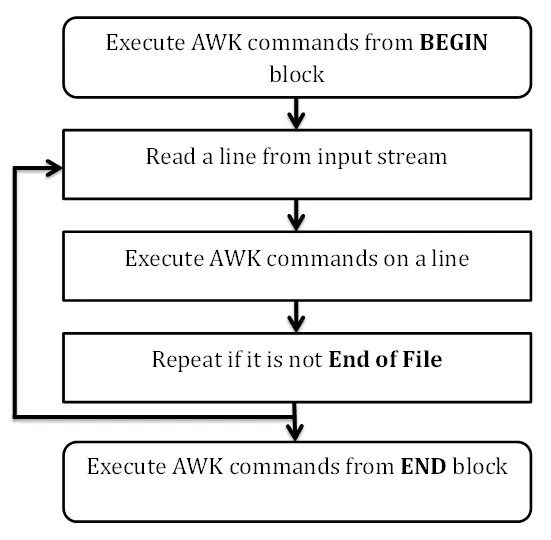
awk 腳本的流程控制
BEGIN{}輸入數據前例程, 可選{}主輸入循環END{}所有文件讀取完成例程
個人理解的執行順序
- 執行開始塊(可選)
BEGIN{} -
若存在主體塊 {}
或結束塊END{}`, 則打開文件並讀入數據如果文件無法打開會在此時報錯.
主體塊允許存在多個, 比如根據不同的匹配模式, 寫多個主體塊.
- 若存在
<尋址>或/pattern/, 則會依次匹配, 通過則對該記錄執行{} - 讀完所有記錄後, 執行結束塊(可選)
END{}
特殊情況, 腳本只包含 BEGIN{} 時, 在執行 awk 命令後面傳入參數(非文件名), 此時不會導致報錯, 因為不會執行到步驟2(即嘗試打開文件).
如果腳本只包含 BEGIN{命令} , 好像可以縮寫成 awk '命令' ??
語法
語法
awk [選項] 'awk腳本內容' [ -- ] [文件...] # 其中任意一部分都是可選的
awk [選項] -f <awk腳本文件> [ -- ] [文件...] # 不直接在命令行中書寫 awk 腳本, 而是從指定文件讀取
選項
-f <腳本文件>, --file=<腳本文件> # 從指定腳本文件讀取 awk 腳本, 而不是默認地從第一個命令行參數讀取.
-F, --field-separator <分隔符> # 字段分隔符可以使用正則表達式, 是空格 " ", 也可以在awk腳本中用 FS="," 來修改這一行為
-v <var>="val", --assign <var>="val" # 直接為awk腳本中的變量賦值, 比如 -v suffix=yjx, 然後代碼中直接就存在 suffix 這個變量了, 且值是 yjx
--dump-variables[=<file="awkvars.out">] # 將awk中的所有全局變量及其值導出到指定文件中.
awk腳本的塊
開始塊
BEGIN {} # 特殊模式: 讀取輸入數據前
主體塊
表達式 {} # 若匹配上才執行後續的 action
# eg.
# `$1 == "top" {}`
# `NR >= 2 {}`
# 'length($0)'
/正則/ {} # 正則匹配, 若匹配上才執行後續的 action
# eg.
# /^menu/ 只處理 menu 開頭的記錄
# /cost/ 只處理本行內容中包含 "cost" 的記錄
!/正則/ {} # 正則不匹配
組合模式 {} # 一個 組合模式 通過與(&&),或(||),非(|),以及括弧來組合多個表達式
{} # 每讀取一行數據則執行後續的 action
模式1,模式2 {} # 範圍模式(range pattern)匹配從與 模式1 相匹配的行到與 模式2 相匹配的行(包含該行)之間的所有行,對於這些輸入行,執行 語句 。
結束塊
END {} # 特殊模式: 讀取完畢後
主體塊的action
print 打印(若未配置則默認是 print)
next 對於本行的處理, 跳過後續步驟表達式
{...} 執行 {} 中的腳本
示例.
awk [選項] 'BEGIN{} [<條件>] {} END{}' 文件... # 其中任意一部分都是可選的
# BEGIN{} 輸入數據前例程
# {} 主輸入循環, <尋址> 是應用於 {} 的
# END{} 所有文件讀取完成例程
awk -f <腳本.awk> # 從文件中加載執行的命令, 注意<尋址>要和 { 寫在同一行, 不然好像沒生效?
# 示例 xx.awk
# BEGIN {
# ...
# }
# /過濾條件/ {
# ...
# }
# END {
# ...
# }
字段引用
$0 # 表示記錄整行
$1 $2 ... $n # 表示第1~第n個字段
NF # 標識 $0 被分割的字段數
$NF # 表示最後一個字段, NF 變量表示字段的數量, 比如當前共5個字段, 則 $NF 等價於 $5.
簡單示例
awk -F ',' '{print $1,$2,$3}' filename # 逗號分隔, 打印前3個字段
echo "menuentry 'CentOS Linux (5.5.6) 7 (Core)' --class centos" | awk -F "'" '{print $2}' # 提取出內核版本修改字段或NF值的聯動效應
注意以下幾種操作
- 修改
$0會根據FS, 重新劃分字段並自動賦值給$1,$2, ... ,NF.$0=$0也會觸發重新劃分字段的操作. -
修改
$1,$2, ... , 會根據OFS重新生成$0, 但不會重新分割.即使是
$1=$1也會觸發上述操作, 當然是用NF=NF也是可以的.# 利用該特性重新生成去除行首行尾空格, 壓縮中間空格的效果 echo " a b c " | awk '{NF=NF; print $0;}' 輸出 a b c - 賦值給不存在的字段, 會新增字段並按需使用空字符串填充中間的字段,並使用
OFS重新計算$0 - 增加
NF值,將使用空字符串新增字段,並使用OFS重新計算$0 - 減少
NF值,將丟棄一定數量的尾部字段,並使用OFS重新計算$0
正則字面量
這裏有個地方容易被坑到!!!
任何單獨出現的 /pattern/ 都等價於 $0 ~ /pattern/, 這個在將正則表達式賦值給變量時特別容易被坑, 舉例:
if(/pattern/)等價於if($0 ~ /pattern/)a = /pattern/等價於將$0 ~ /pattern/的匹配返回值(0或1)賦值給 a/pattern/ ~ $1等價於$0 ~ /pattern/ ~ $1,表示用$1去匹配0或1/pattern/作為參數傳給函數時,傳遞的是$0~/pattern/的結果0或1
匹配成功時返回1, 失敗返回0.
舉例
# 這邊直接用於匹配沒什麼問題
awk 'BEGIN { if ("abc" ~ "^[a-z]+$") { print "match"} }'
#輸出
match
awk 'BEGIN { if ("abc" ~ /^[a-z]+$/) { print "match"} }'
#輸出
match
# 這邊將其賦值給其他變量, 此時其實 regex = $0 ~ /^[a-z]+$/, 也就是值 0
awk 'BEGIN { regex=/^[a-z]+$/; print regex; if ("abc" ~ regex) { print "match"} }'
#輸出
0
awk 'BEGIN { regex="^[a-z]+$"; print regex; if ("abc" ~ regex) { print "match"} }'
#輸出
^[a-z]+$
match在 awk 中書寫正則可以用 /[0-9]+/ 也可以用
/[0-9]+/
匹配方式:"str" ~ /pattern/或"str" !~ /pattern/
匹配結果返回值為0(匹配失敗)或1(匹配成功)
任何單獨出現的/pattern/都等價於$0 ~ /pattern/
if(/pattern/)等價於if($0 ~ /pattern/)
坑1:a=/pattern/等價於將$0 ~ /pattern/的匹配返回值(0或1)賦值給a
坑2:/pattern/ ~ $1等價於$0 ~ /pattern/ ~ $1,表示用$1去匹配0或1
坑3:/pattern/作為參數傳給函數時,傳遞的是$0~/pat/的結果0或1
坑4.坑5.坑6…
內置變量
awk 中可以看作是在一個獨立的系統空間中, 因此也有其特殊的系統變量.
注意:
- 字段的引用不能加
$, 這點與Shell不一樣, 不然就變成獲取記錄中某個字段的值了.
控制 AWK 工作的預定義變量
-
FS(field separator)輸入數據的分隔符, 默認值是空格awk -F "," # 等價於 awk 'BEGIN {FS=","}' # 在讀入文件之前設置字段分隔符 -
OFS(output field separator)輸出字段分隔符(默認是空格)awk 'BEGIN {OFS=","}' FIELDWIDTHS以指定寬度切割字段而非按照 FS-
FPAT以正則匹配, 將匹配到的結果作為字段, 而非按照 FS 或 FIELDWIDTHS 劃分. 理解為 re_match, 而不是 re_splitFPAT = "([^,]+)|(\"[^\"]+\")" # 上述 FPAT 用於分割以逗號分隔的 csv 文件, 若使用雙引號包裹的則視為是一個字段(忽略其中的逗號). # 比如對於數據: abc,"pqr,mno" # $1 值為 abc # $2 值為 "pqr,mno"https://stackoverflow.com/que...
-
RS(record separator)記錄分割符(默認是\n)該變量通常在 BEGIN 塊中修改, 修改該變量可以控制 awk 每次讀取的數據的範圍(默認是讀取一行), 讀取到的記錄是不包含記錄分隔符的.
- RS 設置為單個字符: 直接使用該字符來分割記錄
- RS 設置為多個字符: 視為正則(非兼容模式), 使用該正則來分割記錄.
awk 'BEGIN {RS=":"}' # 將記錄分割符設置為 : , 這樣每次遇到 : 時就視為一條記錄分別處理.
特殊讀取需求
RS="": 按段落讀取(這個特性有用)RS="\0": 一次性讀取所有數據, 但有些特殊文件包含了空字符\0RS="^$": 真正的一次性讀取所有數據, 因此^$匹配的是空文件RS="\n+": 按行讀取, 但忽略空行
-
ORS(output row separator) 輸出記錄分隔符(默認是\n)awk 'BEGIN {OFS=":"}' CONVFMT表示數據轉換為字符串的格式, 默認值是%.6gOFMT表示數值輸出的格式, 默認值是%0.6g, 標識有效位(整數部分加小數部分)最多為6.-
IGNORECASE控制是否對大小寫敏感, 當該變量設置時, 忽略大小寫. 在分割記錄時也受該變量影響.awk 'BEGIN{IGNORECASE=1} /amit/' marks.txt
攜帶信息的預定義變量
文件與行號
-
FILENAME當前被處理的文件名在
BEGIN {}塊中, 該變量是未定義的. NR(number of rows)記錄的行號會一直累加, 就算處理多個文件, 該行號也會一直累加.
FNR(file number of rows)記錄的行號(處理不同文件時會重置)當處理多個文件時, 切換到不同文件則該值會重置掉.
-
NF(number of fields)字段數量最後一個字段內容可以用 $NF 取出
-
ARGIND用於處理多個文件時, 表示當前正在處理的文件的順序(從 1 開始)awk 'ARGIND==1 {if(FNR>3)print FNR,$3 } ARGIND==2 {if(FNR>1)print FNR,$2} ARGIND==3 {if(FNR<3)print FNR,$NF}' s.log t.log s.log RT(Record Termination) 實際記錄分割符當 RS 設置為多個字符(正則)時, 在每條記錄被讀取並分割後,
RT變量會被設置為實際用於劃分記錄的字符.
命令行與環境參數
ARGC命令行位置參數個數("選項"是不包含在內的)-
ARGV命令行位置參數數組ARGV[0]值是命令名本身, 即awkARGV[1]是傳入的第1個參數- 範圍:
ARGV[0]~ARGV[ARGC - 1]
-
ENVIRON存放系統環境變量的關聯數組awk 'BEGIN{print ENVIRON["USER"]}' # 輸出: shell 變量 "USER" -
PROCINFO關聯數組, 保存進程相關的信息# 打印 awk 進程的Id awk 'BEGIN { print PROCINFO["pid"] }' ERRNO用於存儲當 getline 重定向失敗或 close 函數調用失敗時的失敗信息.
表達式
賦值操作符
-
==的左右是可以有空格的.- 字符串拼接中的空格會被忽略
Eg.
var = "hello" "world"實際上 var 值是
"helloworld", 沒有中間的空格 - 若是拼接兩個字符串變量, 則使用字符串字面量隔開即可.
s3=s1""s2
++支持前置遞增和後置遞增
--支持前置遞減增和後置遞減
+=-=*=/=%=^=
算數操作符
+-*/%^
位操作
AND按位與操作OR按位或操作XOR按位異或操作
關係操作符
<><=>===注意, 判斷兩個值是否相等要用
==, 而不是賦值運算符=!=~字符匹配正則表達式!~
布爾操作符
&&||!使用
!時注意使用括號將相關表達式括起來, 避免寫錯.
三元運算符
condition expression ? statement1 : statement2
匹配運算符
除了塊的條件匹配外, 還可以用於 if 判斷之類的.
-
~匹配指定正則表達式的, 用於主體塊的條件匹配# 僅處理包含 hello 文本的行 awk '$0 ~ "hello"' xx.txt # 注意這裏正則是用 / / 包圍起來, 而不是雙引號 awk 'BEGIN { if ("[abc]" ~ /\[.*\]/) { print "match";}}' #輸出 #match # 注意這裏用雙引號括起來時, 裏面用了雙斜槓來處理正則的 [ awk 'BEGIN { if ("[abc]" ~ "\\[abc\\]") { print "match";}}' #輸出 #match -
!~不匹配指定正則表達式的, 用於主體塊的條件匹配# 僅處理不含 hello 文本的行 awk '$0 !~ "hello"' marks.txt
條件和循環
注意:
-
表達式結果: 0為false, 1為true
這個與 Shell 是相反的.
- 影響控制的語句:
break,continue
綜合示例
cat kpi.txt
user1 70 72 74 76 74 72
user2 80 82 84 82 80 78
#-------------- 計算每行數值的總之和平均值 -----------#
awk '{total=0; avg=0; for (i=2;i<=NF;i++) {total+=$i;} avg=total/(NF-1); print $1,total,avg;}' kpi.txt
user1 438 73
user2 486 81if 條件語句
if (表達式) {
} else if (表達式) {
} else {
}
執行多條語句要用 {}, 只有一條語句時可忽略.
for 循環
for (初始值; 循環判斷條件; 累加) {
}while 循環
while (表達式) {
}do 循環
do {
} while(表達式)數組
普通數組
-
awk 的數組實際上是關聯數組, 可通過下標(數字實際上也是字符串)依次訪問
比如
arr[1]和arr["1"]實際上是對同一個 key 操作 -
支持多維數組
gawk(可以認為是 awk 的加強版, 替代版, 至少 centos 的 awk 實際就是 gawk) 支持真正意義上的多維數組.
awk 還有一種更"原始"的使用一維數組模擬多維數組的, 但在 gawk 中已經沒必要了.
# 定義
## 下標可以是數字(視為字符串)或字符串
數組名[下標] = 值
# 遍歷
for (變量 in 數組名) {
數組名[變量] # 獲取對應數組值
}
# 刪除數組
delete 數組
# 刪除數組元素
delete 數組[下標]
# 判斷數組中是否存在指定"鍵"
if (key in array)
# 判斷數組中是否不存在指定"鍵", 注意這裏額外加了一個括號, 不能省略了
if (!(key in array))命令行參數數組
ARGC命令行位置參數個數-
ARGV命令行位置參數數組ARGV[0]值是命令名本身, 即awkARGV[1]是傳入的第1個參數- 範圍:
ARGV[0]~ARGV[ARGC - 1]
示例
cat argv.awk
內容
BEGIN {
for (i=0; i<ARGC; i++) {
print ARGV[i];
}
print ARGC;
}
# --------------------------------#
awk -f argv.awk afile 11 22 33
輸出
awk # ARGV[0]
afile # ARGV[1]
11 # ARGV[2]
22 # ARGV[3]
33 # ARGV[4]
5 # ARGC
此處不會報錯是因為awk腳本中只包含 BEGIN {} 部分, 因此不會將參數視為文件名並嘗試打開.
數組函數
length(數組)獲取數組長度asort(數組a[, 數組b, ...])對數組a的值進行排序,並且會丟掉原先鍵值(重新生成數字遞增的 key 來替代), 並將結果賦予數組 b (若未傳, 則直接修改數組 a).arorti(數組a[, 數組b, ...])對數組a的鍵進行排序, 並將結果賦予數組 b (若未傳, 則直接修改數組 a).
函數
算術函數
sin()cos()atan2(y,x)exp(x)返回自然數 e 的 x 次方sqrt()平方根log(x)計算 x 的自然對數int()轉換為整數(忽略小數部分)-
rand()偽隨機數, 範圍[0,1), 默認使用srand(1)初始化隨機種子.若不使用
srand()會發現每次獲取的所謂隨機數都是一樣的.srand(); print rand(); srand([seed])重置隨機種子, 默認種子採用當前時間的 epoch 值(秒級別)
位操作函數
compl(num)` 按位求補lshift(num, offset)左移N位rshift(num, offset)右移N位
字符串函數
awk 中涉及字符索引的函數, 索引位都是從 1 開始.
注意, 不同 awk 版本, 函數參數個數是有可能不一樣的.
sprintf(format, expr1, ...)返回格式化後的字符串示例:
a = sprintf("%10s\n", "abc")length(s)返回字符串/數組的長度strtonum(str)將字符串轉換為十進制數值如果 str 以0開頭,則將其識別為8進制
如果 str 以0x或0X開頭,則將其識別為16進制
tolower(str)轉換為小寫toupper(str)轉換為大寫-
查找
index(str,substr)在目標字符串中查找子串的位置, 若返回 0 則表示不存在.-
match(string, regexp, array)字符串正則匹配, 將匹配結果保存在 arr 數組中.變量
RLENGTH表示 match 函數匹配的字符串長度.變量
RSTART表示 match 函數匹配的字符串的第一個字符的位置.awk 'BEGIN { if (match("One Two Three", "re")) { print RLENGTH } }' # 輸出 2 awk 'BEGIN { if (match("One Two Three", "Thre")) { print RSTART } }' # 輸出 9cat test # this is wang,not wan # that is chen,not che # this is chen,and wang,not wan che awk '{match($0, /.+is([^,]+).+not(.+)/, a); print a[1],a[2]}' test # wang wan # chen che # chen wan che
-
替換
gsub(regx,sub [,targe=$0])全局替換, 會直接修改原始字符串, 返回替換成功的次數.如果
target使用$0,$...等, 那麼替換成功後會使用 OFS 重新計算$0這邊
sub不支持反向引用, 只能使用&來引用匹配成功的部分sub(regx,sub [,targe=$0])只替換第一個匹配的, 會直接修改原始字符串, 返回替換成功的次數.-
gensub(regx, sub [, how [, target]])不修改原字符串, 而是返回替換後的字符串. 可以完全替代gsub和subhow: 指定替換第幾個匹配, 比如 1 表示只替換第一個匹配,g或G表示全局替換這是 gawk 提供的函數, 其中
sub支持使用\N引用分組匹配, 或&,\0來標識匹配的整個結果.awk 'BEGIN { a = "111 222" b = gensub(/(.+) (.+)/, "\\2 \\1, \\0, &", "g", a) print b }' # 輸出 222 111, 111 222, 111 222
-
截取
substr(str,pos,num=剩餘所有)從指定位置開始截取一個子串
-
分割
split(str, arr [, 正則分隔符=FS])字符串分割為數組, 並將其保存到第2個參數中, 函數返回值是分割的數patsplit(str, arr[, 正則分隔符=FPAT])使用正則捕獲匹配的字符串, 並將其保存到第2個參數中.
若不清楚的, 可以在 man awk 中搜索相應關鍵字
時間函數
systime返回當前時間戳(秒級)-
mktime("YYYY MM DD HH mm SS [DST]")根據給定的字符串格式, 返回其對應的時間戳# 格式: 年 月 日 時 分 秒 awk 'BEGIN{print mktime("2020 10 10 17 51 59")}' -
strftime([format [, timestamp[, utc-flag]]])將時間戳(默認是當前時間)轉換為字符串表示awk 'BEGIN {print strftime("Time = %Y-%m-%d %H:%M:%S")}' 輸出 Time = 2020-10-12 17:53:37SN 描述 %a 星期縮寫(Mon-Sun)。 %A 星期全稱(Monday-Sunday)。 %b 月份縮寫(Jan)。 %B 月份全稱(January)。 %c 本地日期與時間。 %C 年份中的世紀部分,其值為年份整除100。 %d 十進制日期(01-31) %D 等價於 %m/%d/%y. %e 日期,如果只有一位數字則用空格補齊 %F 等價於 %Y-%m-%d,這也是 ISO 8601 標準日期格式。 %g ISO8610 標準周所在的年份模除 100(00-99)。比如,1993 年 1 月 1 日屬於 1992 年的第 53 周。所以,雖然它是 1993 年第 1 天,但是其 ISO8601 標準周所在年份卻是 1992。同樣,儘管 1973 年 12 月 31 日屬於 1973 年但是它卻屬於 1994 年的第一週。所以 1973 年 12 月 31 日的 ISO8610 標準周所在的年是 1974 而不是 1973。 %G ISO 標準周所在年份的全稱。 %h 等價於 %b. %H 用十進制表示的 24 小時格式的小時(00-23) %I 用十進制表示的 12 小時格式的小時(00-12) %j 一年中的第幾天(001-366) %m 月份(01-12) %M 分鐘數(00-59) %n 換行符 (ASCII LF) %p 十二進制表示法(AM/PM) %r 十二進制表示法的時間(等價於 %I:%M:%S %p)。 %R 等價於 %H:%M。 %S 時間的秒數值(00-60) %t 製表符 (tab) %T 等價於 %H:%M:%S。 %u 以數字表示的星期(1-7),1 表示星期一。 %U 一年中的第幾個星期(第一個星期天作為第一週的開始),00-53 %V 一年中的第幾個星期(第一個星期一作為第一週的開始),01-53。 %w 以數字表示的星期(0-6),0表示星期日 。 %W 十進制表示的一年中的第幾個星期(第一個星期一作為第一週的開始),00-53。 %x 本地日期表示 %X 本地時間表示 %y 年份模除 100。 %Y 十進制表示的完整年份。 %z 時區,表示格式為+HHMM(例如,格式要求生成的 RFC 822或者 RFC 1036 時間頭) %Z 時區名稱或縮寫,如果時區待定則無輸出。
其他函數
getline請參照下方的 "getline" 部分.
close(xxx [, from|to])關閉文件、shell進程, 可以僅關閉某一端.
close(xxx, "to")表示關閉該管道的寫入端,close(xxx, "from")表示關閉該管道的輸出端.注意!!!! awk 中任何文件都只會在第一次使用時打開, 之後都不會再重新打開(而是從上次的讀取位置繼續). 因此只有在關閉之後, 再次使用時才會重新打開.
next跳過對當前記錄的後續處理.會回到 awk 循環的頭部, 讀取下一行.
nextfile停止處理當前文件, 從下一個文件開始處理.return xx函數返回值system("shell命令")執行 shell 命令, 並返回退出的狀態值, 0表示成功.flush([output-expr])刷新打開文件或管道的緩衝區如果沒有提供 output-expr,fflush 將刷新標準輸出。若 output-epxr 是空字符串 (""),fflush 將刷新所有打開的文件和管道。
-
close(expr)關閉文件句柄 ???awk 'BEGIN { cmd = "tr [a-z] [A-Z]" print "hello, world !!!" |& cmd # "&|" 表示雙向管道通信 close(cmd, "to") # 關閉其中一個方向的管道, 另一個是 "from" 方向 cmd |& getline out # 使用 getline 函數將輸出存儲到 out 變量中 print out; close(cmd); # 關閉管道 }' 輸出 HELLO, WORLD !!! exit <code=0>終止腳本
自定義函數
function 函數名(參數) {
awk 語句
return awk變量
}注意
- 自定義函數的書寫不能再
BEGIN{},{},END{}的裏層
getline
getline 函數用於讀取一行數據.
根據不同情況, 返回值不一樣.
- 若讀取到數據, 返回 1.
- 若遇到 EOF, 返回 0.
- 發生錯誤, 返回負數. 如-1表示文件無法打開,-2表示IO操作需要重試(retry)。在遇到錯誤的同時,還會設置 ERRNO 變量來描述錯誤.
awk '{print $0; getline; print $0}' marks.txt
# 建議使用 getline 時判斷一下是否讀取成功
awk 'BEGIN {getline; if ((getline) > 0) {...}}'從當前文件讀取
- 使用
getline不帶參數時, 表示從當前正在處理的文件中立即讀取下一條記錄並保存到$0, 同時進行字段分割(分別存到$1,$2,...), 同時會設置 NF, RT, NR, FNR, 然後繼續執行後續代碼. - 執行
getline <變量名>時, 會將讀取結果保存到對應變量中, 而不會更新$0, 也不會更新 NF,$1,$2, ..., 此時僅僅會更新 RT, NR, FNR.
從其他文件讀取
-
執行
getline < "filename"表示從指定文件讀取一條記錄並保存到$0中(同時進行字段分割), 及 NF. 至於 NR, FNR 則不會更新.每次讀取記錄後會自動記錄讀取的位置.
配合
while及getline的返回值可以遍歷完文件.注意
getline < abc與getline < "abc"是兩碼事, 一個是從 abc 變量指向的文件讀取, 一個是讀取 abc 文件 - 執行
getline 變量名 < "filename"表示從指定文件讀取一條記錄並保存到指定變量中.
從 shell 命令輸出結果中讀取
cmd | getline:從Shell命令cmd的輸出結果中讀取一條記錄保存到$0中會進行字段劃分,設置變量
$0NF$NRT,不會修改變量NRFNRcmd | getline var:從Shell命令cmd的輸出結果中讀取數據保存到var中除了
var和RT,其它變量都不會設置
如果要再次執行 cmd 並讀取其輸出數據,則需要close關閉該命令, 示例:。
# 若屏蔽下方的 close 函數, 則再次讀取該 cmd 時為空. 因此需要關閉先.
awk 'BEGIN {cmd = "seq 1 5"; \
while((cmd | getline) > 0) {print}; \
close(cmd); \
while((cmd | getline) > 0) {print}; \
}'可以方便地使用 shell 給 awk 中變量賦值
awk 'BEGIN {get_date = "date +\"%F %T\""; \
get_date | getline cur_date; \
print cur_date; \
close(get_date);
}'
輸出
2020-10-13 19:14:17將數據傳給 shell 處理完(coprocess), 再讀取
這裏要利用 coprocess, 也就是 |& 操作符.
awk 可以利用 |& 將一些不好處理的數據傳給 shell 來處理後, 再從 shell 中讀取結果, 繼續在 awk 中處理.
使用 shell 的排序功能
# sort 命令會等待數據寫入完畢後(即 EOF 標記)才開始排序, 因此實際是在執行 close(CMD, "to") 時才開始執行.
awk 'BEGIN {
CMD = "sort -k2n";
print "6 66" |& CMD;
print "3 33" |& CMD;
print "7 77" |& CMD;
close(CMD, "to");
while ((CMD |& getline) > 0) {
print;
}
close(CMD);
}'
輸出:
3 33
6 66
7 77使用注意:
awk-print |& cmd會直接將數據寫進管道, cmd 可以從管道中獲取數據- 強烈建議在awk_print寫完數據之後加上
close(cmd,"to"),這樣表示向管道中寫入一個EOF標記,避免某些要求讀完所有數據再執行的cmd命令被永久阻塞.關閉管道另一端可以使用
close(cmd, "from") - 如果
cmd是按塊緩衝的,則getline可能會陷入阻塞。這時可將cmd部分改寫成stdbuf -oL cmd以強制其按行緩衝輸出數據CMD="stdbuf -oL cmdline";awk_print |& CMD;close(CMD,"to");CMD |& getline
高級輸出
print 輸出重定向
print "..."print "..." > 文件名重定向輸出-
print "..." >> 文件名重定向輸出這玩意比使用
system函數再調用 echo 快了好幾個量級 print "..." | "shell 命令"awk 將創建管道, 並啓動 shell 命令. print 產生的數據放入管道, shell 命令則從管道中讀取數據.print "..." |& "shell 命令"; "shell 命令" | getline和上面的|不同之處在於, 這裏是將數據交給 Coprocess, 之後 awk 還需要再從 Coprocess 取回數據.Coprocess 執行 shell 命令的時候, 結果是不輸出到標準輸出的, 而是需要從管道中自行讀取.
支持重定向到
- 標準輸入
/dev/stdin - 標準輸出
/dev/stdout - 標準錯誤
/dev/stderr
若 print 輸出後發現後續的管道命令沒有內容, 那其實是因為 awk 的輸出存在緩存, 可使用 fflush() 函數刷新緩衝區.
關於 | 和 |& 使用上區別的示例
# 這裏用的是 |, 執行結果直接輸出到標準輸出
awk 'BEGIN {
cmd = "tr \"[a-z]\" \"[A-Z]\""
print "hello" | cmd
> }'
# 這裏用的是 |&, 執行結果需要手動從 Coprocess 管道讀取
awk 'BEGIN {
cmd = "tr \"[a-z]\" \"[A-Z]\""
print "hello" |& cmd;
close(cmd, "to");
cmd |& getline line;
print line;
close(cmd);
}'
輸出
HELLOprintf 格式化
printf(format, value1, value2, ...)
參數
format 格式
%c (將ASCII轉換為)字符
%s 字符串
%d,%i 整數
%e,$e 科學計數法表示
%f,%F 浮點數
%g,%G 浮點數, 會移除對數值無影響的 0
%o 無符號八進制
%u 無符號十進制
%x,%X 無符號十六進制
%% 百分號
注意: 輸出時不會自動換行
示例
printf("total pay for %s is $%.2f\n", $1, $2 * $3)
# %-8s 字符串, 8個字符寬度, 左對齊
# %6.2f 浮點數, 6個字符寬度, 保留2位小數
printf("%-8s %6.2f\n", $1, $2 * $3)參考: https://awk.readthedocs.io/en...若僅僅是為了格式化字符串(不輸出), 可以用 sprintf 函數.
format 支持的轉義序列
- 換行符
\n - 水平製表符
\t -
垂直製表符
\v理解為輸出光標垂直向下移動一行
-
退格符
\b理解為輸出光標後退一格.
-
回車符
\r理解為光標會回退到當前行的開頭(常用於覆蓋本行)
-
換頁符
\f這個效果...得試一下才行
format 的 % 的可選參數
-
寬度
只有當字段的寬度比要求寬度小時該標示才會有效, 默認使用空格字符填充.
printf("%10d", 1) 輸出 1 -
前導零
0只有當字段的寬度比要求寬度小時該標示才會有效
awk 'BEGIN {printf("%010d", 1)}' 輸出 0000000001 -
左對齊
-在
%和數字之間使用-符號即可指定左對齊awk 'BEGIN {printf("%-10d", 1)}' 輸出 1 -
符號前綴
+使用
+, 在輸出數字時, 將其正負號也輸出.awk 'BEGIN {printf("%+10d", 1)}' 輸出 +1 -
保留進制標識
#awk 'BEGIN {printf("%#o %#X\n", 10, 10)}' 輸出 012 0XA
Examples
打印出當前的可用內核列表
並顯示序號
awk -F "'" '/^menuentry/ {print x++,$2}' /boot/grub2/grub.cfg
輸出
0 CentOS Linux (5.5.6) 7 (Core)
1 CentOS Linux (3.10.0-1062.12.1.el7.x86_64) 7 (Core)
2 CentOS Linux (3.10.0-957.el7.x86_64) 7 (Core)
3 CentOS Linux (0-rescue-d64aa77b8f014365aa6557986697df9c) 7 (Core)統計當前tcp的各個狀態及數量
netstat -ntp | awk '/^tcp / {S[$6]++} END{for (i in S) print i,S[i];}'
輸出
TIME_WAIT 108
ESTABLISHED 154統計每個接口的訪問時間
time cat 20_10_*.txt | grep "request cost" | gawk -v suffix=_test -f ../stat_method.awkstat_method.awk
BEGIN {
DEBUG = 1
methodRecordFile = "method_record"suffix".csv"
methodStatsFile = "method_stats"suffix".csv"
if (DEBUG) {
methodRecordFile = "/dev/stdout"
methodStatsFile = "/dev/stdout"
}
print methodRecordFile
print methodStatsFile
}
{
method=substr($10,2,length($10)-2)
method=substr(method,1,length(method)-7)
timeStr=$1" "$2
timeMs=$6 + 0.01
uid=substr($11,2,length($11)-2)
msLevel=(int(timeMs/100) + 1) * 100
T[method][msLevel]++
if (!(method in Stats)) {
Stats[method]["name"] = method
Stats[method]["max"] = 0
Stats[method]["mean"] = 0
Stats[method]["count"] = 0
Stats[method]["sum"] = 0
Stats[method]["sumX2"] = 0
Stats[method]["min"] = 9999999999999
}
if (timeMs > Stats[method]["max"]) {
Stats[method]["max"] = timeMs
}
if (timeMs < Stats[method]["min"]) {
Stats[method]["min"] = timeMs
}
Stats[method]["sumX2"] += timeMs * timeMs
Stats[method]["count"]++
Stats[method]["sum"] += timeMs
if (NR % 10000 == 0) {
print "已處理 "NR" 條記錄"
}
}
END {
print "----------- 總共處理 "NR" 條記錄 -----------"
print "method,msLevel,count" > methodRecordFile
# print "method,msLevel,count"
for (m in T) {
for (l in T[m]) {
print m","l","T[m][l] >> methodRecordFile
# print m","l","T[m][l]
}
}
print "----------- done -----------"
print "method,min,max,mean,sd(標準差),count,sum(秒)" > methodStatsFile
printf("%-30s\tmin\tmax\tcount\tmean\tsd(標準差)\t,sum(秒)\n", "method")
for (m in Stats) {
Stats[m]["mean"] = Stats[m]["sum"] / Stats[m]["count"]
Stats[m]["sd"] = sqrt(Stats[m]["sumX2"] / Stats[m]["count"] - Stats[m]["mean"] * Stats[m]["mean"])
# for (n in Stats[m]) {
# print "Stats["m"]["n"]= " Stats[m][n]
# }
print m "," Stats[m]["min"] "," Stats[m]["max"] "," Stats[m]["mean"] "," Stats[m]["sd"]"," Stats[m]["count"]","Stats[m]["sum"]/1000 >> methodStatsFile
printf("%-30s\t%.2f\t%.2f\t%.0f\t%.2f\t%d\t%.2f\n", substr(m, 0, 30), Stats[m]["min"], Stats[m]["max"],Stats[m]["mean"],Stats[m]["sd"], Stats[m]["count"], Stats[m]["sum"]/1000)
}
print "----------- done -----------"
print methodRecordFile
print methodStatsFile
} 格式化空白
cat > a.txt <<'EOF'
aaaa bbb ccc
bbb aaa ccc
ddd fff eee gg hh ii jj
EOF
awk 'BEGIN{OFS=" "} {NF=NF; print}' a.txt輸出
aaaa bbb ccc
bbb aaa ccc
ddd fff eee gg hh ii jj打印 ini 文件中的某一段
awk -v scope="extras" 'BEGIN {scope="["scope"]"}
$0 == scope {
print;
while ((getline) > 0) {
if ($0 !~ /\[.*\]/) { print $0; } else { exit }
}
}
' /etc/yum.repos.d/CentOS-Base.repo輸出如下 👇
[extras]
name=CentOS-$releasever - Extras
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
#additional packages that extend functionality of existing packages處理字段中包含字段分割符情況(csv)
echo 'Robbins,Arnold,"1234 A Pretty Street, NE","MyTown",MyState,12345-6789,USA' | awk 'BEGIN { FPAT="[^,]+|\"[^\"]+\"" } { print NF" "$3}'輸出如下 👇
7 "1234 A Pretty Street, NE"